

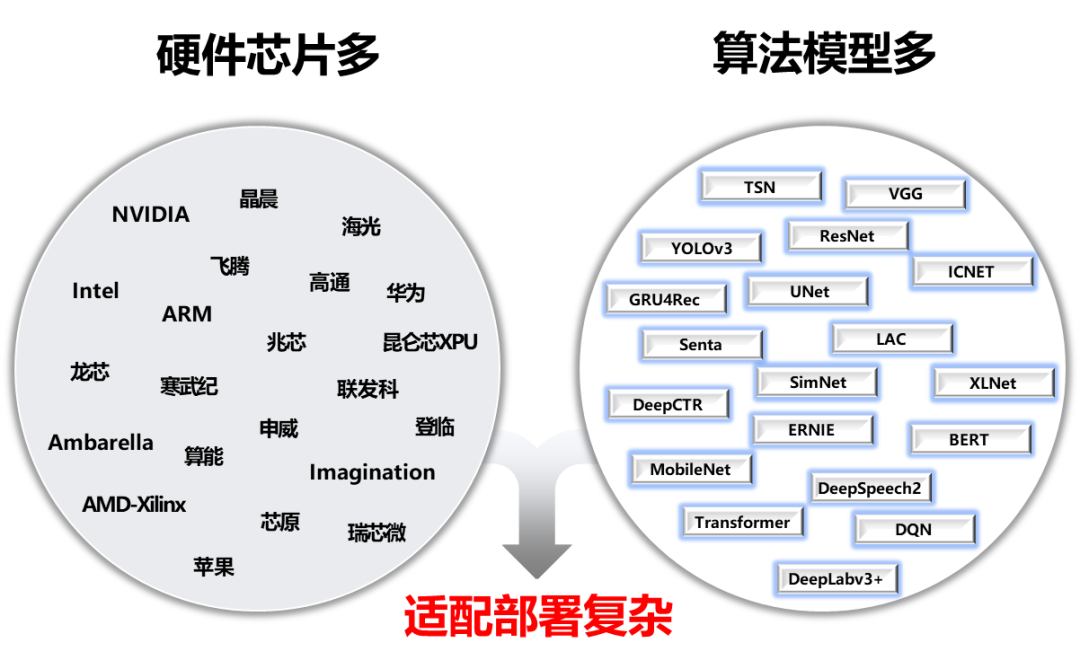
為了解決AI部署落地難題,我們發(fā)起了FastDeploy項目。FastDeploy針對產(chǎn)業(yè)落地場景中的重要AI模型,將模型API標(biāo)準(zhǔn)化,提供下載即可運行的Demo示例。相比傳統(tǒng)推理引擎,做到端到端的推理性能優(yōu)化。FastDeploy還支持在線(服務(wù)化部署)和離線部署形態(tài),滿足不同開發(fā)者的部署需求。
經(jīng)過為期一年的高密度打磨,F(xiàn)astDeploy目前具備三類特色能力:
全場景:支持GPU、CPU、Jetson、ARM CPU、瑞芯微NPU、晶晨NPU、恩智浦NPU等多類硬件,支持本地部署、服務(wù)化部署、Web端部署、移動端部署等,支持CV、NLP、Speech三大領(lǐng)域,支持圖像分類、圖像分割、語義分割、物體檢測、字符識別(OCR)、人臉檢測識別、人像扣圖、姿態(tài)估計、文本分類、信息抽取、行人跟蹤、語音合成等16大主流算法場景。
易用靈活:三行代碼完成AI模型的部署,一行API完成模型替換,無縫切換至其他模型部署,提供了150+熱門AI模型的部署Demo。
極致高效:相比傳統(tǒng)深度學(xué)習(xí)推理引擎只關(guān)注模型的推理時間,F(xiàn)astDeploy則關(guān)注模型任務(wù)的端到端部署性能。通過高性能前后處理、整合高性能推理引擎、一鍵自動壓縮等技術(shù),實現(xiàn)了AI模型推理部署的極致性能優(yōu)化。
項目傳送門:https://github.com/PaddlePaddle/FastDeploy
以下將對該3大特性做進(jìn)一步技術(shù)解讀,全文大約2100字,預(yù)計閱讀時長3分鐘。
1
3大特性篇
2
3步部署實戰(zhàn)篇,搶先看
CPU/GPU部署實戰(zhàn)
Jetson部署實戰(zhàn)
RK3588部署實戰(zhàn)(RV1126、晶晨A311D等NPU類似)
1
3大特性解讀
全場景:一套代碼云邊端多平臺多硬件一網(wǎng)打盡,覆蓋CV、NLP、Speech
支持PaddleInference、TensorRT、OpenVINO、ONNXRuntime、PaddleLite、RKNN等后端,覆蓋常見的NVIDIAGPU、x86CPU、Jetson Nano、Jetson TX2、ARMCPU(移動端、ARM開發(fā)板)、Jetson Xavier、瑞芯微NPU(RK3588、RK3568、RV1126、RV1109、RK1808)、晶晨NPU(A311D、S905D)等云邊端場景的多類幾十款A(yù)I硬件部署。同時支持服務(wù)化部署、離線CPU/GPU部署、端側(cè)和移動端部署方式。針對不同硬件,統(tǒng)一API保證一套代碼在數(shù)據(jù)中心、邊緣部署和端側(cè)部署無縫切換。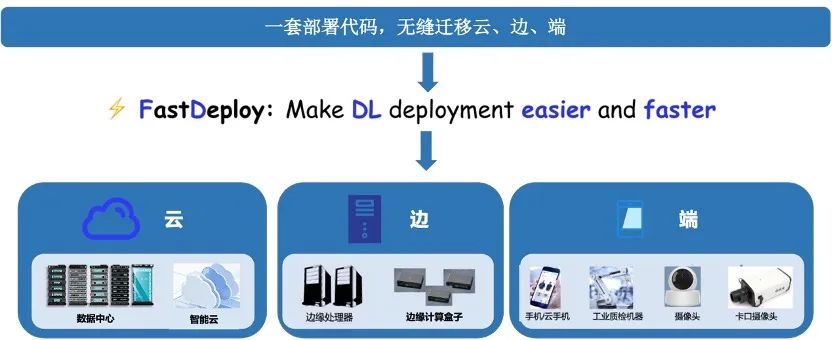 FastDeploy支持CV、NLP、Speech三大AI領(lǐng)域,覆蓋16大類算法(圖像分類、圖像分割、語義分割、物體檢測、字符識別(OCR) 、人臉檢測、人臉關(guān)鍵點檢測、人臉識別、人像扣圖、視頻扣圖、姿態(tài)估計、文本分類 信息抽取 文圖生成、行人跟蹤、語音合成)。支持飛槳PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR、PaddleNLP、PaddleSpeech 6大熱門AI套件的主流模型,同時也支持生態(tài)(如PyTorch、ONNX等)熱門模型的部署。
FastDeploy支持CV、NLP、Speech三大AI領(lǐng)域,覆蓋16大類算法(圖像分類、圖像分割、語義分割、物體檢測、字符識別(OCR) 、人臉檢測、人臉關(guān)鍵點檢測、人臉識別、人像扣圖、視頻扣圖、姿態(tài)估計、文本分類 信息抽取 文圖生成、行人跟蹤、語音合成)。支持飛槳PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR、PaddleNLP、PaddleSpeech 6大熱門AI套件的主流模型,同時也支持生態(tài)(如PyTorch、ONNX等)熱門模型的部署。 ?
?易用靈活,三行代碼完成模型部署,一行命令快速體驗150+熱門模型部署
FastDeploy三行代碼可完成AI模型在不同硬件上的部署,極大降低了AI模型部署難度和工作量。一行命令切換TensorRT、OpenVINO、Paddle Inference、Paddle Lite、ONNX Runtime、RKNN等不同推理后端和對應(yīng)硬件。低門檻的推理引擎后端集成方案,平均一周時間即可完成任意硬件推理引擎的接入使用,解耦前后端架構(gòu)設(shè)計,簡單編譯測試即可體驗FastDeploy支持的AI模型。開發(fā)者可以根據(jù)模型API實現(xiàn)相應(yīng)模型部署,也可以選擇git clone一鍵獲取150+熱門AI模型的部署示例Demo,快速體驗不同模型的推理部署。 # PP-YOLOE的部署 import fastdeploy as fd import cv2 model = fd.vision.detection.PPYOLOE("model.pdmodel", "model.pdiparams", "infer_cfg.yml") im = cv2.imread("test.jpg") result = model.predict(im) # YOLOv7的部署 import fastdeploy as fd import cv2 model = fd.vision.detection.YOLOv7("model.onnx") im = cv2.imread("test.jpg") result = model.predict(im)FastDeploy部署不同模型
# PP-YOLOE的部署 import fastdeploy as fd import cv2 option = fd.RuntimeOption() option.use_cpu() option.use_openvino_backend() # 一行命令切換使用 OpenVINO部署 model = fd.vision.detection.PPYOLOE("model.pdmodel", "model.pdiparams", "infer_cfg.yml", runtime_option=option) im = cv2.imread("test.jpg") result = model.predict(im)FastDeploy切換后端和硬件極致高效:一鍵壓縮提速,預(yù)處理加速,端到端性能優(yōu)化,提升AI算法產(chǎn)業(yè)落地
FastDeploy在吸收TensorRT、OpenVINO、Paddle Inference、Paddle Lite、ONNX Runtime、RKNN等高性能推理優(yōu)勢的同時,通過端到端的推理優(yōu)化解決了傳統(tǒng)推理引擎僅關(guān)心模型推理速度的問題,提升整體推理速度和性能。集成自動壓縮工具,在參數(shù)量大大減小的同時(精度幾乎無損),推理速度大幅提升。使用CUDA加速優(yōu)化預(yù)處理和后處理模塊,將YOLO系列的模型推理加速整體從41ms優(yōu)化到25ms。端到端的優(yōu)化策略,徹底解決AI部署落地中的性能難題。更多性能優(yōu)化,歡迎關(guān)注GitHub了解詳情。https://github.com/PaddlePaddle/FastDeploy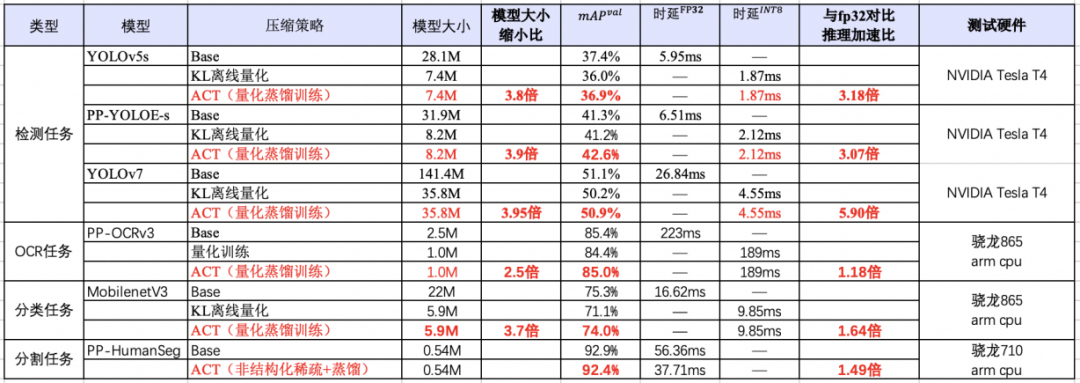 ?
?
?
?2
3步部署實戰(zhàn)篇,搶先看
1
CPU/GPU部署實戰(zhàn)(以YOLOv7為例)
安裝FastDeploy部署包,下載部署示例(可選,也可以三行API實現(xiàn)部署代碼)
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html git clone https://github.com/PaddlePaddle/FastDeploy.git cd examples/vision/detection/yolov7/python/準(zhǔn)備模型文件和測試圖片
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpgCPU/GPU推理模型
# CPU推理 python infer.py --model yolov7.onnx --image 000000014439.jpg --device cpu # GPU推理 python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu # GPU上使用TensorRT推理 python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu --use_trt True推理結(jié)果示例:

2
Jetson部署實戰(zhàn)(以YOLOv7為例)
安裝FastDeploy部署包,配置環(huán)境變量
git clone https://github.com/PaddlePaddle/FastDeploy cd FastDeploy mkdir build && cd build cmake .. -DBUILD_ON_JETSON=ON -DENABLE_VISION=ON -DCMAKE_INSTALL_PREFIX=${PWD}/install make -j8 make install cd FastDeploy/build/install source fastdeploy_init.sh準(zhǔn)備模型文件和測試圖片
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg編譯推理模型
cd examples/vision/detection/yolov7/cpp cmake .. -DFASTDEPLOY_INSTALL_DIR=${FASTDEPOLY_DIR} mkdir build && cd build make -j # 使用TensorRT推理(當(dāng)模型不支持TensorRT時會自動轉(zhuǎn)成使用CPU推理) ./infer_demo yolov7s.onnx 000000014439.jpg 27s.onnx 000000014439.jpg 2推理結(jié)果示例:

3
RK3588部署實戰(zhàn)(以輕量化檢測網(wǎng)絡(luò)PicoDet為例)
安裝FastDeploy部署包,下載部署示例(可選,也可以三行API實現(xiàn)部署代碼)
# 參考編譯文檔,完成FastDeploy編譯安裝 # 參考文檔鏈接:https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/rknpu2.md # 下載部署示例代碼 git clone https://github.com/PaddlePaddle/FastDeploy.git cd examples/vision/detection/paddledetection/rknpu2/python準(zhǔn)備模型文件和測試圖片
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip unzip -qo picodet_s_416_coco_npu.zip ## 下載Paddle靜態(tài)圖模型并解壓 wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip unzip -qo picodet_s_416_coco_npu.zip # 靜態(tài)圖轉(zhuǎn)ONNX模型,注意,這里的save_file請和壓縮包名對齊 paddle2onnx --model_dir picodet_s_416_coco_npu --model_filename model.pdmodel --params_filename model.pdiparams --save_file picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx --enable_dev_version True python -m paddle2onnx.optimize --input_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx --output_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx --input_shape_dict "{'image':[1,3,416,416]}" # ONNX模型轉(zhuǎn)RKNN模型 # 轉(zhuǎn)換模型,模型將生成在picodet_s_320_coco_lcnet_non_postprocess目錄下 python tools/rknpu2/export.py --config_path tools/rknpu2/config/RK3588/picodet_s_416_coco_npu.yaml # 下載圖片 wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg推理模型
python3 infer.py --model_file ./picodet _3588/picodet_3588.rknn --config_file ./picodet_3588/deploy.yaml --image images/000000014439.jpg
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
88文章
34342瀏覽量
275529 -
人工智能
+關(guān)注
關(guān)注
1804文章
48759瀏覽量
246729 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5555瀏覽量
122508
原文標(biāo)題:炸裂!三行代碼完成AI模型的部署!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
企業(yè)部署AI大模型怎么做
MediaTek天璣9400率先完成阿里Qwen3模型部署
AI端側(cè)部署開發(fā)(SC171開發(fā)套件V3)
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
博實結(jié)完成DeepSeek大模型本地化部署
行芯完成DeepSeek-R1大模型本地化部署
C#集成OpenVINO?:簡化AI模型部署

添越智創(chuàng)基于 RK3588 開發(fā)板部署測試 DeepSeek 模型全攻略
企業(yè)AI模型部署攻略
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型
AI模型部署邊緣設(shè)備的奇妙之旅:如何實現(xiàn)手寫數(shù)字識別
AI模型部署和管理的關(guān)系
如何在STM32f4系列開發(fā)板上部署STM32Cube.AI,
企業(yè)AI模型部署怎么做
三行代碼完成生成式AI部署





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論