 訓練數據的質量決定了機器學習算法的上限
訓練數據的質量決定了機器學習算法的上限
如今,越來越多的企業正利用圖分析來增強機器學習,今天的隨身聽我們就一起來聊聊圖和機器學習。如果您正從事機器學習相關的工作,但對圖分析卻不太了解,那么您可以點擊文末的“閱讀原文”,下載完整的《原生并行圖》白皮書,來增強您對圖的了解,從而更好地利用圖來增強機器學習。下面就一起來收聽今天的TigerGraph 隨身聽吧。
我們就以欺詐偵查為例,從許多方面來說,欺詐偵查如同大海撈針。您必須整理并理解海量的數據,才能找到那根“針”,在本例中是指欺詐者。事實上,越來越多的組織利用機器學習及圖技術來防止各種類型的欺詐,包括電話詐騙、信用卡退單、廣告、洗錢等。
訓練數據的質量決定了機器學習算法的上限
在進一步探討機器學習與圖技術這一強大組合的價值之前,我們先看一下當前基于機器學習的欺詐者識別是如何錯失目標的。
為了偵查某一具體的情況,如從事詐騙的電話或涉嫌洗錢的付款交易,機器學習系統需要足夠數量的欺詐電話或可能與洗錢相關的支付交易。下面我們以電話欺詐為例深入分析。
除可能屬于欺詐的電話數量外,機器學習算法還需要與電話欺詐行為高度相關的特征或屬性。
由于欺詐(與洗錢非常相似)在交易總量中所占的比重不到 0.01% 或萬分之一,因此,存在確認欺詐活動的訓練數據體量非常小。相應地,數量如此之少的訓練數據將導致機器學習算法的準確度不佳。
選擇與欺詐相關的一些特征或屬性十分簡單。就電話欺詐來說,這些特征或屬性包括某些電話呼叫其他網內網外電話的歷史記錄、預付費 SIM 卡的卡齡、單向呼叫(即被呼叫方未回電)所占的百分比,以及被拒呼叫所占的百分比。同樣,為了查找涉嫌洗錢的付款交易,需要為機器學習系統提供諸如付款交易的規模和頻率等特征。
但是,由于依賴僅側重于各個點的特征,導致誤報率居高不下。例如,頻繁進行單向呼叫的電話可能屬于銷售代表所有,他們需要致電潛在客戶尋找銷售線索或銷售商品和服務。這種呼叫也可能涉嫌騷擾,是一方對另一方的惡作劇。大量的誤報會造成浪費精力去調查非欺詐電話,最終降低對欺詐偵查機器學習解決方案的信心。
算法好不如數據多
在機器學習領域有一個很流行的說法:“算法好不如數據多”。很多機器學習就是因為缺乏充足的訓練數據而失敗的。簡單來說,樣本大小直接影響著預測的質量。與海量的交易相比(訂單、付款、電話呼叫和計算機訪問日志),諸如欺詐、洗錢或網絡安全違規等異常檢測事件的確認量很低。
很多大型客戶使用 TigerGraph 來計算機器學習領域所謂的基于圖的屬性或特征。就中國移動來說,TigerGraph 為其 6 億個號碼分別生成 118 項新特征。這將創造超過 700 億項新特征,用于將存在疑似欺詐活動的“壞號碼”與其余屬于普通用戶的“好號碼”區分開來。這將會有更多訓練數據,供機器學習解決方案提高欺詐偵查的準確性。
為電話欺詐打造更好的“磁石”
很多現實生活中的示例不斷證明著圖技術和機器學習在打擊欺詐方面的價值。目前,知名大型移動運營商正使用具備實時深度關聯分析的新一代圖數據庫,解決現有機器學習算法訓練方法的缺陷。該解決方案分析了 6 億部手機的超過 150 億通呼叫,最終為每個手機生成了 118 項特征。這些特征基于對通話記錄的深度分析,范圍不限于直接被呼叫方。
那么圖數據庫是如何識別“好”號碼或“壞”號碼呢?圖數據庫解決方案又是如何識別疑似欺詐的類型(例如,垃圾郵件廣告、詐騙銷售等),并且在被呼叫人的手機上顯示警告消息?而且這一切全部都在手機接通之前完成。
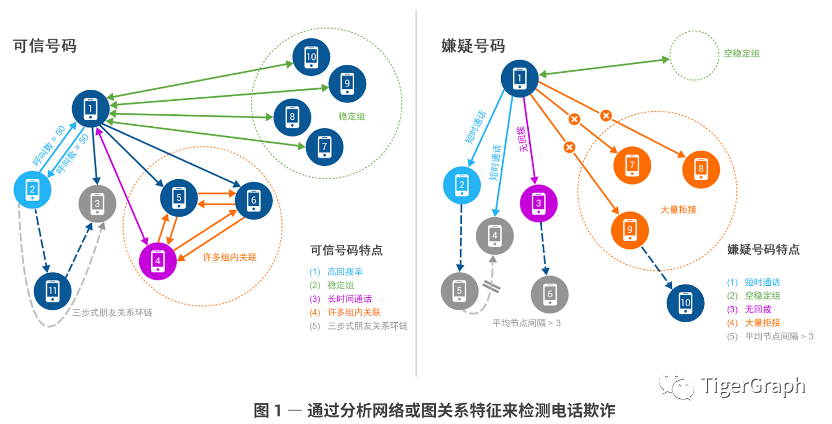
其實,簡單來說,文中圖1所示,擁有好號碼的用戶致電其他用戶,大多數人都會回復他們的電話。這有助于指示用戶之間的熟悉度或信任關系。好號碼還會定期(比如,每天或每月)撥打一組其他號碼,這一號碼組在一段時間內非常穩定(“穩定組”)。
表示好號碼行為的另一個特征是,當呼叫已經入網數月或數年的號碼時得到回電。我們還看到,在好號碼、長期聯系號碼及網內與二者頻繁聯系的其他號碼之間有著大量呼叫。這表明我們的好號碼具有很多組內關聯。
最后,“好號碼”通常會參與三步式朋友關聯,意思是我們的好號碼會呼叫另一號碼,即號碼 2,后者將呼叫號碼 3。好號碼還會通過直接呼叫與號碼 3 聯系。這表示一種三步式朋友關聯,形成信任和相互關聯性圓環。
通過分析號碼之間的這類呼叫模式,我們的圖解決方案可以輕松識別壞號碼,即可能涉嫌詐騙的號碼。這些號碼會短暫呼叫多個好號碼,但不會收到回電。此外,它們也沒有定期呼叫的穩定號碼組(即“空穩定組”)。當壞號碼呼叫長期網內用戶時,對方不會回電。壞號碼的很多呼叫還會被拒絕,而且缺乏三步式朋友關系。
圖數據庫平臺利用超過 100 項圖特征(如穩定組),它們與我們使用案例中的 6 億移動號碼各自的好壞號碼行為高度相關。相應地,它可以生成 700 億項新的訓練數據特征,供機器學習算法使用。最終提高了欺詐偵查機器學習的準確率,同時減少誤報(即非欺詐號碼被標記為潛在欺詐者號碼)和漏報(即未標記出參與欺詐的號碼)。
為了了解基于圖的特征如何提高機器學習的準確率,我們來看一個示例(下圖2),其中使用了以下四位移動用戶的側寫:Tim、Sarah、Fred 和 John。
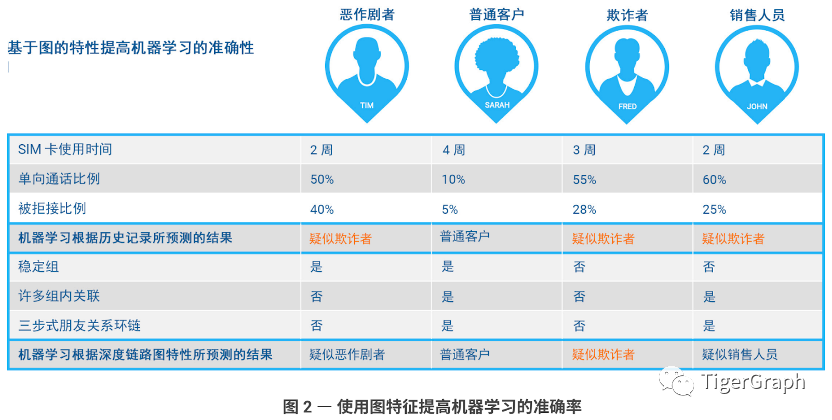
按照傳統的通話記錄特征,如 SIM 卡齡、單向呼叫的百分比以及被拒絕的呼叫總量百分比),四人中的三人(Tim、Fred 和 John)將被標記為疑似或潛在欺詐者,因為從這些特征來看,他們非常相似。經過分析基于圖的特征,以及號碼和用戶之間的深度關聯或多步關系,最終幫助機器學習將 Tim 歸類為愛惡作劇者、John 為銷售人員,而 Fred 則被標記為疑似欺詐者。我們來思考一下這個過程。
就 Tim 來說,他有一個“穩定組”,這意味著他不太可能是銷售人員,因為銷售人員每周都會撥打不同的電話號碼。Tim 沒有很多組內關聯,這意味著他可能經常給陌生人打電話。他也沒有任何三步式朋友關聯,用于確認他所呼叫的陌生人不存在關聯。根據這些特征判斷,Tim 很可能是愛惡作劇者。
我們來看一下 John 的情況,他沒有穩定組,這意味著他每天都通過電話尋找新的潛在銷售線索。他會給具有很多組內關聯的人打電話。當 John 介紹產品或服務時,如果接聽方對它們感興趣或認為與自己相關,則其中一些人很可能會將 John 介紹給其他聯系人。John 還通過三步式朋友關系與他人產生關聯,這表明他作為優秀的銷售人員將整個環鏈閉合,通過在同一組內第一次聯系的人的朋友或同事當中遴選,找到最終的買家來購買他的產品或服務。依據這些特征的組合,最終將 John 歸類為銷售人員。
就 Fred 來說,他既沒有穩定組,也不與具有很多組內關聯的群體交流。此外,他與所呼叫的人之間也沒有三步式朋友關系。這使得他非常容易成為電話詐騙或欺詐的調查對象。
回到我們最初海底撈針的比喻,在本例中,我們可以利用圖分析改善機器學習,進而提高準確率,最終找到那根“針”,即潛在的欺詐者 Fred。為此,需要使用圖數據庫框架對數據進行建模,以便能夠識別和考慮更多特征,用于進一步分析我們的海量數據。相應地,計算機將利用越來越準確的數據進行訓練,使自己不斷變得聰明,更加成功地識別潛在的詐騙分子和欺詐者。
如果您正從事機器學習相關的工作,希望利用圖分析來增強機器學習,別忘了點擊文末的“閱讀原文”,下載完整的《原生并行圖》白皮書,來增強您對圖的了解,從而更好地將圖應用到您的工作中。
另外,您也可以下載使用TigerGraph 機器學習工作臺(ML Workbench),這是一個基于Jupyter的Python開發框架,可以使數據科學家,人工智能和機器學習的從業者更容易、也更熟悉地使用圖分析,而無需學習很多新的數據處理方式。比如數據科學家可以使用TigerGraph 機器學習工作臺(ML Workbench),更快速地構建圖神經網絡 (GNN) 模型,輕松探索圖神經網絡(GNN)。它提供了 Python 級別強大而高效的數據管道,將數據從 TigerGraph 流式傳輸到用戶的機器學習系統,執行常見的數據處理任務,例如對圖數據集的訓練、驗證和測試,以及各種子圖采樣方法。詳細信息,可以點擊文中鏈接查看往期的TigerGraph 隨身聽(Vol.23 TigerGraph機器學習工作臺)。
以上就是我們今天的隨身聽內容,如果您對于我們討論的應用場景,有任何問題,或者希望和我們進行更有針對性的深度探討,歡迎通過文中的聯系方式和我們聯系。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4607瀏覽量
92840 -
機器學習
+關注
關注
66文章
8406瀏覽量
132567
原文標題:Vol.33 圖和機器學習,為電話欺詐檢測打造更好的“磁石”
文章出處:【微信號:TigerGraph,微信公眾號:TigerGraph】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論