") 談?wù)勎锫?lián)網(wǎng)抱穩(wěn)的AI大腿
談?wù)勎锫?lián)網(wǎng)抱穩(wěn)的AI大腿
電子發(fā)燒友網(wǎng)報道(文/周凱揚)如今各行各業(yè)似乎都傍上了AI,物聯(lián)網(wǎng)也不例外。但AIoT的進(jìn)程也已經(jīng)開啟了好幾年,除了智能音箱、智能機器人這樣的產(chǎn)品以外,似乎也沒有冒出任何爆款,反倒是手機憑借著龐大的應(yīng)用生態(tài),Killer App頻出。可無論是芯片原廠,還是下游廠商仍在不遺余力地宣傳AI功能,這讓人百思不得其解了,物聯(lián)網(wǎng)真的抱穩(wěn)了AI這條大腿嗎?我們不妨從物聯(lián)網(wǎng)上實現(xiàn)AI的幾種方式來分析一下。
AIoT芯片
隨著邊緣端對AI需求的增加,其實不少廠商在不改變芯片架構(gòu)的情況下,也為邊緣AI開發(fā)提供了一系列工具。就拿意法半導(dǎo)體為例,他們旗下的STM32產(chǎn)品就全部兼容NanoEdge生態(tài),支持生成異常檢測、異常值檢測、分類和回歸四種ML庫,可以完成常見的能源管理和壽命預(yù)測等工作。至于對性能要求更高的深度學(xué)習(xí)應(yīng)用,就得用到他們的STM32Cube.AI了,對MCU的要求也提升至Cortex-M33以上的內(nèi)核。這種方式對于芯片原廠來說,無需對設(shè)計做出大改,也有助于建立起自己的AI開發(fā)工具鏈生態(tài),還可以針對不同芯片的性能進(jìn)行調(diào)整。

輕量級AI框架
不僅是芯片廠商,AI框架的開發(fā)者們也注意到了IoT龐大的邊緣AI市場,紛紛在推出輕量化或可擴展性強的框架,比如TensorFlow Lite、Caffe2等。這類框架可以在內(nèi)存極小的設(shè)備上運行ML模型,也不需要任何操作系統(tǒng)、庫的支持。由于走了輕量化的路線,所以與工作站或數(shù)據(jù)中心這種場景跑的AI框架還是存在差異的,但也足以完成常見的對象檢測、手勢識別、超分辨率等工作,TinyML已經(jīng)成了每個物聯(lián)網(wǎng)公司研究的方向。

傳感器AI
大家都知道,一旦將數(shù)據(jù)處理盡可能放在靠前的流程中,不僅能降低功耗和延遲,也能極大地提升AI運算的效率,省去交給云端處理這一繁瑣的步驟。在大部分IoT場景中,數(shù)據(jù)傳輸流程的頭部往往都是傳感器,所以無論是何種傳感器,制造商們都開始探討集成AI的方案。

寫在最后
我們自然也不能忽視掉在云端進(jìn)行AI處理的方案,固然這是一種將性能放大到極致的路線。可如果將未經(jīng)處理的數(shù)據(jù)一股腦交給云端處理的話,徒增上云成本不說,延遲也會大大增加;全部交給端測來完成AI計算的話,功耗續(xù)航都得做出讓步,甚至還是難以跑出可觀的性能。這也就是為何亞馬遜、阿里巴巴等廠商紛紛部署IoT的邊緣計算的原因,即便邊緣端接手了主要的AI計算工作,卻依然可以將數(shù)據(jù)交給云端進(jìn)行管理、存儲和分析,而且這不一定是一個實時連接的過程,只需間歇性的同步也能完成任務(wù)。更何況功能、固件升級這樣的任務(wù)主要還是交給云端來實現(xiàn)的,在有效的分析和訓(xùn)練下,云端可以將優(yōu)化過后的模型傳給邊緣端。所以由此看來,物聯(lián)網(wǎng)要想真正跨入AI時代,端云協(xié)同才是最佳方案。


更多熱點文章閱讀
- 車載大屏產(chǎn)業(yè)鏈分析,主要玩家都有誰?
- 谷歌3D全息電話亭,顛覆現(xiàn)有視頻通話!宛如真人面對面
- 富士康Model B/V正式發(fā)布,ALL IN電動車代工,全產(chǎn)業(yè)鏈布局格局顯現(xiàn)
- 半導(dǎo)體TOP 10廠商股價集體腰斬,臺積電再傳危機信號
- 2026年交付!索尼造車終于塵埃落定,本田成代工廠
原文標(biāo)題:談?wù)勎锫?lián)網(wǎng)抱穩(wěn)的AI大腿
文章出處:【微信公眾號:電子發(fā)燒友網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2909文章
44611瀏覽量
373134 -
AI
+關(guān)注
關(guān)注
87文章
30838瀏覽量
268997
原文標(biāo)題:談?wù)勎锫?lián)網(wǎng)抱穩(wěn)的AI大腿
文章出處:【微信號:elecfans,微信公眾號:電子發(fā)燒友網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
物聯(lián)數(shù)據(jù)中臺是什么意思?AI+IOT物聯(lián)網(wǎng)中臺平臺解決方案
物聯(lián)數(shù)據(jù)中臺是什么意思?AI+IOT物聯(lián)網(wǎng)中臺平臺解決方案

物聯(lián)網(wǎng)學(xué)習(xí)路線來啦!
物聯(lián)網(wǎng)學(xué)習(xí)路線來啦! 物聯(lián)網(wǎng)方向作為目前一個熱門的技術(shù)發(fā)展方向,有大量的人才需求,小白的學(xué)習(xí)入門路線推薦以下步驟。 1.了解物
發(fā)表于 11-11 16:03
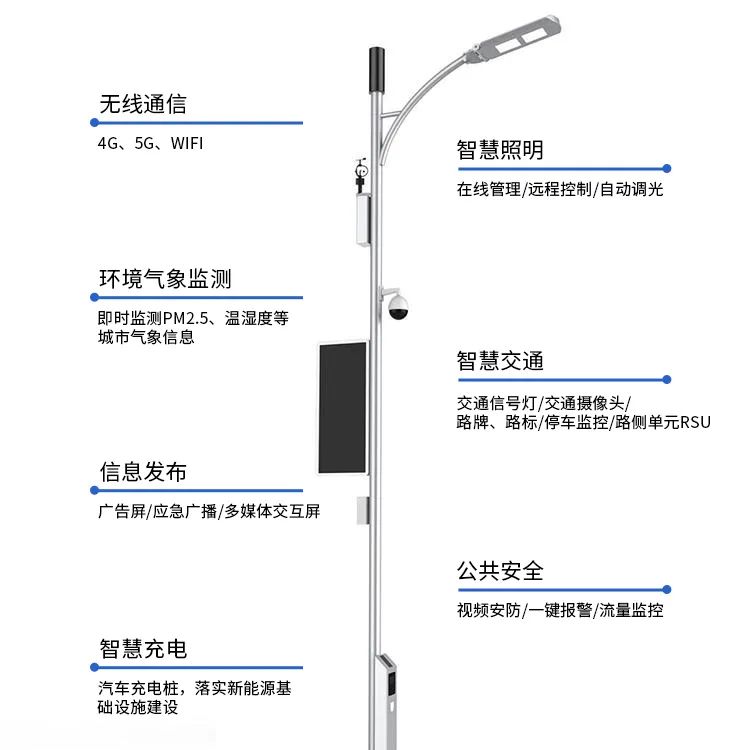
什么是智慧燈桿屏?AI物聯(lián)網(wǎng)LED燈桿屏路燈燈桿顯示器?
什么是智慧燈桿屏?AI物聯(lián)網(wǎng)LED燈桿屏路燈燈桿顯示器?
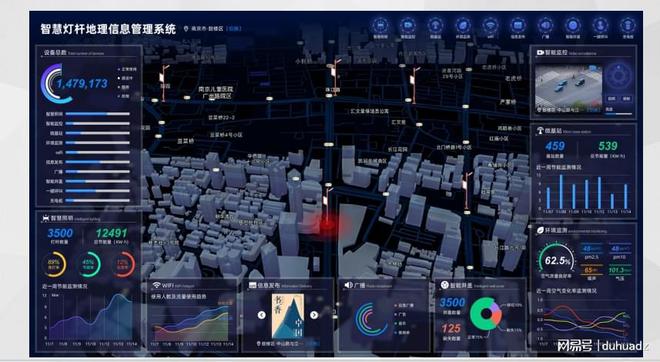
盾華電子創(chuàng)新物聯(lián)網(wǎng)LED智慧燈桿屏,AI燈桿屏助力智慧城市建設(shè)
盾華電子創(chuàng)新物聯(lián)網(wǎng)LED智慧燈桿屏,AI燈桿屏助力智慧城市建設(shè)

智慧城市 盾華電子物聯(lián)網(wǎng)AI智慧燈桿屏為城市建設(shè)提檔增速
智慧城市 | 盾華電子物聯(lián)網(wǎng)AI智慧燈桿屏為城市建設(shè)提檔增速
AI嵌入式蜂窩模塊將主導(dǎo)物聯(lián)網(wǎng)市場
據(jù)知名市場調(diào)查機構(gòu)Counterpoint Research最新發(fā)布的報告,AI嵌入式蜂窩模塊在物聯(lián)網(wǎng)領(lǐng)域的應(yīng)用正迎來爆發(fā)式增長。該報告預(yù)測,到2030年,AI嵌入式蜂窩模塊將占據(jù)
什么是物聯(lián)網(wǎng)技術(shù)?
什么是物聯(lián)網(wǎng)技術(shù)?
物聯(lián)網(wǎng)技術(shù)(Internet of Things, IoT)是一種通過信息傳感設(shè)備,按約定的協(xié)議,將任何物體與網(wǎng)絡(luò)相連接,實現(xiàn)智能化識別、定位、跟蹤、監(jiān)管等功能的
發(fā)表于 08-19 14:08

醫(yī)院新生兒如何做到防盜防抱錯? #嬰兒防盜 #醫(yī)療物聯(lián)網(wǎng) #智慧醫(yī)院
物聯(lián)網(wǎng)
貓度云科醫(yī)療物聯(lián)網(wǎng)
發(fā)布于 :2024年06月28日 18:23:45
梯云物聯(lián)|AI提高物聯(lián)網(wǎng)感知能力:讓電梯更智能、安全!
在當(dāng)今日新月異的科技浪潮中,人工智能(AI)與物聯(lián)網(wǎng)(IoT)的深度融合正在為各行各業(yè)帶來革命性的變化。特別是在電梯行業(yè)中,AI技術(shù)的引入不僅極大地提升了

4G物聯(lián)網(wǎng)開關(guān)求助
阿里云物聯(lián)網(wǎng)平臺 合宙模塊780E 724 或者移遠(yuǎn)4G模塊開發(fā)一款物聯(lián)網(wǎng)開關(guān),有的APP ,可以直接做固件或者固件帶硬件。有可以做的大師可以聯(lián)系我有樣品參考
發(fā)表于 05-19 15:28
梯云物聯(lián):電梯物聯(lián)網(wǎng)如何又快穩(wěn)的發(fā)展?這5關(guān)鍵要素不可忽視!
隨著物聯(lián)網(wǎng)技術(shù)的飛速發(fā)展,電梯物聯(lián)網(wǎng)作為智能化時代的產(chǎn)物,正逐漸展現(xiàn)出其巨大的潛力和價值。電梯物聯(lián)網(wǎng)
物聯(lián)網(wǎng)是什么?物聯(lián)網(wǎng)的功能
物聯(lián)網(wǎng)(Internet of Things,IoT)是指通過信息傳感設(shè)備,按照約定的協(xié)議,將任何物體與網(wǎng)絡(luò)相連接,物體通過信息傳播媒介進(jìn)行信息交換和通信,以實現(xiàn)智能化識別、定位、跟蹤、監(jiān)管等功能
電梯物聯(lián)網(wǎng)AI攝像頭:物聯(lián)網(wǎng)時代下的智能安全新篇章與技術(shù)發(fā)展|梯云物聯(lián)
在物聯(lián)網(wǎng)技術(shù)如日方升的今天,電梯物聯(lián)網(wǎng)AI攝像頭正成為智能安全領(lǐng)域的一顆璀璨明珠。隨著技術(shù)的不斷發(fā)展,它以其獨特的智能化、高效化特點,為電梯
NanoEdge AI的技術(shù)原理、應(yīng)用場景及優(yōu)勢
NanoEdge AI 是一種基于邊緣計算的人工智能技術(shù),旨在將人工智能算法應(yīng)用于物聯(lián)網(wǎng)(IoT)設(shè)備和傳感器。這種技術(shù)的核心思想是將數(shù)據(jù)處理和分析從云端轉(zhuǎn)移到設(shè)備本身,從而減少數(shù)據(jù)傳輸延遲、降低
發(fā)表于 03-12 08:09
物聯(lián)網(wǎng)IOT芯片是什么?物聯(lián)網(wǎng)芯片的作用 物聯(lián)網(wǎng)芯片的應(yīng)用領(lǐng)域
物聯(lián)網(wǎng)IOT芯片是什么?物聯(lián)網(wǎng)芯片的作用 物聯(lián)網(wǎng)芯片的應(yīng)用領(lǐng)域?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論