 五張圖帶你體會堆算法
五張圖帶你體會堆算法
什么是堆
堆(heap),是一類特殊的數據結構的統稱。它通常被看作一棵樹的數組對象。在隊列中,調度程序反復提取隊列中的第一個作業并運行,因為實際情況中某些時間較短的任務卻可能需要等待很長時間才能開始執行,或者某些不短小、但很重要的作業,同樣應當擁有優先權。而堆就是為了解決此類問題而設計的數據結構。
二叉堆是一種特殊的堆,二叉堆是完全二叉樹或者近似完全二叉樹,二叉堆滿足堆特性:父節點的鍵值總是保持固定的序關系于任何一個子節點的鍵值,且每個節點的左子樹和右子樹都是一個二叉堆。
當父節點的鍵值總是大于任何一個子節點的鍵值時為最大堆,當父節點的鍵值總是小于或等于任何一個子節點的鍵值時為最小堆。
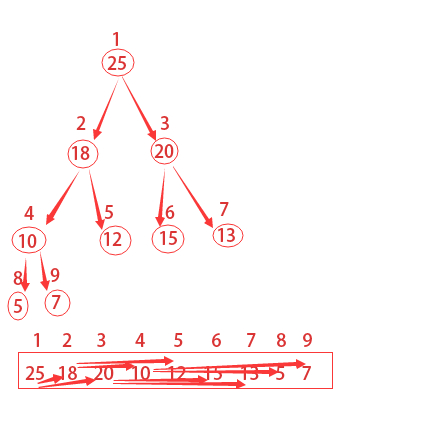
為了更加形象,我們常用帶數字的圓圈和線條來表示二叉堆等,但其實都是用數組來表示的。如果根節點在數組中的位置是1,第n個位置的子節點則分別在2n和2n+1位置上。
如下圖所描的,第2個位置的子節點在4和5,第4個位置的子節點在8和9。所以我們獲得父節點和子節點的方式如下:
PARENT(i)
1 return 小于或等于i/2的最大整數
LEFT-CHILD(i)
1 return 2i
RIGHT-CHILD(i)
1 return 2i+1
假定表示堆的數組為A,那么A.length通常給出數組元素的個數,A.heap?size表示有多少個堆元素存儲在該數組中。這句話略帶拗口,也就是說數組A[1...A.length]可能都有數據存放,但只有A[1...A.heap?size]中存放的數據才是堆中的有效數據。毫無疑問0≤A.heap?size≤A.length。
最大堆除了根以外所有結點i都滿足:A[PARENT(i)]≥A[i]。
最小堆除了根以外所有結點i都滿足:A[PARENT(i)]≤A[i]。
一個堆中結點的高度是該結點到葉借點最長簡單路徑上邊的數目,如上圖所示編號為4的結點的高度為1,編號為2的結點的高度為2,樹的高度就是3。
包含n個元素的隊可以看作一顆完全二叉樹,那么該堆的高度是Θ(lgn)。
通過MAX-HEAPIFY維護最大堆
程序中,不可能所有的堆都天生就是最大堆,為了更好的使用堆這一數據結構,我們可能要人為地構造最大堆。
如何將一個雜亂排序的堆重新構造成最大堆,它的主要思路是:
從上往下,將父節點與子節點以此比較。如果父節點最大則進行下一步循環,如果子節點更大,則將子節點與父節點位置互換,并進行下一步循環。注意父節點要與兩個子節點都進行比較。
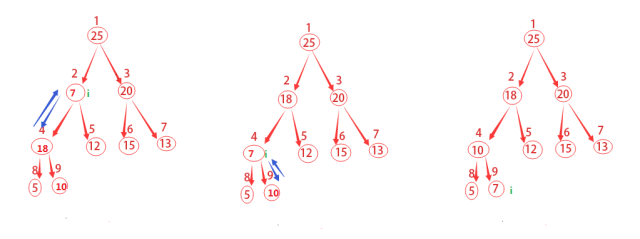
如上圖說描述的,這里從結點為2開始做運算。先去l為4,r為5,將其與父節點做比較,發現左子節點比父節點更大。因此將它們做交換,設4為最大的結點,并繼續以結點4開始做下一步運算。
因此可以給出偽代碼如下:
MAX-HEAPIFY(A,i)
1 l=LEFT-CHILD(i)
2 r=RIGHT-CHILD(i)
3 if l<=A.heap-size and A[l]>A[i]
4 largest=l
5 else
6 largest=i
7 if r<=A.heap-size and A[r]>A[largest]
8 largest=r
9 if largest != i
10 exchange A[i] with A[largest]
11 MAX-HEAPIFY(A,largest)
在以上這些步驟中,調整A[i]、A[l]、A[r]的關系的時間代價為Θ(1),再加上一棵以i的子節點為根結點的子樹上運行MAX-HEAPIFY的時間代價(注意此處的遞歸不一定會發生,此處只是假設其發生)。因為每個子節點的子樹的大小至多為2n/3(最壞情況發生在樹的底層恰好半滿的時候)。因此MAX-HEAPIFY過程的運行時間為:
T(n)≤T(2n/3)+Θ(1)
也就是:
T(n)=O(lgn)
通過BUILD-MAX-HEAP構建最大堆
前面我們通過自頂向下的方式維護了一個最大堆,這里將通過自底向上的方式通過MAX-HEAPIFY將一個n=A.length的數組A[1...n]轉換成最大堆。
回顧一下上面的圖示,其總共有9個結點,取小于或等于9/2的最大整數為4,從4+1,4+2,一直到n都是該樹的葉子結點,你發現了么?這對任意n都是成立的哦。
因此這里我們就要從4開始不斷的調用MAX-HEAPIFY(A,i)來構建最大堆。
為什么會有這一思路呢?
原因是既然我們知道了哪些結點是葉子結點,從最后一個非葉子結點(這里是4)開始,一次調用MAX-HEAPIFY函數,就會將該結點與葉子結點做相應的調整,這其實也就是一個遞歸的過程。
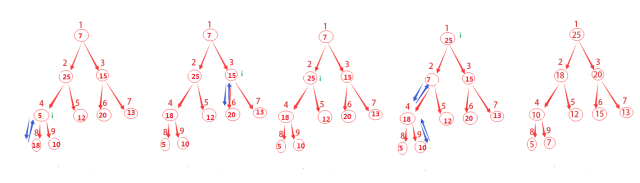
圖示已經這么清晰了,就直接上偽代碼咯。
BUILD-MAX-HEAP(A)
1 A.heap-size=A.length
2 for i=小于或等于A.length/2的最大整數 downto 1
3 MAX-HEAPIFY(A,i)
通過HEAPSORT進行堆排序算法
所謂的堆排序算法,先通過前面的BUILD-MAX-HEAP將輸入數組A[1...n]建成最大堆,其中n=A.length。而數組中的元素總在根結點A[1]中,通過把它與A[n]進行互換,就能將該元素放到正確的位置。
如何讓原來根的子結點仍然是最大堆呢,可以通過從堆中去掉結點n,而這可以通過減少A.heap?size來間接的完成。但這樣一來新的根節點就違背了最大堆的性質,因此仍然需要調用MAX-HEAPIFY(A,1),從而在A[1...n?1]上構造一個新的最大堆。
通過不斷重復這一過程,知道堆的大小從n?1一直降到2即可。
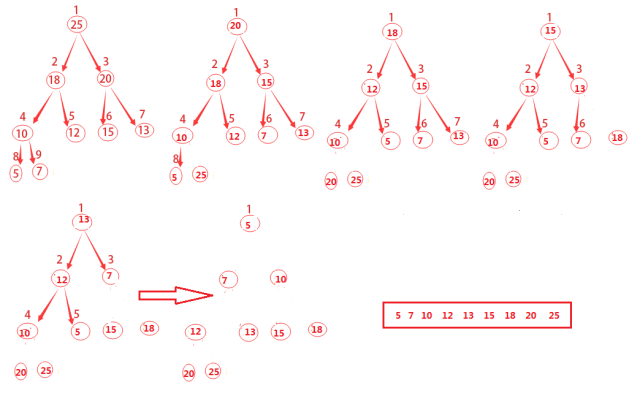
上圖的演進方式主要有兩點:
1)將A[1]和A[i]互換,i從A.length一直遞減到2
2)不斷調用MAX-HEAPIFY(A,1)對剩余的整個堆進行重新構建
一直到最后堆已經不存在了。
HEAPSORT(A)
1 BUILD-MAX-HEAP(A)
2 for i=A.length downto 2
3 exchange A[1] with A[i]
4 A.heap-size=A.heap-size-1
5 MAX-HEAPIFY(A,1)
優先隊列
下一篇博文我們就會介紹大名鼎鼎的快排,快速排序啦,歡迎童鞋們預定哦~
話說堆排序雖然性能上不及快速排序,但作為一個盡心盡力的數據結構而言,其可謂業界良心吶。它還為我們提供了傳說中的“優先隊列”。
優先隊列(priority queue)和堆一樣,堆有最大堆和最小堆,優先隊列也有最大優先隊列和最小優先隊列。
優先隊列是一種用來維護由一組元素構成的集合S的數據結構,其中每個元素都有一個相關的值,稱之為關鍵字(key)。
一個最大優先隊列支持一下操作:
MAXIMUM(S):返回S中有著最大鍵值的元素。
EXTRACT?MAX(S):去掉并返回S中的具有最大鍵字的元素。
INCREASE?KEY(S,x,a):將元素x的關鍵字值增加到a,這里假設a的值不小于x的原關鍵字值。
INSERT(S,x):將元素x插入集合S中,這一操作等價于S=S∪{x}。
這里來舉一個最大優先隊列的示例,我曾在關于“50% CPU 占有率”題目的內容擴展 這篇博文中簡單介紹過Windows的系統進程機制。
這里以圖片的形式簡單的貼出來如下:
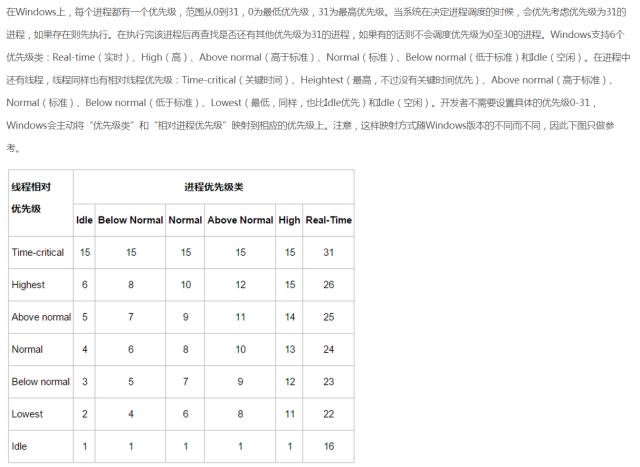
在用堆實現優先隊列時,需要在堆中的每個元素里存儲對應對象的句柄(handle)。句柄的準確含義依賴于具體的應用程序,可以是指針,也可以是整型數。
在堆的操作過程中,元素會改變其在數組中的位置,因此在具體實現中,在重新確定堆元素位置時,就自然而然地需要改變其在數組中的位置。
一、前面的MAXIMUM(S)過程其實很簡單,完全可以在Θ(1)時間內完成,因為只需要返回數組的第一個元素就可以呀,它已經是最大優先隊列了嘛。
HEAP-MAXIMUM(A)
1 return A[1]
二、EXTRACT?MAX(S)就稍顯復雜了一點,它的時間復雜度是O(lgn),因為這里面除了MAX-HEAPIFY(A,1)以外,其他的操作都是常量時間的。
HEAP-EXTRACT-MAX(A)
1 if A.heap-size < 1
2 error "堆下溢"
3 max=A[1]
4 A[1]=A[A.heap-size]
5 A.heap-size=A.heap-size-1
6 MAX-HEAPIFY(A,1)
7 return max
三、INCREASE?KEY(S,x,a)需要將一個大于元素x原有關鍵字值的a加到元素x上。
和上一個函數一樣,首先判斷a知否比原有的關鍵字更大。
然后就是老辦法了,不斷的將該結點與父結點做對比,如果父結點更小,那么就將他們進行對換。
相信有圖示會更加清楚,于是……再來一張圖。
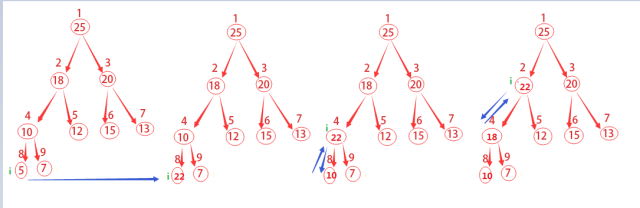
HEAP-INCREASE-KEY(A,i,key)
1 if key < A[i]
2 error "新關鍵字值比當前關鍵字值更小"
3 A[i]=key
4 while i>1 and A[PARENT(i)] < A[i]
5 exchange A[i] with A[PARENT(I)]
6 i=PARENT(i)
在包含n個元素的堆上,HEAP-INCREASE-KEY的運行時間就是O(lgn)了。因為在第3行做了關鍵字更新的結點到根結點的路徑長度為O(lgn)。
四、INSERT(S,x)首先通過一個特殊的關鍵字(比如這里的-10000擴展)結點來擴展最大堆,然后調用HEAP-INCREASE-KEY來為新的結點設置對應的關鍵字,同時保持最大堆的性質。
MAX-HEAP-INSERT(A,key)
1 A.heap-size=A.heap-sieze+1
2 A[A.heap-size]=-10000
3 HEAP-INCREASE-KEY(A,A.hep-size,key)
在包含n個元素的堆上,MAX-HEAP-INSERT的運行時間就是O(lgn)了。因為這個算法相對于上一個算法,除了HEAP-INCREASE-KEY之外就都是常量的運行時間了,而HEAP-INCREASE-KEY的運行時間我們在上一部分已經講過了。
總而言之,在一個包含n個元素的堆中,所有優先隊列的操作時間都不會大于O(lgn)。
---END---
審核編輯 :李倩
-
算法
+關注
關注
23文章
4608瀏覽量
92844 -
數據結構
+關注
關注
3文章
573瀏覽量
40124 -
數組
+關注
關注
1文章
417瀏覽量
25940
原文標題:五張圖帶你體會堆算法
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+一本介紹基礎硬件算法模塊實現的好書
如何使用SystemView的堆監控功能
單相整流橋堆怎么測量好壞
算法系列:彩色轉灰度
MDSC-1000C雙張傳感器在家電五金沖壓疊料檢測中的創新應用


壓電疊堆功率放大器在直升機機身振動研究中的應用
核反應堆工作原理 核反應堆的燃料是什么
堆和棧的區別和使用注意事項
微軟用 AI 簡化核反應堆監管審批流程;比亞迪獲首張 L3 級自動駕駛測試牌照

分布式可視化管理系統,讓多媒體會議管理更高效!






 工商網監
工商網監
評論