

01
研究動機
目前最先進的神經機器翻譯模型主要是自回歸(autoregressive, AR)[1][2]模型,即在解碼時從左向右依次生成目標端單詞。盡管具有很強的性能,但這種順序解碼會導致較高的解碼時延,在效率方面不令人滿意。相比之下,非自回歸(non-autoregressive, NAR)模型[3]使用更加高效的并行解碼,在解碼時同時生成所有的目標端單詞。為此,NAR模型需要對目標端引入條件獨立假設。然而,這一假設無法在概率上準確地描述人類語言數據中的多模態現象(或多樣性現象,即一條源端句存在多個正確的翻譯結果)。這為NAR模型帶來了嚴峻的挑戰,因為條件獨立假設與傳統的極大似然估計(Maximum Likelihood Estimate, MLE)訓練方式無法為NAR模型提供足夠信息量的學習信號和梯度。因此,NAR模型經常產生較差的神經表示,尤其是在解碼器(Decoder)部分。而由于解碼器部分直接控制生成,從而導致了NAR模型顯著的性能下降。為了提升NAR模型的性能,大多數先前的研究旨在使用更多的條件信息來改進目標端依賴關系的建模(GLAT[4], CMLM[5])。我們認為,這些研究工作相當于在不改變NAR模型概率框架的前提下提供更好的替代學習信號。并且,這些工作中的大部分需要對模型結構進行特定的修改。
沿著這個思路,我們希望能夠為NAR模型提供更具信息量的學習信號,以便更好地捕獲目標端依賴。同時,最好可以無需對模型結構進行特定的修改,適配多種不同的NAR模型。因此,在本文中我們提出了一種簡單且有效的多任務學習框架。我們引入了一系列解碼能力較弱的AR Decoder來輔助NAR模型訓練。隨著弱AR Decoder的訓練,NAR模型的隱層表示中將包含更多的上下文和依賴信息,繼而提高了NAR模型的解碼性能。同時,我們的方法是即插即用的,且對NAR模型的結構沒有特定的要求。并且我們引入的AR Decoder僅在訓練階段使用,因此沒有帶來額外的解碼開銷。
02
貢獻
1、我們提出了一個簡單有效的多任務學習框架,使NAR模型隱層表示包含更豐富的上下文和依賴信息。并且我們的方法無需對模型結構進行特定的修改,適配多種NAR模型。
2、一系列AR Decoder的引入帶來了較大的訓練開銷。為此我們提出了兩種降低訓練開銷的方案,在幾乎不損失性能的前提下顯著降低了參數量和訓練時間。
3、在多個數據集上的實驗結果表明,我們的方法能夠為不同的NAR模型帶來顯著的提升。當使用束搜索解碼時,我們的模型在所有數據集上均優于強大的Transformer模型,同時不引入額外的解碼開銷。
03
解決方案
3.1、模型結構
我們的模型結構如圖1所示。對于每個NAR Decoder層,我們都引入了一個輔助的弱AR Decoder(每個AR Decoder僅包含1層Transformer Layer)。我們令這些AR Decoder基于對應的NAR隱層表示進行解碼,即令NAR隱層表示作為AR Decoder Cross-Attention的Key和Value。由于AR Decoder的解碼能力較弱,因此很難自行捕捉目標句的依賴關系。只有當其對應的NAR隱層表示中的信息足夠充分,AR Decoder才能夠正確地解碼。因此,AR Decoder為NAR模型帶來了新的訓練信號,迫使NAR Decoder變得更強,在隱層表示中包含更多的上下文和依賴信息來支持AR Decoder的解碼。在這個過程中,NAR提升了自己的表示能力,從而在實際解碼時獲得了更好的表現。
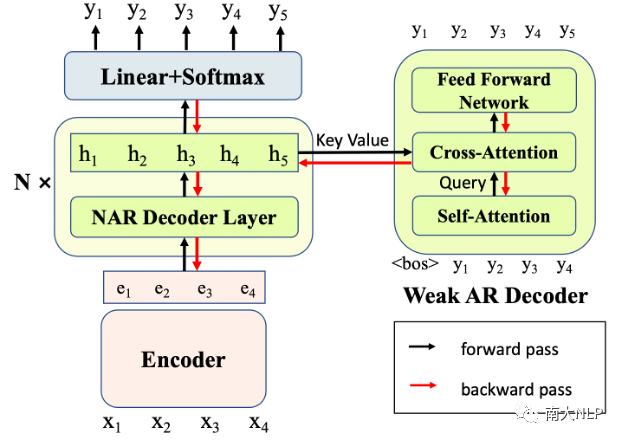
圖1:我們的方法示意圖
3.2、訓練目標
我們的訓練目標如下式所示
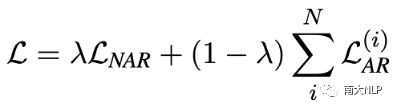
對于NAR部分,我們保持NAR模型的原始訓練目標不變。如對于CTC模型,我們使用CTC Loss作為NAR的損失函數。對于AR部分,我們使用交叉熵損失進行訓練,并將所有AR Decoder的損失相加。最終的損失函數是兩部分的加權和,權重是超參數。
3.3、Glancing Training訓練策略
Glancing Training是一種有效提升NAR模型性能的訓練策略[4]。我們在我們的方法中應用了Glancing Training。具體來說,在訓練時根據模型當前的解碼質量,隨機采樣參考句中的token作為NAR Decoder的輸入。模型當前解碼質量越差則采樣越多,反之亦然。然后令AR Decoder基于NAR隱層表示進行解碼。
3.4、降低解碼開銷
我們為每層NAR Decoder都配置了一個AR Decoder,這可能會帶來較大的訓練開銷。為此,我們從模型參數量和訓練時間的角度,提出了兩種降低訓練開銷的方案。
Parameter Sharing:令所有的AR Decoder之間共享參數,降低參數量;
Layer Dropout:每個訓練步隨機選擇一半數量的AR Decoder進行訓練,降低訓練時間。
3.5、解碼過程
在解碼時,我們不使用AR Decoder,僅使用NAR模型自身進行解碼。因此,我們的方法沒有引入額外的解碼開銷。
04
實驗
我們在機器翻譯領域目前最廣泛使用的數據集上進行了實驗:WMT14英德(4.5M語言對)、WMT16英羅(610K語言對)、IWSLT14德英(160K語言對)。我們遵循Gu和Kong[6]的工作中的數據預處理方式,并且使用了BLEU[9]指標作為機器翻譯質量評價指標。為了緩解數據集中多模態現象導致的訓練困難,我們對所有數據集使用了知識蒸餾技術進行處理[3]。
4.1、實驗結果
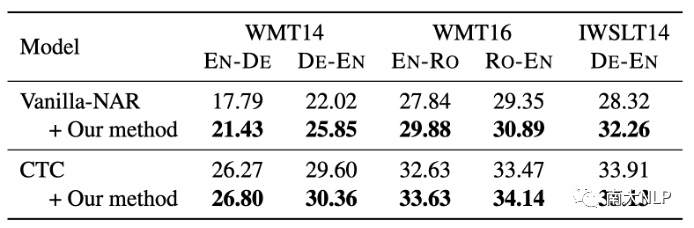
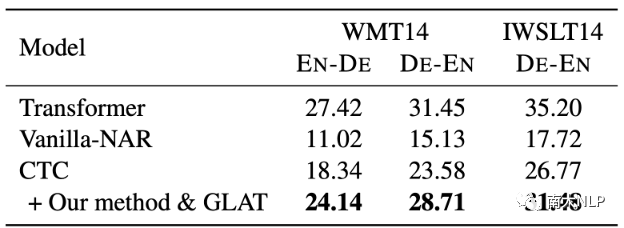
我們的方法可以對不同類型的NAR模型帶來提升。
我們使用了Vanilla-NAR[3]和CTC[7]作為我們的基線模型,并在基線模型上應用我們的方法,實驗結果如表1所示。可以看到,我們的方法一致且顯著地提高了每個基線模型在每個語言對上的翻譯質量。這說明了我們方法的通用性。
表1:對不同的基線模型應用我們的方法
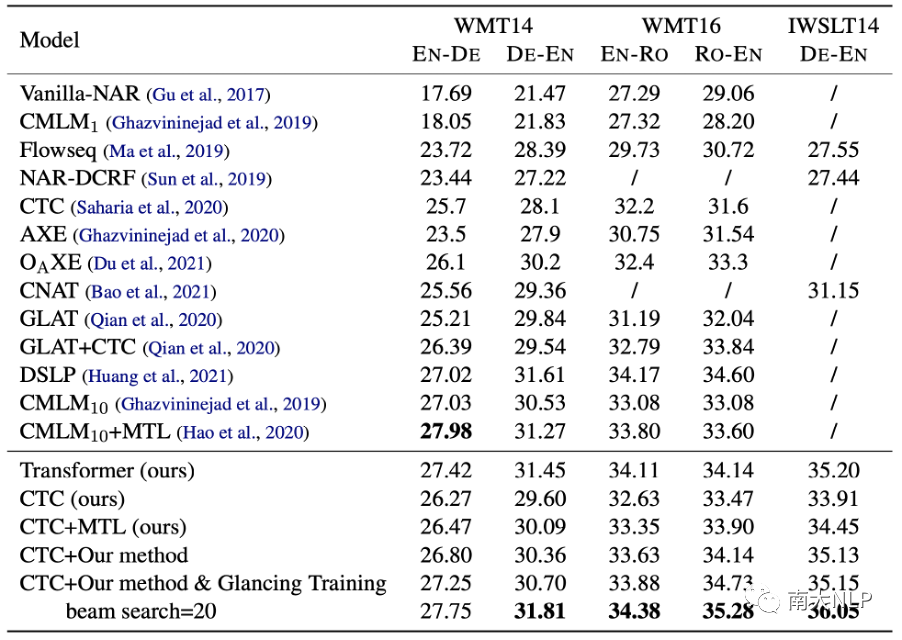
與其他的NAR模型相比,我們的方法獲得了更好的結果。
我們選用CTC模型應用我們的方法作為我們的模型,并與其他強大的NAR模型進行比較,實驗結果如表2所示。可以看到,我們的方法顯著提高了翻譯質量,并優于其他強大的基線模型。此外,當應用Glancing Training技術后,我們的方法可以帶來更大程度的提升。
與采取迭代解碼的模型(CMLM)相比,我們的方法僅使用單步解碼,具備更快的解碼速度,并在除了WMT14英德之外的所有語言對上獲得了更好的性能。
Hao等人[8]的工作與我們的工作相關,都使用了多任務學習框架。我們在CTC模型上復現了他們的方法(CTC+MTL)。實驗結果表明我們的方法可以為模型帶來更明顯的提升。
表2:與其他強大的NAR模型比較。 代表使用k輪迭代解碼
代表使用k輪迭代解碼
4.2、實驗分析
較弱的AR Decoder是否有必要?
在我們的方法中,AR Decoder的解碼能力需要足夠弱,由此強迫NAR Decoder變得更強。我們對這一點進行了驗證。我們使用不同層數的AR Decoder進行實驗(1、3、6層),實驗結果如圖2所示。每種深度的AR Decoder都可以為NAR模型帶來增益,但是隨著AR Decoder層數的增加,AR Decoder解碼能力增強,為NAR模型帶來的增益也在逐漸降低。這也驗證了我們的動機:一個較弱的AR Decoder能夠使NAR Decoder包含更多有用的信息。
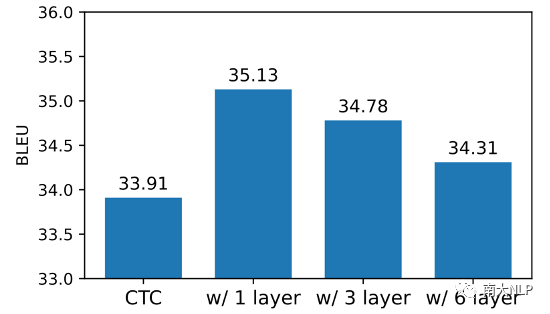
圖2:不同層數的AR Decoder為模型帶來了不同程度的增益
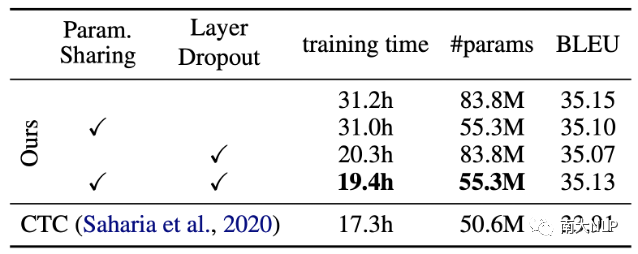
關于訓練開銷的消融實驗。
我們在IWSLT14德英數據集上評估了我們提出的降低訓練開銷策略的效果。如表3所示,在使用了Param Sharing和Layer Dropout兩種策略后,參數量(83.8M vs 55.3M)和訓練時間(31.2h vs 19.4h)均得到了顯著的降低,同時保持模型性能幾乎沒有變化
表3:兩種降低訓練開銷策略的效果評估
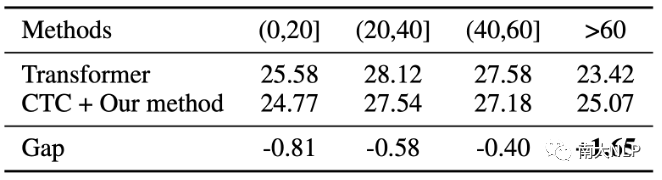
我們的方法使模型能夠更好地解碼長句。
為了進一步分析NAR模型在生成不同長度目標端句時的表現差異,我們在WMT14英德數據集的測試集上進行了實驗,將目標端句按照長度分成不同的區間。如表4所示,隨著句子長度的增加,我們的模型和Transformer之間的差距在逐漸降低。當目標端句長度大于60時,我們的模型能夠超過Transformer的解碼性能。在解碼更長的句子時,模型需要處理更復雜的上下文關聯。我們推測我們提出的多任務學習方法顯著改善了NAR隱藏狀態下包含的上下文和依賴信息,因此在長句子翻譯中具有更好的性能。
表4:生成不同長度目標端句時的性能差異
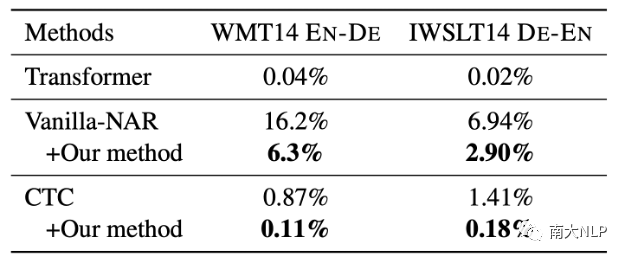
我們的方法使模型減少了重復生成。
由于數據集中的多模態現象,NAR模型會出現重復生成的翻譯錯誤。表5展示了在應用我們的方法前后,NAR模型出現重復生成現象的比率。可以看到,我們的方法顯著降低了重復單詞的出現頻率,使NAR模型的生成質量更好。值得注意的是,盡管CTC模型本身已經能夠產生很少的重復生成,我們的方法依然可以進一步降低重復生成的比率。
表5:重復生成的比率
不使用知識蒸餾技術時的性能表現。
盡管知識蒸餾是一種常用的約減多模態現象的手段,但它限制了NAR模型在AR教師模型下的性能,同時構建教師模型也需要額外的開銷。為了驗證我們的方法在原始數據場景中的有效性,我們在WMT14和IWSLT14數據集上進行了實驗。如表6所示,我們的方法可以為基線模型(CTC)帶來非常顯著的提升,進一步縮小了與Transformer模型的差距。
表6:不使用知識蒸餾的實驗結果
我們的方法相對于其他多任務學習方法的優勢。
Hao等人[8]的工作也使用了多任務學習框架,但我們的方法能夠為NAR模型帶來更顯著的提升。我們認為我們的方法在多任務學習模塊(即AR Decoder)的位置和容量上更有優勢。
對于AR Decoder的位置,我們認為Decoder決定生成過程,因此將AR Decoder部署于NAR Decoder上能夠更直接和顯式地改善NAR的生成過程,而Hao等人的工作是部署于NAR Encoder上的。
對于AR Decoder的容量,我們認為AR Decoder應盡可能弱,這樣AR Decoder無法自行對目標端句進行建模,從而迫使NAR Decoder隱層表示包含更多的上下文和依賴信息。而Hao等人的工作使用的標準AR Decoder,對NAR隱層表示的要求更低,因此為NAR帶來的提升更少。
05
總結
在本文中,我們為NAR模型提出了一個多任務學習框架,引入了一系列弱AR解碼器輔助訓練NAR模型。隨著弱AR解碼器的訓練,NAR隱藏狀態將包含更多的上下文和依賴信息,從而提高NAR模型的性能。在多個數據集上的實驗表明,我們的方法可以顯著且一致地提高翻譯質量。當使用束搜索解碼時,我們基于CTC的NAR模型在所有基準測試上都優于強大的Transformer,同時不引入額外的解碼開銷。
審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1163瀏覽量
41650 -
Ar
+關注
關注
25文章
5141瀏覽量
171748 -
模型
+關注
關注
1文章
3477瀏覽量
49922
原文標題:EMNLP'22 | 幫助弱者讓你變得更強:利用多任務學習提升非自回歸翻譯質量
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
工業通信的“超級翻譯官”Modbus轉Profinet如何讓稱重設備實現語言自由
自媒體別亂推!用好DeepSeek,讓你的內容“穩穩的”!
AI助力實時翻譯耳機

自鎖電路與非自鎖電路的比較
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
基于移動自回歸的時序擴散預測模型
【「大模型啟示錄」閱讀體驗】對本書的初印象
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
超ChatGPT-4o,國產大模型竟然更懂翻譯,8款大模型深度測評|AI 橫評

不同類型神經網絡在回歸任務中的應用
機器學習算法原理詳解
名單公布!【書籍評測活動NO.35】如何用「時間序列與機器學習」解鎖未來?
研究人員利用人工智能提升超透鏡相機的圖像質量






 工商網監
工商網監

評論