 BEV空間內進行特征級融合具有哪些優勢
BEV空間內進行特征級融合具有哪些優勢
BEV空間內進行特征級融合具有如下優勢:
1.跨攝攝像頭融合和多模融合更易實現
2.時序融合更易實現
3.可“腦補”出遮擋區域的目標
4.更方便端到端做優化
在高等級智能駕駛領域,除了特斯拉和mobileye走的是純視覺技術路線外,其他大多數玩家走的還是多傳感器融合的技術路線。
多傳感器融合方案,一方面能夠充分利用不同工作原理的傳感器,提升對不同場景下的整體感知精度,另一方面,也可以在某種傳感器出現失效時,其他傳感器可以作為冗余備份。
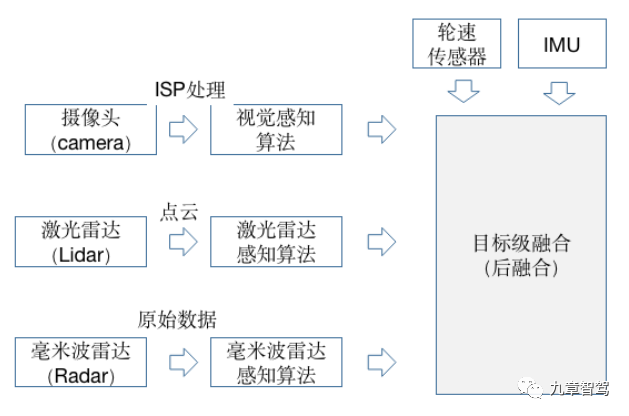
目前多傳感器融合方案,主要有后融合(目標級融合)、前融合(數據級融合)和中融合(特征級融合)三種。
多傳感器融合方案
傳感器后融合(目標級融合)
所謂后融合,是指各傳感器針對目標物體單獨進行深度學習模型推理,從而各自輸出帶有傳感器自身屬性的結果,并在決策層進行融合,這也是當前的主流方案。
其優勢是不同的傳感器都獨立進行目標識別,解耦性好,且各傳感器可以互為冗余備份。
對于Tier 1而言,后融合方案便于做標準的模塊化開發,把接口封裝好,提供給主機廠“即插即用”。
對于主機廠來說,后融合算法比較簡單,每種傳感器的識別結果輸入到融合模塊,融合模塊對各傳感器在不同場景下的識別結果,設置不同的置信度,最終根據融合策略進行決策。
不過后融合也有缺點,最大的問題就是,各自傳感器經過目標識別再進行融合時,中間損失了很多有效信息,影響了感知精度,而且最終的融合算法,仍然是一種基于規則的方法,要根據先驗知識來設定傳感器的置信度,局限性很明顯。
 ?
?
目標級融合(后融合)原理示意圖
傳感器前融合(數據級融合)
所謂前融合,是指把各傳感器的數據采集后,經過數據同步后,對這些原始數據進行融合。
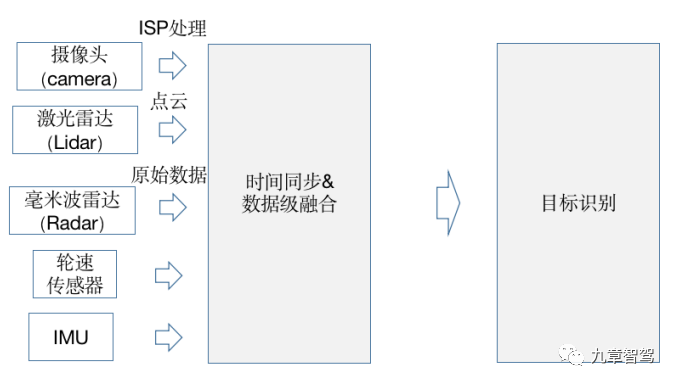
多傳感器數據級融合(前融合)原理示意圖
其優勢是可以從整體上來處理信息,讓數據更早做融合,從而讓數據更有關聯性,比如把激光雷達的點云數據和攝像頭的像素級數據進行融合,數據的損失也比較少。
不過其挑戰也很明顯,因為視覺數據和激光雷達點云數據是異構數據,其坐標系不同,視覺數據是2D圖像空間,而激光雷達點云是3D空間,在進行融合時,只能在圖像空間里把點云放進去,給圖像提供深度信息,或者在點云坐標系里,通過給點云染色或做特征渲染,而讓點云具有更豐富的語義信息。

相機和激光雷達前融合效果示意圖(來自馭勢公眾號)
坐標系的不同,也導致前融合的效果并不理想,一方面,前融合需要處理的數據量較大,對算力要求較高;另一方面,前融合要想達到好的效果,對融合策略要求較高,過程非常復雜,所以目前業內應用并不多。
為了解決異構傳感器坐標系不一致的問題,開發人員常常會把視覺2D圖像轉到3D坐標系下,這樣就和其他傳感器數據,如激光雷達點云數據,所在的空間保持一致,從而可以在相同坐標系下進行融合。
將視覺信息轉換到3D坐標系,就是今天介紹的重點——BEV。
BEV是鳥瞰圖(Bird’s Eye View)的簡稱,也被稱為上帝視角,是??一種用于描述感知世界的視角或坐標系(3D),BEV也用于代指在計算機視覺領域內的一種??端到端的、由神經網絡將??視覺信息,從圖像空間轉換到BEV空間的技術。
雖然理論上BEV可以應用在前、中、后融合過程中,不過因為前融合實現難度大,一般很少將BEV應用在前融合,偶爾也會用在后融合上,更多會應用在介于數據級融合和目標級融合之間的特征級融合,即中融合上。
傳感器中融合(特征級融合) 所謂中融合,就是先將各個傳感器通過神經網絡模型提取中間層特征(即有效特征),再對多種傳感器的有效主要特征進行融合,從而更有可能得到最佳推理。
對有效特征在BEV空間進行融合,一來數據損失少,二來算力消耗也較少(相對于前融合),所以一般在BEV空間進行中融合比較多。
為了簡化描述,如無特殊說明,下文提及的BEV感知,均指“BEV空間內的中融合”(特征級融合)。
那么,視角轉換到BEV空間,究竟有什么意義呢? 想象一下停車就好了。停車挺有難度的,尤其對于新手司機來說。駕駛員不僅要注意前方,還要兼顧左右兩個后視鏡和車內倒車鏡,根據經驗去預估自車相對于周邊障礙物的位置和距離。
而有了車載360環視功能,駕駛員能從上帝視角一目了然地看到自車周邊物體的位置和距離,停車也就變得簡單了很多。
具體到智能駕駛系統,因為感知、預測、決策和規劃等模塊,都是在3D空間內進行的,而攝像頭看到的圖像信息,只是真實物理世界在透視視圖(Perspective View)下的投影,從圖像得到的信息,需要經過復雜的后處理才能使用,信息損失也很多。而將視覺信息轉換到BEV空間,則可以很方便地連接感知與下游的??規劃控制模塊。
此外,BEV空間內的感知任務,在精度上也有優勢。做2D感知時,面對遠處的物體,可能幾個像素的誤差便可能導致幾十米的真實誤差,而在BEV空間內訓練模型時,對遠處誤差的損失(loss)更加明顯,所以感知結果也會更準確一些。
綜上,這也就是BEV如此重要的原因。
BEV的發展歷史
在了解BEV的技術細節之前,我們先來了解下BEV的發展歷史。
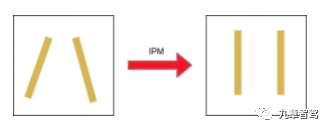
傳統方法的BEV空間轉換方法,一般是先在圖像空間對圖像進行特征提取,生成分割結果,然后通過IPM(Inverse Perspective Mapping,逆透視變換)函數轉換到BEV空間。
什么是IPM?
在前視攝像頭拍攝的圖像中,由于透視效應現象(想象從一個點去看世界,透視效應會呈現出近大遠小的觀察結果)的存在,本來平行的事物(比如車道線),在圖像中卻不平行。IPM就是利用相機成像過程中的坐標系轉化關系,對其原理進行抽象和簡化,得到真實世界坐標系和圖像坐標系之間坐標的對應關系,并進行公式化描述,從而消除這種透視效應,所以叫做逆透視變換。
 ?
?
車道線的逆透視變換(IPM)
IPM是一種連接圖像空間和BEV空間的簡單直接的方法,只需要知道相機內外參數就可以。相機內參數,指的是與相機自身特性相關的參數,比如焦距、像素大小等,而相機外參數則是相機在真實世界坐標系中的參數,比如相機的安裝位置、旋轉方向等。
不過,IPM依賴一些預先的假設,比如地面平直性假設(地面要是平的),且相機和地面之間沒有相對運動(車輛的俯仰角不變)。
很多時候這個假設太嚴苛了,很難滿足,比如在顛簸道路上,或者在車輛加速或減速產生俯仰時,系統對目標物的感知結果波動非常大,會產生“忽近忽遠”的跳變,平行的車道線,這時也會變成“內八”或者“外八”。
于是就有了改進方案,那就是將相機的實時位姿考慮進來,加上俯仰角的修正補償后,再進行空間轉換。改進后雖然效果有所改善,但是實時位姿也很難準確得到,所以效果并不理想。
這兩年,深度學習也開始被應用于BEV空間轉換,且逐漸成為主流方案。 相比于依賴人為規則,使用神經網絡從2D空間進行BEV空間轉換,能夠取得更好的感知效果。
具體的流程是,先通過一個共享的主干網絡(Backbone)來提取每個相機的特征(feature),然后再通過Transformer等將多攝像頭數據,完成從圖像空間到BEV空間的轉換。在BEV空間內,由于坐標系相同,可以很方便地將圖像數據和其他傳感器數據(如Lidar、Radar等)進行融合,還可以進行時序融合形成4D空間,這也是當下BEV技術的大趨勢。
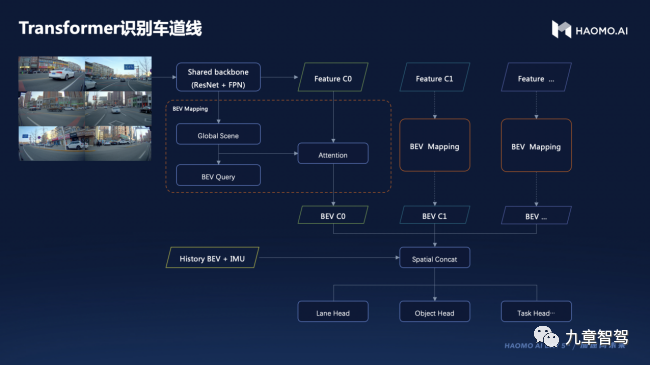
毫末智行用于識別車道線的BEV時空融合感知網絡
BEV空間內中融合的優勢
相比于后融合和前融合,在BEV空間內進行中融合具有如下優勢:
01 跨攝像頭融合和多模融合更易實現
傳統跨攝像頭融合或者多模融合時,因數據空間不同,需要用很多后處理規則去關聯不同傳感器的感知結果,操作非常復雜。在BEV空間內做融合后,再做目標檢測,算法實現更加簡單,BEV空間內視覺感知到的物體大小和朝向也都能直接得到表達。
02 時序融合更易實現
在BEV空間時,可以很容易地融合時序信息,形成4D空間。 在4D空間內,感知網絡可以更好地實現一些感知任務,如測速等,甚至可以直接輸出運動預測(motion prediction)給到下游的決策和規控。
03 可“腦補”出被遮擋區域的目標
因為視覺的透視效應,2D圖像很容易有遮擋,因而,傳統的2D感知任務只能感知看得見的目標,對于遮擋完全無能為力,而在BEV空間內,可以基于先驗知識,對被遮擋的區域進行預測,從而“腦補”出被遮擋區域可能存在物體。雖然“腦補”出的物體,有一定“想象”的成分,但這對于下游的規控模塊仍有很多好處。
04 更方便端到端做優化
傳統做感知任務時,依次做目標識別、追蹤和運動預測,更像是個“串行系統”,上游的誤差會傳遞到下游從而造成誤差累積,而在BEV空間內,感知和運動預測在統一空間內完成,因而可以通過神經網絡直接做端到端優化,“并行”出結果,這樣既可以避免誤差累積,也大大減少了人工邏輯的作用,讓感知網絡可以通過數據驅動的方式來自學習,從而更好地實現功能迭代。
隨著特斯拉和毫末智行等紛紛使用BEV空間轉換,近期BEV也引起了行業內的高度關注,不過當前BEV的應用實踐并不太多,業內專家仍有很多疑問,BEV感知的模型架構是什么?如何在BEV空間內做目標檢測和模型訓練?BEV語義感知地圖是否可以代替高精地圖?當前BEV仍有什么挑戰?BEV的技術壁壘是什么?為什么有的公司可以這么做,而有的公司則不行?
帶著這些問題,九章智駕采訪了毫末智行的技術總監潘興、紐勱科技的視覺專家符張杰、鑒智機器人研究總監朱政以及一些其他行業專家。
BEV感知需要什么樣的架構
雖然每個公司使用的BEV感知架構可能不完全相同,但是大致架構類似。
第一步,先將攝像頭數據輸入到共享的骨干網絡(Backbone),提取每個攝像頭的數據特征(feature)。
第二步,把所有的攝像頭數據(跨攝)進行融合,并轉換到BEV空間。
第三步,在BEV空間內,進行跨模態融合,將像素級的視覺數據和激光雷達點云進行融合。
第四步,進行時序融合,形成4D時空維度的感知信息。
最后一步,就是多任務輸出,可以是靜態語義地圖、動態檢測和運動預測等,給到下游規控模塊使用。 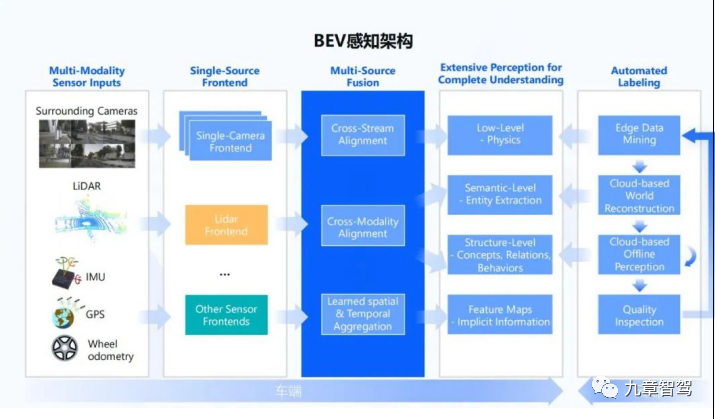
BEV感知架構
引用自地平線架構師劉景初主題為“上帝視角與想象力—自動駕駛感知的新范式”的線上分享 值得一提的是,Transformer在CV領域的應用自2020年底就開始獲得關注,隨著2021年特斯拉在AI Day上公開其在FSD中使用了Transformer算法后,國內多家公司也紛紛開始將Transformer應用在感知系統中,如毫末智行、地平線、紐勱等。
相比于傳統神經網絡(如CNN)的局部感受野,Transformer的注意力機制,能夠帶來更好的全局感受野,讓其在進行跨攝像頭、跨傳感器以及時序融合時,可以更好地在空間時序維度上建模,從而可以提升感知準確率。
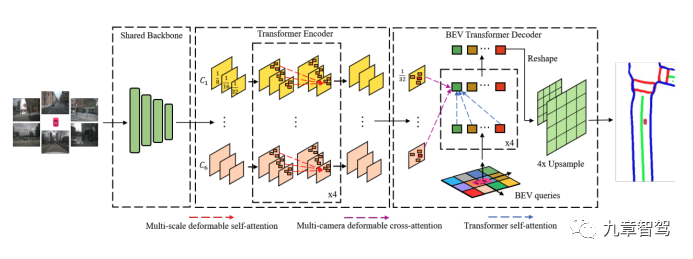
下圖中,南京大學、上海人工智能實驗室和香港大學提出的BEVFormer算法架構就使用了Transformer,并在nuScenes測試集上的NDS指標上取得了新的當前最優水平(SOTA)56.9%,提升了9個點。  ?
?
BEVFormer算法架構
BEVFormer經過骨干網絡提取特征后,經過了6個編碼層(encoder),每一個都采用了典型的transformer結構。
具體實現上,BEVFormer通過預先設置參數的網格劃分(grid-shaped)的BEV 查詢機制(BEV queries)來利用時空信息。為了聚合空間信息,BEVFormer設計了空間交叉注意力機制(spatial cross-attention,即BEV 查詢機制從多相機特征中通過注意力機制提取所需的空間特征),讓BEV查詢機制能從其感興趣的多相機視角中提取特征,為了聚合時序信息,BEVFormer提出了時序自注意力機制(temporal self-attention,即每一時刻生成的BEV特征都從上一時刻的BEV特征獲取所需的時序信息)來融合歷史信息。
BEVFormer在通過Transformer進行BEV空間轉換時,是通過預先設置參數的網格劃分(grid-shaped)的BEV 查詢機制和空間交叉注意力機制。
預先設置了一個大小為H x W x C的空間,作為BEVFormer的查詢空間,其中H和W是BEV平面的空間尺寸,C為與該平面垂直的高度坐標,其中網格間隔值s代表了該空間的顆粒度,自車坐標作為原點,BEV查詢機制負責不斷查詢,找到這個空間內每個坐標點(x , y)的柱狀3D參考點,最終完成全部BEV空間轉換。
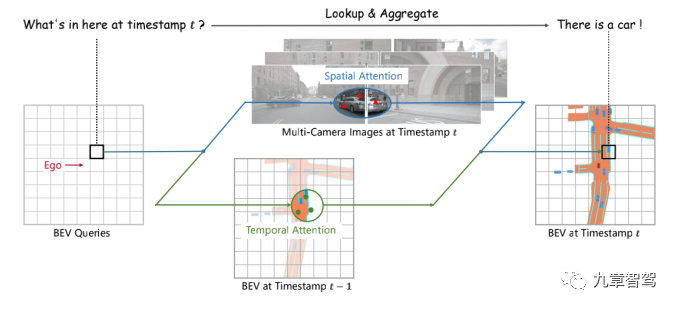
BEVFormer的BEV查詢機制
BEVFusion在進行BEV轉換時,雖沒使用Transformer,不過也經歷了編碼(encoder)和解碼(decoder)兩個過程,在解碼過程中,把圖像信息轉化成BEV的3D空間的特征點云,每個像素都有一個預估深度D,N個輸入相機會生成大小為 N x H x W x D 的相機特征點云,其中(H,W) 是相機特征圖的大小,D為深度信息。
而轉換成的BEV空間的特征點云,以自車作為坐標系原點,沿x軸和y軸展開,以局部網格采樣的方式,如網格間隔(grid)為r,一般通過池化(pooling)操作來聚合每個 r × r BEV空間網格內的特征,并沿 z 軸(高度方向)展平特征,于是完成了從2D到BEV空間的轉換。
 ?
?
BEVFusion相機到BEV空間轉換機制
此外,紐勱提出的對多相機配置的BEV語義分割任務的BEVSegFormer架構,也用到了Transformer,并在nuScenes驗證集的語義分割任務上取得了當前最優水平(SOTA)。
 ?
?
BEVSegFormer的網絡
幾位行業內專家認為,由于Transfromer先天具有更好的全局感受野,因而可以好地提取全局特征,既可以用來作為骨干網絡,也可以在BEV轉換中使用。BEV+Transformer聯合使用,優勢會更加明顯,有可能會成為行業發展趨勢。
BEV感知任務實踐
如何在BEV空間內做3D目標檢測?
在自動駕駛感知中,目標檢測是非常重要的任務。 所有下游跟蹤、預測、規劃、控制等任務都需要目標檢測“打好基礎”,而下游任務都是在3D空間內完成的。因此,強大的 3D 檢測能力是自動駕駛安全的保證。
在實際應用中,純視覺方案面臨從 2D 推測 3D“少一個維度” 的挑戰。一般傳統方案做3D檢測時(如FCOS3D),先做2D的目標檢測,再通過以激光雷達測的真值訓練的神經網絡去對2D目標預測深度,以此來得到3D目標的檢測。
在BEV空間內可以直接進行3D目標檢測,省去預測深度的過程,實現起來更簡單。如把2D檢測算法DETR稍加改造用于做3D目標檢測的DETER3D,算法復雜度大大降低,也在NuScenes數據集上取得了當前最優水平(SOTA)的檢測效果。
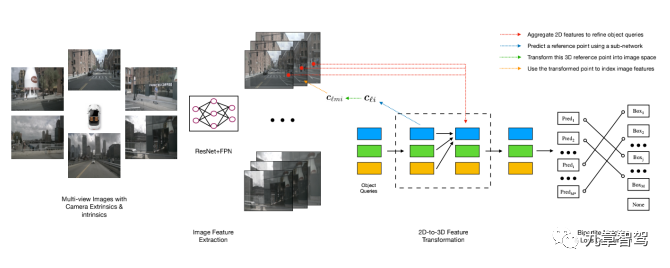 ?
?
DETR3D算法架構(其損失函數的借鑒了DETR的設計)
注:DETR3D由麻省理工學院(MIT)和清華大學、理想汽車和豐田研究所團隊共同合作提出的,目前代碼已經開源。
DETR3D論文中的感知結果顯示,由于在BEV空間里的跨攝像頭的融合效果更好,DETR3D對于相機附近超大的、被截斷目標物(如大貨車)的檢出率有了明顯的提升(在關鍵檢出指標NDS上,FCOS3D:0.317,DETR3D:0.356)。
此外,BEV空間內的目標檢測更容易做到“不重不漏”。
鑒智機器人朱政介紹道:“目標檢測最重要是做到‘不重不漏’。在2D圖像空間內,由于透視效應,遮擋嚴重,很容易重合和漏檢;在BEV空間內,做到不重合很容易,只需要按照物理世界的規則,把重合的感知目標去掉即可;要做到不漏檢,如果單幀圖像下被完全遮擋,那的確沒辦法——不過,加上時序信息,即使在某幾幀下被遮擋,只要不是一直被遮擋住,就可以在BEV空間‘腦補’出來。就像人開車一樣,前幾秒看到旁邊車道有輛車,??中間有幾秒被大車擋住了,但我們知道再過幾秒它還會出現。”
傳統2D感知任務和BEV空間如何結合?
筆者有個疑問:在BEV空間內檢測有這么多好處,那是不是所有的感知任務都可以在BEV空間內完成,傳統的那些2D檢測和語義分割等感知任務還有“用武之地”嗎? 目前看下來,2D感知任務并不會完全被“棄用”,還是會與BEV空間內的檢測任務結合進行使用。
鑒智機器人科學家朱政認為,一般的檢測任務,如動態車輛、行人和靜態車道線等,當然更適合在BEV空間內做,但也有些是在BEV空間內做不了或者更合適在2D空間內做的感知任務,比如紅綠燈檢測。
紐勱也認為,傳統的2D檢測和圖像分割任務,其實是可以作為輔助來提升BEV感知任務的性能,可以根據下游的不同需求,來做不同的安排。
那么,2D感知的結果怎么對應到 BEV空間呢? 對于這個問題,地平線架構師劉景初在線上分享中提到,其實關鍵是要找到2D檢測結果在BEV空間的映射關系,且這些映射關系要在不同的場景下表現得足夠魯棒,這是比較難的,需要很多后處理規則。
如何處理“腦補”出來的預測結果?
在BEV空間做目標檢測時,對于被遮擋區域,感知模型會根據先驗知識,“腦補”出被遮擋部分的目標。這種“腦補”的功能,無疑是非常令人驚喜的,地平線的架構師劉景柱在一次線上分享中,認為這種想象力是“一種感知范式的轉變”。
那么對于“腦補”出的感知結果,到底如何使用才能最大化發揮其作用呢?
業內專家普遍認為,對于神經網絡所“想象”出來的感知結果,應該和實際看到的感知結果做好區分,比如可以讓感知結果輸出時帶一個“置信度”的標簽,告訴下游這個結果到底是實際看到,還是“腦補”出來的。
對于下游而言,對不同置信度的結果的“可信賴度”是不同的,使用的時候也會做好甄別,比如對低置信度的感知結果使用時會做一些限制。
劉景初在線上分享時提到,對于低置信度的感知結果,只能用一些比較粗糙的信息,比如車道線是不能用的,但是如果前面有個路口,能看到人行橫道,那么大概率兩邊會有延伸出去的道路,這個感知結果就是可以用的。
毫末智行的潘興也認為,復雜拓撲結構道路環境下,“腦補”出的車道線準確度很一般,“經常出錯,比如會在小路口時“腦補”將車道線延長,或者將待轉區的線“腦補”成了車道線”,對于這類識別結果,毫末的選擇是不使用,甚至直接選擇不輸出這些“腦補”的車道線感知結果。
鑒智機器人的朱政認為,“腦補”出的結果,可以作為隱變量或者放在隱空間存儲起來,交給模型自行判斷使用,而不去加太多人為規則去約束。
時序融合有什么用處? 在BEV空間內,進行時序融合后形成的4D空間,除了上述提到的可以實現對暫時被遮擋的物體有更好的跟蹤效果外,還可以更方便地對運動物體進行測速和運動預測。
測速
除了像毫米波雷達這種自帶測速功能的傳感器外,其他傳感器基于某一時刻的信息去做測速是很困難的,而融入了時序信息后,視覺就可以實現穩定地測速。
在2D圖像空間內,一般采用光流法(Optical Flow)進行測速。
光流法,是在視頻流中,利用上一幀代表同一目標物的像素點到下一幀的移動量,從而計算出目標物的運動速度的方法。
根據進行光流估計時圖像的選取點是稀疏還是稠密,可以將光流估計分為稀疏光流(Sparse Optical Flow)和稠密光流(Dense Optical Flow),如下左圖的稀疏光流為選取了明顯的特征點進行光流估計,右圖為連續幀稠密光流示意圖。
稠密光流描述圖像中每個像素向下一幀運動的方向和速度,為了便于識別,用不同的顏色和亮度表示光流的大小和方向,如黃色代表向下運動,紫色代表向上運動,速度越快顏色越深。  ?
?
稀疏光流(左圖)和稠密光流(右圖 )
在BEV空間內,因為能夠直接獲取到目標物體每幀下的具體位置信息,再加上前后幀的時間戳信息,就可以很容易求出目標物體的速度,“可以把根據位置信息得到的速度,再融合毫米波雷達提供的速度,這樣結果會更準確,”一位行業內專家介紹道。
毫末智行潘興認為,也可以在模型訓練時,把速度信息直接標注上去,讓車端模型根據前后幀的信息自行推理出來,“有了4D信息后,速度的真值也比較容易獲取,訓練起來更容易一些”,潘興說道。
運動預測
自動駕駛系統需要與道路上的交通參與者進行互動,并預測他們未來的行為,以便能正確做好自車的規劃控制。
云端有了4D時空信息,就像掌握了預知未來的“超能力”一樣,可以準確地知道接下來每個目標物的運動軌跡,而用這些信息去訓練神經網絡,可以讓模型根據過往的歷史信息去預測目標物接下來的運動軌跡。
傳統算法會先做感知,再做運動預測,中間會人為增加很多規則來處理感知結果,這樣一方面會增加很多人工邏輯,增加了后續調優的難度,另一方面處理時也損失了很多有效信息。而神經網絡則直接從感知傳遞到運動預測,全部在BEV空間內完成,減少信息損失的同時,還可以端到端做優化,減少了人工邏輯,大大提升數據迭代的效率。
此前也已經有一些端到端感知聯合預測的實踐。
英國的自動駕駛創業公司Wayve和劍橋大學合作提出的FIERY網絡,也是基于純視覺的方法,通過端到端的方式,通過攝像頭輸入,直接在BEV空間預測每個目標的運動軌跡(motion trajectory),并給出了具體軌跡的概率。
下圖是FIERY BEV網絡運動預測的示意圖,上面兩行為相機輸入,最下面一行為BEV空間下的目標物的預測軌跡。 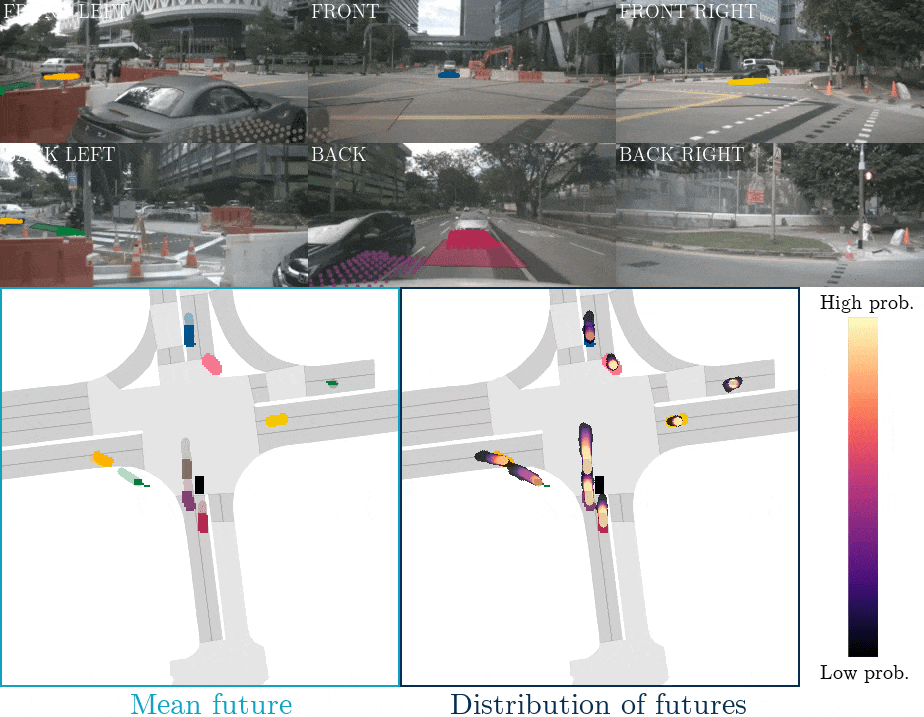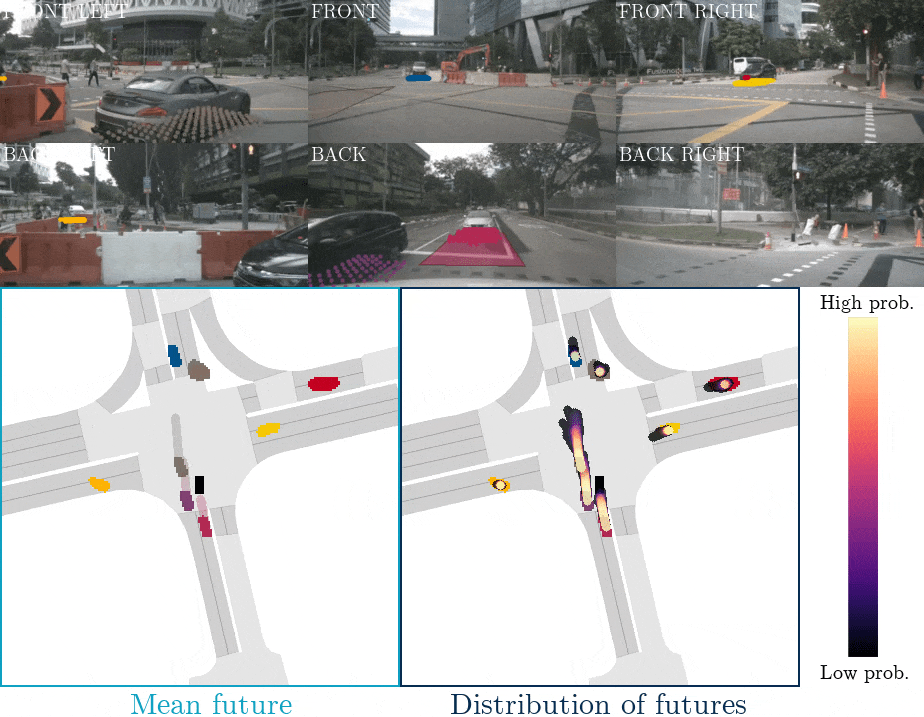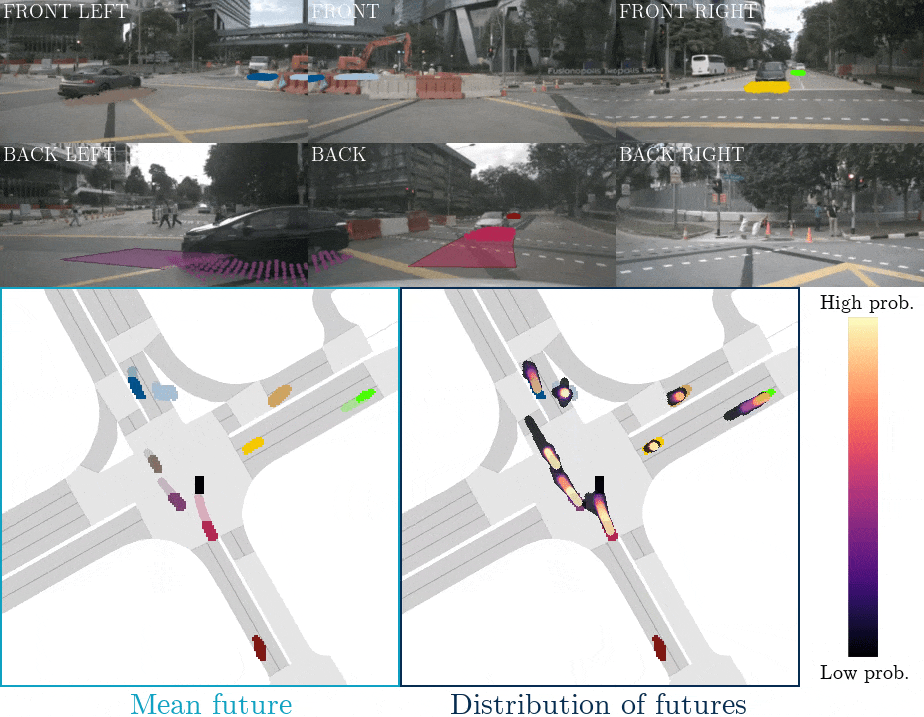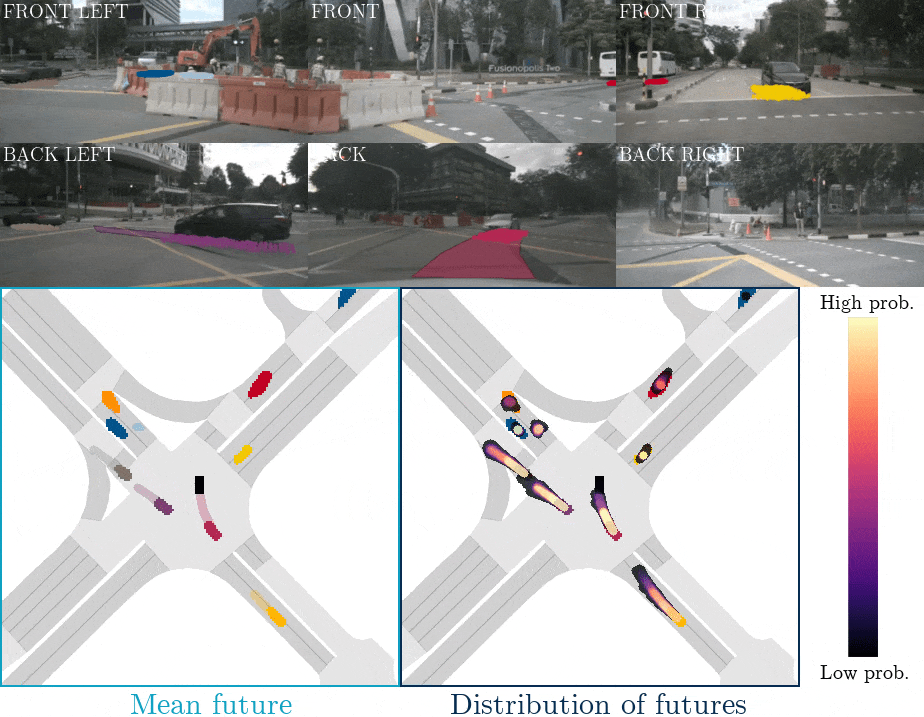 ?
?
FIERYBEV網絡運動預測的示意圖
下圖為鑒智機器人和清華大學團隊合作提出的BEVerse,以周視攝像頭的視頻流作為輸入,就是在BEV空間內完成的多任務模型感知任務,除了動態感知和局部語義地圖外,還進行了運動預測。 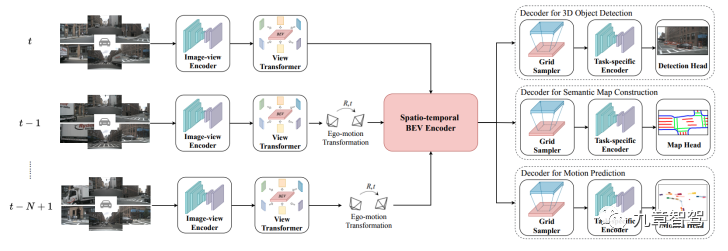 ?
?
BEVerse的多任務模型架構
在網格劃分時,如何權衡大小、遠近目標檢測的矛盾?
本質上,從2D圖像到BEV空間的轉化就是尋找一種映射關系,將2D圖像的每個像素投射到3D空間,使圖像的稠密語義信息在BEV空間得以完整保留。
一般在BEV轉化時,都會使用網格劃分機制。
具體轉換過程,上文已經詳細描述了,雖然轉換過程的原理不難,但轉化過程(如池化時)卻非常消耗算力,主要是因為相機的特征點云密度非常大,比如200萬像素的相機,每幀會生成200萬個點特征點云,比激光雷達的點云密度要大得多。
所以,為了提高轉換效率和節省算力,一般會限制網格的數量,這就需要預先設置好網格參數,主要是網格間隔(grid)和x/y軸的范圍(range)。
這就帶來了一個挑戰,那就是如何在網格間隔參數設置時兼顧近處和遠處、大目標和小目標。
網格間隔參數設置得大,BEV空間內的特征顆粒度就大,雖然計算運行速度比較快,但細節不是很豐富,網格參數小的話,顆粒度小,雖然細節豐富,但計算量大。
因為車端算力的限制,要想感知距離足夠遠,網格就不能設置得特別小,而網格大的話,就可能損失很多細節,小目標就可能會遺漏,這就需要采取折中的方案,也需要對網絡做一些精細化的設計,使用一些人工規則或者加一些訓練技巧。
紐勱的符張杰介紹:“可以對遠處目標或者小目標加以更大的損失權重,這樣網絡就會更加關注遠處目標或小目標,也可以利用多尺度的特征來解決這個問題。” 在BEV空間的多頭感知任務中,不同的任務對于網格采樣顆粒度和范圍的需求不同,可以根據具體的任務來設置網格和范圍參數,這個思想在紐勱的BEVSegFormer和鑒智機器人和清華大學團隊共同提出的BEVerse網絡架構中都有體現。
在BEVerse中的多頭任務模型中,在語義地圖感知任務中,由于車道線一般比較細,需把采樣網格設置和x/y軸范圍設置得比較小(x軸范圍為[-30m,30m],y軸為[-15m,15m],間隔為0.15m),而在3D目標檢測任務中,網格和范圍可以設置地稍大一些(x軸和y軸范圍均為[-51.2m,51.2m],間隔為0.8m)。
鑒智機器人的朱政則提到,可以根據不同場景的需求,對不同的范圍(x/y軸)進行采樣,他說道:“要考慮功能對于感知范圍的需求,比如某些功能只在高速公路上開啟,那么對遠處的目標就更關注一些;如果只在城區開啟時,因為車速低,關注的范圍就不需要那么遠,這樣可以節省部分算力。”
BEV空間內的模型訓練和優化
既然在BEV空間內做目標檢測有這么多好處,那么如何訓練BEV空間內的模型呢?
如何在BEV空間訓練算法模型?
車端BEV網絡的訓練方式,還是采用傳統的有監督學習,不過區別在于,和傳統2D感知任務在2D圖像空間內完成標注不同,其所需要的真值需要在BEV空間內完成標注。
據業內專家反饋,BEV訓練最大的挑戰是在訓練神經網絡所需要的真值(Ground Truth)的生成上。
訓練所需的真值數據,是從車端的影子模式下回傳的視頻流數據中,通過數據挖掘篩選出有價值的corner case數據。這部分數據再進入云端真值系統。
云端真值系統的作用,先是進行三維重建,轉換到BEV空間,再做時序融合,形成4D空間數據,再進行自動標注。
最后經過人工質檢(QA)后就形成了所需要的真值。
這樣4D空間的真值數據就可以用來訓練車端的BEV感知模型了,訓練完成后再繼續部署到車端,這樣不斷迭代來形成閉環。
具體流程可以參考下圖。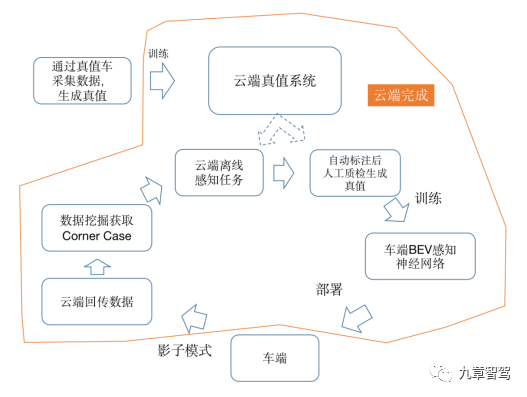 ?
?
BEV感知模型的訓練鏈路
值得一提的是,上述的鏈路,尤其是車端影子模式+云端真值系統相結合的方式進行模型迭代形成數據閉環,更像是個“理想鏈路”。受限于實現技術難度和合規性,目前真正能夠實現完整閉環的玩家,可以說是少之又少。 當前更普遍的還是自建采集車隊,用激光雷達+視覺的真值車去采集數據,做聯合4D標注來進行模型訓練和迭代,并部署到車端。
如何提升BEV感知精度?
對于感知任務而言,精度是下游非常關心的。
由于視覺先天在測距方面存在不足,在BEV空間內提升感知精度就成為了至關重要的,而這又和模型訓練密不可分。
根據業內專家的實踐經驗,要想提高車端BEV感知模型的精度,一般從這三方面入手:
01 優化云端三維重建和標注模型
有監督學習模式下,訓練數據真值的精度決定了所訓練模型的精度上限。對于BEV感知模型而言,云端真值生成系統就是“老師”,要想提升車端BEV感知模型這位“學生”的水平,提升負責三維重建和自動標注的云端真值系統這位“老師”的水平是很重要的。
云端“老師”的三維重建功能,也是要經過數據進行訓練的,為了讓訓練“老師”的數據有足夠高的精度,一般會使用帶激光雷達的真值車采集得到用于訓練數據的真值。地平線的做法是,為了獲取更好的重建效果,會使用真值車從不同的行駛方向采集同一個地點的數據。
除了提升用于訓練“老師”的數據精度外,業內公司在使用云端真值系統進行離線感知任務時,會不惜算力做一些感知融合處理,如融合其他傳感器數據(激光雷達、毫米波雷達等)和時序信息,從而獲得完整的BEV空間的4D重建場景,以此作為真值來訓練車端的網絡。
如果車端回傳的數據中有激光點云,數據精度會更高,效果也更好,如果沒有激光點云,??也可以依賴視覺進行三維重建。據了解,基于視覺數據進行云端三維重建的數據精度,也是可以滿足車端模型訓練要求的。而且,由于當前激光雷達上車較少且位置差異較大,目前業內還是以視覺數據為主進行三維重建。
在BEV空間下標注時,為了提升標注效率和標注精度,也會先用云端真值系統自動標注做預處理,完成后再人工進行校驗,使真值的精度達到近似人類駕駛員能達到的精度。
02 增加訓練數據量
影子模式下,車端會設置很多觸發器(trigger)的策略,采集有價值的數據回傳到云端。 在云端進行數據挖掘后,找到有價值的corner case,然后重新去做真值生成,并通過數據驅動對車端網絡進行訓練迭代。
毫無疑問,訓練數據所覆蓋的場景越多,車端模型的泛化能力越強,感知精度也越高。相比于訓練數據的數量,更重要的是數據的質量,也就是數據需要覆蓋更多的極端場景,如不同的城市道路、不同的光照條件等。
除了車端影子模式獲取數據和自建采集車隊外,還有一種更高效地獲取數據的方法,那就是去年特斯拉AI Day提出來的通過仿真獲取數據。 ?
?
特斯拉AI Day中的仿真介紹
03 優化車端網絡架構
除了上述兩點外,設計車端模型架構也是非常重要的,架構的好壞也直接決定了網絡的效率和功能水平。 不過受訪的多位專家也提到,對于BEV感知而言,并不需要一味地提升感知精度,最主要的評價指標還是看能否滿足下游的需求。
其實感知精度的要求可以不用那么高,就像人開車一樣,對于近處的物體精度高一點就可以,對于遠處的物體來說,過于追求精度反而是沒有必要的。
一位專注于做視覺的從業者說:“BEV空間內的視覺算法精度在相當一段范圍內精度還是非常準的,??基本可以控制在百分之幾的誤差。??人開車的時候也是如此,前面200米左右有個東西,??它的精確距離是200米還是220米,其實區別并不大。”
BEV語義地圖有啥用?
在當前高等級智能駕駛系統中,高精地圖所提供的語義信息,包括道路拓撲結構、車道線、限速要求等,能夠讓智能駕駛系統更好地理解現實世界的行車規則,也讓很多人認為高精地圖是通往高等級智能駕駛的道路上不可或缺的一部分。
不過當前大部分的高精地圖,都是使用采集車得到的以點云為主的數據進行標注得來,地圖的構建和維護成本都很高。
而HDMapNet、BEVSegFormer、BEVerse等方法,可以基于多攝像頭信息,將BEV空間內的車道線、路沿、斑馬線等靜態目標物,在線生成局部語義地圖供下游規控任務使用,大大降低了語義地圖的構建和維護成本,從而可能會給行業帶來地圖構建和更新的新范式。
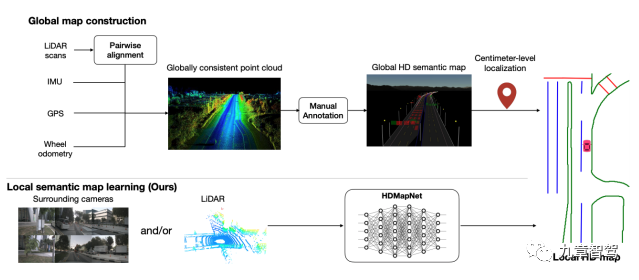
HDMapNet實時構建局部語義地圖的網絡模型
當前高速NOA的主流方案,還是依賴高精地圖,不過當功能拓展到城區NOA時,目前城市道路尚無高精地圖覆蓋。
諸多業內專家認為BEV在線構建的語義地圖可以一定程度上代替高精地圖的作用,在城市NOA中發揮重要作用。
追勢科技發布的城市記憶領航功能,也是利用了“單車多次”的記憶模式,利用車端傳感器(激光雷達非必要)來實現特定通勤路線的語義地圖的構建和更新,從而可以實現上下班這種特定路線的點對點領航輔助功能。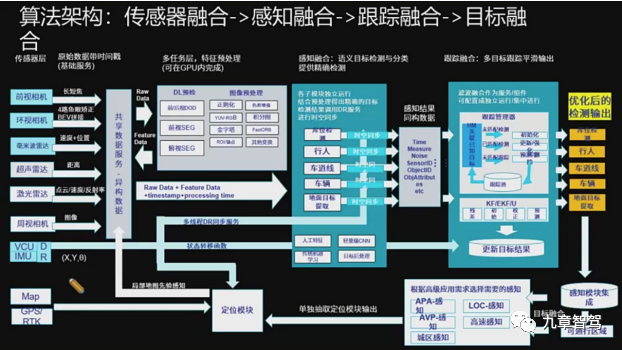 ?
?
追勢科技城市記憶領航功能算法架構
雖然在理論上,方案可行性沒有大問題,不過在實際落地中也有不少挑戰。
最大的挑戰是精度,相比于高精地圖,BEV語義地圖的精度是略有不足的,而傳統智能駕駛算法架構中,下游的規控任務都依賴高精地圖提供精確的drive line,當面對上游給個“不那么精確”或者“大方向上正確”的語義地圖時,要保證通過率,下游的規控邏輯也需要相應地調整。
不過,并不是說地圖就完全不需要了,地圖畢竟是超視距傳感器,對于提前預知下個路口的道路拓撲結構還是很有幫助的。追勢科技的城市記憶領航輔助中,也只有當特定路線的語義地圖成熟、完整時,才可以啟用記憶領航功能。
只是可能以后地圖的精度不需要像現在的高精地圖一樣那么高了,有專家表示“可能未來導航地圖上加一些語義信息就可以滿足要求了”
BEV模型和數據的通用性
不同的量產車型中,攝像頭的數量、安裝位置和具體參數存在較大的差異,使用傳統后融合策略時,這些定制化的傳感器適配帶來了巨大的工作量。
那么,在BEV空間進行中融合時,是否會有差異呢?
一方面,在適配不同車型時,是否和傳統的后融合有差異呢? 另一方面,從不同量產車型回傳回來的數據,是否能夠用于持續迭代統一的BEV感知模型呢?
如何適配不同車型 ??
由于傳統后融合太依賴人工后處理規則,在傳感器適配時,有諸多的無比痛苦的定制化工作,可能安裝位置或者視角稍微調整一下,就需要花大量的時間適配。
與后融合方案相比,BEV感知模型由于少了很多人工規則,通用能力要出色得多,雖然也需要做一些適配,但是整體工作量還是要少地多。
“換一個新車型,相機安裝位置變了,這時候需要把相機重新標定一下,再采集數據訓練一下,”一位行業專家說道。
為了提升BEV模型的泛化能力,一般可以通過預先設置??結構化參數來適配不同車型(比如安裝高度、安裝位置、角度等),這樣就可以在模型訓練時排除相機內外參的影響。
不過也有一些模型,如BEVerse等,嘗試把相機的內外參作為信號輸入,直接給到模型進行訓練,讓神經網絡自己去學著利用這些信息做適配,這樣適配會更加方便,不過這也對BEV網絡架構的設計提出了更高的要求。
回傳數據的通用性
業內專家普遍認為,不同車型上的攝像頭雖然可能位置、數量不同,但回傳回來的數據(如圖像、視頻流)轉換到BEV空間后,都可以很方便地用于訓練BEV模型。
只是考慮到位置差異,在使用車端攝像頭數據時,需要對多攝像頭的重合部分做一下處理。
其實環視攝像頭的視野重合部分并不多,前向多個不同FOV的攝像頭會有較多重合部分。
要處理這種重合部分,可以采用拼接技術。每一張圖像都有自己的特征點,數據采集后,先根據圖像的特征點,對特征點相似的圖像進行特征匹配(圖像匹配),從而找到鄰接圖并將相鄰的圖像拼接在一起(圖像拼接),然后就對特征相同的不同分辨率的圖像進行融合(圖像融合)。完成圖像融合后,只需要把相鄰幀圖進行拼接成視頻(視頻融合),整個過程就完成了。
具體過程如下圖所示。
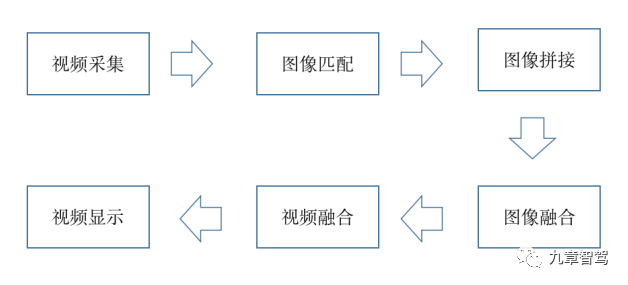
拼接流程
圖像匹配過程中很關鍵的環節是圖像特征點的獲取和匹配。這可以通過SIFT、SURF等方法來實現,不過為了提升計算效率,業內一般通過降采樣(類似于降低分辨率)的方式來進行特征檢測。
在圖像融合時,一般可用泊松算法、直接平均算法和加權算法等方法,直接平均算法業內用得更多一些。
除了上述的圖像拼接外,為了消除不同車型的差異,業內還用到一種叫“虛擬相機”的方法來共享訓練數據,“就是將圖像投影到一個標準的視角上(訓練時用的視角),投影后的相機就叫虛擬相機,這樣就能保證回傳數據和訓練數據的視角相同了,”一位行業專家介紹道。
除了上述提到的視角問題外,一位行業專家也提到ISP( Image Signal Process, 圖像信號處理)的處理也可能會影響數據的通用性。不同攝像頭的ISP不同,對Raw data的處理方式也不同,雖然可以通過技術手段來解決(如通過圖像預處理統一到同一個色彩空間下),但也可能會影響到感知結果,“就像人帶著墨鏡看世界一樣,看一般物體可能不受影響,看紅綠燈就可能會受到一些影響”,這位專家解釋道。
BEV技術的局限性與挑戰
BEV解決不了視覺的“先天缺陷” ??在傳統的2D檢測時,檢測、分類和跟蹤任務,都是依賴有監督學習的訓練,也就是說感知網絡只能識別出之前“見過”的物體,對于之前沒“見過”的物體(即訓練數據集里沒有的),是識別不出來的,從而會出現“不認識就看不見”的現象,這也被認為是視覺的“先天缺陷”。比如少見的異形物體,如披薩盒,高速上奔跑的野生動物等,這種情況可能出現的概率并不高,但是一旦出現可能是致命的。
那么這個問題,在轉換到BEV空間后,可以解決嗎?
業內專家給的答案很一致:不能。
BEV模型沒有訓練過的物體,在BEV空間內,可能是“不存在”的。
不過仍然有其他辦法來彌補這個缺陷,具體如下:
01 深度(Depth)估計
當前在2D感知方案中應用比較廣泛的是底層視覺感知(low level vision)中的深度估計。
深度估計一般是通過激光雷達的稀疏點云提供的真值進行訓練,從而利用深度學習直接預測出稠密的深度值。通過預測深度就可以一定程度上解決異形物體問題。
如下圖所示的右側的拉了樹木的大車,如果使用普通的車輛檢測,因為這種訓練樣本極少,可能會漏檢,而采用深度估計,至少可以知道該處有物體,可以及時采取措施,避免安全事故。  ?
?
單目深度估計
引自地平線蘇治中主題為“面向規模化量產的自動駕駛感知研發與實踐”的線上分享
在BEV空間中,可以把底層視覺靜態感知到的深度預估,轉化為路面上的高度信息。下圖所示為一幀所感知到的結果,藍色表示路面,高度比較低,紅色表示凸起,紅色越深表示高度越高,也能看到一些地面上的凸起物體,可以根據識別出來的物體類別進行后續的決策規劃,如果是無法識別的異形物體,那么最安全的方式就是避開它。

BEV空間中的底層視覺感知
引自地平線架構師劉景初主題為“上帝視角與想象力——自動駕駛感知的新范式”的線上分享
鑒智機器人推出的視覺雷達也是采用類似的原理,通過前向雙目相機和環視相機產生深度信息生成稠密點云,并在BEV空間內進行目標檢測。  ?
?
鑒智機器人提出的視覺雷達算法架構
02 數據驅動
當然,底層視覺感知的深度估計也不是萬能的,如果遇到一個沒訓練過的數據,可能在特征提取時就忽略了,所以,要解決這個問題的另一種方法就是數據驅動。
數據驅動依賴數據閉環工具鏈,各家也都開發了工具鏈系統,比如毫末智行的LUCAS、地平線的AIDI等。
03 多傳感器冗余
在純視覺不能保證百分之百安全的情況下,采用多傳感器冗余的方案成為了眾多主機廠的選擇,尤其是激光雷達,是對視覺非常好的補充。車端裝了激光雷達之后,由于有更高精度的數據,能給視覺提供更好的真值數據,也能更好地訓練視覺算法。
就像均勝電子郭繼舜在一次線上分享時提到的,在不能保證完全安全的情況下,系統設計時考慮傳感器冗余、硬件堆料等是非常必要的,也是“系統設計的正義”。
BEV感知的挑戰
總體而言,BEV是個全新的感知范式,向上下游(如定位和預測)都有很大的拓展空間,業內很多企業也都在積極探索實踐中,但在實踐中還有很多的挑戰需要克服。
01 數據問題
上文也提到了,BEV感知中最具備挑戰的還是如何獲取更多維度的數據,以及產生更高質量的真值。加上Transformer本身的特性,為更好地發揮優勢,其對數據量的要求也比傳統卷積神經網絡大得多,這就越發加劇了模型對數據的“饑渴”程度。
要應對這個挑戰,一方面依賴車端影子模式持續不斷地采集數據,另一方面也依賴云端系統去做數據挖掘和真值生成,這需要持續不斷地去優化云端真值系統的算法。
此外,為了減少標注工作量,提升訓練效率,自監督學習也開始被引入到云端系統中。 和有監督學習不同,自監督學習的真值信息不是人工標注的,而是算法自動構造監督信息(真值),來進行監督學習或訓練。當前自監督學習已經被應用在數據挖掘、數據標注和神經網絡的預訓練中。
02 算力消耗問題
上文也提到過,由于使用Transfomer進行BEV空間轉化非常消耗算力,對車端有限算力提出了挑戰。 目前主要有兩個優化的方向:
2.1模型輕量化
圖像處理中,使用Transformer的計算復雜度與圖像尺寸的平方成正比,這會導致,在圖像很大的時候,計算量過于龐大。
如何在盡量不影響感知精度的前提下,降低Transformer的計算復雜度,節省車端算力,成了學術界和工業界普遍關注的問題。
為了解決這個問題,可以借鑒使用傳統CNN中的模型壓縮技巧來降低計算復雜度,比如:
剪枝:深度學習模型可以看作是一個復雜樹狀結構,如果能減去一些對結果沒什么影響的旁枝,就可以實現模型的減小。
量化:深度學習模型由大量的浮點型(float)權重參數組成,如果能用低精度類型(如int8)替代原有的高精度類型(如float32)的權重參數,那么模型體積就會大大壓縮,低位的浮點計算速度會遠遠高于高位浮點計算速度,這也是最容易實現的壓縮方式。
此外,學術界也有一些最新的成果,可以供業界參考。 使用移動窗口操作(Shifted windowscheme)、具有層級設計的(hierarchicalarchitecture)的SwinTransformer,可以把計算復雜度大幅度降低到具有輸入圖像大小線性計算的復雜度,且在各種圖像任務上也都有很好的性能,因而SwinTransformer可以被當做骨干網絡來使用。
借鑒了DCN(Deformable Convolutional Networks,可變形卷積網絡)的思想,Deformable DETR將DETR中的注意力機制替換成可變形注意力機制(與全局(global)&密集(dense)的注意力機制不同,可變形注意力機制能夠聚焦于特征相關區域并捕獲信息,從而實現局部(local)&稀疏(sparse)的高效注意力機制),使DETR范式的檢測器更加高效,收斂速度也大大加快,并且給了業界啟發,可以將可變形注意力泛化,形成了Deformable Transformer。
2.2多任務模型
除了上述模型壓縮技巧外,還有一個常用的技巧,就是共享權重,有點像提取公因數,假設模型的每一層都有公用的公因數,是否可以提取出來做一次運算,而不是每一層都算一次,如共享骨干網絡等,這就是應用普遍的多任務模型(Multi-Task learning)。
其中最出名的多任務模型,莫過于特斯拉的HydraNet,在一個模型中同時實現了目標檢測、紅綠燈檢測和車道線檢測三個任務。
使用多任務模型最明顯的優勢,就是因為共享特征提取的網絡參數,避免了大量的重復計算,效率大大提升。
除此外,多任務模型還有個額外好處,就是有時可以加速網絡的訓練過程。因為共享網絡的感知任務是強相關的,比如車道線檢測和動態目標檢測,在訓練其中一個任務時,共享網絡的特征提取能力也加強了,對于另外的任務的性能提升也是有幫助的。
那有沒有可能在訓練多任務模型的時候出現不同的任務“相互傷害”“此消彼長”的現象呢?
據地平線蘇治中的線上分享中提到的,這種情況是有可能的,不過也有技巧辦法可以解決。比如某個任務對其他任務傷害很大,就可以降低這個任務的學習速率(learning rate),降低它的權重,如果實在無法兼容,還可以單獨再新建一個模型去訓練這個任務。
比如BEVerse,就是在BEV空間內完成的多任務模型感知任務,完成了3D目標檢測、局部語義地圖和運動預測這三個任務,且每個模塊都達到了當前最優水平( SOTA)。
3. BEV算法更復雜、門檻更高
相比于傳統2D圖像檢測,BEV感知算法會復雜得多,尤其是前文提到的云端的3D重建、4D空間的標注、真值生成和模型訓練,都是之前2D感知任務中所沒有的,相應地難度和門檻自然也要高一些。
不過,朱政也提到,由于BEV感知進入大家的視野還不太算太久,各家還在摸索中,有些算法還沒那么成熟,等到后續量產實踐多起來了,開源的工具也慢慢多起來了,門檻也會慢慢降低,“就像四五年前其實2D感知也沒那么好做,不過現在成熟多了,有很多開源的算法,工具鏈也很成熟了,門檻就顯得沒那么高了,”朱政說道。
未盡之語
隨著如BEV和Transformer等諸多視覺算法的進展,視覺能力的上限也大大提升。
諸多業內專家也提到,即使量產車輛裝了激光雷達,在云端進行數據處理時,還是會以視覺為主,“畢竟,相比激光雷達先天的缺點(如點云稀疏、缺少語義信息等),視覺的優勢非常明顯,加上攝像頭出貨量更大,產業鏈更加成熟,后續升級也更加方便,比如可以很容易從800萬像素升級到1600萬像素,甚至現在手機攝像頭的像素已經過億了”,一位專家告訴九章智駕。
之前采訪一家進軍L2前裝量產市場的L4公司的CTO時,對方也提到,過去L4以激光雷達點云為主、視覺為輔的方案是有其歷史原因的,因為那時基于深度學習的視覺算法還不成熟,能支持深度學習的大算力平臺也不成熟,不過目前,視覺在L4方案中占的分量會越來越重,甚至未來有可能超過激光雷達。
隨著圖像轉化到BEV空間后,也可以直接借鑒激光雷達、毫米波雷達領域的研究方法和進展。如果未來進一步繞過ISP,直接將RAW DATA輸入到感知模型中,可進一步提升視覺在極限條件下(極暗和極亮)的感知能力,可以想象,未來視覺能力會有更大的發展,讓我們拭目以待。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100718 -
多傳感器
+關注
關注
0文章
80瀏覽量
15356 -
IPM
+關注
關注
5文章
161瀏覽量
38940
原文標題:一文讀懂BEV空間內的特征級融合
文章出處:【微信號:智能汽車電子與軟件,微信公眾號:智能汽車電子與軟件】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
探討智慧校園的特征與優勢
淺析基于自動駕駛的4D-bev標注技術

如何對電磁頻譜特征進行分析
自動駕駛中一直說的BEV+Transformer到底是個啥?

FPGA在圖像處理領域的優勢有哪些?
毫米波雷達具有哪些特點和優勢
訊維融合通信系統在醫療領域的應用:打破時間與空間的限制
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
黑芝麻智能開發多重亮點的BEV算法技術 助力車企高階自動駕駛落地

工業級路由器的性能優勢
基于Transformer的多模態BEV融合方案
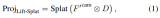
BEV和Occupancy自動駕駛的作用

自動駕駛領域中,什么是BEV?什么是Occupancy?

超融合的優勢和劣勢
基于LSS范式的BEV感知算法優化部署詳解






 工商網監
工商網監
評論