 NVIDIA Triton系列文章:開發資源說明
NVIDIA Triton系列文章:開發資源說明
大部分要學習 Triton 推理服務器的入門者,都會被搜索引擎或網上文章引導至官方的https://developer.nvidia.com/nvidia-triton-inference-server處(如下截圖),然后從 “Get Started” 直接安裝服務器與用戶端軟件、創建基礎的模型倉、執行一些最基本的范例。

這條路徑雖然能在很短時間內跑起 Triton 的應用,但在未掌握整個應用架構之前便貿然執行,反倒容易讓初學者陷入迷失的狀態,因此建議初學者最好先對 Triton 項目有比較更完整的了解之后,再執行前面的 “Get Started” 就會更容易掌握項目的精髓。
要獲得比較完整的 Triton 技術資料,就得到項目開源倉里去尋找。與 NVIDIA 其他放在 https://github.com/NVIDIA或https://github.com/NVIDIA-AI-IOT的項目不同,Triton 項目有獨立的開源倉,位置在https://github.com/triton-inference-server,進入開源倉后會看到如下截屏的內容:
下面列出四大部分的技術資源:
1. Getting Start(新手上路):
這里提供三個鏈接,比較重要的是 “Quick Start(快速啟動)” 的部分,提供以下三個步驟就能輕松執行 Triton 的基礎示范:
(1) Create a Model Repository(創建模型倉)
(2) Launch Triton(啟動Triton服務器與用戶端)
(3) Send an Inference Request(提交推理要求)
2. Production Documentation(生產文件):
這里最重要的是 “server documents on GitHub” 鏈接,點進去后會進入整個 Triton 項目中最完整的技術文件中心(如下圖),除 Installation 與 Getting Started 屬于入門范疇,其余 User Guide、API Guide、Additional Resources 與 Customization Guide 等四個部分,都是 Triton 推理服務器非常重要的技術內容。

因此這個部分可以算得上是學習 Triton 服務器的最重要資源。
例如點擊 “User Guide” 之后,就會看到以下所條例的執行步驟:
Creating a Model Repository
Writing a Model Configuration
Buillding a Model Pipeline
Managing Model Availablity
Collecting Server Metrics
Supporting Custom Ops/layers
Using the Client API
Analyzing Performance
Deploying on edge (Jetson)
3. Examples(范例):
這里的范例,比較重要的是指向https://github.com/NVIDIA/DeepLearningExamples鏈接,列出針對 NVIDIA Tensor Core 計算單元的深度學習模型列表,包括計算機視覺、NLP 自然語言處理、推薦系統、語音轉文字 / 文字轉語音、圖形神經網絡、時間序列等各種神經網絡模型細節,包括網絡結構與相關參數的內容。
對于未來要在 Triton 服務器上,對于所使用的網絡后端進行性能優化或者創建新的后端,會有很大的助益,但是對于初學者來說是相對艱澀的,因此現階段先不做深入的說明與示范。
4. Feedback(反饋):
這里會鏈接到https://github.com/triton-inference-server/server/issues問題中心,是 Triton 項目中最重要的技術問題解決資源之一,后面執行過程中所遇到的問題,都可以先到這里來查看是否有人已經提出?如果沒有的話,也可以在這里提交自己所遇到的問題,項目負責人會提供合適的回復。
以上第 2、4 兩項資源,對初學者來說會有最大的幫助。接著看一下項目里 “釘住(Pinned)” 的 6 個倉(如下圖),是比較重要的基礎部分,涵蓋了 Triton 架構圖中的主要板塊。
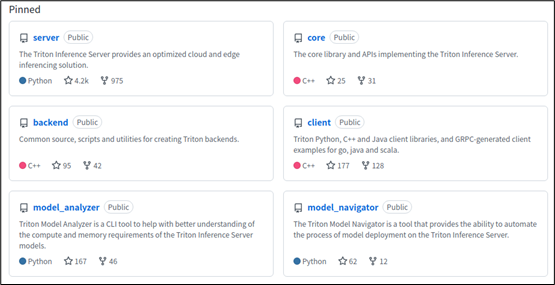
主要內容如下:
1. server 倉:
這里集成整個項目的主要內容,包括幾部分:
(1)deploy(部署):提供在阿里巴巴、亞馬遜等云資源的部署方式,以及基于 NVIDIA Fleet 指令集、GKE(Google kubernets Engine)、k8s、Helm 等應用平臺的各種部署方法;
(2)docker(容器):修正一些創建容器腳本的錯誤;
(3)docs(使用說明):就是前面 “生產文件(Production Documentation)” 的內容,這里不重復贅述;
(4)qa(質量優化):由于 Triton 推理服務器有非常多優化的環節,在這個目錄下提供上百個不同狀況的優化測試腳本;
(5)src(源代碼):目錄下存放整個 Triton 推理服務器的開源代碼(.cc)、頭文件(.h)與編譯腳本(CMakeLists.txt);
(6)其他代碼與腳本
2. core 倉:
此存儲庫包含實現 Triton 核心功能的庫的源代碼和標頭。核心庫可以如下所述構建,并通過其 CAPI 直接使用。為了有用,核心庫必須與一個或多個后端配對。您可以在后端回購中了解有關后端的更多信息。
3. backend 倉:
提供創建 Triton 服務器后端(backend)的源代碼、腳本與工具。“后端” 是用來執行不同深度學習模型的管理模塊,以深度學習框架進行封裝,例如 PyTorch、Tensorflow、ONNX Runtime 與 TensorRT 等等,用戶也可以為了性能目的,自行定義 C / C++ 封裝方式。
4. client 倉:
提供 Triton 用戶端的 C++ / Python / Java 開發接口、能生成適用于不同編程語言的 GRPC 開發接口的 protoc 編譯器,以及對應的用戶端范例;
5. model_analyzer 倉:
深度學習模型(model)是 Triton 推理服務器的最基礎組成元件,因此對分析模型的計算與內存需求是服務器性能的一項關鍵功能。這個 model_analyzer 模型分析工具是一種 CLI 工具,這款新工具可以自動化地從數百種組合中為 AI 模型選擇最佳配置,以實現最優性能,同時確保應用程序所需的服務質量,能幫助開發人員更好地了解不同配置中的權衡,并選擇能夠最大化 Triton 的性能配置;
6. model_navigator 倉:
這個 model_navigator 模型導航器是一種能夠自動將模型從源移動到最佳格式和配置的工具,支持將模型從源導出為所有可能的格式,并應用 Triton 服務器的后端優化。使用模型分析器能找到最佳的模型配置,匹配提供的約束條件并優化性能。
以上是 Triton 開源項目里比較核心的 6 個倉,另外還有 20 多個代碼倉,其中大約 15 個是項目提供的后端(backend)擴充應用,例如 tensorrt_backend、fil_backend、square_backend 等等,以及一些額外的管理工具,并且不斷增加中。
本系列后面的內容都會基于這個 server 倉的 docs 目錄下的內容為主,按部就班地帶著讀者循序漸進創建與調試 Triton 推理服務器的運作環境。
審核編輯 :李倩
-
NVIDIA
+關注
關注
14文章
4999瀏覽量
103227 -
服務器
+關注
關注
12文章
9221瀏覽量
85599
原文標題:NVIDIA Triton 系列文章(3):開發資源說明
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Triton編譯器與GPU編程的結合應用
Triton編譯器如何提升編程效率
Triton編譯器在高性能計算中的應用
Triton編譯器的優化技巧
Triton編譯器的優勢與劣勢分析
Triton編譯器在機器學習中的應用
Triton編譯器支持的編程語言
Triton編譯器與其他編譯器的比較
Triton編譯器功能介紹 Triton編譯器使用教程
NVIDIA助力提供多樣、靈活的模型選擇
使用NVIDIA Triton推理服務器來加速AI預測
在AMD GPU上如何安裝和配置triton?

【BBuf的CUDA筆記】OpenAI Triton入門筆記一






 工商網監
工商網監
評論