 YOLOv5網絡結構解析
YOLOv5網絡結構解析
本教程涉及到的代碼在 https://github.com/Oneflow-Inc/one-yolov5 ,教程也同樣適用于 ultralytics/yolov5 因為 one-yolov5 僅僅是換了一個運行時后端而已,計算邏輯和代碼相比于 ultralytics/yolov5 沒有做任何改變,歡迎 star 。詳細信息請看One-YOLOv5 發布,一個訓得更快的YOLOv5
YOLOv5 網絡結構解析
引言
YOLOv5針對不同大小(n, s, m, l, x)的網絡整體架構都是一樣的,只不過會在每個子模塊中采用不同的深度和寬度,
分別應對yaml文件中的depth_multiple和width_multiple參數。
還需要注意一點,官方除了n, s, m, l, x版本外還有n6, s6, m6, l6, x6,區別在于后者是針對更大分辨率的圖片比如1280x1280,
當然結構上也有些差異,前者只會下采樣到32倍且采用3個預測特征層 , 而后者會下采樣64倍,采用4個預測特征層。
本章將以 yolov5s為例 ,從配置文件 models/yolov5s.yaml(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml) 到 models/yolo.py(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py) 源碼進行解讀。
yolov5s.yaml文件內容:
nc:80#numberofclasses數據集中的類別數
depth_multiple:0.33#modeldepthmultiple模型層數因子(用來調整網絡的深度)
width_multiple:0.50#layerchannelmultiple模型通道數因子(用來調整網絡的寬度)
#如何理解這個depth_multiple和width_multiple呢?它決定的是整個模型中的深度(層數)和寬度(通道數),具體怎么調整的結合后面的backbone代碼解釋。
anchors:#表示作用于當前特征圖的Anchor大小為xxx
#9個anchor,其中P表示特征圖的層級,P3/8該層特征圖縮放為1/8,是第3層特征
-[10,13,16,30,33,23]#P3/8,表示[10,13],[16,30],[33,23]3個anchor
-[30,61,62,45,59,119]#P4/16
-[116,90,156,198,373,326]#P5/32
#YOLOv5sv6.0backbone
backbone:
#[from,number,module,args]
[[-1,1,Conv,[64,6,2,2]],#0-P1/2
[-1,1,Conv,[128,3,2]],#1-P2/4
[-1,3,C3,[128]],
[-1,1,Conv,[256,3,2]],#3-P3/8
[-1,6,C3,[256]],
[-1,1,Conv,[512,3,2]],#5-P4/16
[-1,9,C3,[512]],
[-1,1,Conv,[1024,3,2]],#7-P5/32
[-1,3,C3,[1024]],
[-1,1,SPPF,[1024,5]],#9
]
#YOLOv5sv6.0head
head:
[[-1,1,Conv,[512,1,1]],
[-1,1,nn.Upsample,[None,2,'nearest']],
[[-1,6],1,Concat,[1]],#catbackboneP4
[-1,3,C3,[512,False]],#13
[-1,1,Conv,[256,1,1]],
[-1,1,nn.Upsample,[None,2,'nearest']],
[[-1,4],1,Concat,[1]],#catbackboneP3
[-1,3,C3,[256,False]],#17(P3/8-small)
[-1,1,Conv,[256,3,2]],
[[-1,14],1,Concat,[1]],#catheadP4
[-1,3,C3,[512,False]],#20(P4/16-medium)
[-1,1,Conv,[512,3,2]],
[[-1,10],1,Concat,[1]],#catheadP5
[-1,3,C3,[1024,False]],#23(P5/32-large)
[[17,20,23],1,Detect,[nc,anchors]],#Detect(P3,P4,P5)
]
anchors 解讀
yolov5 初始化了 9 個 anchors,分別在三個特征圖(feature map)中使用,每個 feature map 的每個 grid cell 都有三個 anchor 進行預測。分配規則:
-
尺度越大的 feature map 越靠前,相對原圖的下采樣率越小,感受野越小,所以相對可以預測一些尺度比較小的物體(小目標),分配到的 anchors 越小。
-
尺度越小的 feature map 越靠后,相對原圖的下采樣率越大,感受野越大,所以可以預測一些尺度比較大的物體(大目標),所以分配到的 anchors 越大。
-
即在小特征圖(feature map)上檢測大目標,中等大小的特征圖上檢測中等目標, 在大特征圖上檢測小目標。
backbone & head解讀
[from, number, module, args] 參數
四個參數的意義分別是:
- 第一個參數 from :從哪一層獲得輸入,-1表示從上一層獲得,[-1, 6]表示從上層和第6層兩層獲得。
- 第二個參數 number:表示有幾個相同的模塊,如果為9則表示有9個相同的模塊。
- 第三個參數 module:模塊的名稱,這些模塊寫在common.py中。
- 第四個參數 args:類的初始化參數,用于解析作為 moudle 的傳入參數。
下面以第一個模塊Conv 為例介紹下common.py中的模塊
Conv 模塊定義如下:
classConv(nn.Module):
#Standardconvolution
def__init__(self,c1,c2,k=1,s=1,p=None,g=1,act=True):#ch_in,ch_out,kernel,stride,padding,groups
"""
@Pargmc1:輸入通道數
@Pargmc2:輸出通道數
@Pargmk:卷積核大小(kernel_size)
@Pargms:卷積步長(stride)
@Pargmp:特征圖填充寬度(padding)
@Pargmg:控制分組,必須整除輸入的通道數(保證輸入的通道能被正確分組)
"""
super().__init__()
#https://oneflow.readthedocs.io/en/master/generated/oneflow.nn.Conv2d.html?highlight=Conv
self.conv=nn.Conv2d(c1,c2,k,s,autopad(k,p),groups=g,bias=False)
self.bn=nn.BatchNorm2d(c2)
self.act=nn.SiLU()ifactisTrueelse(actifisinstance(act,nn.Module)elsenn.Identity())
defforward(self,x):
returnself.act(self.bn(self.conv(x)))
defforward_fuse(self,x):
returnself.act(self.conv(x))
比如上面把width_multiple設置為了0.5,那么第一個 [64, 6, 2, 2] 就會被解析為 [3,64*0.5=32,6,2,2],其中第一個 3 為輸入channel(因為輸入),32 為輸出channel。
關于調整網絡大小的詳解說明
在yolo.py(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py)的256行 有對yaml 文件的nc,depth_multiple等參數讀取,具體代碼如下:
anchors,nc,gd,gw=d['anchors'],d['nc'],d['depth_multiple'],d['width_multiple']
"width_multiple"參數的作用前面介紹args參數中已經介紹過了,那么"depth_multiple"又是什么作用呢?
在yolo.py(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py)的257行有對參數的具體定義:
n=n_=max(round(n*gd),1)ifn>1elsen#depthgain暫且將這段代碼當作公式(1)
其中 gd 就是depth_multiple的值,n的值就是backbone中列表的第二個參數:
根據公示(1) 很容易看出 gd 影響 n 的大小,從而影響網絡的結構大小。
后面各層之間的模塊數量、卷積核大小和數量等也都產生了變化,YOLOv5l 與 YOLOv5s 相比較起來訓練參數的大小成倍數增長,
其模型的深度和寬度也會大很多,這就使得 YOLOv5l 的 精度值要比 YOLOv5s 好很多,因此在最終推理時的檢測精度高,但是模型的推理速度更慢。
所以 YOLOv5 提供了不同的選擇,如果想要追求推理速度可選用較小一些的模型如 YOLOv5s、YOLOv5m,如果想要追求精度更高對推理速度要求不高的可以選擇其他兩個稍大的模型。
如下面這張圖:
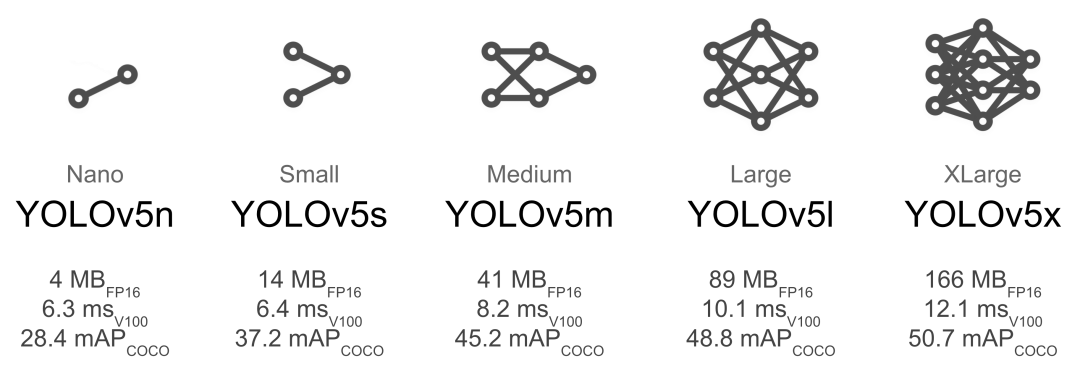 yolov5模型復雜度比較圖
yolov5模型復雜度比較圖Conv模塊解讀
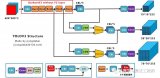
網絡結構預覽
下面是根據yolov5s.yaml(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml)繪制的網絡整體結構簡化版。
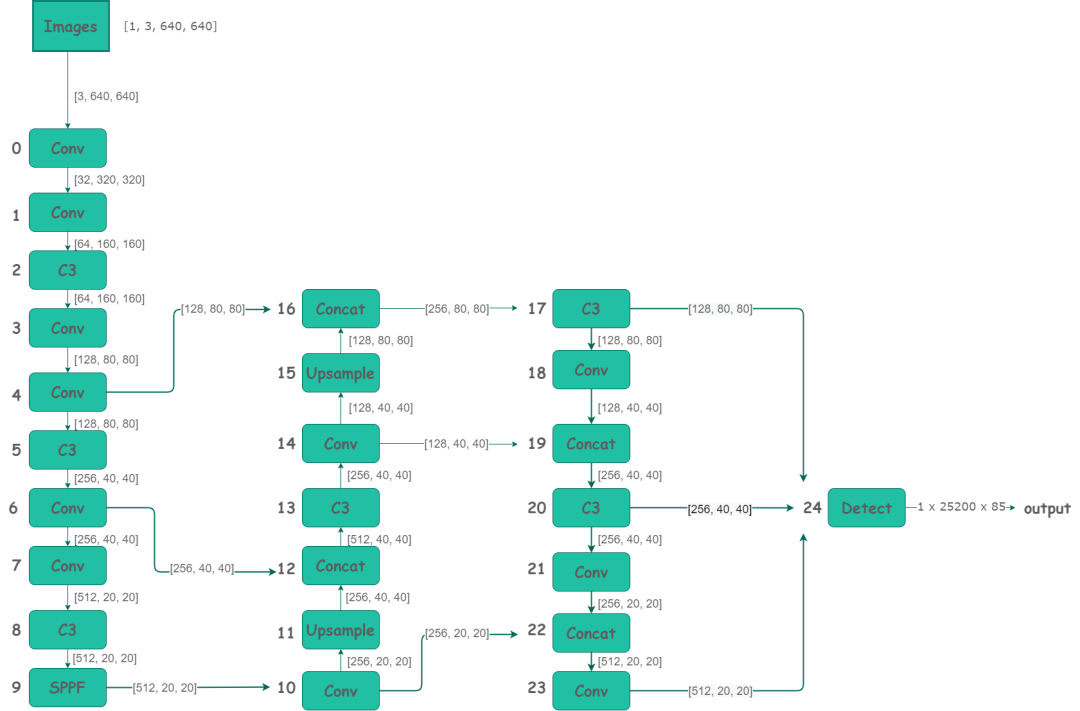 yolov5s網絡整體結構圖
yolov5s網絡整體結構圖-
詳細的網絡結構圖:https://oneflow-static.oss-cn-beijing.aliyuncs.com/one-yolo/imgs/yolov5s.onnx.png通過export.py導出的onnx格式,并通過 https://netron.app/ 網站導出的圖片(模型導出將在本教程的后續文章單獨介紹)。
-
模塊組件右邊參數 表示特征圖的的形狀,比如 在 第 一 層( Conv )輸入 圖片形狀為 [ 3, 640, 640] ,關于這些參數,可以固定一張圖片輸入到網絡并通過yolov5s.yaml(
https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml)的模型參數計算得到,并且可以在工程 models/yolo.py(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py) 通過代碼進行print查看,詳細數據可以參考附件表2.1。
yolo.py解讀
文件地址(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py)
文件主要包含 三大部分: Detect類, Model類,和 parse_model 函數
可以通過 python models/yolo.py --cfg yolov5s.yaml 運行該腳本進行觀察
parse_model函數解讀
defparse_model(d,ch):#model_dict,input_channels(3)
"""用在下面Model模塊中
解析模型文件(字典形式),并搭建網絡結構
這個函數其實主要做的就是:更新當前層的args(參數),計算c2(當前層的輸出channel)=>
使用當前層的參數搭建當前層=>
生成layers+save
@Paramsd:model_dict模型文件字典形式{dict:7}[yolov5s.yaml](https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml)中的6個元素+ch
#Paramsch:記錄模型每一層的輸出channel初始ch=[3]后面會刪除
@returnnn.Sequential(*layers):網絡的每一層的層結構
@returnsorted(save):把所有層結構中from不是-1的值記下并排序[4,6,10,14,17,20,23]
"""
LOGGER.info(f"
{'':>3}{'from':>18}{'n':>3}{'params':>10}{'module':<40}{'arguments':<30}")
#讀取d字典中的anchors和parameters(nc、depth_multiple、width_multiple)
anchors,nc,gd,gw=d['anchors'],d['nc'],d['depth_multiple'],d['width_multiple']
#na:numberofanchors每一個predicthead上的anchor數=3
na=(len(anchors[0])//2)ifisinstance(anchors,list)elseanchors#numberofanchors
no=na*(nc+5)#numberofoutputs=anchors*(classes+5)每一個predicthead層的輸出channel
#開始搭建網絡
#layers:保存每一層的層結構
#save:記錄下所有層結構中from中不是-1的層結構序號
#c2:保存當前層的輸出channel
layers,save,c2=[],[],ch[-1]#layers,savelist,chout
#enumerate()函數用于將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,同時列出數據和數據下標,一般用在for循環當中。
fori,(f,n,m,args)inenumerate(d['backbone']+d['head']):#from,number,module,args
m=eval(m)ifisinstance(m,str)elsem#evalstrings
forj,ainenumerate(args):
#args是一個列表,這一步把列表中的內容取出來
withcontextlib.suppress(NameError):
args[j]=eval(a)ifisinstance(a,str)elsea#evalstrings
#將深度與深度因子相乘,計算層深度。深度最小為1.
n=n_=max(round(n*gd),1)ifn>1elsen#depthgain
#如果當前的模塊m在本項目定義的模塊類型中,就可以處理這個模塊
ifmin(Conv,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,DWConv,MixConv2d,Focus,CrossConv,
BottleneckCSP,C3,C3TR,C3SPP,C3Ghost,nn.ConvTranspose2d,DWConvTranspose2d,C3x):
#c1:輸入通道數c2:輸出通道數
c1,c2=ch[f],args[0]
#該層不是最后一層,則將通道數乘以寬度因子也就是說,寬度因子作用于除了最后一層之外的所有層
ifc2!=no:#ifnotoutput
#make_divisible的作用,使得原始的通道數乘以寬度因子之后取整到8的倍數,這樣處理一般是讓模型的并行性和推理性能更好。
c2=make_divisible(c2*gw,8)
#將前面的運算結果保存在args中,它也就是這個模塊最終的輸入參數。
args=[c1,c2,*args[1:]]
#根據每層網絡參數的不同,分別處理參數具體各個類的參數是什么請參考它們的__init__方法這里不再詳細解釋了
ifmin[BottleneckCSP,C3,C3TR,C3Ghost,C3x]:
#這里的意思就是重復n次,比如conv這個模塊重復n次,這個n是上面算出來的depth
args.insert(2,n)#numberofrepeats
n=1
elifmisnn.BatchNorm2d:
args=[ch[f]]
elifmisConcat:
c2=sum(ch[x]forxinf)
elifmisDetect:
args.append([ch[x]forxinf])
ifisinstance(args[1],int):#numberofanchors
args[1]=[list(range(args[1]*2))]*len(f)
elifmisContract:
c2=ch[f]*args[0]**2
elifmisExpand:
c2=ch[f]//args[0]**2
else:
c2=ch[f]
#構建整個網絡模塊這里就是根據模塊的重復次數n以及模塊本身和它的參數來構建這個模塊和參數對應的Module
m_=nn.Sequential(*(m(*args)for_inrange(n)))ifn>1elsem(*args)#module
#獲取模塊(moduletype)具體名例如models.common.Conv,models.common.C3,models.common.SPPF等。
t=str(m)[8:-2].replace('__main__.','')#replace函數作用是字符串"__main__"替換為'',在當前項目沒有用到這個替換。
np=sum(x.numel()forxinm_.parameters())#numberparams
m_.i,m_.f,m_.type,m_.np=i,f,t,np#attachindex,'from'index,type,numberparams
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f}{t:<40}{str(args):<30}')#print
"""
如果x不是-1,則將其保存在save列表中,表示該層需要保存特征圖。
這里x%i與x等價例如在最后一層:
f=[17,20,23],i=24
y=[x%iforxin([f]ifisinstance(f,int)elsef)ifx!=-1]
print(y)#[17,20,23]
#寫成x%i可能因為:i-1=-1%i(比如f=[-1],則[x%iforxinf]代表[11])
"""
save.extend(x%iforxin([f]ifisinstance(f,int)elsef)ifx!=-1)#appendtosavelist
layers.append(m_)
ifi==0:#如果是初次迭代,則新創建一個ch(因為形參ch在創建第一個網絡模塊時需要用到,所以創建網絡模塊之后再初始化ch)
ch=[]
ch.append(c2)
#將所有的層封裝為nn.Sequential,對保存的特征圖排序
returnnn.Sequential(*layers),sorted(save)
Model 類解讀
classModel(nn.Module):
#YOLOv5model
def__init__(self,cfg='[yolov5s.yaml](https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml)',ch=3,nc=None,anchors=None):#model,inputchannels,numberofclasses
super().__init__()
#如果cfg已經是字典,則直接賦值,否則先加載cfg路徑的文件為字典并賦值給self.yaml。
ifisinstance(cfg,dict):
self.yaml=cfg#modeldict
else:#is*.yaml加載yaml模塊
importyaml#forflowhub
self.yaml_file=Path(cfg).name
withopen(cfg,encoding='ascii',errors='ignore')asf:
self.yaml=yaml.safe_load(f)#modeldict從yaml文件中加載出字典
#Definemodel
#ch:輸入通道數。假如self.yaml有鍵‘ch’,則將該鍵對應的值賦給內部變量ch。假如沒有‘ch’,則將形參ch賦給內部變量ch
ch=self.yaml['ch']=self.yaml.get('ch',ch)#inputchannels
#假如yaml中的nc和方法形參中的nc不一致,則覆蓋yaml中的nc。
ifncandnc!=self.yaml['nc']:
LOGGER.info(f"Overridingmodel.yamlnc={self.yaml['nc']}withnc={nc}")
self.yaml['nc']=nc#overrideyamlvalue
ifanchors:#anchors先驗框的配置
LOGGER.info(f'Overridingmodel.yamlanchorswithanchors={anchors}')
self.yaml['anchors']=round(anchors)#overrideyamlvalue
#得到模型,以及對應的保存的特征圖列表。
self.model,self.save=parse_model(deepcopy(self.yaml),ch=[ch])#model,savelist
self.names=[str(i)foriinrange(self.yaml['nc'])]#defaultnames初始化類名列表,默認為[0,1,2...]
#self.inplace=True默認True節省內存
self.inplace=self.yaml.get('inplace',True)
#Buildstrides,anchors確定步長、步長對應的錨框
m=self.model[-1]#Detect()
ifisinstance(m,Detect):#檢驗模型的最后一層是Detect模塊
s=256#2xminstride
m.inplace=self.inplace
#計算三個featuremap下采樣的倍率[8,16,32]
m.stride=flow.tensor([s/x.shape[-2]forxinself.forward(flow.zeros(1,ch,s,s))])#forward
#檢查anchor順序與stride順序是否一致anchor的順序應該是從小到大,這里排一下序
check_anchor_order(m)#mustbeinpixel-space(notgrid-space)
#對應的anchor進行縮放操作,原因:得到anchor在實際的特征圖中的位置,因為加載的原始anchor大小是相對于原圖的像素,但是經過卷積池化之后,特征圖的長寬變小了。
m.anchors/=m.stride.view(-1,1,1)
self.stride=m.stride
self._initialize_biases()#onlyrunonce初始化偏置
#Initweights,biases
#調用oneflow_utils.py下initialize_weights初始化模型權重
initialize_weights(self)
self.info()#打印模型信息
LOGGER.info('')
#管理前向傳播函數
defforward(self,x,augment=False,profile=False,visualize=False):
ifaugment:#是否在測試時也使用數據增強TestTimeAugmentation(TTA)
returnself._forward_augment(x)#augmentedinference,None
returnself._forward_once(x,profile,visualize)#single-scaleinference,train
#帶數據增強的前向傳播
def_forward_augment(self,x):
img_size=x.shape[-2:]#height,width
s=[1,0.83,0.67]#scales
f=[None,3,None]#flips(2-ud,3-lr)
y=[]#outputs
forsi,fiinzip(s,f):
xi=scale_img(x.flip(fi)iffielsex,si,gs=int(self.stride.max()))
yi=self._forward_once(xi)[0]#forward
#cv2.imwrite(f'img_{si}.jpg',255*xi[0].cpu().numpy().transpose((1,2,0))[:,:,::-1])#save
yi=self._descale_pred(yi,fi,si,img_size)
y.append(yi)
y=self._clip_augmented(y)#clipaugmentedtails
returnflow.cat(y,1),None#augmentedinference,train
#前向傳播具體實現
def_forward_once(self,x,profile=False,visualize=False):
"""
@paramsx:輸入圖像
@paramsprofile:True可以做一些性能評估
@paramsfeature_vis:True可以做一些特征可視化
"""
#y:存放著self.save=True的每一層的輸出,因為后面的特征融合操作要用到這些特征圖
y,dt=[],[]#outputs
#前向推理每一層結構m.i=indexm.f=fromm.type=類名m.np=numberofparams
forminself.model:
#ifnotfrompreviouslayerm.f=當前層的輸入來自哪一層的輸出s的m.f都是-1
ifm.f!=-1:#ifnotfrompreviouslayer
x=y[m.f]ifisinstance(m.f,int)else[xifj==-1elsey[j]forjinm.f]#fromearlierlayers
ifprofile:
self._profile_one_layer(m,x,dt)
x=m(x)#run
y.append(xifm.iinself.saveelseNone)#saveoutput
ifvisualize:
feature_visualization(x,m.type,m.i,save_dir=visualize)
returnx
#將推理結果恢復到原圖圖片尺寸(逆操作)
def_descale_pred(self,p,flips,scale,img_size):
#de-scalepredictionsfollowingaugmentedinference(inverseoperation)
"""用在上面的__init__函數上
將推理結果恢復到原圖圖片尺寸TestTimeAugmentation(TTA)中用到
de-scalepredictionsfollowingaugmentedinference(inverseoperation)
@paramsp:推理結果
@paramsflips:
@paramsscale:
@paramsimg_size:
"""
ifself.inplace:
p[...,:4]/=scale#de-scale
ifflips==2:
p[...,1]=img_size[0]-p[...,1]#de-flipud
elifflips==3:
p[...,0]=img_size[1]-p[...,0]#de-fliplr
else:
x,y,wh=p[...,0:1]/scale,p[...,1:2]/scale,p[...,2:4]/scale#de-scale
ifflips==2:
y=img_size[0]-y#de-flipud
elifflips==3:
x=img_size[1]-x#de-fliplr
p=flow.cat((x,y,wh,p[...,4:]),-1)
returnp
#這個是TTA的時候對原圖片進行裁剪,也是一種數據增強方式,用在TTA測試的時候。
def_clip_augmented(self,y):
#ClipYOLOv5augmentedinferencetails
nl=self.model[-1].nl#numberofdetectionlayers(P3-P5)
g=sum(4**xforxinrange(nl))#gridpoints
e=1#excludelayercount
i=(y[0].shape[1]//g)*sum(4**xforxinrange(e))#indices
y[0]=y[0][:,:-i]#large
i=(y[-1].shape[1]//g)*sum(4**(nl-1-x)forxinrange(e))#indices
y[-1]=y[-1][:,i:]#small
returny
#打印日志信息前向推理時間
def_profile_one_layer(self,m,x,dt):
c=isinstance(m,Detect)#isfinallayer,copyinputasinplacefix
o=thop.profile(m,inputs=(x.copy()ifcelsex,),verbose=False)[0]/1E9*2ifthopelse0#FLOPs
t=time_sync()
for_inrange(10):
m(x.copy()ifcelsex)
dt.append((time_sync()-t)*100)
ifm==self.model[0]:
LOGGER.info(f"{'time(ms)':>10s}{'GFLOPs':>10s}{'params':>10s}module")
LOGGER.info(f'{dt[-1]:10.2f}{o:10.2f}{m.np:10.0f}{m.type}')
ifc:
LOGGER.info(f"{sum(dt):10.2f}{'-':>10s}{'-':>10s}Total")
#initializebiasesintoDetect(),cfisclassfrequency
def_initialize_biases(self,cf=None):
#https://arxiv.org/abs/1708.02002section3.3
#cf=flow.bincount(flow.tensor(np.concatenate(dataset.labels,0)[:,0]).long(),minlength=nc)+1.
m=self.model[-1]#Detect()module
formi,sinzip(m.m,m.stride):#from
b=mi.bias.view(m.na,-1).detach()#conv.bias(255)to(3,85)
b[:,4]+=math.log(8/(640/s)**2)#obj(8objectsper640image)
b[:,5:]+=math.log(0.6/(m.nc-0.999999))ifcfisNoneelseflow.log(cf/cf.sum())#cls
mi.bias=flow.nn.Parameter(b.view(-1),requires_grad=True)
#打印模型中最后Detect層的偏置biases信息(也可以任選哪些層biases信息)
def_print_biases(self):
"""
打印模型中最后Detect模塊里面的卷積層的偏置biases信息(也可以任選哪些層biases信息)
"""
m=self.model[-1]#Detect()module
formiinm.m:#from
b=mi.bias.detach().view(m.na,-1).T#conv.bias(255)to(3,85)
LOGGER.info(
('%6gConv2d.bias:'+'%10.3g'*6)%(mi.weight.shape[1],*b[:5].mean(1).tolist(),b[5:].mean()))
def_print_weights(self):
"""
打印模型中Bottleneck層的權重參數weights信息(也可以任選哪些層weights信息)
"""
forminself.model.modules():
iftype(m)isBottleneck:
LOGGER.info('%10.3g'%(m.w.detach().sigmoid()*2))#shortcutweights
#fuse()是用來進行conv和bn層合并,為了提速模型推理速度。
deffuse(self):#fusemodelConv2d()+BatchNorm2d()layers
"""用在detect.py、val.py
fusemodelConv2d()+BatchNorm2d()layers
調用oneflow_utils.py中的fuse_conv_and_bn函數和common.py中Conv模塊的fuseforward函數
"""
LOGGER.info('Fusinglayers...')
forminself.model.modules():
#如果當前層是卷積層Conv且有bn結構,那么就調用fuse_conv_and_bn函數講conv和bn進行融合,加速推理
ifisinstance(m,(Conv,DWConv))andhasattr(m,'bn'):
m.conv=fuse_conv_and_bn(m.conv,m.bn)#updateconv
delattr(m,'bn')#removebatchnorm移除bnremovebatchnorm
m.forward=m.forward_fuse#updateforward更新前向傳播updateforward(反向傳播不用管,因為這種推理只用在推理階段)
self.info()#打印conv+bn融合后的模型信息
returnself
#打印模型結構信息在當前類__init__函數結尾處有調用
definfo(self,verbose=False,img_size=640):#printmodelinformation
model_info(self,verbose,img_size)
def_apply(self,fn):
#Applyto(),cpu(),cuda(),half()tomodeltensorsthatarenotparametersorregisteredbuffers
self=super()._apply(fn)
m=self.model[-1]#Detect()
ifisinstance(m,Detect):
m.stride=fn(m.stride)
m.grid=list(map(fn,m.grid))
ifisinstance(m.anchor_grid,list):
m.anchor_grid=list(map(fn,m.anchor_grid))
returnself
Detect類解讀
classDetect(nn.Module):
"""
Detect模塊是用來構建Detect層的,將輸入featuremap通過一個卷積操作和公式計算到我們想要的shape,為后面的計算損失或者NMS后處理作準備
"""
stride=None#stridescomputedduringbuild
onnx_dynamic=False#ONNXexportparameter
export=False#exportmode
def__init__(self,nc=80,anchors=(),ch=(),inplace=True):#detectionlayer
super().__init__()
#nc:分類數量
self.nc=nc#numberofclasses
#no:每個anchor的輸出數
self.no=nc+5#numberofoutputsperanchor
#nl:預測層數,此次為3
self.nl=len(anchors)#numberofdetectionlayers
#na:anchors的數量,此次為3
self.na=len(anchors[0])//2#numberofanchors
#grid:格子坐標系,左上角為(1,1),右下角為(input.w/stride,input.h/stride)
self.grid=[flow.zeros(1)]*self.nl#initgrid
self.anchor_grid=[flow.zeros(1)]*self.nl#initanchorgrid
#寫入緩存中,并命名為anchors
self.register_buffer('anchors',flow.tensor(anchors).float().view(self.nl,-1,2))#shape(nl,na,2)
#將輸出通過卷積到self.no*self.na的通道,達到全連接的作用
self.m=nn.ModuleList(nn.Conv2d(x,self.no*self.na,1)forxinch)#outputconv
self.inplace=inplace#useinplaceops(e.g.sliceassignment)
defforward(self,x):
z=[]#inferenceoutput
foriinrange(self.nl):
x[i]=self.m[i](x[i])#conv
bs,_,ny,nx=x[i].shape#x(bs,255,20,20)tox(bs,3,20,20,85)
x[i]=x[i].view(bs,self.na,self.no,ny,nx).permute(0,1,3,4,2).contiguous()
ifnotself.training:#inference
ifself.onnx_dynamicorself.grid[i].shape[2:4]!=x[i].shape[2:4]:
#向前傳播時需要將相對坐標轉換到grid絕對坐標系中
self.grid[i],self.anchor_grid[i]=self._make_grid(nx,ny,i)
y=x[i].sigmoid()
ifself.inplace:
y[...,0:2]=(y[...,0:2]*2+self.grid[i])*self.stride[i]#xy
y[...,2:4]=(y[...,2:4]*2)**2*self.anchor_grid[i]#wh
else:#forYOLOv5onAWSInferentiahttps://github.com/ultralytics/yolov5/pull/2953
xy,wh,conf=y.split((2,2,self.nc+1),4)#y.tensor_split((2,4,5),4)
xy=(xy*2+self.grid[i])*self.stride[i]#xy
wh=(wh*2)**2*self.anchor_grid[i]#wh
y=flow.cat((xy,wh,conf),4)
z.append(y.view(bs,-1,self.no))
returnxifself.trainingelse(flow.cat(z,1),)ifself.exportelse(flow.cat(z,1),x)
#相對坐標轉換到grid絕對坐標系
def_make_grid(self,nx=20,ny=20,i=0):
d=self.anchors[i].device
t=self.anchors[i].dtype
shape=1,self.na,ny,nx,2#gridshape
y,x=flow.arange(ny,device=d,dtype=t),flow.arange(nx,device=d,dtype=t)
yv,xv=flow.meshgrid(y,x,indexing="ij")
grid=flow.stack((xv,yv),2).expand(shape)-0.5#addgridoffset,i.e.y=2.0*x-0.5
anchor_grid=(self.anchors[i]*self.stride[i]).view((1,self.na,1,1,2)).expand(shape)
returngrid,anchor_grid
附件
表2.1 yolov5s.yaml(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml)解析表
| 層數 | form | moudule | arguments | input | output |
|---|---|---|---|---|---|
| 0 | -1 | Conv | [3, 32, 6, 2, 2] | [3, 640, 640] | [32, 320, 320] |
| 1 | -1 | Conv | [32, 64, 3, 2] | [32, 320, 320] | [64, 160, 160] |
| 2 | -1 | C3 | [64, 64, 1] | [64, 160, 160] | [64, 160, 160] |
| 3 | -1 | Conv | [64, 128, 3, 2] | [64, 160, 160] | [128, 80, 80] |
| 4 | -1 | C3 | [128, 128, 2] | [128, 80, 80] | [128, 80, 80] |
| 5 | -1 | Conv | [128, 256, 3, 2] | [128, 80, 80] | [256, 40, 40] |
| 6 | -1 | C3 | [256, 256, 3] | [256, 40, 40] | [256, 40, 40] |
| 7 | -1 | Conv | [256, 512, 3, 2] | [256, 40, 40] | [512, 20, 20] |
| 8 | -1 | C3 | [512, 512, 1] | [512, 20, 20] | [512, 20, 20] |
| 9 | -1 | SPPF | [512, 512, 5] | [512, 20, 20] | [512, 20, 20] |
| 10 | -1 | Conv | [512, 256, 1, 1] | [512, 20, 20] | [256, 20, 20] |
| 11 | -1 | Upsample | [None, 2, 'nearest'] | [256, 20, 20] | [256, 40, 40] |
| 12 | [-1, 6] | Concat | [1] | [1, 256, 40, 40],[1, 256, 40, 40] | [512, 40, 40] |
| 13 | -1 | C3 | [512, 256, 1, False] | [512, 40, 40] | [256, 40, 40] |
| 14 | -1 | Conv | [256, 128, 1, 1] | [256, 40, 40] | [128, 40, 40] |
| 15 | -1 | Upsample | [None, 2, 'nearest'] | [128, 40, 40] | [128, 80, 80] |
| 16 | [-1, 4] | Concat | [1] | [1, 128, 80, 80],[1, 128, 80, 80] | [256, 80, 80] |
| 17 | -1 | C3 | [256, 128, 1, False] | [256, 80, 80] | [128, 80, 80] |
| 18 | -1 | Conv | [128, 128, 3, 2] | [128, 80, 80] | [128, 40, 40] |
| 19 | [-1, 14] | Concat | [1] | [1, 128, 40, 40],[1, 128, 40, 40] | [256, 40, 40] |
| 20 | -1 | C3 | [256, 256, 1, False] | [256, 40, 40] | [256, 40, 40] |
| 21 | -1 | Conv | [256, 256, 3, 2] | [256, 40, 40] | [256, 20, 20] |
| 22 | [-1, 10] | Concat | [1] | [1, 256, 20, 20],[1, 256, 20, 20] | [512, 20, 20] |
| 23 | -1 | C3 | [512, 512, 1, False] | [512, 20, 20] | [512, 20, 20] |
| 24 | [17, 20, 23] | Detect | [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]] | [1, 128, 80, 80],[1, 256, 40, 40],[1, 512, 20, 20] | [1, 3, 80, 80, 85],[1, 3, 40, 40, 85],[1, 3, 20, 20, 85] |
審核編輯 :李倩
-
代碼
+關注
關注
30文章
4802瀏覽量
68740 -
網絡結構
+關注
關注
0文章
48瀏覽量
11129
原文標題:YOLOv5 網絡結構解析
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是YOLO?RK3568+YOLOv5是如何實現物體識別的?一起來了解一下!

在RK3568教學實驗箱上實現基于YOLOV5的算法物體識別案例詳解
在樹莓派上部署YOLOv5進行動物目標檢測的完整流程
如何配置IPv6網絡
RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測
RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測-迅為電子

RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測
基于迅為RK3588【RKNPU2項目實戰1】:YOLOV5實時目標分類
如何在PyTorch中實現LeNet-5網絡
YOLOv5的原理、結構、特點和應用
用yolov5的best.pt導出成onnx轉化成fp32 bmodel后在Airbox上跑,報維度不匹配怎么處理?
maixcam部署yolov5s 自定義模型
yolov5轉onnx在cubeAI上部署失敗的原因?
深入淺出Yolov3和Yolov4





 工商網監
工商網監
評論