 用Python算法預測客戶行為案例!
用Python算法預測客戶行為案例!
這是一份kaggle上的銀行的數據集,研究該數據集可以預測客戶是否認購定期存款y。這里包含20個特征。
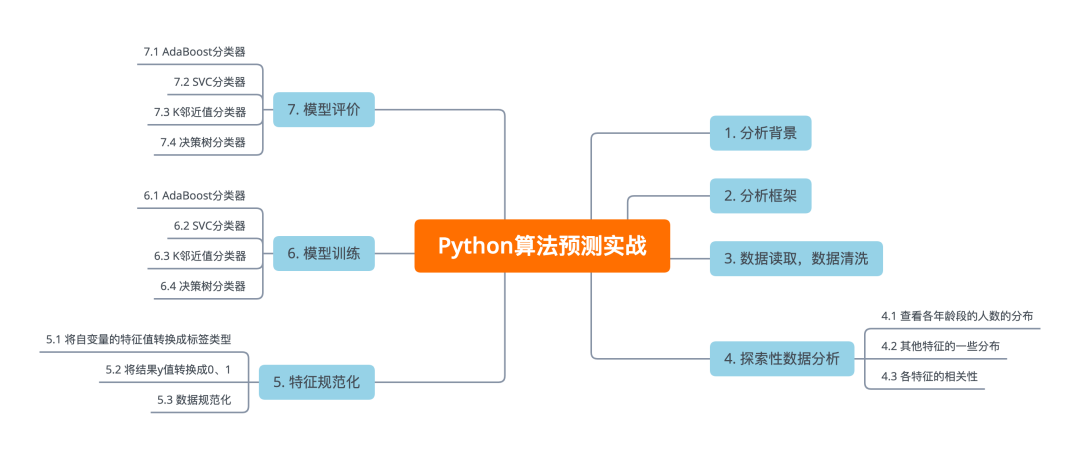
1. 分析框架
2. 數據讀取,數據清洗
#導入相關包
importnumpyasnp
importpandasaspd
#讀取數據
data=pd.read_csv('./1bank-additional-full.csv')
#查看表的行列數
data.shape
輸出:
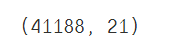
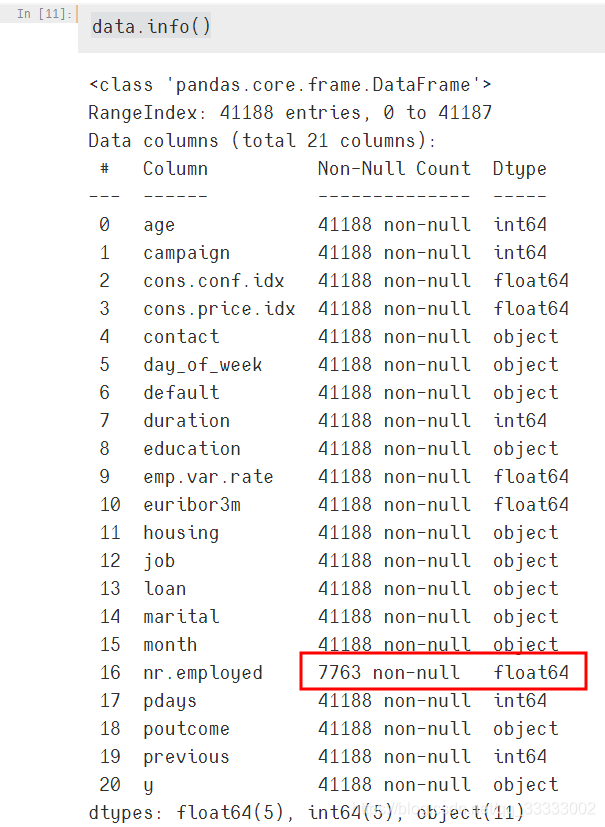
這里只有nr.employed這列有丟失數據,查看下:
data['nr.employed'].value_counts()

這里只有5191.0這個值,沒有其他的,且只有7763條數據,這里直接將這列當做異常值,直接將這列直接刪除了。
#data.drop('nr.employed',axis=1,inplace=True)
3. 探索性數據分析
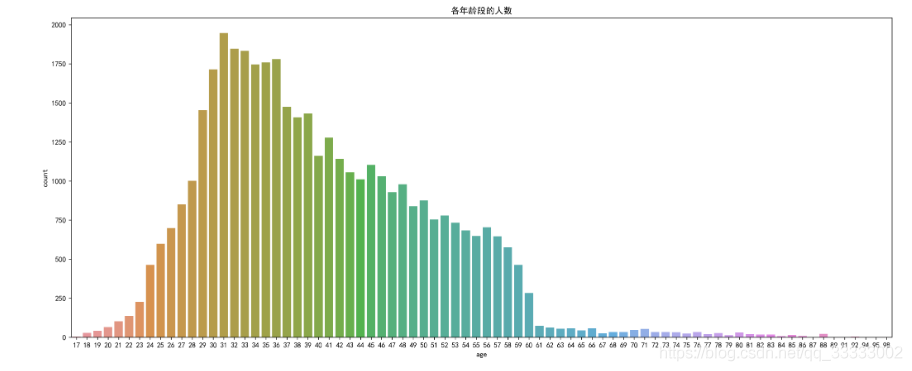
3.1查看各年齡段的人數的分布
這里可以看出該銀行的主要用戶主要集中在23-60歲這個年齡層,其中29-39這個年齡段的人數相對其他年齡段多。
importmatplotlib.pyplotasplt
importseabornassns
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(20,8),dpi=256)
sns.countplot(x='age',data=data)
plt.title("各年齡段的人數")
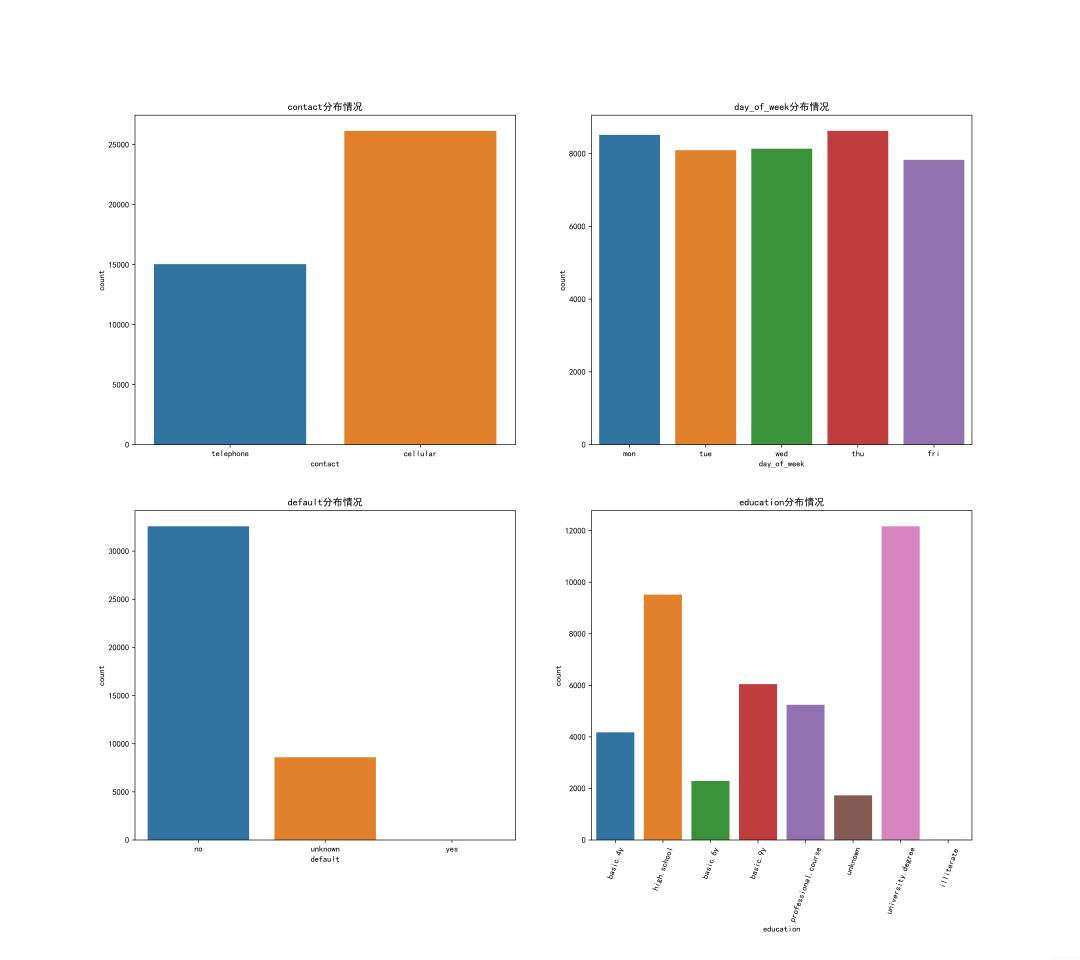
3.2 其他特征的一些分布
plt.figure(figsize=(18,16),dpi=512)
plt.subplot(221)
sns.countplot(x='contact',data=data)
plt.title("contact分布情況")
plt.subplot(222)
sns.countplot(x='day_of_week',data=data)
plt.title("day_of_week分布情況")
plt.subplot(223)
sns.countplot(x='default',data=data)
plt.title("default分布情況")
plt.subplot(224)
sns.countplot(x='education',data=data)
plt.xticks(rotation=70)
plt.title("education分布情況")
plt.savefig('./1.png')
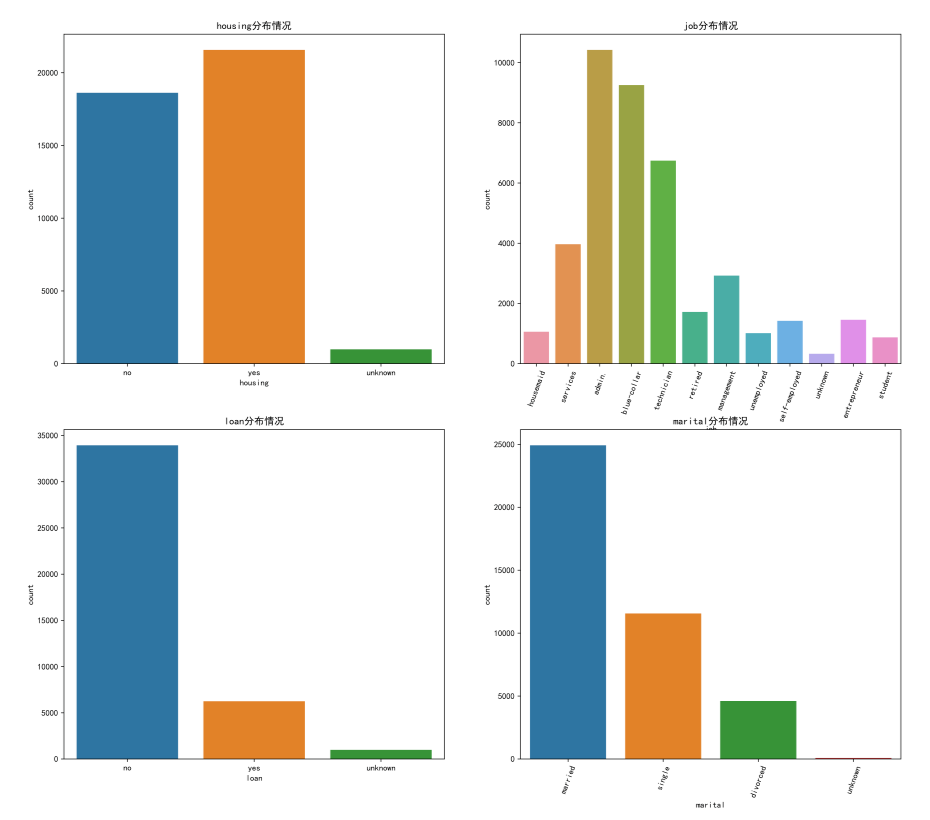
plt.figure(figsize=(18,16),dpi=512)
plt.subplot(221)
sns.countplot(x='housing',data=data)
plt.title("housing分布情況")
plt.subplot(222)
sns.countplot(x='job',data=data)
plt.xticks(rotation=70)
plt.title("job分布情況")
plt.subplot(223)
sns.countplot(x='loan',data=data)
plt.title("loan分布情況")
plt.subplot(224)
sns.countplot(x='marital',data=data)
plt.xticks(rotation=70)
plt.title("marital分布情況")
plt.savefig('./2.png')
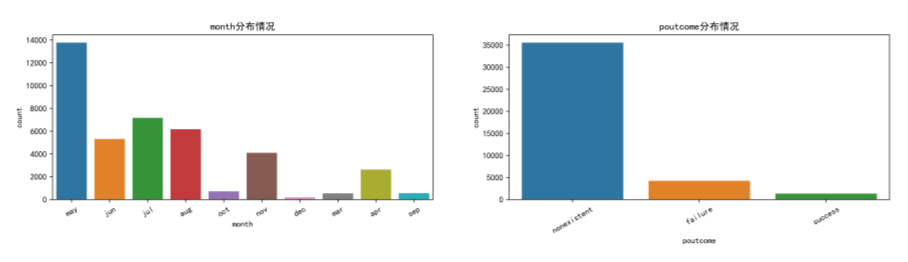
plt.figure(figsize=(18,8),dpi=512)
plt.subplot(221)
sns.countplot(x='month',data=data)
plt.xticks(rotation=30)
plt.subplot(222)
sns.countplot(x='poutcome',data=data)
plt.xticks(rotation=30)
plt.savefig('./3.png')
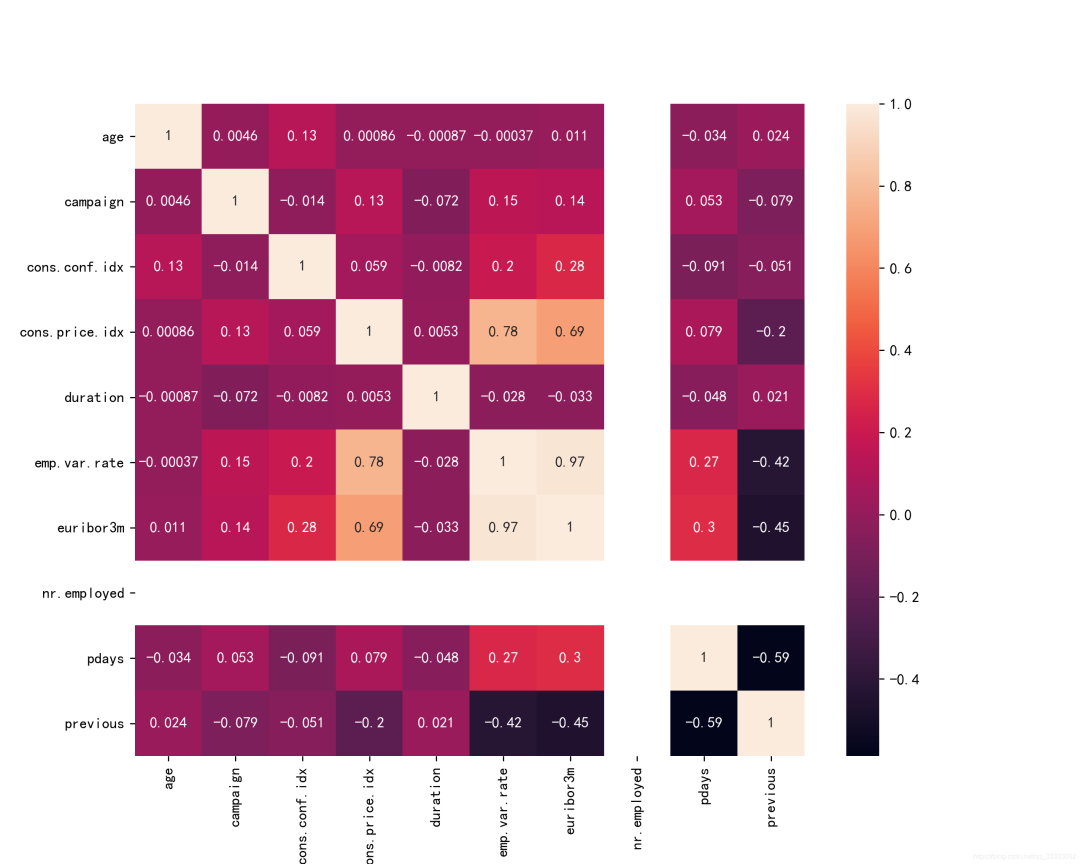
3.3 各特征的相關性
plt.figure(figsize=(10,8),dpi=256)
plt.rcParams['axes.unicode_minus']=False
sns.heatmap(data.corr(),annot=True)
plt.savefig('./4.png')
4. 特征規范化
4.1 將自變量的特征值轉換成標簽類型
#特征化數據
fromsklearn.preprocessingimportLabelEncoder
features=['contact','day_of_week','default','education','housing',
'job','loan','marital','month','poutcome']
le_x=LabelEncoder()
forfeatureinfeatures:
data[feature]=le_x.fit_transform(data[feature])
4.2 將結果y值轉換成0、1
defparse_y(x):
if(x=='no'):
return0
else:
return1
data['y']=data['y'].apply(parse_y)
data['y']=data['y'].astype(int)
4.3 數據規范化
#數據規范化到正態分布的數據
#測試數據和訓練數據的分割
fromsklearn.preprocessingimportStandardScaler
fromsklearn.model_selectionimporttrain_test_split
ss=StandardScaler()
train_x,test_x,train_y,test_y=train_test_split(data.iloc[:,:-1],
data['y'],
test_size=0.3)
train_x=ss.fit_transform(train_x)
test_x=ss.transform(test_x)
5. 模型訓練
5.1 AdaBoost分類器
fromsklearn.ensembleimportAdaBoostClassifier
fromsklearn.metricsimportaccuracy_score
ada=AdaBoostClassifier()
ada.fit(train_x,train_y)
predict_y=ada.predict(test_x)
print("準確率:",accuracy_score(test_y,predict_y))
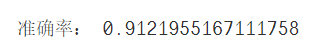
5.2 SVC分類器
fromsklearn.svmimportSVC
svc=SVC()
svc.fit(train_x,train_y)
predict_y=svc.predict(test_x)
print("準確率:",accuracy_score(test_y,predict_y))
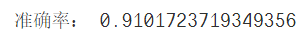
5.3 K鄰近值分類器
fromsklearn.neighborsimportKNeighborsClassifier
knn=KNeighborsClassifier()
knn.fit(train_x,train_y)
predict_y=knn.predict(test_x)
print("準確率:",accuracy_score(test_y,predict_y))
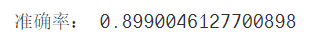
5.4 決策樹分類器
fromsklearn.treeimportDecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(train_x,train_y)
predict_y=dtc.predict(test_x)
print("準確率:",accuracy_score(test_y,predict_y))
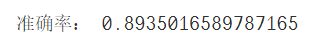
6 模型評價
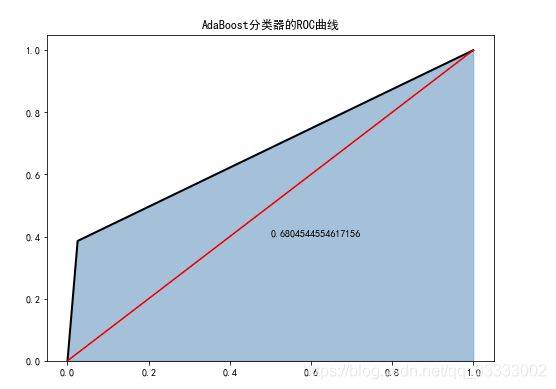
6.1 AdaBoost分類器
fromsklearn.metricsimportroc_curve
fromsklearn.metricsimportauc
plt.figure(figsize=(8,6))
fpr1,tpr1,threshoulds1=roc_curve(test_y,ada.predict(test_x))
plt.stackplot(fpr1,tpr1,color='steelblue',alpha=0.5,edgecolor='black')
plt.plot(fpr1,tpr1,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr1,tpr1))
plt.title('AdaBoost分類器的ROC曲線')
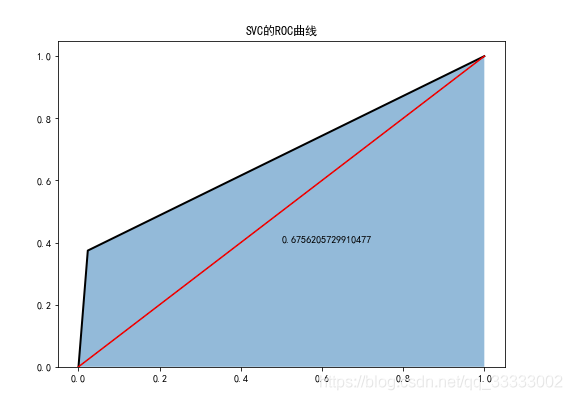
6.2 SVC分類器
plt.figure(figsize=(8,6))
fpr2,tpr2,threshoulds2=roc_curve(test_y,svc.predict(test_x))
plt.stackplot(fpr2,tpr2,alpha=0.5)
plt.plot(fpr2,tpr2,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr2,tpr2))
plt.title('SVD的ROC曲線')
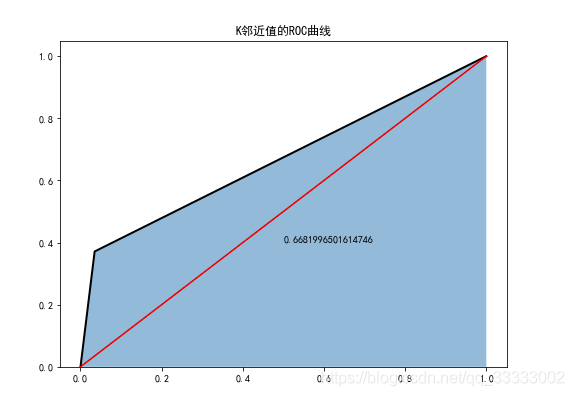
6.3 K鄰近值分類器
plt.figure(figsize=(8,6))
fpr3,tpr3,threshoulds3=roc_curve(test_y,knn.predict(test_x))
plt.stackplot(fpr3,tpr3,alpha=0.5)
plt.plot(fpr3,tpr3,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr3,tpr3))
plt.title('K鄰近值的ROC曲線')
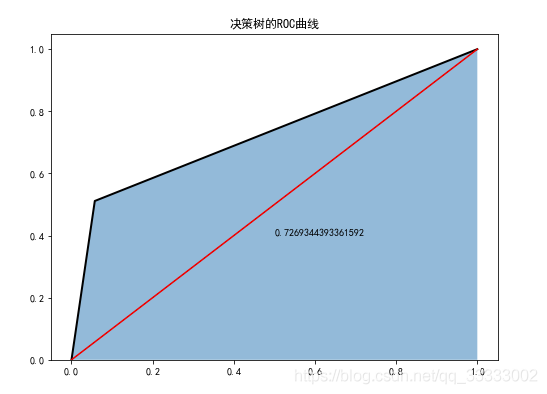
6.4 決策樹分類器
plt.figure(figsize=(8,6))
fpr4,tpr4,threshoulds4=roc_curve(test_y,dtc.predict(test_x))
plt.stackplot(fpr4,tpr4,alpha=0.5)
plt.plot(fpr4,tpr4,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr4,tpr4))
plt.title('決策樹的ROC曲線')
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
算法
+關注
關注
23文章
4619瀏覽量
93041 -
數據分析
+關注
關注
2文章
1452瀏覽量
34076 -
python
+關注
關注
56文章
4798瀏覽量
84801
原文標題:用 Python 算法預測客戶行為案例!
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

如何使用Python實現PID控制
PID控制(比例-積分-微分控制)是一種常見的反饋控制算法,廣泛應用于工業控制系統中。在Python中實現PID控制,我們可以遵循以下步驟: 1. 理解PID控制原理 PID控制器有三個主要參數
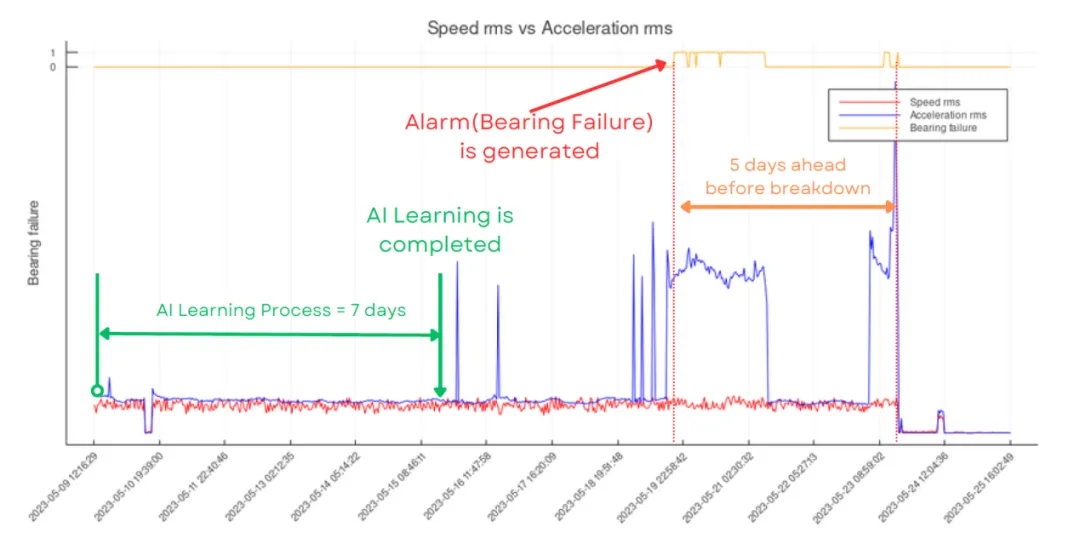
電梯按需維保——“故障預測”算法模型數據分析
梯云物聯的智能AI終端在故障預測算法模型數據分析中扮演著核心角色,其工作流程涵蓋了數據采集、特征提取、模型構建、故障預測與預警等多個環節,形成了一套完整的電梯故障預測解決方案。
旗晟機器人人員行為監督AI智慧算法
,以實現對工業場景巡檢運維的高效化目標。那么,下面我們來談談旗晟機器人AI智慧算法之一——人員行為監督AI智慧算法。 旗晟人員行為監督AI智慧算法

Python建模算法與應用
上成為理想的腳本語言,特別適用于快速的應用程序開發。本文將詳細介紹Python在建模算法中的應用,包括常見的建模算法、Python在建模中的優勢、常用庫以及實際案例。
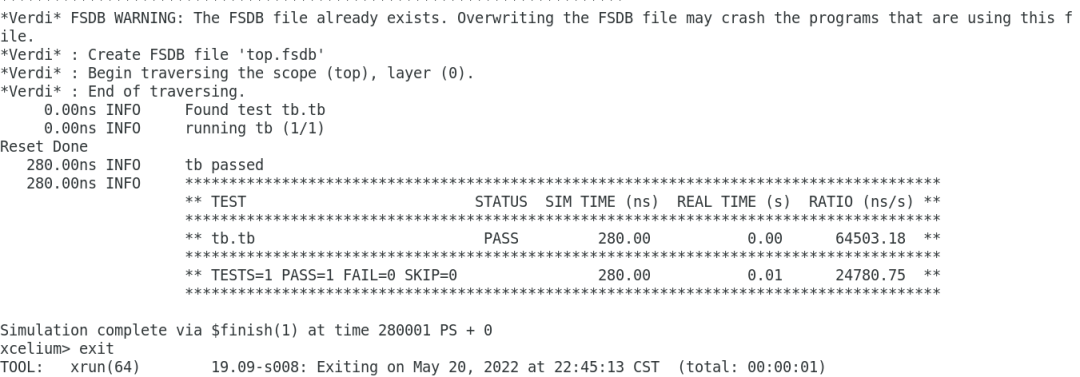
用python寫驗證環境cocotb
本文介紹了cocotb的安裝、python tb文件的寫法、用xrun仿真cocotb的腳本等,我們來看看體驗如何。
如何實現Python復制文件操作
Python 中有許多“開蓋即食”的模塊(比如 os,subprocess 和 shutil)以支持文件 I/O 操作。在這篇文章中,你將會看到一些用 Python 實現文件復制的特殊方法。下面我們開始學習這九種不同的方法來實現
matlab預測模型怎么用
MATLAB預測模型是一種基于統計和數學方法的預測工具,廣泛應用于各種領域,如金融、氣象、生物醫學等。本文將介紹MATLAB預測模型的使用方法。 數據預處理 數據預處理是預測模型建立的
python做bp神經網絡預測數據
BP神經網絡(Backpropagation Neural Network)是一種多層前饋神經網絡,通過反向傳播算法進行訓練。它在許多領域,如模式識別、數據挖掘、預測分析等,都有廣泛的應用。本文將
用pycharm進行python爬蟲的步驟
以下是使用PyCharm進行Python爬蟲的步驟: 安裝PyCharm和Python 首先,您需要安裝PyCharm和Python。PyCharm是一個流行的Python集成開發環境
AI行為識別視頻監控系統 Python
AI行為識別視頻監控系統來自機器視覺技術的革新。機器視覺技術應用是人工智能技術分析的一個支系。它可以在圖形和圖象具體內容敘述中間創建投射關聯,使電腦可以根據圖像處理和剖析比較,進而熟悉視頻圖象中

神經網絡的基本原理及Python編程實現
神經網絡作為深度學習算法的基本構建模塊,模擬了人腦的行為,通過互相連接的節點(也稱為“神經元”)實現對輸入數據的處理、模式識別和結果預測等功能。本文將深入探討神經網絡的基本原理,并結合Pyth
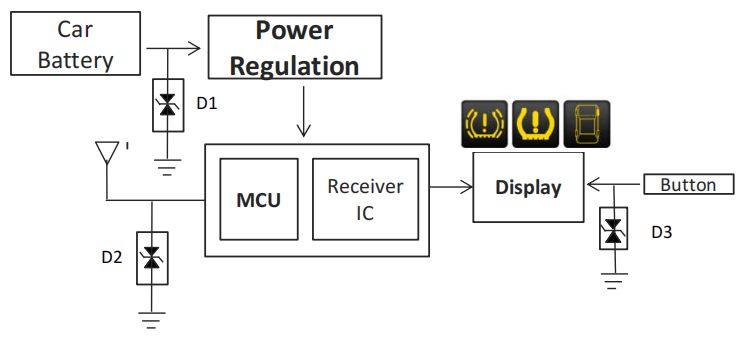
SCG客戶應用ZETA預測性維護方案,精準發現設備故障
故障,從而提升工廠運營效率,降低管理成本。其中,SCG的一個客戶通過采用ZETA預測性維護方案精準提前發現了機器故障,為工廠設備預測性維護樹立了行業標桿。





 工商網監
工商網監
評論