 英偉達推出A800 GPU,為了能賣給中國客戶,對A100“砍了一刀”...
英偉達推出A800 GPU,為了能賣給中國客戶,對A100“砍了一刀”...
電子發燒友網報道(文/梁浩斌)當地時間本周一,英偉達官方確認將面向中國客戶推出一款型號為A800的GPU,以替代此前受到出口管制的A100 GPU芯片。英偉達表示,A800符合美國政府的出口管制條例,不能通過編程超過限制的性能。
今年8月的最后一天,英偉達發布公告稱,公司收到美國政府通知,要求對中國大陸以及中國香港、俄羅斯的客戶出口的高端GPU芯片,需要申請出口許可證,其中覆蓋到A100和H100等幾款GPU,同時未來性能等于或高于A100的產品都會受到該政策影響。隨后10月繼續加碼的出口限制,更是將申請出口許可證的產品類別覆蓋到更大的范圍,包括用于超級計算機、量子計算等的尖端芯片、技術、設備等。
值得一提的是,A800 GPU是美國半導體公司首次為中國市場推出符合美國貿易政策的先進芯片。在9月份,英偉達曾表示,新的出口管制規則可能會令公司損失數億美元的收入。而A800作為應對貿易政策而“定制”的產品,可謂進展神速,英偉達透露在今年第三季度已經投產,目前已經有一些國內經銷商已經拿到實物,并打出A800 GPU的廣告。
A100性能和A800幾乎一致,但互連帶寬被“砍一刀”
相信大家最關心的是A800跟此前的A100性能有什么差別,A800會不會是特供中國的“低配版”。其實從英偉達已經公開的參數來看,A800單卡算力在參數上幾乎是與A100是完全一致的。
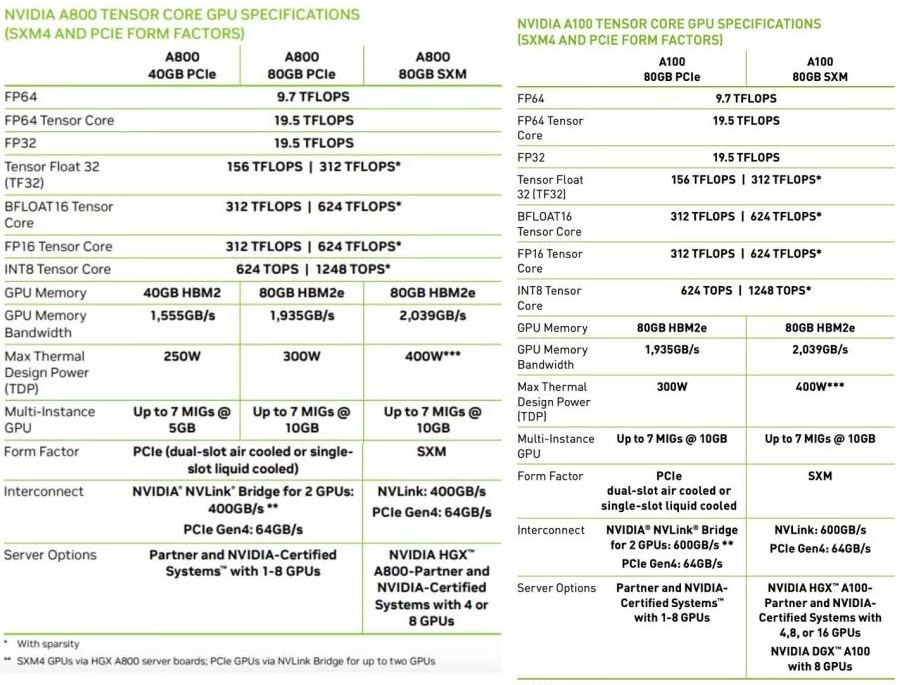
唯一的不同在于NVLink互連橋的帶寬縮水33%,從A100上的600GB/s砍至A800的400GB/s,這可能會影響到多卡服務器,比如數據中心、超級計算機的整體性能。
NVLink是英偉達在2014年發布的一種總線和通信協議,采用了點對點結構、串列傳輸,用于CPU和GPU之間,或是多個GPU之間的連接,相比通過PCIe總線互連的傳統方式,NVLink可以大幅提高交互效率。簡單來說,NVLink就是能在GPU和GPU、GPU和CPU之間實現高速大帶寬直連通信的互連技術。
圖源:英偉達
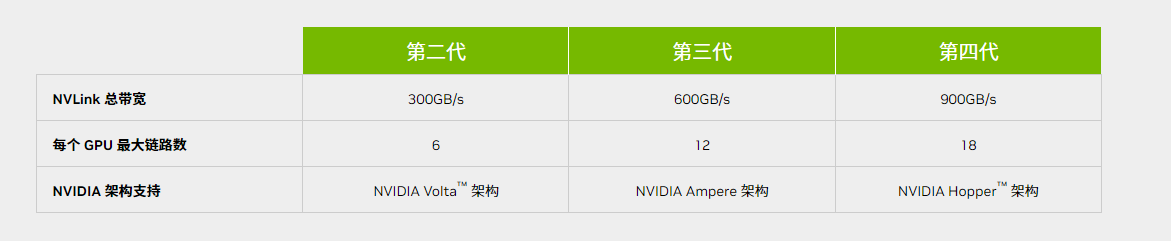
電子發燒友從英偉達官網上了解到,A100所支持的NVLink總帶寬達到600GB/s,屬于第三代產品。今年3月英偉達在GTC 2022上發布的第四代NVLink-C2C則可以實現高達900GB/s的總帶寬,是PCIe 5.0帶寬的七倍,并將互連技術擴展至芯片之間的互連,支持定制裸片與 NVIDIA GPU、CPU、DPU、NIC 和 SOC之間實現一致的互連。
而A800上的NVLink總帶寬為400GB/s,介于第二代和第三代之間。在AI和HPC等領域中,GPU之間的互連帶寬降低,對于動輒數千塊GPU組成的計算集群而言顯然會造成不小的性能損失。
國內自動駕駛行業首當其沖,誰能替代英偉達?
自動駕駛技術開發,是一項需要大量算力進行AI模型訓練、計算的密集型工作。作為AI模型訓練的核心之一,英偉達的GPU產品一直以來都是自動駕駛玩家的主要選擇。英偉達推出的HGX A100平臺就是專為AI場景設計的高性能服務器平臺,包含比如驅動自動駕駛汽車的模型,以及大型數據集等,官方宣稱可以將模型開發效率提高20倍。
對于自動駕駛項目而言,開發效率的提高意味著縮短自動駕駛汽車的上市周期,加速架構的迭代。在行業內,包括特斯拉目前也在大量應用英偉達GPU打造超算平臺。去年6月,特斯拉公布了公司內部用于訓練Autopilot與自動駕駛深度神經網絡的超級計算機,這個集群使用了720個節點的8個A100 GPU(共5760個),實現高達1.8 exaflops的總算力。
國內方面,蔚來在去年年底就宣布采用英偉達A100 GPU以及Mellanox InfiniBand ConnectX-6網卡構建超級計算機集群。
小鵬汽車在今年8月2日宣布與阿里云合作在烏蘭察布建成了中國最大的自動駕駛智算中心“扶搖”,采用阿里云智能計算平臺,算力可達600PFLOPS。雖然官方沒有公布該超算中心所用的硬件,但此前阿里云一直與英偉達有密切合作,今年3月阿里云和英偉達還合作推出了初創加速計劃,為初創企業提供算力緩解計算壓力。
另一方面小鵬汽車創始人何小鵬在9月份的朋友圈中評論了英偉達A100出口受限的事件,并表示“壞消息是這會對所有自動駕駛云端訓練帶來挑戰,好消息是剛好我們已經把未來幾年的需求提前買回來了。” 言下之意小鵬在自動駕駛AI模型訓練上所采用的GPU同樣來自英偉達。
因此,高端GPU的供應限制,給未來國內自動駕駛行業帶來了很大的不確定性,未來算力受限有可能成為抑制自動駕駛技術發展的關鍵因素。
當然,英偉達也在努力趕在出口的緩沖期盡量向中國完成更多交付。此前英偉達更新的最新消息稱,公司已經獲得了授權,可以使得A100和H100在2023年9月1日之前通過英偉達在相關的公司履行訂單和物流。
在9月份業內又傳出英偉達向臺積電下了“超級急件”訂單,要求臺積電提前生產原計劃在明年出貨的部分產品,交付期從原本的5-6個月縮短至2-3個月,總量約5000片晶圓。從時間上看,這批產品可能在11月前后可以向英偉達交貨。
可以預見,在近一年的緩沖期內,在目前沒有其他替代產品的情況下,國內廠商會加快采購相關產品,重點可能是相比A100性能提升高達450%的H100 GPU,這至少能保證在未來幾年內對算力的需求。
另一方面,英偉達與多家車企的自動駕駛已經進行深度綁定,包括蔚來、小鵬、極氪、輕舟智航等都已經宣布選擇英偉達下一代Thor自動駕駛芯片,但如今有了出口管制的先例,繼續在終端采用英偉達芯片難免會存在供應風險。
而在車端的自動駕駛芯片上,國內已經有一些替代產品,比如地平線、黑芝麻、寒武紀、華為等都推出了自研自動駕駛芯片,比如華為MDC810平臺采用了昇騰610芯片,可以支持最高400 TOPS算力;理想L8 首發的地平線征程5單芯算力也達到了196TOPS,據稱下一代征程6算力將超過100TOPS。而隨著國內自動駕駛芯片的發展,未來的供應風險,或許也會是國內車企轉向本土芯片公司的契機。
目前的狀況,對于英偉達以及國內自動駕駛行業來說顯然都不是一件好事。但至少在車端自動駕駛芯片上,國內車企往往采用多供應商的策略,扶持國內芯片廠商,并已經有所起色。然而在自動駕駛AI云端訓練上,國內供應商要走的路還很長。
今年8月的最后一天,英偉達發布公告稱,公司收到美國政府通知,要求對中國大陸以及中國香港、俄羅斯的客戶出口的高端GPU芯片,需要申請出口許可證,其中覆蓋到A100和H100等幾款GPU,同時未來性能等于或高于A100的產品都會受到該政策影響。隨后10月繼續加碼的出口限制,更是將申請出口許可證的產品類別覆蓋到更大的范圍,包括用于超級計算機、量子計算等的尖端芯片、技術、設備等。
值得一提的是,A800 GPU是美國半導體公司首次為中國市場推出符合美國貿易政策的先進芯片。在9月份,英偉達曾表示,新的出口管制規則可能會令公司損失數億美元的收入。而A800作為應對貿易政策而“定制”的產品,可謂進展神速,英偉達透露在今年第三季度已經投產,目前已經有一些國內經銷商已經拿到實物,并打出A800 GPU的廣告。
A100性能和A800幾乎一致,但互連帶寬被“砍一刀”
相信大家最關心的是A800跟此前的A100性能有什么差別,A800會不會是特供中國的“低配版”。其實從英偉達已經公開的參數來看,A800單卡算力在參數上幾乎是與A100是完全一致的。
唯一的不同在于NVLink互連橋的帶寬縮水33%,從A100上的600GB/s砍至A800的400GB/s,這可能會影響到多卡服務器,比如數據中心、超級計算機的整體性能。
NVLink是英偉達在2014年發布的一種總線和通信協議,采用了點對點結構、串列傳輸,用于CPU和GPU之間,或是多個GPU之間的連接,相比通過PCIe總線互連的傳統方式,NVLink可以大幅提高交互效率。簡單來說,NVLink就是能在GPU和GPU、GPU和CPU之間實現高速大帶寬直連通信的互連技術。
圖源:英偉達
電子發燒友從英偉達官網上了解到,A100所支持的NVLink總帶寬達到600GB/s,屬于第三代產品。今年3月英偉達在GTC 2022上發布的第四代NVLink-C2C則可以實現高達900GB/s的總帶寬,是PCIe 5.0帶寬的七倍,并將互連技術擴展至芯片之間的互連,支持定制裸片與 NVIDIA GPU、CPU、DPU、NIC 和 SOC之間實現一致的互連。
而A800上的NVLink總帶寬為400GB/s,介于第二代和第三代之間。在AI和HPC等領域中,GPU之間的互連帶寬降低,對于動輒數千塊GPU組成的計算集群而言顯然會造成不小的性能損失。
國內自動駕駛行業首當其沖,誰能替代英偉達?
自動駕駛技術開發,是一項需要大量算力進行AI模型訓練、計算的密集型工作。作為AI模型訓練的核心之一,英偉達的GPU產品一直以來都是自動駕駛玩家的主要選擇。英偉達推出的HGX A100平臺就是專為AI場景設計的高性能服務器平臺,包含比如驅動自動駕駛汽車的模型,以及大型數據集等,官方宣稱可以將模型開發效率提高20倍。
對于自動駕駛項目而言,開發效率的提高意味著縮短自動駕駛汽車的上市周期,加速架構的迭代。在行業內,包括特斯拉目前也在大量應用英偉達GPU打造超算平臺。去年6月,特斯拉公布了公司內部用于訓練Autopilot與自動駕駛深度神經網絡的超級計算機,這個集群使用了720個節點的8個A100 GPU(共5760個),實現高達1.8 exaflops的總算力。
國內方面,蔚來在去年年底就宣布采用英偉達A100 GPU以及Mellanox InfiniBand ConnectX-6網卡構建超級計算機集群。
小鵬汽車在今年8月2日宣布與阿里云合作在烏蘭察布建成了中國最大的自動駕駛智算中心“扶搖”,采用阿里云智能計算平臺,算力可達600PFLOPS。雖然官方沒有公布該超算中心所用的硬件,但此前阿里云一直與英偉達有密切合作,今年3月阿里云和英偉達還合作推出了初創加速計劃,為初創企業提供算力緩解計算壓力。
另一方面小鵬汽車創始人何小鵬在9月份的朋友圈中評論了英偉達A100出口受限的事件,并表示“壞消息是這會對所有自動駕駛云端訓練帶來挑戰,好消息是剛好我們已經把未來幾年的需求提前買回來了。” 言下之意小鵬在自動駕駛AI模型訓練上所采用的GPU同樣來自英偉達。
因此,高端GPU的供應限制,給未來國內自動駕駛行業帶來了很大的不確定性,未來算力受限有可能成為抑制自動駕駛技術發展的關鍵因素。
當然,英偉達也在努力趕在出口的緩沖期盡量向中國完成更多交付。此前英偉達更新的最新消息稱,公司已經獲得了授權,可以使得A100和H100在2023年9月1日之前通過英偉達在相關的公司履行訂單和物流。
在9月份業內又傳出英偉達向臺積電下了“超級急件”訂單,要求臺積電提前生產原計劃在明年出貨的部分產品,交付期從原本的5-6個月縮短至2-3個月,總量約5000片晶圓。從時間上看,這批產品可能在11月前后可以向英偉達交貨。
可以預見,在近一年的緩沖期內,在目前沒有其他替代產品的情況下,國內廠商會加快采購相關產品,重點可能是相比A100性能提升高達450%的H100 GPU,這至少能保證在未來幾年內對算力的需求。
另一方面,英偉達與多家車企的自動駕駛已經進行深度綁定,包括蔚來、小鵬、極氪、輕舟智航等都已經宣布選擇英偉達下一代Thor自動駕駛芯片,但如今有了出口管制的先例,繼續在終端采用英偉達芯片難免會存在供應風險。
而在車端的自動駕駛芯片上,國內已經有一些替代產品,比如地平線、黑芝麻、寒武紀、華為等都推出了自研自動駕駛芯片,比如華為MDC810平臺采用了昇騰610芯片,可以支持最高400 TOPS算力;理想L8 首發的地平線征程5單芯算力也達到了196TOPS,據稱下一代征程6算力將超過100TOPS。而隨著國內自動駕駛芯片的發展,未來的供應風險,或許也會是國內車企轉向本土芯片公司的契機。
目前的狀況,對于英偉達以及國內自動駕駛行業來說顯然都不是一件好事。但至少在車端自動駕駛芯片上,國內車企往往采用多供應商的策略,扶持國內芯片廠商,并已經有所起色。然而在自動駕駛AI云端訓練上,國內供應商要走的路還很長。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
gpu
+關注
關注
28文章
4729瀏覽量
128891 -
英偉達
+關注
關注
22文章
3770瀏覽量
90990 -
A800
+關注
關注
0文章
14瀏覽量
257
發布評論請先 登錄
相關推薦
英偉達或取消B100轉用B200A代替
今年3月份,英偉達在美國加利福尼亞州圣何塞會議中心召開的GTC 2024大會上推出了Blackwell架構GPU。原定于今年底出貨的B100
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
2024年3月19日,[英偉達]CEO[黃仁勛]在GTC大會上公布了新一代AI芯片架構BLACKWELL,并推出基于該架構的超級芯片GB200,將助推數據處理、工程模擬、電子設計自動化
發表于 05-13 17:16
英偉達宣布推出新一代GPU Blackwell,SK海力士已量產HBM3E
在英偉達GTC 2024大會上,英偉達CEO黃仁勛宣布推出新一代GPU Blackwell,第

英偉達縮短AI GPU交付周期,持續推進算力產業鏈發展
與此同時,隨著人工智能的迅猛發展及其廣泛應用,對像H100和A100這類專為數據中心設計的高性能GPU的需求也大幅增長。而包括Yotta在內的多家公司因此紛紛加大向英偉
猛獸財經:2024年繼續看好英偉達的兩個理由
2023年可以說是英偉達成立近30年以來最好的一年。由于大語言模型帶動的訓練和推理算力需求的增加,導致市場對英偉達AI芯片(H100、

NVIDIA特供中國的芯片,AI性能大降10%售價依然高
目前NVIDIA最昂貴的A100、H100芯片無法對中國市場出售,此前為中國市場定制的A800、H800
2024年,GPU能降價嗎?
首當其沖的就是A100GPU。OpenAI使用的是3,617臺HGXA100服務器,包含近3萬塊英偉達GPU。國內云計算相關專家認為,做好A

英偉達和華為/海思主流GPU型號性能參考
一句話總結,H100 vs. A100:3 倍性能,2 倍價格 值得注意的是,HCCS vs. NVLINK的GPU 間帶寬。 對于 8 卡
發表于 12-29 11:43
?5973次閱讀

英偉達vs.華為/海思:GPU性能一覽
NVIDIA NVLink采用全網狀拓撲,如下所示,(雙向)GPU-to-GPU 最大帶寬可達到400GB/s (需要注意的是,下方展示的是8*A100模塊時的600GB/s速率,8*A800也是類似的全網狀拓撲);






 工商網監
工商網監
評論