 深度模型Adan優化器如何完成ViT的訓練
深度模型Adan優化器如何完成ViT的訓練
自Google提出Vision Transformer(ViT)以來,ViT漸漸成為許多視覺任務的默認backbone。憑借著ViT結構,許多視覺任務的SoTA都得到了進一步提升,包括圖像分類、分割、檢測、識別等。
然而,訓練ViT并非易事。除了需要較復雜的訓練技巧,模型訓練的計算量往往也較之前的CNN大很多。近日,新加坡Sea AI LAB (SAIL) 和北大ZERO Lab的研究團隊共同提出新的深度模型優化器Adan,該優化器可以僅用一半的計算量就能完成ViT的訓練。
此外,在計算量一樣的情況下, Adan在多個場景(涉及CV、NLP、RL)、多種訓練方式(有監督與自監督)和多種網絡結構/算法(Swin、ViT、ResNet、ConvNext、MAE、LSTM、BERT、Transformer-XL、PPO算法)上,均獲得了性能提升。
代碼、配置文件、訓練log均已開源。
深度模型的訓練范式與優化器
隨著ViT的提出,深度模型的訓練方式變得越來越復雜。常見的訓練技巧包括復雜的數據增強(如MixUp、CutMix、AutoRand)、標簽的處理(如label smoothing和noise label)、模型參數的移動平均、隨機網絡深度、dropout等。伴隨著這些技巧的混合運用,模型的泛化性與魯棒性均得到了提升,但是隨之而來的便是模型訓練的計算量變得越來越大。
在ImageNet 1k上,訓練epoch數從ResNet剛提出的90已經增長到了訓練ViT常用的300。甚至針對一些自監督學習的模型,例如MAE、ViT,預訓練的epoch數已經達到了1.6k。訓練epoch增加意味著訓練時間極大的延長,急劇增加了學術研究或工業落地的成本。目前一個普遍的解決方案是增大訓練的batch size并輔助并行訓練以減少訓練時間,但是伴隨的問題便是,大的batch size往往意味著performance的下降,并且batch size越大,情況越明顯。
這主要是因為模型參數的更新次數隨著batch size的增加在急劇減少。當前的優化器并不能在復雜的訓練范式下以較少的更新次數實現對模型的快速訓練,這進一步加劇了模型訓練epoch數的增長。
因此,是否存在一種新的優化器能在較少的參數更新次數情況下更快更好地訓練深度模型?在減少訓練epoch數的同時,也能緩解batch size增加帶來的負面影響?
被忽略的沖量
要想加速優化器的收斂速度,最直接的方法便是引入沖量。近年提出的深度模型優化器均沿用著Adam中使用的沖量范式——重球法:
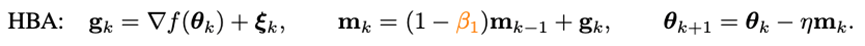
其中g_k是隨機噪聲,m_k是moment,eta是學習率。Adam將m_k的更新由累積形式換成了移動平均的形式,并引入二階moment(n_k)對學習率進行放縮,即:
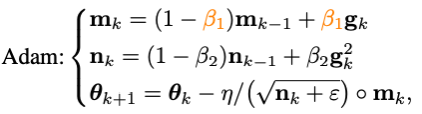
然而隨著Adam訓練原始ViT失敗,它的改進版本AdamW漸漸地變成了訓練ViT甚至ConvNext的首選。但是AdamW并沒有改變Adam中的沖量范式,因此在當batch size超過4,096的時候,AdamW訓練出的ViT的性能會急劇下降。
在傳統凸優化領域,有一個與重球法齊名的沖量技巧——Nesterov沖量算法:
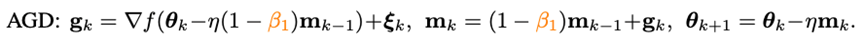
Nesterov沖量算法在光滑且一般凸的問題上,擁有比重球法更快的理論收斂速度,并且理論上也能承受更大的batch size。同重球法不同的是,Nesterov算法不在當前點計算梯度,而是利用沖量找到一個外推點,在該點算完梯度以后再進行沖量累積。
外推點能幫助Nesterov算法提前感知當前點周圍的幾何信息。這種特性使得Nesterov沖量更加適合復雜的訓練范式和模型結構(如ViT),因為它并不是單純地依靠過去的沖量去繞開尖銳的局部極小點,而是通過提前觀察周圍的梯度,調整更新的方向。
盡管Nesterov沖量算法擁有一定的優勢,但是在深度優化器中,卻鮮有被應用與探索。其中一個主要的原因就是Nesterov算法需要在外推點計算梯度,在當前點更新,期間需要多次模型參數重載以及需要人為地在外推點進行back-propagation (BP)。這些不便利性極大地限制了Nesterov沖量算法在深度模型優化器中的應用。
Adan優化器
通過結合改寫的Nesterov沖量與自適應優化算法,并引入解耦的權重衰減,可以得到最終的Adan優化器。利用外推點,Adan可以提前感知周圍的梯度信息,從而高效地逃離尖銳的局部極小區域,以增加模型的泛化性。
1) 自適應的Nesterov沖量
為了解決Nesterov沖量算法中多次模型參數重載的問題,研究人員首先對Nesterov進行改寫:
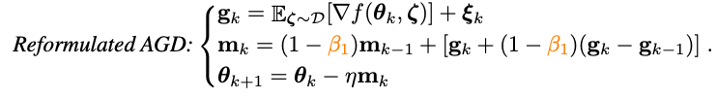
可以證明,改寫的Nesterov沖量算法與原算法等價,兩者的迭代點可以相互轉化,且最終的收斂點相同。可以看到,通過引入梯度的差分項,已經可以避免手動的參數重載和人為地在外推點進行BP。
將改寫的Nesterov沖量算法同自適應類優化器相結合——將m_k的更新由累積形式替換為移動平均形式,并使用二階moment對學習率進行放縮:
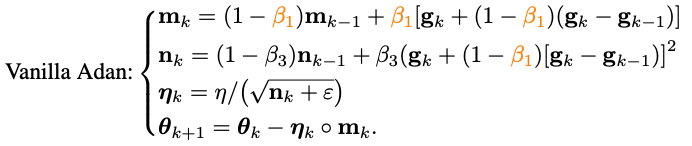
至此已經得到了Adan的算法的基礎版本。
2) 梯度差分的沖量
可以發現,m_k的更新將梯度與梯度的差分耦合在一起,但是在實際場景中,往往需要對物理意義不同的兩項進行單獨處理,因此研究人員引入梯度差分的沖量v_k:
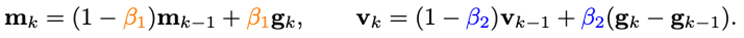
這里對梯度的沖量和其差分的沖量設置不同的沖量/平均系數。梯度差分項可以在相鄰梯度不一致的時候減緩優化器的更新,反之,在梯度方向一致時,加速更新。
3) 解耦的權重衰減
對于帶L2權重正則的目標函數,目前較流行的AdamW優化器通過對L2正則與訓練loss解耦,在ViT和ConvNext上獲得了較好的性能。但是AdamW所用的解耦方法偏向于啟發式,目前并不能得到其收斂的理論保證。
基于對L2正則解耦的思想,也給Adan引入解耦的權重衰減策略。目前Adan的每次迭代可以看成是在最小化優化目標F的某種一階近似:
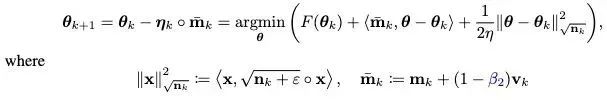
由于F中的L2權重正則過于簡單且光滑性很好,以至于不需要對其進行一階近似。因此,可以只對訓練loss進行一階近似而忽略L2權重正則,那么Adan的最后一步迭代將會變成:
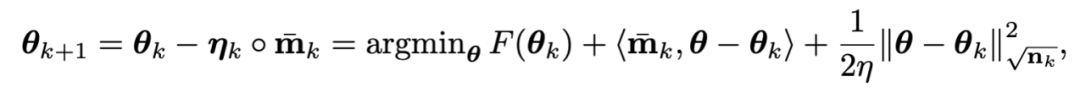
有趣的是,可以發現AdamW的更新準則是Adan更新準則在學習率eta接近0時的一階近似。因此,可從proximal 算子的角度給Adan甚至AdamW給出合理的解釋而不是原來的啟發式改進。
4) Adan優化器
將2)和3)兩個改進結合進Adan的基礎版本,可以得到如下的Adan優化器。

Adan結合了自適應優化器、Nesterov沖量以及解耦的權重衰減策略的優點,能承受更大的學習率和batch size,以及可以實現對模型參數的動態L2正則。
5) 收斂性分析
這里跳過繁復的數學分析過程,只給出結論:
定理:在給定或未給定Hessian-smooth條件的兩種情況下,Adan優化器的收斂速度在非凸隨機優化問題上均能達到已知的理論下界,并且該結論在帶有解耦的權重衰減策略時仍然成立。
實驗結果
一、CV場景
1)有監督學習——ViT模型
針對ViT模型,研究人員分別在ViT和Swin結構上,測試了Adan的性能。

可以看到,例如在ViT-small、ViT-base、Swin-tiny以及Swin-base上,Adan僅僅消耗了一半的計算資源就獲得了同SoTA優化器接近的結果,并且在同樣的計算量下,Adan在兩種ViT模型上均展現出較大的優勢。
此外,也在大batch size下測試了Adan的性能:

可以看到,Adan在各種batch size下都表現得不錯,且相對于專為大batch size設計的優化器(LAMB)也具有一定的優勢。
2)有監督學習——CNN模型
除了較難訓練的ViT模型,研究人員也在尖銳局部極小點相對較少的CNN模型上也測試了Adan的性能——包括經典的ResNet與較先進的ConvNext。結果如下:
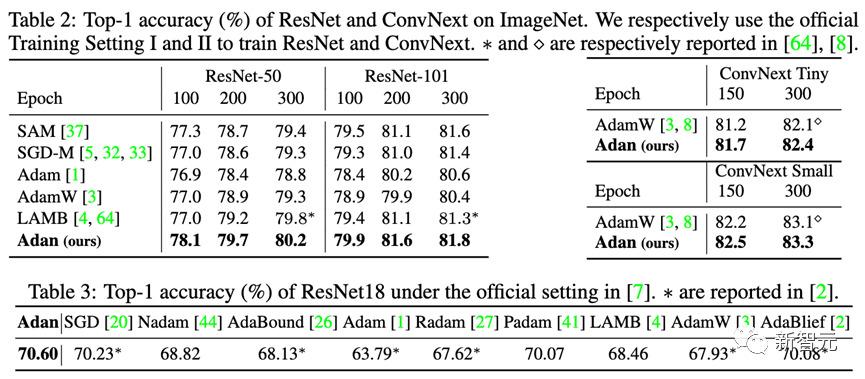
可以觀察到,不管是ResNet還是ConvNext,Adan均能在大約2/3訓練epoch以內獲得超越SoTA的性能。
3) 無監督學習
在無監督訓練框架下,研究人員在最新提出的MAE上測試了Adan的表現。其結果如下:

同有監督學習的結論一致,Adan僅消耗了一半的計算量就追平甚至超過了原來的SoTA優化器,并且當訓練epoch越小,Adan的優勢就越明顯。
二、NLP場景
1) 有監督學習
在NLP的有監督學習任務上,分別在經典的LSTM以及先進的Transformer-XL上觀察Adan的表現。
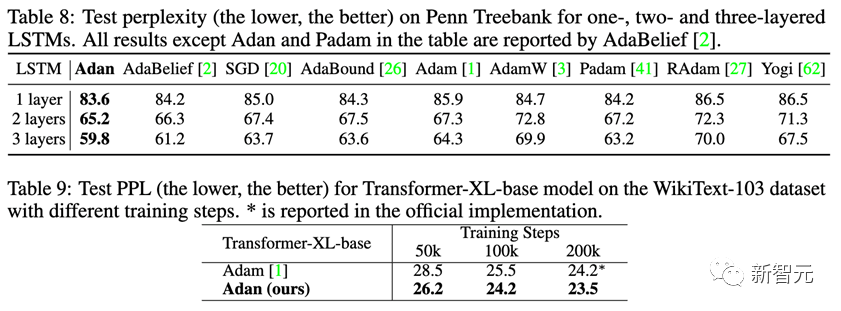
Adan在上述兩種網絡上,均表現出一致的優越性。并且對于Transformer-XL,Adan在一半的訓練步數內就追平了默認的Adam優化器。
2) 無監督學習
為了測試Adan在NLP場景下無監督任務上的模型訓練情況。研究人員從頭開始訓練BERT:在經過1000k的預訓練迭代后,在GLUE數據集的7個子任務上測試經過Adan訓練的模型性能,結果如下:

Adan在所測試的7個詞句分類任務上均展現出較大的優勢。值得一提的是,經過Adan訓練的BERT-base模型,在一些子任務上(例如RTE、CoLA以及SST-2)的結果甚至超過了Adam訓練的BERT-large.
三、RL場景
研究人員將RL常用的PPO算法里的優化器替換為了Adan,并在MuJoCo引擎中的4個游戲上測試了Adan的性能。在4個游戲中,用Adan作為網絡優化器的PPO算法,總能獲得較高的reward。
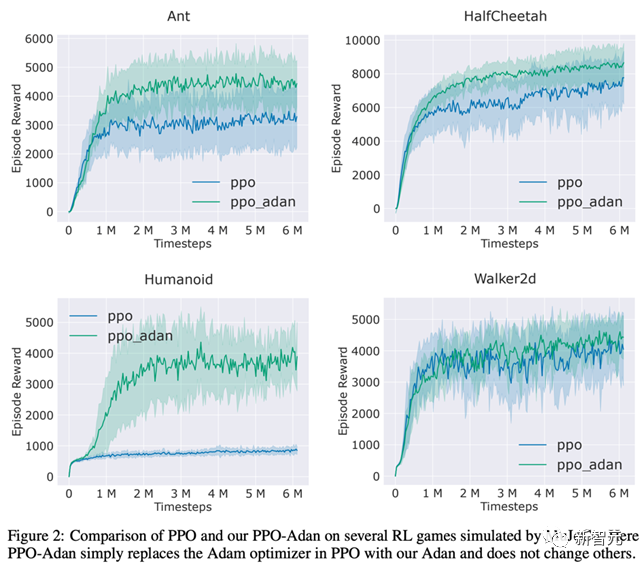
Adan在RL的網絡訓練中,也表現出較大的潛力。
結論與展望
Adan優化器為目前的深度模型優化器引入了新的沖量范式。在復雜的訓練范式下以較少的更新次數實現對模型的快速訓練。
實驗顯示,Adan僅需1/2-2/3的計算量就能追平現有的SoTA優化器。
Adan在多個場景(涉及CV、NLP、RL)、多個訓練方式(有監督與自監督)和多種網絡結構(ViT、CNN、LSTM、Transformer等)上,均展現出較大的性能優勢。此外,Adan優化器的收斂速度在非凸隨機優化上也已經達到了理論下界。
-
數據
+關注
關注
8文章
7067瀏覽量
89107 -
函數
+關注
關注
3文章
4333瀏覽量
62685 -
模型
+關注
關注
1文章
3254瀏覽量
48875
原文標題:訓練ViT和MAE減少一半計算量!Sea和北大提出新優化器Adan:深度模型都能用!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何才能高效地進行深度學習模型訓練?
Pytorch模型訓練實用PDF教程【中文】
探索一種降低ViT模型訓練成本的方法

基于預訓練模型和長短期記憶網絡的深度學習模型
如何顯著提升Vision Transformer的訓練效率
深度學習如何訓練出好的模型






 工商網監
工商網監
評論