") 首個無監(jiān)督3D點云物體實例分割算法
首個無監(jiān)督3D點云物體實例分割算法
在物體部件分割和室內、室外物體分割任務上的效果圖(無需任何人工標注):

1. Introduction
三維點云物體分割是三維場景理解的關鍵問題之一,也是自動駕駛、智能機器人等應用的基礎。然而,目前的主流方法都是基于監(jiān)督學習,需要大量人工標注的數據,而對點云數據進行人工標注是十分耗費時間和人力的。
2. Motivation
本文旨在尋求一種無監(jiān)督的3D物體分割方法。我們發(fā)現,運動信息有望幫助我們實現這一目標。如下圖1所示,在左圖中的藍色/橙色圓圈內,一輛汽車上的所有點一起向前運動,而場景中其他的點則保持靜止。那么理論上,我們可以基于每個點的運動,將場景中屬于汽車的點和其他點分割開,實現右圖中的效果。
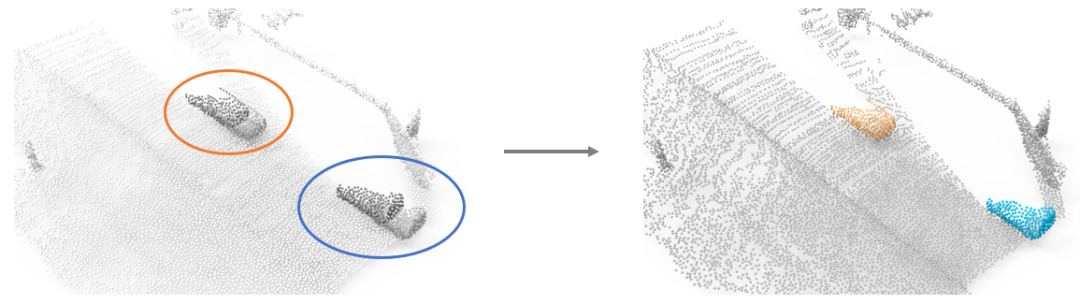
Figure 1. 利用運動信息分割物體的motivation
利用運動信息分割3D物體的想法已經在一些現有的工作中得到了探索。例如,[1] 和 [2] 利用傳統(tǒng)的稀疏子空間聚類的方法從點云序列中分割運動的物體;SLIM [3] 提出了第一個基于學習的方法來分割運動的前景和靜止的背景。然而,現有的方法都在以下的一個或多個方面存在局限性:
1)只適用于特定場景,不具備通用性;
2)只能實現運動的前景和靜止的背景之間的二類分割,無法進一步區(qū)分前景中的多個物體;
3)(幾乎所有的現有方法都存在的局限)必須要多幀的點云序列作為輸入,而且只能分割出其中在運動的物體。但是理論上,我們利用運動信息學會辨別某些物體之后,當這些物體以靜止的狀態(tài)出現在單幀點云中,我們應該依然能辨別它們。
針對上述問題,我們希望設計一種通用的、能分割多個物體的無監(jiān)督3D物體分割方法:這種方法在完全無標注的點云序列上進行訓練,從運動信息中學習3D物體分割;經過訓練后,能夠直接在單幀點云上進行物體分割。為此,本文提出了無監(jiān)督的3D物體分割方法OGC (Object Geometry Consistency)。本文的主要貢獻包括以下三點:
1)我們提出了第一個通用的無監(jiān)督3D物體分割框架OGC,訓練過程中無需任何人工標注,從點云序列包含的運動信息中學習;經過訓練后能直接在單幀點云上進行物體分割。
2)作為OGC框架的核心,我們以物體在運動中保持幾何形狀一致作為約束條件,設計了一組損失函數,能夠有效地利用運動信息為物體分割提供監(jiān)督信號。
3)我們在物體部件分割和室內、室外物體分割任務上都取得了非常好的效果。
3. Method
3.1 Overview
如下圖2所示,我們的框架包括三個部分:
1)一個物體分割網絡(橙色部分),從單幀點云估計物體分割mask;
2)一個自監(jiān)督的場景流估計網絡(綠色部分),估計兩幀點云之間的運動(場景流);
3)一組損失函數(藍色部分),利用2)估計出的運動為1)輸出的物體分割mask提供監(jiān)督信號。
在訓練過程中,需要三個部分聯合工作;在訓練后,只需保留1)的物體分割網絡,即可用于分割單幀點云。

Figure 2 OGC示意圖
對于OGC框架中的物體分割網絡和場景流估計網絡,我們可以直接利用現有的網絡結構,如下圖3所示。具體來說:
1)物體分割網絡:我們采用PointNet++ [4] 從輸入的單幀點云 提取特征,然后用Transformer [5] 解碼器直接從提取的點云特征估計出所有物體的分割mask,表示為
提取特征,然后用Transformer [5] 解碼器直接從提取的點云特征估計出所有物體的分割mask,表示為 。整個網絡結構可以視作最近在2D圖像上非常成功的物體分割方法MaskFormer [6] 向3D點云的拓展。
。整個網絡結構可以視作最近在2D圖像上非常成功的物體分割方法MaskFormer [6] 向3D點云的拓展。
2)場景流估計網絡:我們直接采用了最近非常成功的FlowStep3D [5],接收兩幀點云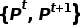 作為輸入,估計
作為輸入,估計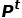 中的點的運動(場景流)
中的點的運動(場景流) 。
。

Figure 3 OGC結構圖
3.2 OGC Losses
OGC框架的關鍵,就在于如何利用運動信息為物體分割提供監(jiān)督信號。為此,我們設計了以下損失函數:
1)Dynamic loss:現實世界中大部分物體的運動都可以用剛體變換來描述。因此在這項損失函數中,我們要求對每個估計出的物體分割mask,其中所包含的點的運動必須服從同一個剛體變換:
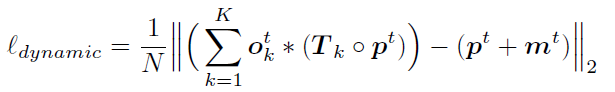
上式中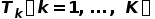 表示每個物體分割mask上擬合出的剛體變換。如果一個mask實際上包含了兩個運動方向不同的物體,這兩個物體上點的運動必然不可能服從同一個剛體變換。此時用這兩個物體上的點強行擬合出的剛體變換與這些點的實際運動并不一致,這個mask就會被損失函數懲罰。可以看到,dynamic loss能幫助我們區(qū)分運動方向不同的物體。但是,如果實際上屬于同一個物體的點被分割成兩塊,即“過度分割”,dynamic loss并不能懲罰這種情況。
表示每個物體分割mask上擬合出的剛體變換。如果一個mask實際上包含了兩個運動方向不同的物體,這兩個物體上點的運動必然不可能服從同一個剛體變換。此時用這兩個物體上的點強行擬合出的剛體變換與這些點的實際運動并不一致,這個mask就會被損失函數懲罰。可以看到,dynamic loss能幫助我們區(qū)分運動方向不同的物體。但是,如果實際上屬于同一個物體的點被分割成兩塊,即“過度分割”,dynamic loss并不能懲罰這種情況。
2)Smoothness loss:物體上的點在空間中一般都是連接在一起的,否則物體就會斷裂。基于這一事實,我們提出了對物體分割mask的平滑性先驗,要求一個局部區(qū)域內相互鄰近的點被分配到同一個物體:
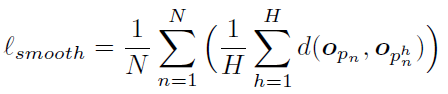
上式中H表示某個點的領域內包含的點的數量。可以看到dynamic loss和smoothness loss起到了相互對抗的效果:前者根據運動方向的不同將點區(qū)分開;后者則根據空間中的近鄰關系將鄰近的點聚合,以抵消潛在的“過度分割”問題。這兩項損失函數聯合起來,為分割場景中的運動物體提供了充足的監(jiān)督信號。
3)Invariance loss:我們希望將學習到的運動物體分割充分地泛化到外形相近的靜態(tài)物體。為此,我們要求物體分割網絡在面對處于不同位姿的同一物體時,能夠無差別地辨別(分割)該物體。具體來說,我們對同一場景施加兩個不同的空間變換(旋轉,平移和縮放)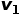 和
和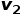 ,使得場景中物體的位姿都發(fā)生變化,然后我們要求場景的分割結果保持不變:
,使得場景中物體的位姿都發(fā)生變化,然后我們要求場景的分割結果保持不變:
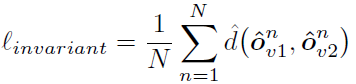
Invariance loss能有效地將從運動物體學習到的分割策略泛化到不同位姿的靜態(tài)物體。
3.3 Iterative Optimization
當我們從運動信息中學會了分割物體,理論上我們可以用估計出的物體分割來提升對運動(場景流)的估計質量,隨后從更準確的運動信息中更好地學習分割物體。為實現這一目標,我們提出了如下圖4所示的“物體分割-運動估計”迭代優(yōu)化算法:初始階段,我們通過FlowStep3D網絡估計運動。在每一輪中,我們首先從當前估計出的運動信息學習物體分割;隨后用我們的Object-aware ICP算法,基于估計出的物體分割來提升對運動的估計質量,將改善后的運動估計送入下一輪。
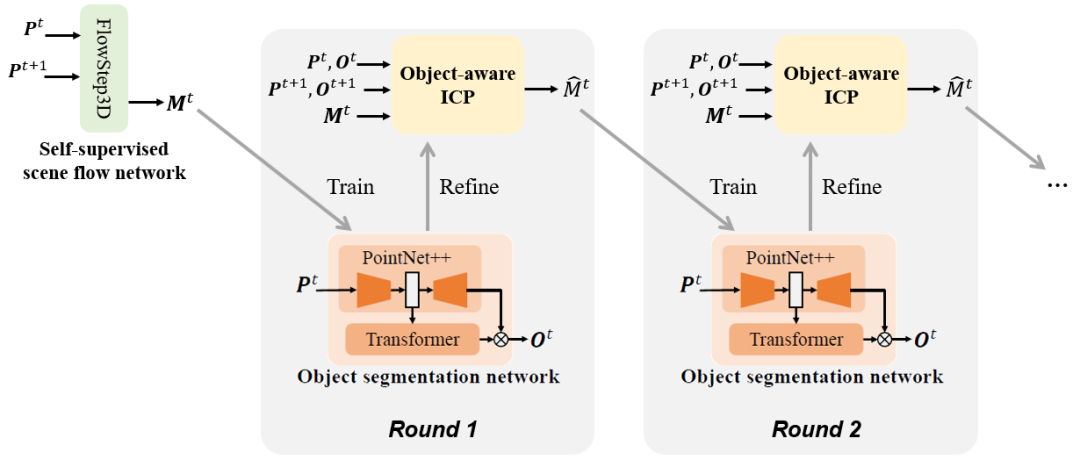
Figure 4 “物體分割-運動估計”迭代優(yōu)化算法示意圖
在迭代過程中用到的Object-aware ICP算法,可以看作傳統(tǒng)的ICP算法向多物體場景的拓展,算法的具體細節(jié)可以參考原文附錄A.2。
4. Experiments
Evaluation on Synthetic Datasets
我們首先在SAPIEN數據集和我們在自己合成的OGC-DR / OGC-DRSV數據集上評估了OGC對物體部件分割和室內物體分割任務的效果。從下面兩個表格可以看到,在高質量的合成數據集上,OGC不僅領先于傳統(tǒng)的無監(jiān)督運動分割和聚類方法,還達到了接近甚至超越全監(jiān)督方法的效果。
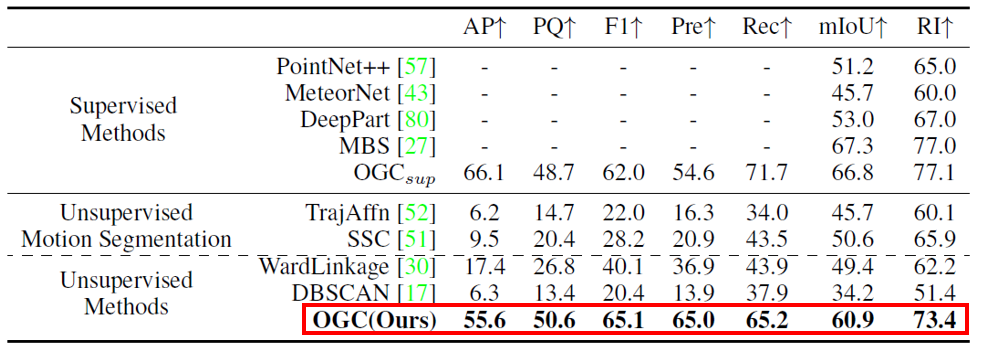
Figure 5 不同方法在SAPIEN數據集上的定量結果對比

Figure 6不同方法在OGC-DR/OGC-DRSV數據集上的定量結果對比
Evaluation on Real-World Outdoor Datasets
接下來,我們評估OGC在極具挑戰(zhàn)性的室外物體分割任務上的表現。首先,我們在KITTI Scene Flow(KITTI-SF)數據集上進行評估。KITTI-SF包含200對點云用于訓練,200單幀點云用于測試。實驗結果如下表所示:我們的方法達到了與全監(jiān)督方法接近的優(yōu)異性能。
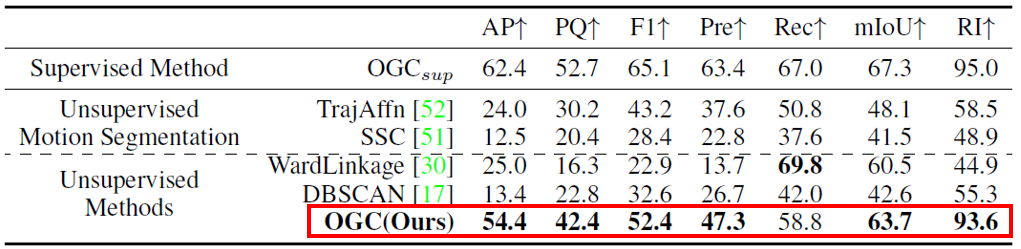
Figure 7不同方法在KITTI-SF數據集上的定量結果對比
在實際應用中,有時無法收集到包含運動的序列數據,但我們可以將相似場景中訓練出的OGC模型泛化過來。這里,我們將上述KITTI-SF數據集上訓練好的OGC模型拿來,直接用于分割KITTI Detection(KITTI-Det)和SemanticKITTI數據集中的單幀點云。注意:KITTI-Det和SemanticKITTI中的點云都是通過雷達采集的,比KITTI-SF中雙目相機采集的點云稀疏很多,且KITTI-SF(3769幀)和SemanticKITTI(23201幀)的數據規(guī)模都遠遠大于KITTI-SF。實驗結果如下面兩張表所示:我們在KITTI-SF上訓練的OGC模型能直接泛化到稀疏的雷達點云數據,并取得與全監(jiān)督方法接近的效果。
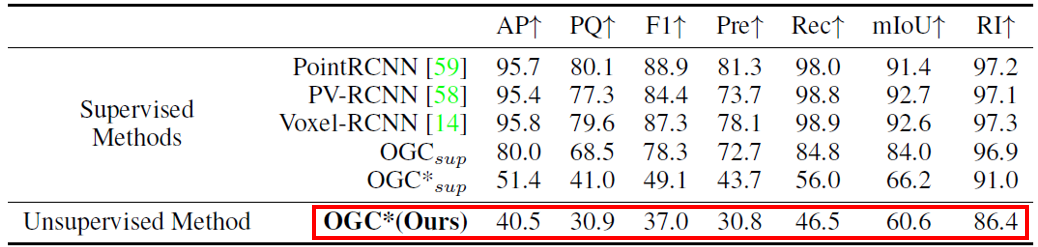
Figure 8在KITTI-Det數據集上的定量結果對比(*表示模型在KITTI-SF上訓練)
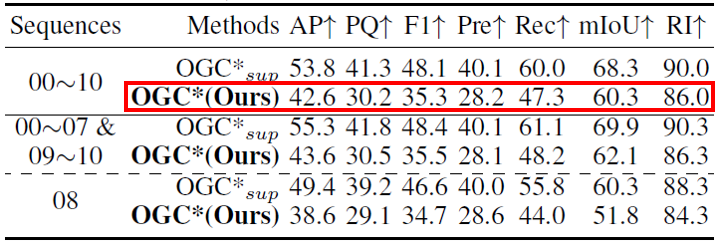
Figure 9在SemanticKITTI數據集上的定量結果對比(*表示模型在KITTI-SF上訓練)
Ablation Studies
我們在SAPIEN數據集上對OGC框架的核心技術進行了消融實驗:
1)損失函數設計:從下方圖表可以看到,OGC的三個損失函數結合使用能帶來最好的效果。如果移除dynamic loss,所有點會被分到同一物體;如果移除smoothness loss,會出現“過度分割”的問題。
2)迭代優(yōu)化算法:可以看到,隨著迭代輪數增多,更高質量的運動估計確實帶來了更好的物體分割表現。
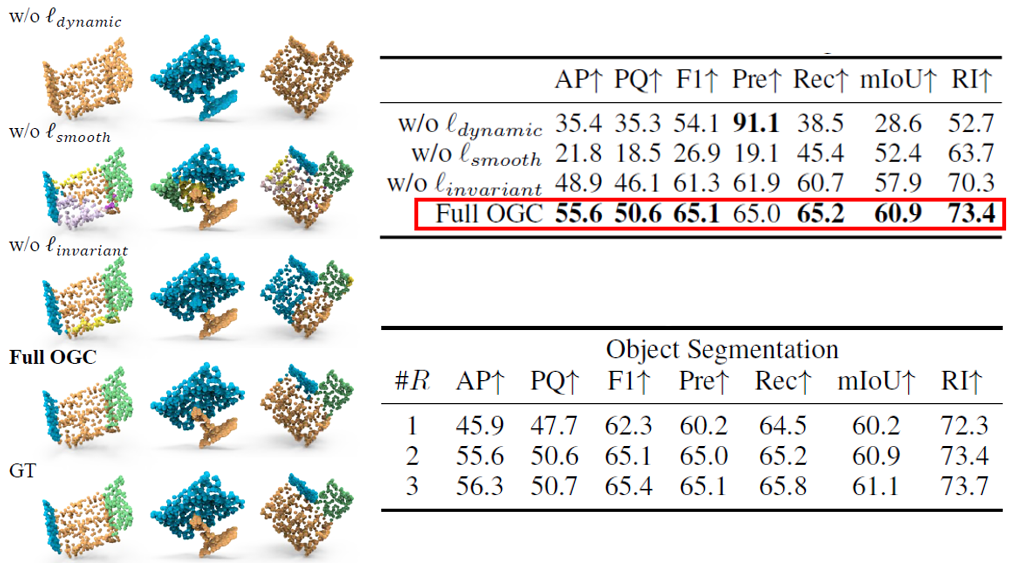
Figure 10 在SAPIEN數據集上的消融實驗(圖-左和表-上:損失函數設計;表下:迭代優(yōu)化算法)
5. Summary
最后總結一下,我們提出了第一個點云上的無監(jiān)督3D物體分割框架。這個框架的核心是一組基于物體幾何形狀一致性的損失函數,利用運動信息有效地監(jiān)督物體分割。我們的方法在完全無標注的點云序列上訓練,訓練后可以直接用于分割單幀點云,在多種任務場景下都展示出了非常好的效果。未來OGC還可以進一步拓展:
1)當有少量標注數據時,如何將無監(jiān)督的OGC模型與這些標注數據結合取得更好的性能;
2)當有多幀作為輸入時,如何利用多幀信息更好地分割。
審核編輯 :李倩
-
函數
+關注
關注
3文章
4338瀏覽量
62761 -
智能機器人
+關注
關注
17文章
870瀏覽量
82388 -
分割算法
+關注
關注
0文章
10瀏覽量
7212
原文標題:NeurIPS 2022 | 香港理工提出OGC:首個無監(jiān)督3D點云物體實例分割算法
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
采用華為云 Flexus 云服務器 X 實例部署 YOLOv3 算法完成目標檢測

3D線激光輪廓測量儀的關鍵參數——最大掃碼頻率
歡創(chuàng)播報 騰訊元寶首發(fā)3D生成應用

神經網絡如何用無監(jiān)督算法訓練
3D建模的重要內容和應用
友思特案例 | 自研創(chuàng)新!三維工件尺寸測量及點云處理解決方案
3D建模的特點和優(yōu)勢都有哪些?
機器人3D視覺引導系統(tǒng)框架介紹
新質生產力探索| AICG浪潮下的3D打印與3D掃描技術

基于深度學習的方法在處理3D點云進行缺陷分類應用
移動協作機器人的RGB-D感知的端到端處理方案
探索ICLR‘24 Spotlight中的首個十億級別3D通用大模型

15倍加速!SuperCluster:最強3D點云全景分割!






 工商網監(jiān)
工商網監(jiān)
評論