


1. 前言
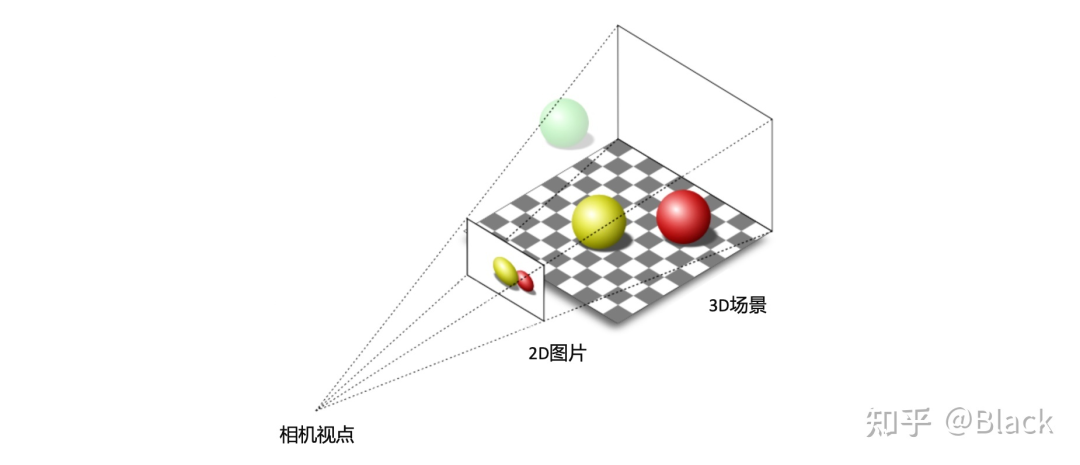
做為被動傳感器的相機,其感光元件僅接收物體表面反射的環境光,3D場景經投影變換呈現在2D像平面上,成像過程深度信息丟失了。而當我們僅有圖片時,想要估計物體在真實3D場景中所處的位置,這將是一個欠約束的問題。
2. 幾何求解
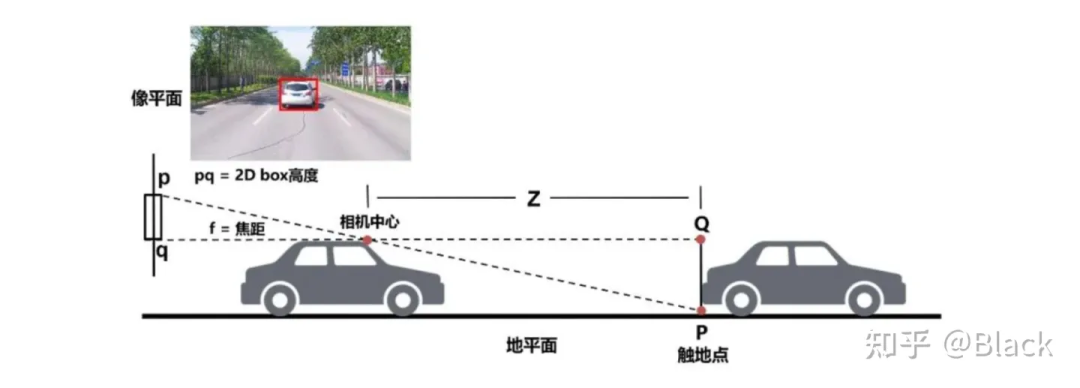
分類、2D目標檢測等圖像任務已經在工業界得到廣泛應用,可以認為是已經解決了的問題,并且數據價格低廉。但2D目標框無法滿足自動駕駛、機器人等對障礙物有定位需求的領域。傳統算法利用2D檢測框的底部中心點,基于平面假設,求解近似三角形來獲得目標離自車的距離。這類方法簡單輕量,數據驅動的部分僅限于2D目標檢測部分,但對地面有較強的假設,面對車輛顛簸敏感(俯仰角變化),且對2D檢測框的完整性有較強的依賴。
3. 單目3D目標檢測
隨著標注方法的升級,目標的表示由原來的2D框對角點表示 進化成了3D坐標系下bounding box的表示 ,不同緯度表示了3D框的位置、尺寸、以及地面上的偏航角。有了數據,原本用于2D檢測的深度神經網絡,也可以依靠監督學習用于3D目標框檢測。
這樣的3D數據業界目前主要有兩種獲取方式,一種是車輛除了配備了相機,同時安裝了LiDAR這樣的3D傳感器,經掃描,目標輪廓以點云的形式被記錄下來,標注員主要看點云來標注。另一種是像特斯拉這樣僅配備相機的車輛,收集的只有圖像數據,依靠多種交叉驗證的離線算法,輔以人工來生成3D標注數據。
焦距適中的相機,FOV是有限的,想要檢測車身 目標,就要部署多個相機,每個相機負責一定FOV范圍內的感知。最終將各相機的檢測結果通過相機到車身的外參,轉換到統一的車輛坐標系下。
但在有共視時,會產生冗余檢測,即有多個攝像頭對同一目標做了預測,現有方法,如FCOS3D,會在統一的坐標系下對所有檢測結果做一遍NMS,有重合的目標框僅留下一個分類指標得分最高的。
冗余問題得到緩解,但要命的是被截斷的目標往往在任一個相機里都只出現了一部分,多數情況是每個相機下的檢測質量都堪憂。原因是多相機的圖片在深度神經網絡是以 的形式傳遞的,傳統網絡中會有緯度 的特征間交互,也會有緯度 的空間交互,但唯獨沒有不同圖片間batch緯度的交互。簡單來說就是下圖中左邊圖片在檢測黑色客車時,是無法用到右邊圖片的信息的。

4. 統一多視角相機的3D目標檢測
4.1 看到哪算哪
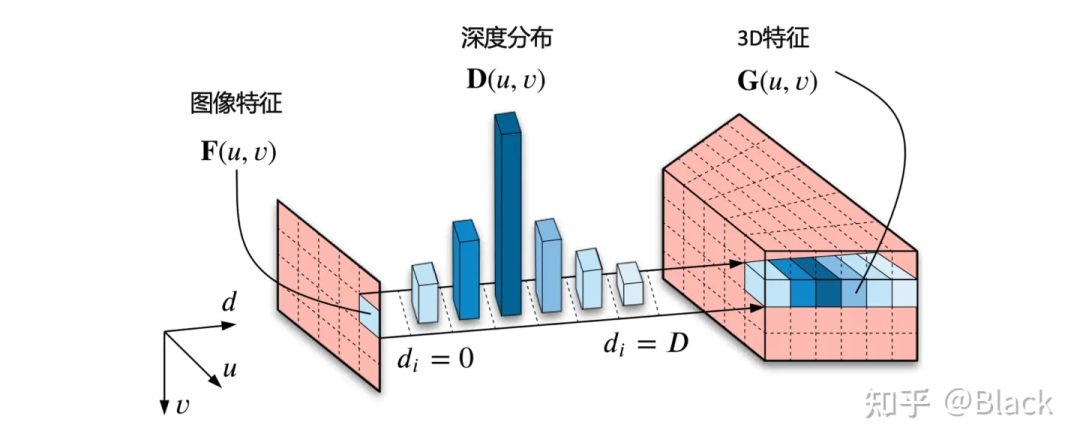
自下而上的方法,手頭的信息看到哪算哪。下圖來自CaDNN這篇文章,很好的描述了這一類方法,包括Lift、BEVDet、BEVDepth。這類方法預測每個像素的深度/深度分布,有的方法隱式的預測,有的方法利用LiDAR點云當監督信號(推理時沒有LiDAR),雖然只用在訓練階段,但不太能算在純視覺的方法里比較精度,工程使用的時候可能涉及部署車輛和數據采集車輛割裂的尷尬。總之,有了深度就可以由相機內外參計算此像素在3D空間中的位置,然后把圖像特征塞入對應位置。可以理解為由圖片生成3D“點云”,多視角相機形成的“點云”拼在一起,有了“點云”就可以利用現有的點云3D目標檢測器了(如PointPillars, CenterPoint)。
4.2 先決定看哪
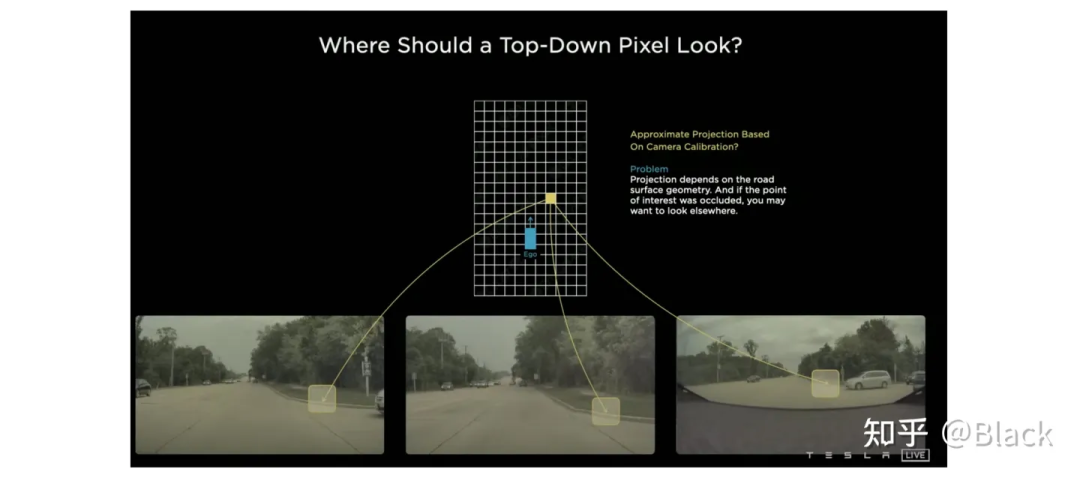
自上而下的方法,先確定關注的地方(但可能手頭不寬裕,不配關注這個地方... 比如想關注自車后方,可后方視野完全被一輛大車遮擋了的情況)。關于這類的方法,下圖碰瓷一下特斯拉,簡單來說就是先確定空間中要關注的位置(圖中網格代表的車身周圍的地方),由這些位置去各個圖像中“搜集”特征,然后做判斷。根據“搜集”方式的不同衍生出了下面幾種方法。
4.2.1 關鍵點采樣
下圖來自DETR3D,其作為將DETR框架用于3D目標的先鋒工作,由一群可學習的3D空間中離散的位置(包含于object queries),根據相機內外參轉換投影到圖片上,來索引圖像特征,每個3D位置僅對應一個像素坐標(會提取不同尺度特征圖的特征)。
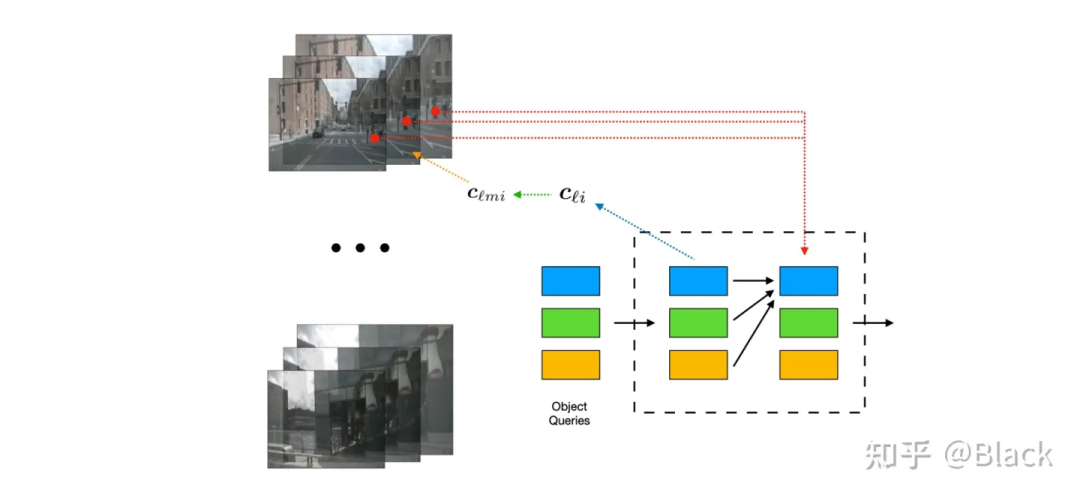
4.2.2 局部注意力
下圖來自BEVFormer,該方法預先生成稠密的空間位置(含不同的高度,且不隨訓練更新),每個位置投影到各圖片后,會和投影位置局部的數個像素塊發生交互來提取特征(基于deformable detr),相比于DETR3D,每個3D點可以提取到了更多的特征。最終提取的3D稠密特征圖在高度緯度會被壓扁,形成一張BEV視角下稠密的2D特征圖,后續基于此特征圖做目標檢測。BEVFormer相比DETR3D在精度上有提升(結構上也多了額外的BEV decoders),在BEV視角下,目標尺度被統一了,不會出現圖像視角下目標近大遠小的問題。一張稠密的BEV特征圖還可以做車道線檢測/道路分割等任務,缺點是計算量大,顯存占用大。
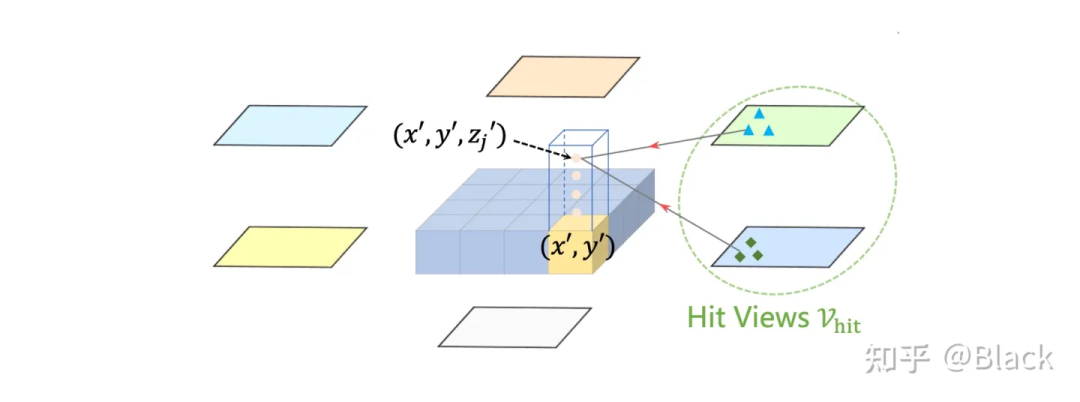
4.2.3 全局注意力
典型方法如PETR,該方法強調保持2D目標檢測器DETR的框架,探索3D檢測需要做哪些適配。PETR同樣利用稀疏的3D點(來自object queries)來“搜索”圖像特征,但不像DETR3D或BEVFormer把3D點投影回圖片,而是基于標準的attention模塊,每個3D點會和來自全部圖片的所有像素交互。相似度(attention matrix)計算遵循 ,其中 來自object queries,里面包含的信息和3D bounding box的信息強相關(暫不討論query也包含的表觀信息),而 來自圖像(可以理解為和RGB信息強相關,原生DETR中還會加入像素位置編碼),這兩個向量計算相似度缺乏可解釋性(直接訓練也不怎么work)。可以理解為下圖描述的場景,很難說一個3D框和哪個像素相似。

PETR對矩陣下手,為每個像素編碼了3D位置相關的信息,使得相似度得以計算。實現上簡單來說是相機光心到像素的射線上每隔一段距離采樣一個點的 ,并轉換到query坐標系下。相比之下,DETR3D和BEVFormer都遵循了deformable detr的方式,由query預測權重來加權“搜集”來的特征,規避掉了點積相似度的計算,PETR是正面硬剛這個問題了屬于是。下圖是PETR單位置編碼相似度效果圖(達到了跨相機相似的效果),只是這個相似度是“虛假”的,跟真實場景沒關系,也不會變化。很快,PETRv2中加上了圖像特征,效果也有提升。不過全局注意力算力消耗巨大,PETR只用了單尺度特征圖,一般顯卡還需利用混合精度、checkpoint等降顯存的方法才能訓練起來。
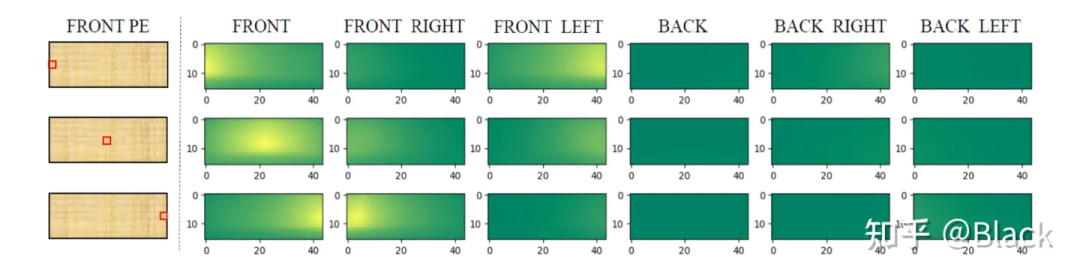
-
3D
+關注
關注
9文章
2960瀏覽量
110916 -
神經網絡
+關注
關注
42文章
4814瀏覽量
103916 -
自動駕駛
+關注
關注
790文章
14349瀏覽量
170935
原文標題:3D目標檢測 | 視覺3D目標檢測,從視覺幾何到BEV檢測
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
為何PCB設計需要3D功能?
哪些適配器需要做CCC認證?
高精度3D掃描如何實現?
基于ToF的3D活體檢測算法研究
探索如何打開我國3D打印的應用之路
3DSYS公布了Figure4 3D打印機的材料參數
探索3D打印PCB的潛力
矩子科技的3D檢測業務水平如何?
3D視覺相機板材瑕疵檢測(窄)說明

為什么要選擇3D機器視覺檢測
電柜3D布局需要滿足哪些條件?
如何搞定自動駕駛3D目標檢測!






 工商網監
工商網監

評論