 用于學習對象級、語言感知和語義豐富視覺表征的GLIP模型
用于學習對象級、語言感知和語義豐富視覺表征的GLIP模型
簡介
問題
Visual recognition 模型通常只能預測一組固定的預先確定的目標類別,這限制了在現實世界的可擴展能力,因為對于新的視覺概念類別和新的任務領域需要新的標注數據。
CLIP可以在大量圖像文本對上有效地學習 image-level 的視覺表征,因為大規模匹配的圖像文本對包含的視覺概念比任何預定義的概念都更廣泛,預訓練的CLIP模型語義豐富,可以在 zero-shot 下輕松地遷移到下游的圖像分類和文本圖像檢索任務中。
為了獲得對圖像的細粒度理解(如目標檢測、分割、人體姿態估計、場景理解、動作識別、視覺語言理解),這些任務都非常需要 object-level 的視覺表征。
方案
這篇論文提出了 grounded language-image pretraining (GLIP) 模型,用于學習對象級、語言感知和語義豐富的視覺表征。GLIP將 object detection 和 phrase grounding 結合起來進行預訓練。這有兩個好處:
GLIP可以同時從 detection 和 grounding 數據中訓練學習,以改進兩種任務,訓練一個優秀的 grounding 模型;
GLIP可以通過 self-training 的方式生成 grounding boxes(即偽標簽)來利用大量的圖像文本對數據,使學習到的視覺表征具有豐富的語義。
實驗上,作者對27M grounding data 進行預訓練(包括3M人工注釋和24M網絡爬取的圖像文本對)。訓練學習到的視覺表征在各種目標級別的識別任務中都具有較強的zero/few shot遷移能力。
當直接在COCO和LVIS上評估(預訓練期間沒有訓練COCO中的圖像)時,GLIP分別達到 49.8 AP和 26.9 AP;
當在COCO上進行微調后,在val上達到 60.8 AP,在test-dev上達到 61.5 AP,超過了之前的SoTA模型。
主要貢獻
「1、Unifying detection and grounding by reformulating object detection as phrase grounding」
改變了檢測模型的輸入:不僅輸入圖像,還輸入 text prompt(包含檢測任務的所有候選類別)。例如,COCO目標檢測任務的 text prompt 是由80個COCO對象類別名組成的文本字符串,如圖2(左)所示。通過將 object classification logits 替換為 word-region alignment 分數(例如視覺region和文本token的點積),任何 object detection 模型都可以轉換為 grounding 模型,如圖2(右)所示。與僅在最后點積操作融合視覺和語言的CLIP不同,GLIP利用跨模態融合操作,具有了深度的跨模態融合的能力。
「2、Scaling up visual concepts with massive image-text data」
給定 grounding 模型(teacher),可以自動生成大量圖像-文本對數據的 grounding boxes 來擴充GLIP預訓練數據,其中 noun phrases 由NLP解析器檢測,圖3為兩個 boxes 的示例,teacher模型可以定位到困難的概念,如注射器、疫苗、美麗的加勒比海綠松石,甚至抽象的單詞(視圖)。在這種語義豐富的數據上訓練可以生成語義豐富的student模型。
「3、Transfer learning with GLIP: one model for all」
GLIP可以有效的遷移到各種任務中,而只需要很少甚至不需要額外的人工標注。此外,當特定于任務的標注數據可用時,也不必微調整個模型,只需微調特定于任務的 prompt embedding,同時凍結模型參數。
相關工作
標準的 object detection 模型只能推理固定的對象類別,如COCO,而這種人工標注的數據擴展成本很高。GLIP將 object detection 定義為 phrase grounding,可以推廣到任何目標檢測任務。
CLIP和ALIGN在大規模圖像-文本對上進行跨模態對比學習,可以直接進行開放類別的圖像分類。GLIP繼承了這一研究領域的語義豐富和語言感知的特性,實現了SoTA對象檢測性能,并顯著提高了對下游檢測任務的可遷移能力。
方法
Grounded Language Image Pre-training
在概念上,object detection 與 phrase grounding 具有很大的相似性,它們都尋求對對象進行本地化(即學習到并能檢測這種對象的類別),并將其與語義概念對齊。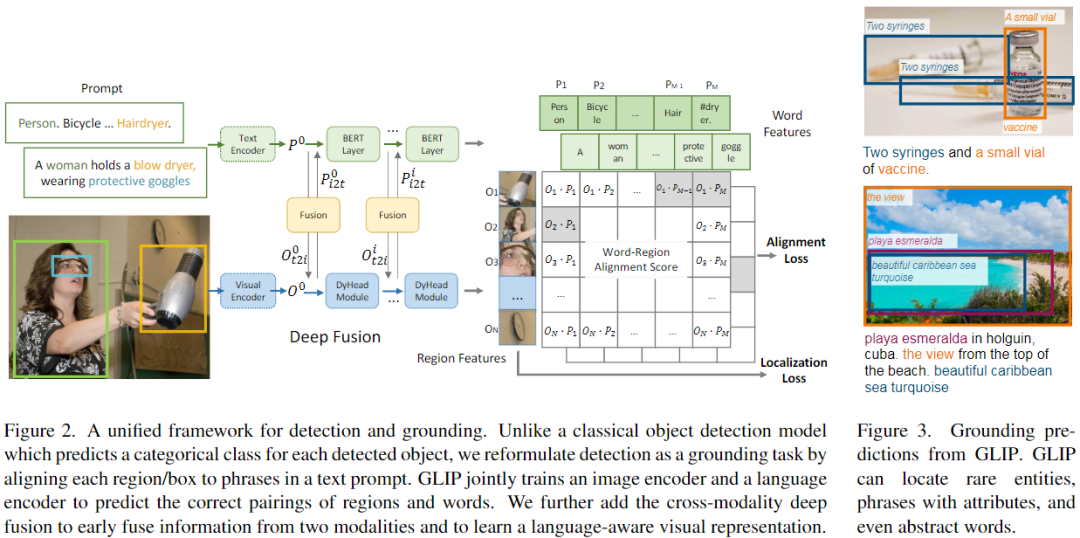
a、Unified Formulation
「Background: object detection」
標準的檢測模型將一張圖像輸入 visual encoder(CNN或Transformer),提取 region/box 特征(圖2底部),每個 region/box 特征輸入兩個 prediction heads,即分類器(分類損失)和回歸器(定位損失)。在兩階段檢測器中,還有一個分離的RPN層用以區分前景、背景和改善anchors,因為RPN層沒有用到目標類別的語義信息,我們將其損失合并到定位損失。
「Object detection as phrase grounding」
作者不是將每個 region/box 分類為c類,而是將檢測任務重新定義為一個 grounding 任務,通過將每個 region 與文本 prompt(Prompt = "Detect: person, bicycle, car, ... , toothbrush") 中的c個phrases 進行 grounding/aligning(圖2)。在 grounding 模型中,計算圖像區域和prompt中的word之間的對齊分數:
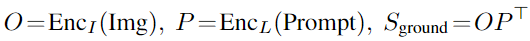
其中 為圖像編碼器, 為文本編碼器,通過 和上一小節提到的分類損失、定位損失,共三個損失端到端進行訓練。到這里,會有一個問題,如圖2中間所示,子詞的數量 是要大于文本 prompt 的 phrases 數量 的,這是因為:
有一些phrase包含多個word,例如‘traffic light’;
一些單詞會切分為多個子詞,例如‘toothbrush’會切分為‘tooth#’和‘#brush’;
一些token為added token或special token,不屬于要識別的類別;
在token詞表中會添加一個[NoObj] token。
因此,如果一個phrase是正匹配某個visual region,便將所有子詞正匹配,而將所有的added token負匹配所有的visual region,這樣將原始的分類損失擴展為。
「Equivalence between detection and grounding」
通過上述方法,將任意detection 模型轉化為grounding模型,且理論上訓練和推理都是等價的。由于語言編碼器的自由形式的輸入,預訓練的phrase grounding模型可以直接應用于任何目標檢測任務。
b、Language-Aware Deep Fusion
在公式3中,圖像和文本由單獨的編碼器編碼,只在最后融合以計算對齊分數,這種模型為晚期融合模型,而在視覺語言任務中,視覺和語言特征的深度融合是必要的。
因此,作者在圖像和語言編碼器之間引入了深度融合,融合最后幾個編碼層中的圖像和文本信息,如圖2(中)所示。具體來說,當使用DyHead作為圖像編碼器,BERT作為文本編碼器時,深度融合編碼器為:
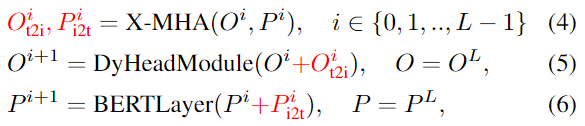
跨模態交互由跨模態多頭注意力(X-MHA)(4)實現,然后是單模態融合,并在(5)和(6)中更新。在沒有添加上下文向量(視覺模態和語言模態)的情況下,模型即為后期融合模型。
在跨模態多頭注意力(XMHA)(4)中,每個head通過關注另一個模態來計算一個模態的上下文向量:
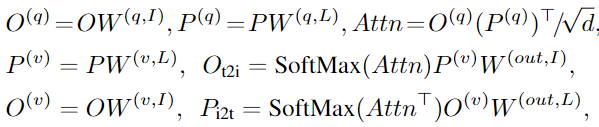
深度融合(4)-(6)有兩個好處:
提高了 phrase grounding 性能;
使學習到的視覺表征是語言感知的。
因此模型的預測是以文本prompt為條件的。
c、Pre-training with Scalable Semantic-Rich Data
GLIP模型可以在檢測和更重要的grounding數據上進行訓練,作者表明,grounding數據可以提供豐富的語義,以促進本地化,可以以self-training的方式擴展。
Grounding 數據涵蓋了更多的視覺概念詞匯,因此作者擴展了詞匯表,幾乎涵蓋了 grounded captions 中出現的任何概念,例如,Flickr30K包含44,518個惟一的phrase,而VG Caption包含110,689個惟一phrase。
實驗
GLIP variants
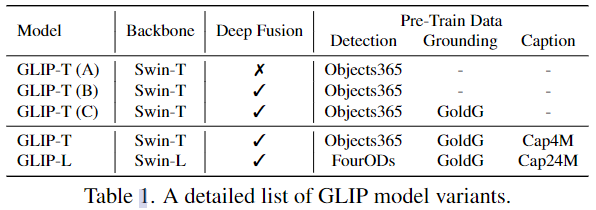
經過預訓練,GLIP可以輕松地應用于 grounding 和 detection 任務,在三個基準上顯示了強大的域遷移性能:
COCO,包含80個類別;
LVIS包含1000個類別;
Flickr30K用以 phrase grounding任務。
作者訓練了5個GLIP變種模型(表1)用以消融,其中GoldG是指0.8M人類標注的grounding數據,包括Flickr30K, VG Caption和GQA,并且已經從數據集中刪除了COCO圖像,Cap4M和Cap24M是指網絡收集的圖文對。
a、Zero-Shot and Supervised Transfer on COCO
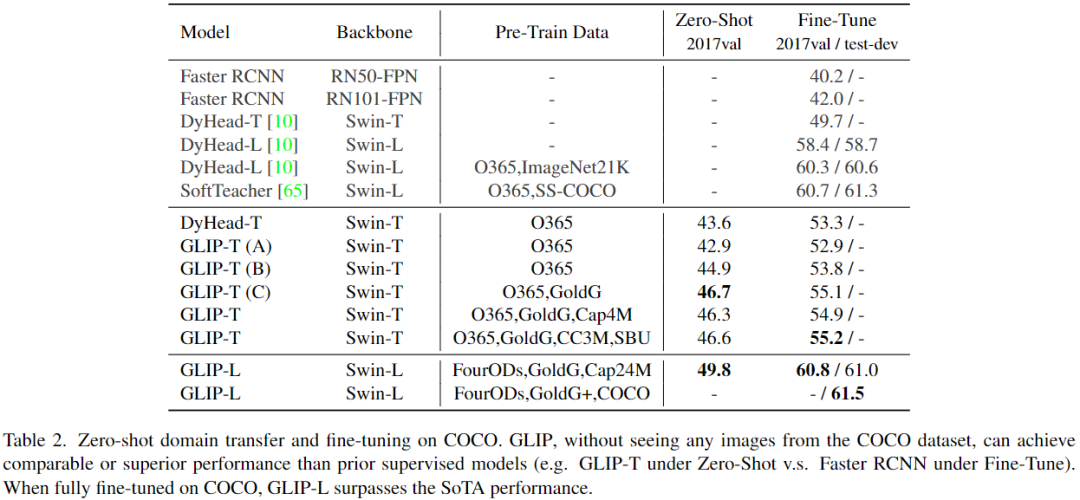
表2可以看到,GLIP模型實現了強大的zero-shot和有監督(即Fine-Tune)性能。GLIP-T(C)達到46.7 AP,超過了Faster RCNN,GLIP-L達到49.8 AP,超過DyHead-T。
在有監督下,GLIP-T比標準DyHead提高5.5 AP (55.2 vs 49.7)。通過swin-large作為主干,GLIP-L超越了COCO上當前的SoTA,在2017val上達到了60.8 AP,在test-dev上達到了61.5 AP。
b、Zero-Shot Transfer on LVIS
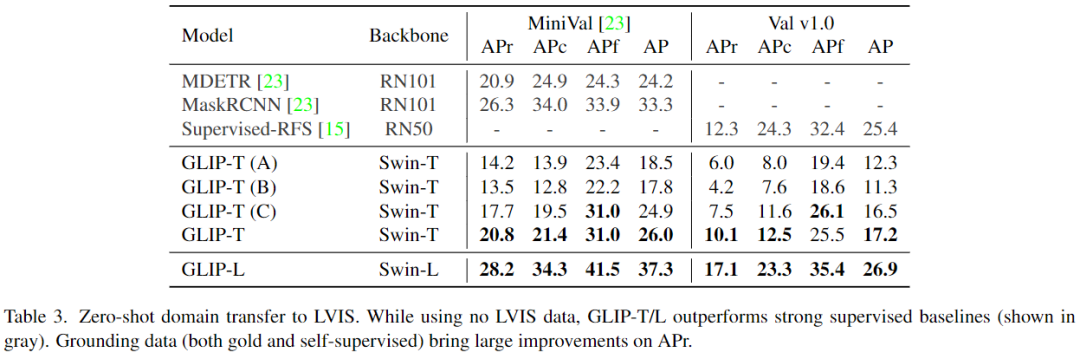
表3可以看到,GLIP在所有類別上都展示了強大的zero-shot性能。
c、Phrase Grounding on Flickr30K Entities
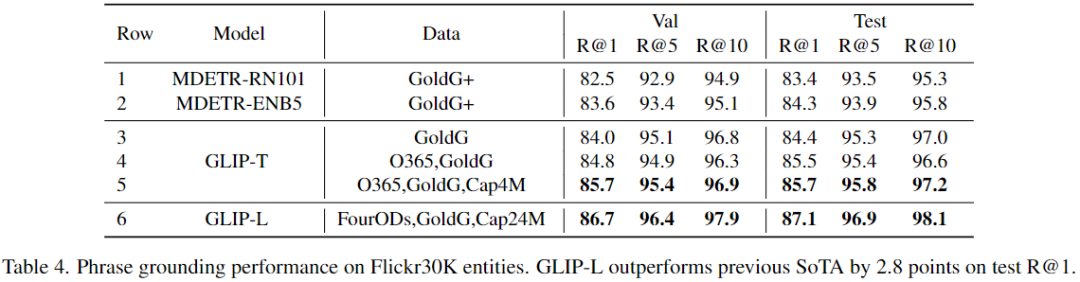
帶有GoldG(第3行)的GLIP-T實現了與帶有GoldG+的MDETR相似的性能,這是因為引入了Swin Transformer、DyHead模塊和深度融合模塊。擴展訓練數據的(GLIP-L)可以達到87.1 Recall@1,比之前的SoTA高出2.8點。
總結
GLIP將 object detection 和 phrase grounding 任務統一起來,以學習對象級的、語言感知的和語義豐富的視覺表征。在預訓練之后,GLIP在完善的基準測試和13個下游任務的zero-shot和fine-tune設置方面顯示了有競爭力的結果。
審核編輯:劉清
-
Clip
+關注
關注
0文章
31瀏覽量
6674 -
cnn
+關注
關注
3文章
353瀏覽量
22254 -
nlp
+關注
關注
1文章
489瀏覽量
22058
原文標題:全新的多模態預訓練范式:微軟提出GLIP統一了對象檢測和短語定位任務
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用VLM和MLLMs實現SLAM語義增強

基于視覺語言模型的導航框架VLMnav
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
圖像分割與語義分割中的CNN模型綜述
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
淺析自動駕駛行業的視覺感知主流框架設計
機器人基于開源的多模態語言視覺大模型






 工商網監
工商網監
評論