


MLPerf競賽由圖靈獎得主大衛·帕特森(David?Patterson)聯合谷歌、斯坦福、哈佛大學等單位共同成立,是國際上最有影響力的人工智能基準測試之一。
在MLPerf V0.7推理競賽開放賽道中,浪潮信息通過模型壓縮優化算法取得性能大幅提升,將ResNet50的計算量壓縮至原模型的37.5%,壓縮優化后的ResNet50推理速度相比優化前單GPU提升83%,8GPU提升81%,基于浪潮NF5488A5服務器,每秒最多可以處理549782張圖片,排名世界第一。
本文將重點介紹浪潮在比賽中使用的模型壓縮算法的設計思路、實現方式及效果。
什么是模型壓縮
為了提高識別準確率,當前深度學習模型的規模越來越大。ResNet50參數量超過2500萬,計算量超40億,而Bert參數量達到了3億。不管是訓練還是推理部署,這對平臺的計算能力和存儲能力都提出了非常高的要求。當前深度學習已經發展到部署應用普及階段,在移動端/嵌入式端設備,計算/存儲資源是有限的,大模型難以適用。
很多深度神經網絡中存在顯著的冗余,僅僅訓練一小部分原來的權值參數就有可能達到和原網絡相近的性能,甚至超過原網絡的性能[1]。這給模型壓縮帶來了啟發。
模型壓縮是通過特定策略降低模型參數量/計算量,使其運行時占用更少的計算資源/內存資源,同時保證模型精度,滿足用戶對模型計算空間、存儲空間的需求,從而能夠將模型更好地部署在移動端、嵌入式端設備,讓模型跑得更快、識別得更準。
常用模型壓縮方法
模型壓縮有多種實現方法,目前可分為5大類:
?模型裁剪
實現方式:對網絡中不重要的權重進行修剪,降低參數量/計算量。
使用方式:分為非結構化裁剪與結構化裁剪,非結構化裁剪需結合定制化軟硬件庫,結構化裁剪無軟硬件限制。
?模型量化
實現方式:以低比特位數表示網絡權重,(如fp16/8bit/4bit/2bit),降低模型的占用空間,進行推理加速。
使用方式:需要定制化軟硬件支持,如TensorRT、TVM。
?知識蒸餾
實現方式:遷移學習的一種,用訓練好的“教師”網絡去指導另一個“學生”網絡訓練。
使用方式:大模型輔助小模型訓練來幫助小模型提升。
?精度緊湊網絡
實現方式:設計新的小模型結構,如MobileNet、ShuffleNet。
?低秩分解
實現方式:將原來大的權重矩陣分解成多個小的矩陣。
使用方式:現在模型多以1x1為主,低秩分解難以壓縮,目前已不太適用。
上述幾種模型壓縮技術中,模型量化對推理部署軟硬件的要求較高,知識蒸餾一般用來輔助提高精度,緊湊網絡模型結構相對固定,低秩分解不適用目前主流模型結構。而模型裁剪可以對模型結構靈活壓縮,滿足用戶對計算量/參數量的需求,且壓縮后的模型仍可保持較高精度,本文將重點介紹模型裁剪方法。
模型裁剪相關技術
如前所述,模型裁剪分為非結構化裁剪與結構化裁剪。非結構化裁剪是一種細粒度裁剪,通過裁剪掉某些不重要的神經元實現,優點是裁剪力度較大,可將模型壓縮幾十倍,缺點是裁剪后的模型部署需要定制化的軟硬件支持,部署成本較高。而結構化裁剪是一種粗粒度裁剪,一般有channel、filter和shape級別的裁剪,這種方法裁剪力度雖然不像非結構化裁剪力度那么大,但好處是裁剪后的模型不受軟硬件的限制,可以靈活部署,是近幾年模型壓縮領域研究者/公司的研究熱點。本文我們重點研究結構化裁剪。
結構化模型裁剪近幾年涌現很多優秀論文,壓縮成績不斷被刷新,壓縮技術從手動化結構裁剪進化到基于AutoML的自動化結構化裁剪。以下是幾種代表性的方法:
將訓練好的模型進行通道剪枝(channel pruning)[2]。通過迭代兩步操作進行:第一步是channel selection,采用LASSO regression來做;第二步是reconstruction,基于linear least squares來約束剪枝后輸出的feature map盡可能和減枝前的輸出feature map相等。
麻省理工學院韓松團隊提出了一種模型壓縮方法[3],其核心思想是使用強化學習技術來實現自動化壓縮模型。它不是對網絡結構的路徑搜索,而是采用強化學習中的DDPG(深度確定性策略梯度法)來產生連續空間上的具體壓縮比率。
基于元學習的自動化裁剪方法[4],分三步實現:首先生成元網絡進行權重預測;然后基于元網絡利用遺傳進化算法進行裁剪模型結構搜索;最后篩選出符合要求的裁剪模型結構,對候選模型進行訓練。
對ResNet50模型的壓縮優化
我們選擇Resnet50進行模型壓縮。從MLPerf競賽開始至2022年,而Resnet50始終是圖像分類任務的基準模型,是計算機視覺領域模型的典型代表。
在裁剪方法的選擇上,我們采用基于AutoML的自動化裁剪方法。該方法的優勢是可以靈活定義搜索空間,從而靈活裁剪出所需要的任何模型結構。
Resnet50的裁剪要求可概括為“快且準”,實現方法分以下三步:
? 第一,與MetaPruning類似,首先生成一個“超網絡”,為后續搜索出的裁剪模型生成權重及預測精度。
?第二,優化搜索空間。自動化模型裁剪方法會基于特定方法對裁剪模型進行搜索,搜索方法與搜索效率直接影響到目標模型的質量,我們對模型裁剪的搜索空間與搜索方法進行了深度優化。這一步是搜索出符合預期的最優裁剪模型結構的關鍵,也是對Resnet50模型裁剪優化的關鍵技術點。
傳統方法在裁剪時一般以模型的計算量/參數量為裁剪指標,比如需要將參數量/計算量裁剪掉多少,但是我們對裁剪的終極目標之一是在推理部署時降低延遲,也就是快且準中的“快”。而單純降低模型參數量/計算量并不代表一定能帶來模型性能提升,需要考慮裁剪后模型計算強度與平臺計算強度的關系,參考roofline model理論。
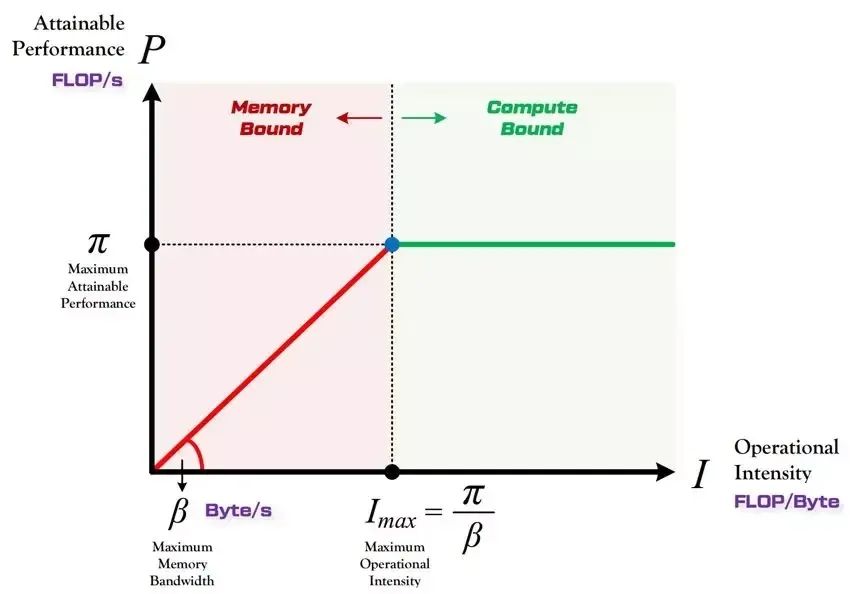
圖1 Roofline model示意圖▲
圖1為roofline model示意圖,roofline model展示了模型在計算平臺的限制下能達到多快的計算速度,使用計算強度進行定量分析。當模型計算強度小于平臺計算強度(紅色區域),模型處于內存受限狀態,模型性能<計算平臺理論性能,性能提升<計算量減少;當模型計算強度大于平臺計算強度(綠色區域),模型處于計算受限狀態,模型性能約等于計算平臺理論性能,性能提升接近計算量減少。
同時我們研究發現,某些情況下,單純減少channel不一定會帶來模型性能提升甚至可能會降低模型性能,另外,裁剪后模型的推理性能因目標運行設備不同存在差異。也就是說單純裁剪channel不一定會帶來性能提升,甚至有可能會適得其反,裁剪后模型的實際性能與部署的目標設備相關,平臺計算特性和模型結構特點緊密相關。
基于以上研究,我們對裁剪模型的搜索空間做了重點優化,提出了基于性能感知的模型裁剪優化方法。在對裁剪模型結構進行搜索時,除了考慮裁剪后模型的規模如計算量/參數量(FLOPS/Params),同時考慮不同模型結構(channel/shape/layers)基于設備平臺的真實性能表現,也就是裁剪模型在推理部署平臺上的的推理延遲時間(latency)。具體做法如下:
由于單純的計算量/參數量并不能反映模型在計算平臺上的真實性能,我們首先將不同的模型結構在計算平臺進行性能測試,決定模型的哪些層的channel需要多裁,哪些層的channel需要少裁,裁掉哪些層對實際性能提升效果最好。我們對resnet50的模型結構特點進行了研究。圖2為resnet50模型[5]結構圖,該模型結構分為5個conv模塊,conv1是一個7x7卷積,conv2-conv5都是由bottleneck組成,分別包含3/4/6/3個bottleneck。
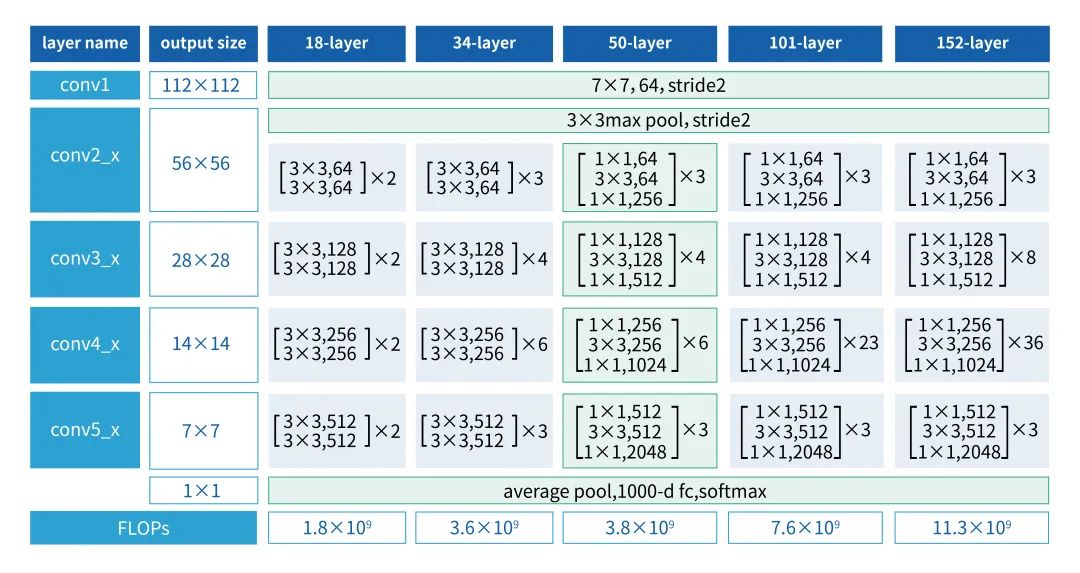
圖2 resnet50模型結構▲
以bottleneck為基本測試單位,模型推理測試平臺選擇tensorrt,對于每一個bottleneck,改變他們的輸入輸出channel個數,測試其在tensorrt上的推理性能表現,得到了每一個bottleneck在不同的輸入輸出channel下的實際性能表現。圖3展示了實驗中resnet50第三個stage的第6個bottleneck在不同的輸出channel個數下,在tensorrt上測試的推理性能。
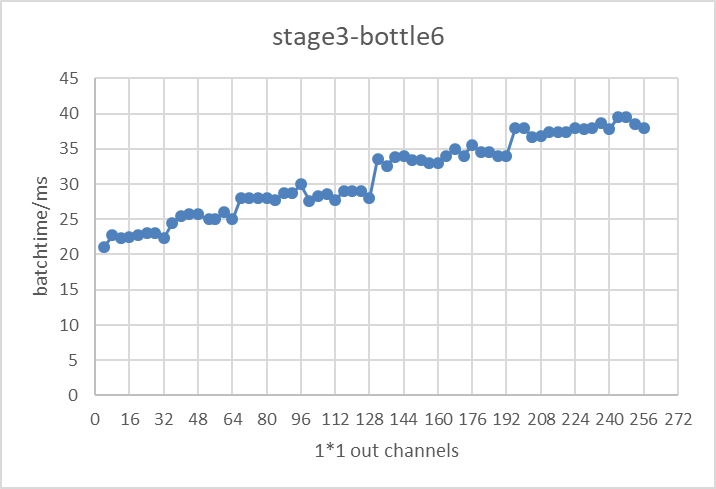
圖3 resnet50conv3_bottleneck6基于tensorrt的推理延遲▲
由圖3結果可以看出,該模型結構下測得的推理延遲時間并不會隨著channel個數的增加而線性增長,推理時間與channel個數呈現出階梯狀關系(如當32<channel個數≤64時,推理性能持平)。該實驗結果帶來的啟發是,在對模型進行裁剪時,我們選擇保留階梯線右側邊緣的channel個數,這樣既能保證推理性能又能盡可能保證模型本身的channel個數;
在對裁剪模型進行自動化搜索時,除了基于計算量/參數量參考指標,提出了以延遲為優化目標的自動化模型裁剪方法。將基于性能感知的約束條件添加到裁剪模型搜索空間,在對裁剪模型進行搜索時,可同時滿足對計算量/參數量/延遲的多重要求,盡可能保證裁剪后的模型在推理部署階段最大限度地降低延遲。在裁剪模型搜索階段,我們的優化代碼第一階段首先會指定裁剪模型的計算量/參數量,通過計算量/參數量的設定去搜索符合條件的裁剪模型。在裁剪模型的搜索空間中,每一層channel個數的設定會參考(1)中的測試結果。第二階段在搜索出的候選裁剪模型中,計算每個候選裁剪模型在目標推理平臺上的推理耗時,篩選出推理耗時最小的模型為我們的目標裁剪模型,從而保證裁剪模型是在計算量/參數量/延遲三個層面搜索出的最優結果。
第三步,裁剪后模型精度恢復。對于模型裁剪,大家最關注的問題是裁剪后的模型是否能恢復到與裁剪前相近的精度,也就是快且準中的“準”。一般的模型裁剪方法是將模型裁剪之后進行finetune或者一邊裁剪一邊訓練,而通過我們的實驗發現通過裁剪算法得到的壓縮模型,直接隨機初始化訓練(Training from scratch)得到的模型精度,反而比基于原模型權重finetune效果更好,Training from scratch可以更多去探索稀疏化模型的表達空間,所以我們對于裁剪后的模型采用Training from scratch的訓練方式。同時,為了盡可能恢復裁剪后模型的精度,我們結合蒸餾訓練,用大模型去指導裁剪后的小模型訓練,在精度保持上取得了非常好的效果。
表1是我們裁剪并訓練出的一些模型,將Resnet50計算量裁剪到原來的50%、37.5%時,仍然可以保持76%以上的TOP1精度:
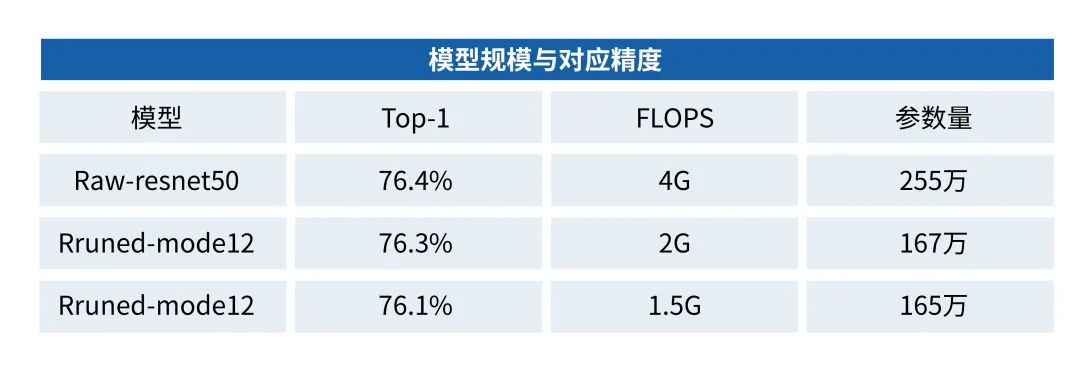
表1模型規模與對應精度▲
基于浪潮NF5488A5平臺,未經過壓縮優化的Resnet50推理性能如表2:

表2 壓縮前的Resnet50基于NF5488A5的性能▲
而經過壓縮優化后,Resnet50在開放賽道的性能如表3:

表3 壓縮后的Resnet50基于NF5488A5的性能▲
綜上,在MLPerf推理V0.7競賽開放賽道中,基于壓縮優化算法,我們將ResNet50計算量壓縮到原來的37.5%,壓縮優化后的ResNet50模型單GPU推理速度相比壓縮優化前提升83%,8GPU推理速度相比壓縮優化前提升81%。基于浪潮NF5488A5服務器,單卡每秒可處理68994張圖片,8卡每秒可以處理549782張圖片,這個成績在當時參賽結果中排名第一。
-
嵌入式
+關注
關注
5161文章
19769瀏覽量
319474 -
服務器
+關注
關注
13文章
9855瀏覽量
88372
原文標題:MLPerf世界紀錄技術分享:通過模型壓縮優化取得最佳性能
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
利用自壓縮實現大型語言模型高效縮減

基于FPGA的壓縮算法加速實現
請問如何能讓模型的效果更好?
Optimum Intel / NNCF在重量壓縮中選擇FP16模型的原因?
FOC 算法實現永磁同步電機調整指南
EE-257:面向Blackfin處理器的引導壓縮/解壓縮算法

【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+一本介紹基礎硬件算法模塊實現的好書
常見人體姿態評估顯示方式的兩種方式
【BearPi-Pico H3863星閃開發板體驗連載】LZO壓縮算法移植
PolarDB-MySQL引擎層的索引前綴壓縮能力的技術實現和效果
如何評估AI大模型的效果
Huffman壓縮算法概述和詳細流程
FP8模型訓練中Debug優化思路





 工商網監
工商網監

評論