 基于超大感受野注意力的超分辨率模型
基于超大感受野注意力的超分辨率模型
注意力機制是深度學習領域非常重要的一個研究方向,在圖像超分領域也有不少典型的應用案例,比如基于通道注意力構建的RCAN,基于二階注意力機制構建的SAN,基于像素注意力機制構建的PAN,基于Transformer自注意力機制構建的SwinIR,基于多尺度大核注意力的MAN等。
本文則以PAN為藍本,對其進行逐步改進以期達到更少的參數量、更高的超分性能。該方案具體包含以下幾個關鍵點:
- 提升注意力分割的感受野,類似大核卷積注意力VAN;
- 將稠密卷積核替換為深度分離卷積,進一步降低參數量;
- 引入像素規范化(Pixel Normalization)技術,其實就是Layer Normalization,但出發點不同。
上述關鍵技術點為注意力機制的設計提供了一個清晰的演變路線,最終得到了本文的VapSR,即大感受像素注意力網絡(VAst-receptive-field Pixel attention Network)。
實驗結果表明:相比其他輕量超分網絡,VapSR具有更少的參數量。比如,項目IMDB與RFDN,VapSR僅需21.68%、28.18%的參數即可取得與之相當的性能。
本文動機
通過引入像素注意力,PAN在大幅降低參數量的同時取得了非常優秀的性能。相比通道注意力與空域注意力,像素注意力是一種更廣義的注意力形式,為進一步的探索提供了一個非常好的基線。
受啟發于自注意力的發展,我們認為:基于卷積操作的注意力仍有進一步改進的空間。因此,作者通過以下三個像素注意力中的設計原則展示了改善超分注意力的過程:
- 首先,在注意力分支引入大核卷積具有明顯的優勢;
- 其次,深度分離卷積可以降低大核卷積導致的巨大計算復雜度問題;
- 最后,引入像素規范化操作讓訓練更高效、更穩定。
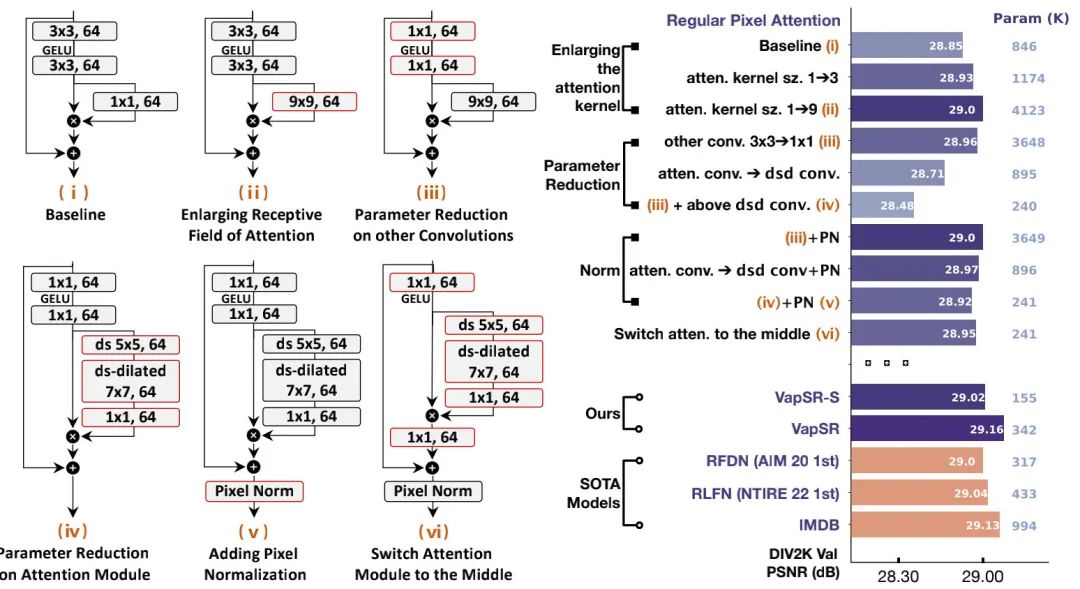
**Large Kernel **以上圖i中的baseline為基礎,作者首先對注意力分支進行感受野擴增:將提升到(將圖示ii),性能提升0.15dB,但參數量從846K提升到了4123K。
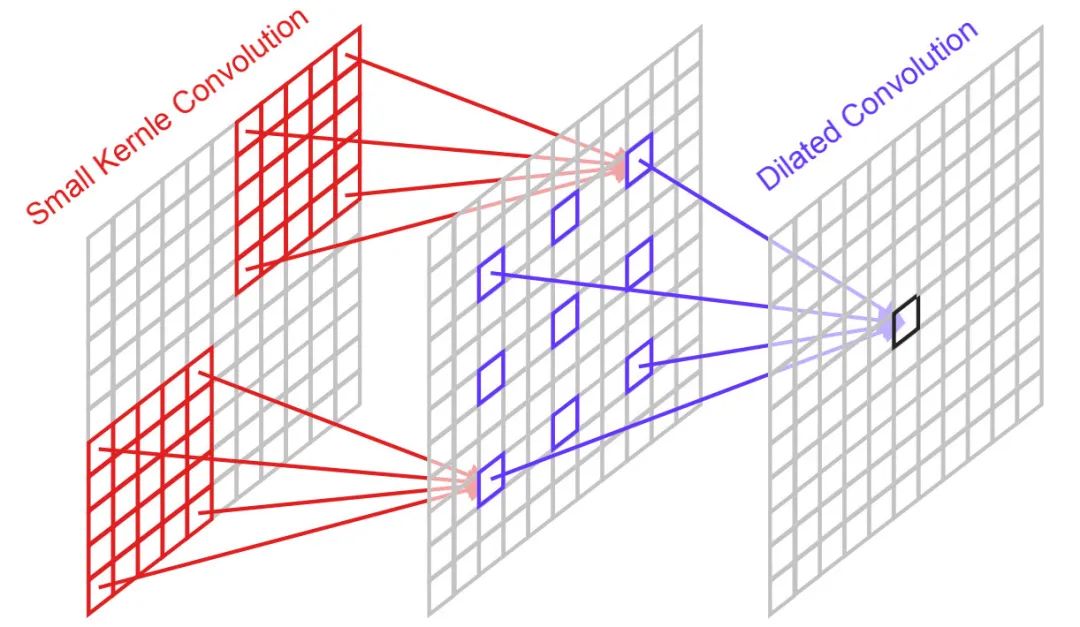
Parameter Reduction 為降低參數量,我們嘗試盡可能移除相對不重要的部分。作者提出了三個方案:(1) 將非注意力分支的卷積尺寸從下調到;(2) 將大核卷積注意力分支替換為深度深度分離卷積;(3) 將深度分離卷積中的深度卷積進行分解為深度卷積+帶擴張因子的深度卷積(該機制可參考下圖,將卷積拆分為+,其中后者的擴張因子為3)。此時,模型性能變為28.48dB,但參數量降到了240K,參數量基本被壓縮到了極限。
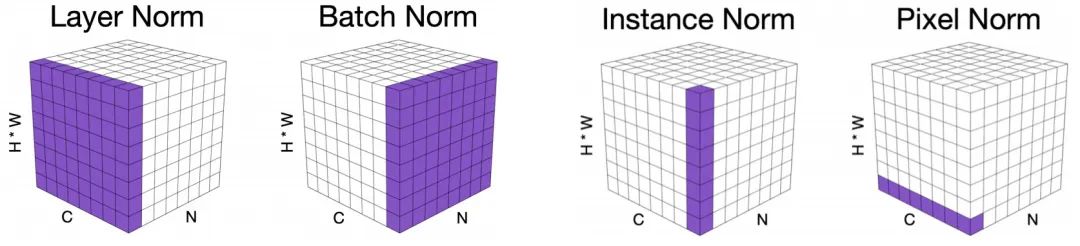
Pixel Normalization(PN) 注意力機制的元素乘操作會導致訓練不穩定問題:小學習率收斂不夠好,大學習率又會出現梯度異常。前面的注意力改進導致所得方案存在性能下降問題。為解決該問題,作者經深入分析后提出了像素規范化技術(可參考下圖不同規范化技術的可視化對比)。
假設輸入特征為,第i個像素的特征均值與方差可以描述如下:
那么,像素規范化可以表示為:
當引入PN后,模型的性能取得了顯著的提升,達到了28.92dB,參數量僅為241K。
Switch Attention to Middle 在上述基礎上,作者進一步將注意力的位置進行了調整,放到了兩個卷積中間。此時,模型性能得到了0.03dB提升,達到了28.95dB,參數量仍為241K。
本文方案
前面的探索主要聚焦在微觀層面,基于此,作者進一步在宏觀層面進行了更多設計與提煉,進而構建了VapSR,取得了更佳的性能,同時具有更少的參數量。
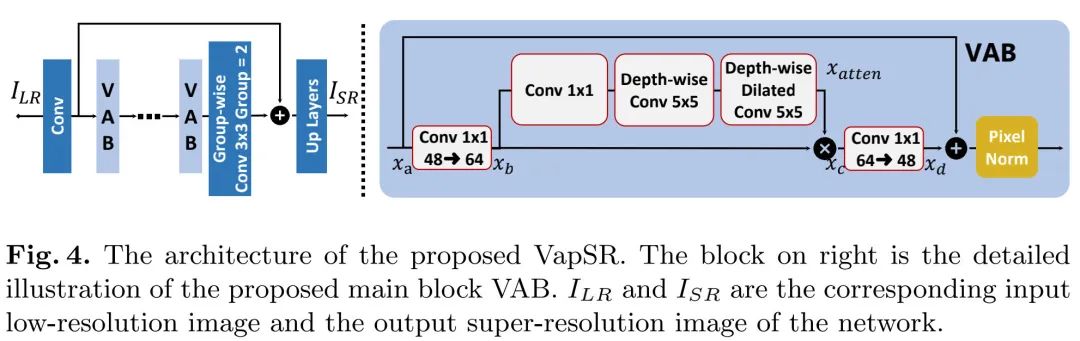
上圖給出了所提VapSR架構示意圖,延續了常規輕量方案的設計思路:
- 淺層特征:;
- 非線性映射: ;
- 圖像重建:
VAB模塊在前面探索得到的模塊上進行了微調:(1) 主要是將模塊輸入與輸出通道數從64減少到了48,保持中間注意力部分的通道數仍為64;(2) 將注意力分支深度擴張卷積(有時也稱之為空洞卷積)調整為深度擴張卷積,此時感受野為;(3) 調整了注意力分支三個卷積的順序,將卷積移到最前面。對于VapSR-S,作者進一步將部分從卷積調整為組卷積(group=2),該操作可以進一步降低參數量。
classAttention(nn.Module):
def__init__(self,dim):
super().__init__()
self.pointwise=nn.Conv2d(dim,dim,1)
self.depthwise=nn.Conv2d(dim,dim,5,padding=2,groups=dim)
self.depthwise_dilated=nn.Conv2d(dim,dim,5,1,padding=6,groups=dim,dilation=3)
defforward(self,x):
u=x.clone()
attn=self.pointwise(x)
attn=self.depthwise(attn)
attn=self.depthwise_dilated(attn)
returnu*attn
classVAB(nn.Module):
def__init__(self,d_model,d_atten):
super().__init__()
self.proj_1=nn.Conv2d(d_model,d_atten,1)
self.activation=nn.GELU()
self.atten_branch=Attention(d_atten)
self.proj_2=nn.Conv2d(d_atten,d_model,1)
self.pixel_norm=nn.LayerNorm(d_model)
default_init_weights([self.pixel_norm],0.1)
defforward(self,x):
shorcut=x.clone()
x=self.proj_1(x)
x=self.activation(x)
x=self.atten_branch(x)
x=self.proj_2(x)
x=x+shorcut
x=x.permute(0,2,3,1)#(B,H,W,C)
x=self.pixel_norm(x)
x=x.permute(0,3,1,2).contiguous()#(B,C,H,W)
returnx
本文實驗
在實驗部分,作者構建了VapSR與VapSR-S兩個版本的輕量型超分方案:
- VapSR:包含21個VAB模塊,主干通道數為48;
- VapSR-S:包含11個VAB模塊,主干通道數為32。
此外,需要注意的是:對于X4模型,重建模塊并未采用常規的輕量方案(Conv+PS),而是采用了類EDSR的重方案(Conv+PS+Conv+PS)。
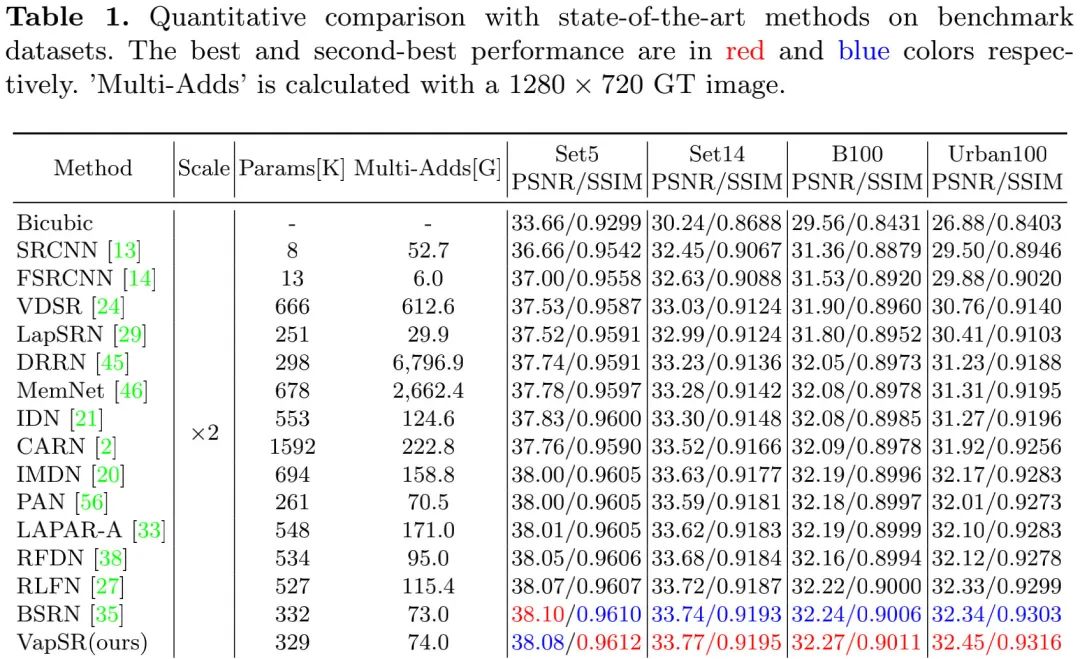
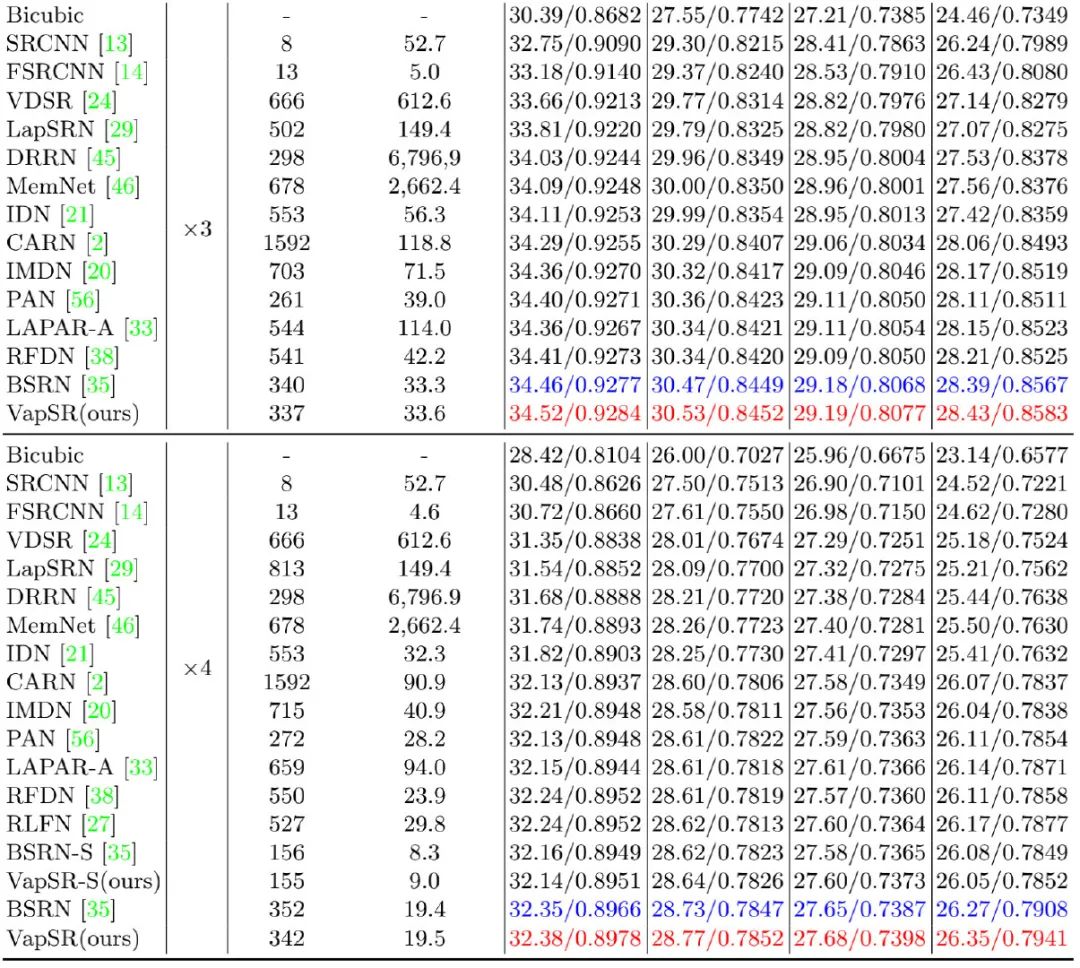

上表&圖給出了不同方案的性能與可視化效果對比,從中可以看到:
- 所提VapSR取得了SOTA性能,同時具有非常少的參數量。
- 在X4任務上,相比RFDN與IMDN,VapSR僅需21.68%/28.18%的參數量,即可取得平均0.187dB指標提升;
- VapSR-S取得了與BSRN-S相當的性能,后者是NTIRE2022-ESR模型復雜度賽道冠軍。
- 在線條重建方面,VapSR具有比其他方案更精確的重建效果。
審核編輯 :李倩
-
分辨率
+關注
關注
2文章
1068瀏覽量
41962 -
模型
+關注
關注
1文章
3261瀏覽量
48914 -
深度學習
+關注
關注
73文章
5507瀏覽量
121272
原文標題:董超團隊提出VapSR:基于超大感受野注意力的超分辨率模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何提高透鏡成像的分辨率
如何選擇掃描電鏡的分辨率?

HDMI接口支持哪些視頻分辨率
視頻處理器的分辨率是如何管理的

微軟發布DirectSR新預覽版:整合FSR 3.1超分辨率技術

Arm精銳超級分辨率技術解析

什么是高分辨率示波器?它有哪些優勢?
VR顯示器分辨率的選擇
基于CNN的圖像超分辨率示例
華為pockets屏幕分辨率是多少
EVAL_PASCO2_SENSOR為什么無法從較低的分辨率高速獲得更高的分辨率?
編碼器分辨率是什么意思 編碼器分辨率和脈沖數的關系






 工商網監
工商網監
評論