") 介紹大模型高效訓練所需要的主要技術(shù)
介紹大模型高效訓練所需要的主要技術(shù)
本文分為三部分介紹了大模型高效訓練所需要的主要技術(shù),并展示當前較為流行的訓練加速庫的統(tǒng)計。
引言:隨著BERT、GPT等預訓練模型取得成功,預訓-微調(diào)范式已經(jīng)被運用在自然語言處理、計算機視覺、多模態(tài)語言模型等多種場景,越來越多的預訓練模型取得了優(yōu)異的效果。為了提高預訓練模型的泛化能力,近年來預訓練模型的一個趨勢是參數(shù)量在快速增大,目前已經(jīng)到達萬億規(guī)模。
但如此大的參數(shù)量會使得模型訓練變得十分困難,于是不少的相關(guān)研究者和機構(gòu)對此提出了許多大模型高效訓練的技術(shù)。本文將分為三部分來介紹大模型高效訓練所需要的主要技術(shù):并行訓練技術(shù)、顯存優(yōu)化技術(shù)和其他技術(shù)。文章最后會展示當前較為流行的訓練加速庫的統(tǒng)計。歡迎大家批評指正,相互交流。
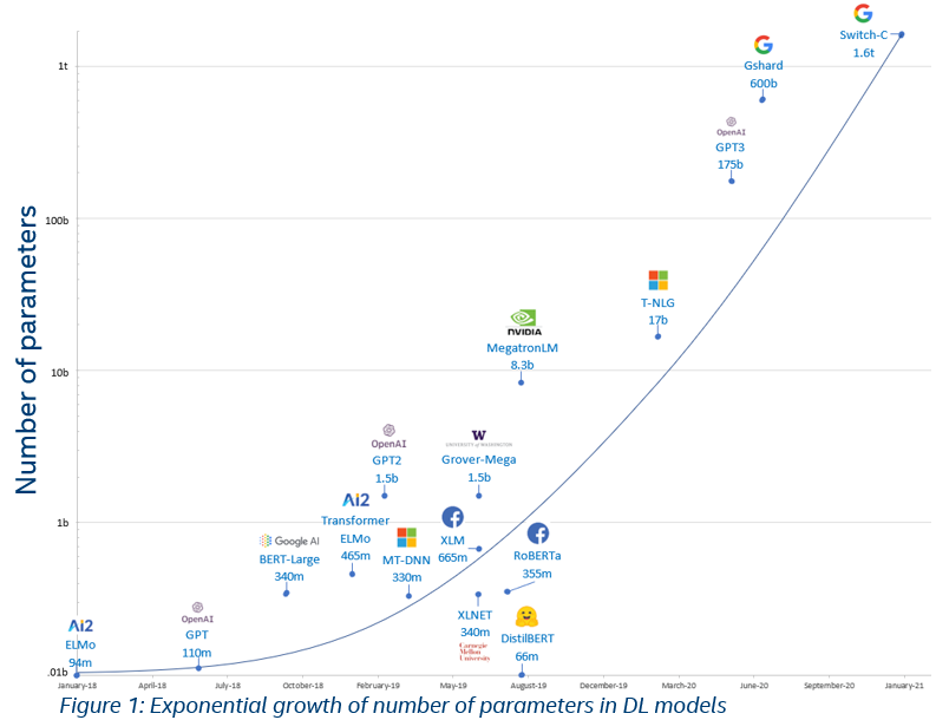
預訓練模型參數(shù)量增長趨勢
一、并行訓練技術(shù):
并行訓練技術(shù)主要是如何使用多塊顯卡并行訓練模型,主要可以分為三種并行方式:數(shù)據(jù)并行(Data Parallel)、張量并行(Tensor Parallel)和流水線并行(Pipeline Parallel)。
數(shù)據(jù)并行(Data Parallel)
數(shù)據(jù)并行是目前最為常見和基礎(chǔ)的并行方式。這種并行方式的核心思想是對輸入數(shù)據(jù)按 batch 維度進行劃分,將數(shù)據(jù)分配給不同GPU進行計算。
在數(shù)據(jù)并行里,每個GPU上存儲的模型、優(yōu)化器狀態(tài)是完全相同的。當每塊GPU上的前后向傳播完成后,需要將每塊GPU上計算出的模型梯度匯總求平均,以得到整個batch的模型梯度。
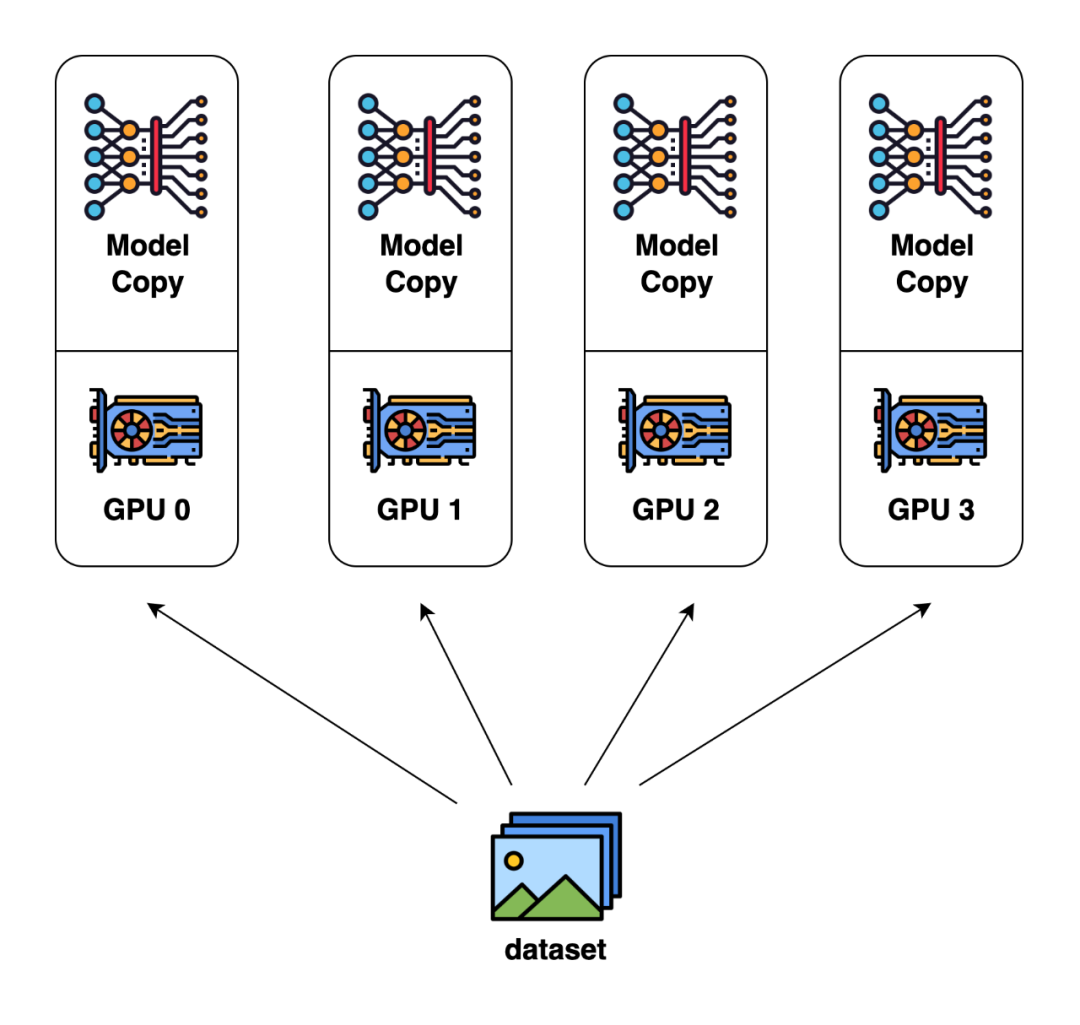
數(shù)據(jù)并行(圖片來自 Colossal-AI 的文檔)
目前 PyTorch 已經(jīng)支持了數(shù)據(jù)并行 [1]:
https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
張量并行(Tensor Parallel)
在訓練大模型的時候,通常一塊GPU無法儲存一個完整的模型。張量并行便是一種使用多塊GPU存儲模型的方法。
與數(shù)據(jù)并行不同的是,張量并行是針對模型中的張量進行拆分,將其放置到不同的GPU上。比如說對于模型中某一個線性變換Y=AX,對于矩陣A有按列拆解和按行拆解兩種方式:
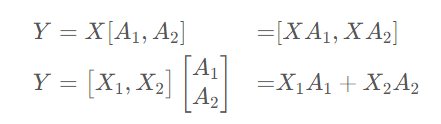
我們可以將矩陣A1和A2分別放置到兩塊不同的GPU上,讓兩塊GPU分別計算兩部分矩陣乘法,最后再在兩張卡之間進行通信便能得到最終的結(jié)果。
同理也可以將這種方法推廣到更多的GPU上,以及其他能夠拆分的算子上。
下圖是Megatron-LM[2] 在計算 MLP 的并行過程,它同時采用了這兩種并行方式:
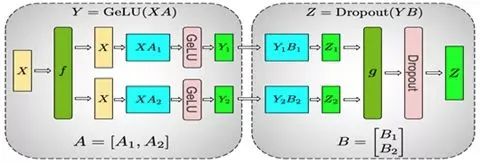
整個MLP的輸入X先會復制到兩塊GPU上,然后對于矩陣A采取上面提到的按列劃分的方式,在兩塊GPU上分別計算出第一部分的輸出Y1和Y2。
接下來的 Dropout 部分的輸入由于已經(jīng)按列劃分了,所以對于矩陣B則采取按行劃分的方式,在兩塊GPU上分別計算出Z1和Z2。最后在兩塊GPU上的Z1和Z2做All-Reduce來得到最終的Z。
以上方法是對矩陣的一維進行拆分,事實上這種拆分方法還可以擴展到二維甚至更高的維度上。在Colossal-AI中,他們實現(xiàn)了更高維度的張量并行:
https://arxiv.org/abs/2104.05343 https://arxiv.org/abs/2105.14500 https://arxiv.org/abs/2105.14450
對于序列數(shù)據(jù),尤洋團隊還提出了Sequence Parallel來實現(xiàn)并行:
https://arxiv.org/abs/2105.13120
流水線并行(Pipeline Parallel)
和張量并行類似,流水線并行也是將模型分解放置到不同的GPU上,以解決單塊GPU無法儲存模型的問題。和張量并行不同的地方在于,流水線并行是按層將模型存儲的不同的GPU上。
比如以Transformer為例,流水線并行是將連續(xù)的若干層放置進一塊GPU內(nèi),然后在前向傳播的過程中便按照順序依次計算hidden state。反向傳播也類似。下圖便是流水線并行的示例:
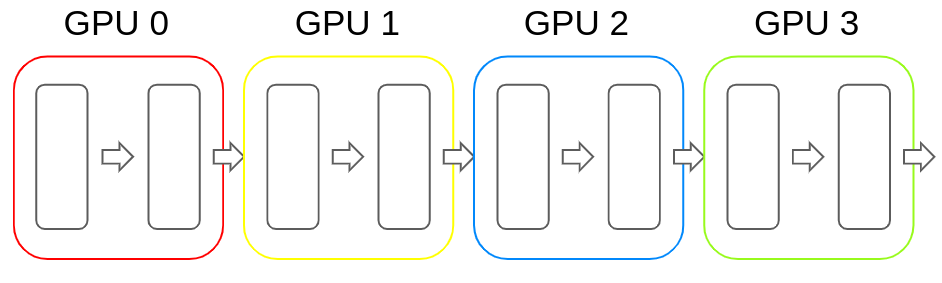
但樸素的流水線并行實現(xiàn)會導致GPU使用率過低(因為每塊GPU都要等待之前的GPU計算完畢才能開始計算),使流水線中充滿氣泡,如下圖所示:
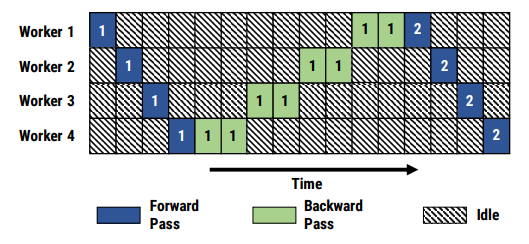
有兩種比較經(jīng)典的減少氣泡的流水線并行算法:GPipe[7] 和PipeDream[8]
GPipe 方法的核心思想便是輸入的minibatch劃分成更小的 micro-batch,讓流水線依次處理多個 micro batch,達到填充流水線的目的,進而減少氣泡。GPipe 方法的流水線如下所示:
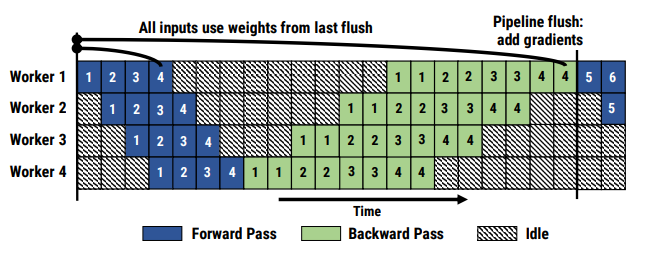
PipeDream 解決流水線氣泡問題的方法則不一樣,它采取了類似異步梯度更新的策略,即計算出當前 GPU 上模型權(quán)重的梯度后就立刻更新,無需等待整個梯度回傳完畢。相較于傳統(tǒng)的梯度更新公式:
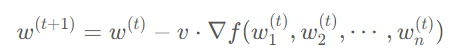
PipeDream 的更新公式為:
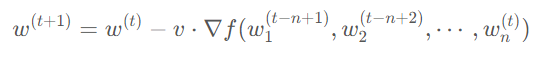
由于這種更新方式會導致模型每一層使用的參數(shù)更新步數(shù)不一樣多,PipeDream 對上述方法也做出了一些改進,即模型每次前向傳播時,按照更新次數(shù)最少的權(quán)重的更新次數(shù)來算,即公式變?yōu)椋?/p>
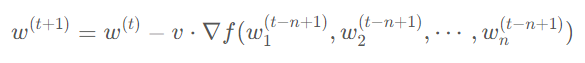
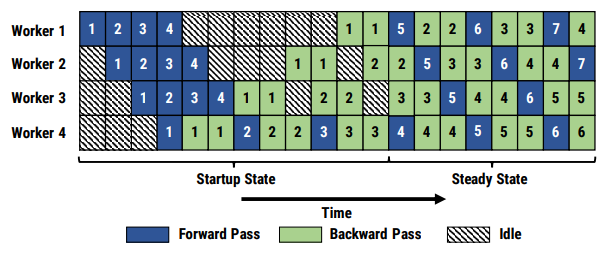
PipeDream 方法的流水線如下所示:
對比總結(jié)
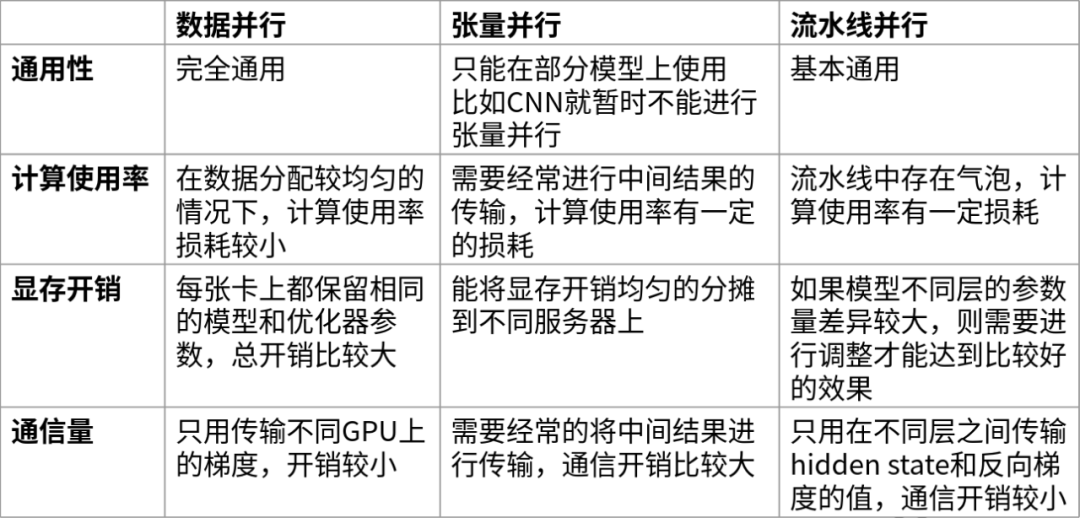
下面是對這三種并行技術(shù)從通用性、計算效率、顯存開銷和通信量這幾個方面進行對比。
可以看出數(shù)據(jù)并行的優(yōu)勢在于通用性強且計算效率、通信效率較高,缺點在于顯存總開銷比較大;而張量并行的優(yōu)點是顯存效率較高,缺點主要是需要引入額外的通信開銷以及通用性不是特別好;流水線并行的優(yōu)點除了顯存效率較高以外,且相比于張量并行的通信開銷要小一些,但主要缺點是流水線中存在氣泡。
二、顯存優(yōu)化技術(shù):
在模型訓練的過程中,顯存主要可以分為兩大部分:常駐的模型及其優(yōu)化器參數(shù),和模型前向傳播過程中的激活值。顯存優(yōu)化技術(shù)主要是通過減少數(shù)據(jù)冗余、以算代存和壓縮數(shù)據(jù)表示等方法來降低上述兩部分變量的顯存使用量,大致可分為四大類:ZeRO技術(shù)、Offload技術(shù)、checkpoint技術(shù)以及一些節(jié)約顯存的優(yōu)化器。
ZeRO 技術(shù)
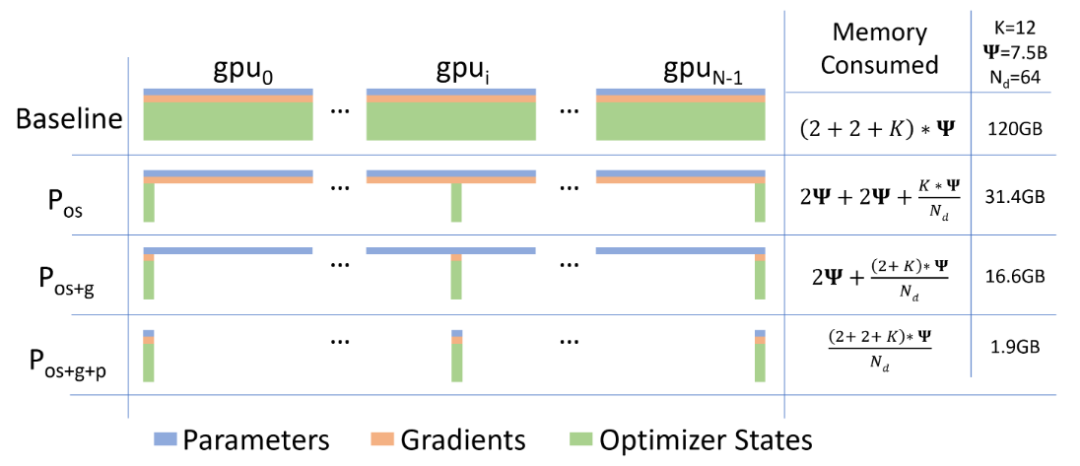
ZeRO[9] 技術(shù)是微軟的 DeepSpeed 團隊解決數(shù)據(jù)并行的中存在的內(nèi)存冗余問題所提出的解決方法。常駐在每塊GPU上的數(shù)據(jù)可以分為三部分:模型參數(shù),模型梯度和優(yōu)化器參數(shù)。注意到由于每張 GPU 上都存儲著完全相同的上述三部分參數(shù),我們可以考慮每張卡上僅保留部分數(shù)據(jù),其余的可以從其他 GPU 上獲取。
即假如有N張卡,我們可以讓每張卡上只保存其中1/N的參數(shù),需要的時候再從其他 GPU 上獲取。ZeRO 技術(shù)便是分別考慮了上述三部分參數(shù)分開存儲的情況,下圖中的Pos、Pos+g和Pos+g+p就分別對應(yīng)著將優(yōu)化器參數(shù)分開存儲、將優(yōu)化器參數(shù)和模型梯度分開存儲以及三部分參數(shù)都分開存儲三種情況。
論文里不僅分析了三種情況可以節(jié)省的內(nèi)存情況,還分析出了前兩種優(yōu)化方法不會增加通信開銷,第三種情況的通信開銷只會增加50%。
目前Pytorch也已經(jīng)支持了類似的技術(shù):
https://engineering.fb.com/2021/07/15/open-source/fsdp/ https://pytorch.org/docs/stable/fsdp.html
Offload 技術(shù)
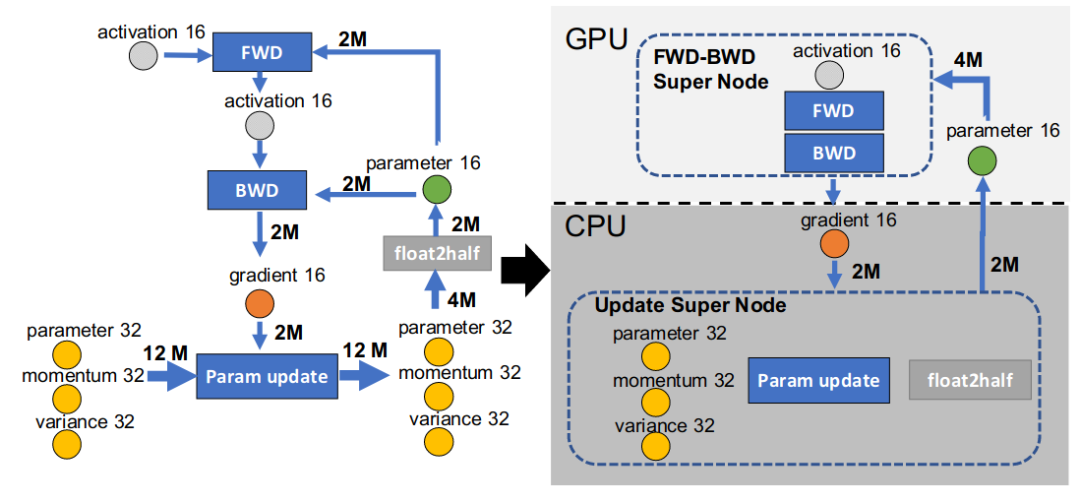
ZeRO-Offload[10] 技術(shù)主要思想是將部分訓練階段的模型狀態(tài) offload 到內(nèi)存,讓 CPU 參與部分計算任務(wù)。
為了避免 GPU 和 CPU 之間的通信開銷,以及 CPU 本身計算效率低于 GPU 這兩個問題的影響。Offload 的作者在分析了 adam 優(yōu)化器在 fp16 模式下的運算流程后,考慮只將模型更新的部分下放至 CPU 計算,即讓 CPU 充當 Parameter Server 的角色。如下圖所示:
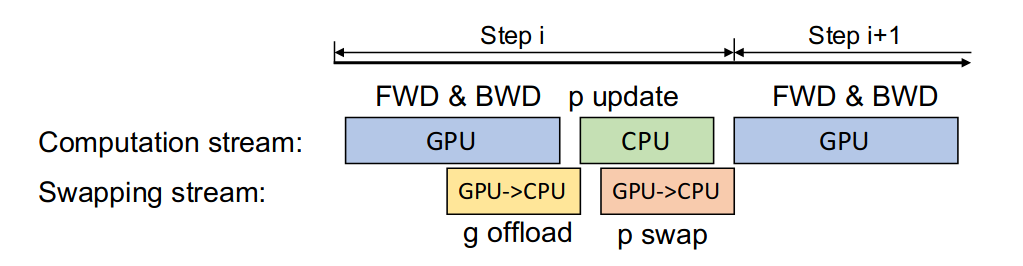
同時為了提高效率,Offload 的作者提出可以將通信和計算的過程并行起來,以降低通信對整個計算流程的影響。
具體來說,GPU 在反向傳播階段,可以待梯度值填滿bucket后,一邊計算新的梯度一邊將bucket傳輸給CPU;當反向傳播結(jié)束,CPU基本上獲取了最新的梯度值。同樣的,CPU在參數(shù)更新時也同步將已經(jīng)計算好的參數(shù)傳給GPU,如下圖所示:
最后作者也分析了多卡的情況,證明了他提出的方案具有可擴展性。
Checkpoint 技術(shù)
在模型前向傳播的過程中,為了反向傳播計算梯度的需要,通常需要保留一些中間變量。例如對于矩陣乘法
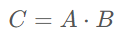
A和B的梯度計算公式如下所示
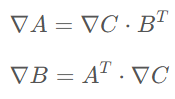
可以看出要想計算A和B的梯度就必須在計算過程中保留A和B本身。這部分為了反向傳播所保留的變量會占用不小的空間。Checkpoint技術(shù)的核心是只保留checkpoint點的激活值,checkpoint點之間的激活值則在反向傳播的時候重新通過前向進行計算。可以看出,這是一個以算代存的折中方法。最早是陳天奇將這個技術(shù)引入機器學習中 [11]:
https://arxiv.org/abs/1604.06174
目前該方法也以及被 PyTorch 所支持。
https://pytorch.org/docs/stable/checkpoint.html
節(jié)約顯存的優(yōu)化器
比較早期的工作是如Adafactor[12] 主要是針對 Adam 進行優(yōu)化的,它取消了 Adam 中的動量項,并使用矩陣分解方法將動量方差項分解成兩個低階矩陣相乘來近似實現(xiàn) Adam 的自適應(yīng)學習率功能。
后來也有使用低精度量化方式存儲優(yōu)化器狀態(tài)的優(yōu)化器,如8 bit Optimizer[13],核心思想是將優(yōu)化器狀態(tài)量化至 8 bit 的空間,并通過動態(tài)的浮點數(shù)表示來降低量化的誤差。還有更加激進的使用 1 bit 量化優(yōu)化器的方法,如1-bit Adam[14] 和1-bit LAMB[15]。他們主要是使用壓縮補償方法的來減少低精度量化對模型訓練的影響。
三、其他優(yōu)化技術(shù):
大批量優(yōu)化器
在目前模型訓練的過程中,直接使用大批量的訓練方式可能導致模型訓練不穩(wěn)定。最早有 Facebook 的研究[16] 表明,通過線性調(diào)整學習率,并配合 warmup 等輔助手段,讓學習率隨 batch 的增大而線性增大,即可在ResNet-50上將 batch size 增大至 8K 時仍不影響模型性能。
但該方法在 AlexNet 等網(wǎng)絡(luò)失效,在LARS[17] 優(yōu)化器這篇論文中,作者尤洋在實驗中發(fā)現(xiàn)不同層的權(quán)值和其梯度的 2 范數(shù)的比值差異很大,據(jù)此基于帶動量的SGD優(yōu)化器提出LARS優(yōu)化器。核心算法如下圖所示:

基于以上的思路,尤洋將上述方法擴展到Adam優(yōu)化器,提出了LAMB[18] 優(yōu)化器:

FP16
FP16[19] 基本原理是將原本的32位浮點數(shù)運算轉(zhuǎn)為16位浮點數(shù)運算。一方面可以降低顯存使用,另一方面在 NVIDIA 的顯卡上 fp16 的計算單元比 fp32 的計算單元多,可以提升計算效率。在實際的訓練過程中,為了保證實際運算過程中的精度,一般還會配合動態(tài)放縮技術(shù)。目前的主流框架都已實現(xiàn)該功能。
算子融合
算子融合實際上是將若干個 CUDA 上的運算合成一個運算,本質(zhì)上是減少了 CUDA 上的顯存讀寫次數(shù)。舉個例子,對于一個線性層 + batch norm + activation 這個組合操作來說:
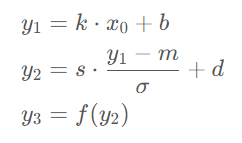
直接使用 PyTorch 實現(xiàn)的會在計算y1,y2,y3的過程中分別產(chǎn)生一次顯存的讀和寫操作,即3次讀和寫。如果將其按下面的公式合并成一個算子進行計算,那么中間的結(jié)果可以保留在 GPU 上的寄存器或緩存中,從而將顯存讀寫次數(shù)降低至1次。
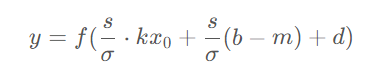
目前 PyTorch 可以使用 torch.jit.script 來將函數(shù)或 nn.Module 轉(zhuǎn)化成 TorchScript 代碼,從而實現(xiàn)算子融合。
https://pytorch.org/docs/stable/generated/torch.jit.script.html
設(shè)備通信算法
在之前介紹的模型分布式訓練中,通常需要在不同 GPU 之間傳輸變量。在 PyTorch 的 DataParallel 中,使用的是Parameter Server架構(gòu),即存在一個中心來匯總和分發(fā)數(shù)據(jù):
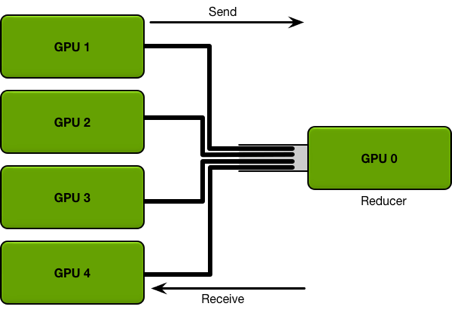
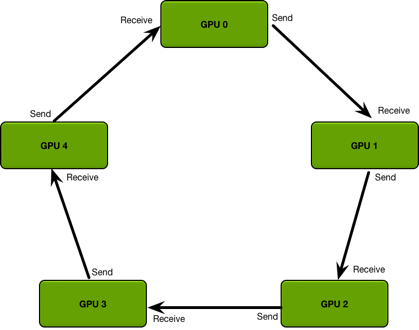
但上述方式的缺點是會導致 Parameter Server 成為通信瓶頸。之后PyTorch的Distributed DataParallel則使用了Ring All-Reduce[20] 方法,將不同的GPU構(gòu)成環(huán)形結(jié)構(gòu),每個GPU只用與環(huán)上的鄰居進行通信:
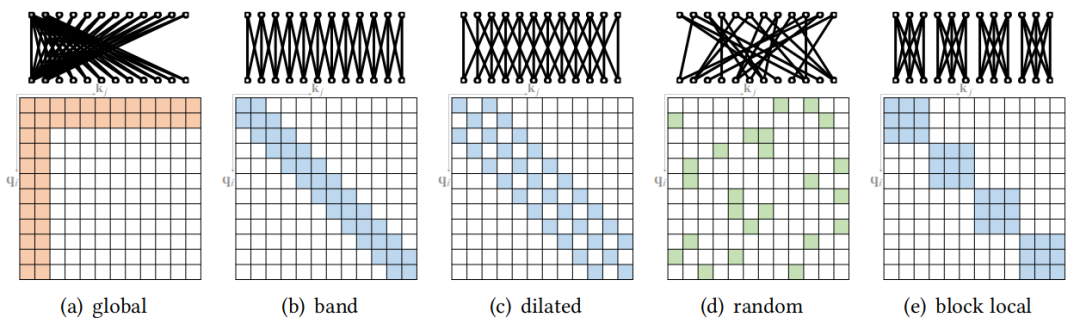
稀疏attention
稀疏Attention技術(shù)最開始是運用在長序列的Transformer建模上的,但同時也能有效的降低模型計算的強度。稀疏Attention主要方法可以分為以下五類 [21]:
目前DeepSpeed已經(jīng)集成了這個功能:
https://www.deepspeed.ai/tutorials/sparse-attention/
自動并行
目前并行訓練技術(shù)在大模型訓練中已被廣泛使用,通常是會將前面介紹的三種并行方法結(jié)合起來一起使用,被稱之為 3D 并行。
但這些并行方式都有不少的訓練超參數(shù),之前的一些研究者是使用手動的方式來設(shè)置這些超參數(shù)。目前也出現(xiàn)了不少自適應(yīng)的方法來設(shè)置超參數(shù),被稱為自動并行技術(shù)。
這些方法包括動態(tài)規(guī)劃、蒙特卡洛方法、強化學習等。下面的 GitHub 倉庫整理了一些自動并行的代碼和論文:
https://github.com/ConnollyLeon/awesome-Auto-Parallelism
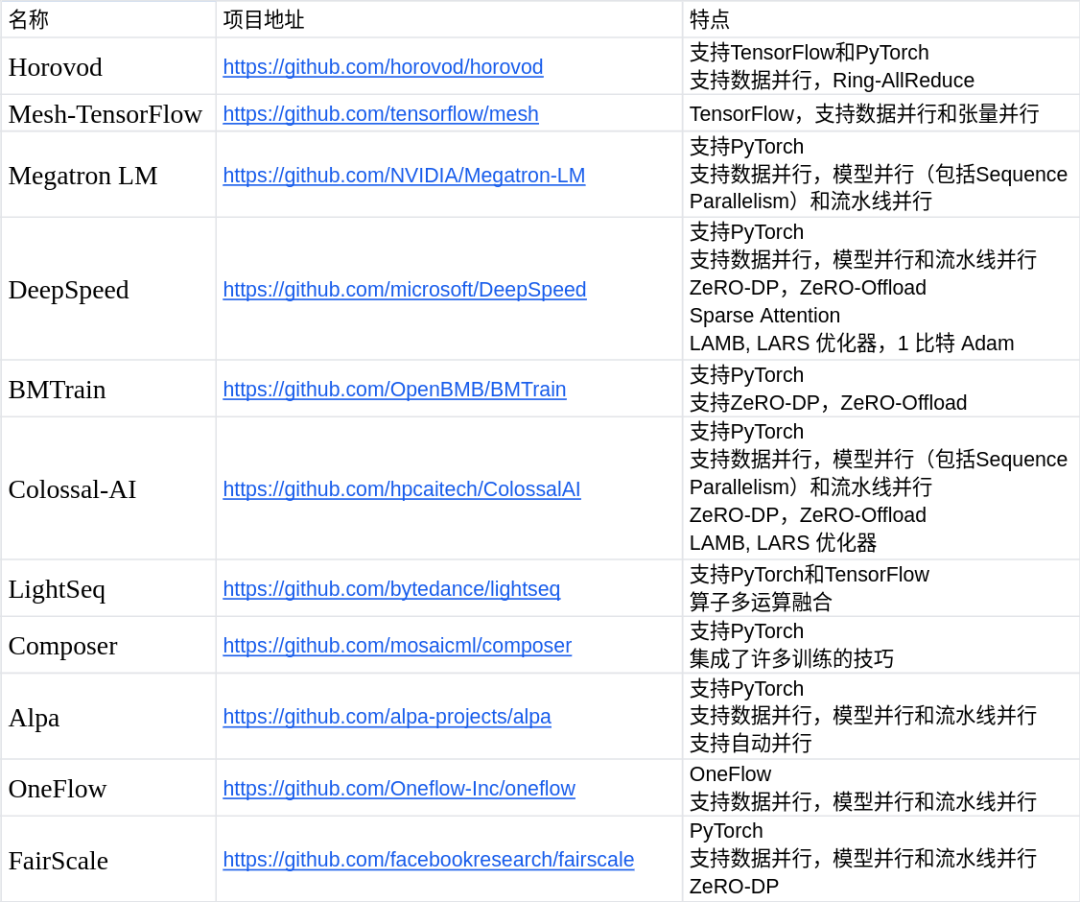
四、訓練加速庫概覽
下面是本人對當下比較流行的訓練加速庫的統(tǒng)計,可供大家進行參考。
審核編輯:劉清
-
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128890 -
GPT
+關(guān)注
關(guān)注
0文章
352瀏覽量
15343 -
MLP
+關(guān)注
關(guān)注
0文章
57瀏覽量
4241 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2643
原文標題:Huge and Efficient! 一文了解大規(guī)模預訓練模型高效訓練技術(shù)
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何在SAM時代下打造高效的高性能計算大模型訓練平臺
芯耀輝DDR PHY訓練技術(shù)簡介
【大語言模型:原理與工程實踐】核心技術(shù)綜述
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】大語言模型的預訓練
Pytorch模型訓練實用PDF教程【中文】
醫(yī)療模型人訓練系統(tǒng)是什么?
如何進行高效的時序圖神經(jīng)網(wǎng)絡(luò)的訓練
基于速度追蹤原理實現(xiàn)目標模擬訓練系統(tǒng)的設(shè)計
探究超大Transformer語言模型的分布式訓練框架
DGX SuperPOD助力助力織女模型的高效訓練
深度學習如何訓練出好的模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論