") AI、游戲與通用計算,國產(chǎn)GPU的定位
AI、游戲與通用計算,國產(chǎn)GPU的定位
摩爾線程

芯動科技
壁仞科技



原文標題:AI、游戲與通用計算,國產(chǎn)GPU的定位
文章出處:【微信公眾號:電子發(fā)燒友網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
電子發(fā)燒友網(wǎng)
+關(guān)注
關(guān)注
1010文章
544瀏覽量
164398
原文標題:AI、游戲與通用計算,國產(chǎn)GPU的定位
文章出處:【微信號:elecfans,微信公眾號:電子發(fā)燒友網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
CPU\GPU引領(lǐng),國產(chǎn)AI PC進階
電子發(fā)燒友網(wǎng)報道(文/黃晶晶)當前AI PC已經(jīng)成為PC產(chǎn)業(yè)的下一個浪潮,國產(chǎn)CPU、GPU廠商在PC市場一直處于追趕態(tài)勢,AI PC給了大家新的機遇,在這個賽道

GPU是如何訓(xùn)練AI大模型的
在AI模型的訓(xùn)練過程中,大量的計算工作集中在矩陣乘法、向量加法和激活函數(shù)等運算上。這些運算正是GPU所擅長的。接下來,AI部落小編帶您了解GPU
《CST Studio Suite 2024 GPU加速計算指南》
《GPU Computing Guide》是由Dassault Systèmes Deutschland GmbH發(fā)布的有關(guān)CST Studio Suite 2024的GPU計算指南。涵蓋GP
發(fā)表于 12-16 14:25
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
場景精確投射到2D平面;最后在像素著色階段完成材質(zhì)渲染和光照明細處理。DirectX API的迭代推動了可編程著色器的發(fā)展,解放了GPU的通用計算潛能。特別是像素著色器的設(shè)計,啟發(fā)了我在深度學(xué)習(xí)任務(wù)中
發(fā)表于 11-24 17:12
GPU加速計算平臺是什么
GPU加速計算平臺,簡而言之,是利用圖形處理器(GPU)的強大并行計算能力來加速科學(xué)計算、數(shù)據(jù)分析、機器學(xué)習(xí)等復(fù)雜
新的Arm GPU助力釋放消費電子設(shè)備市場中的游戲和AI創(chuàng)新潛能
作為人們?nèi)粘?shù)字生活中不可或缺的一部分,Arm GPU 賦能了從當今智能手機上的沉浸式游戲,到各類邊緣側(cè)人工智能 (AI) 體驗的方方面面。

為什么GPU對AI如此重要?
GPU在人工智能中相當于稀土金屬,甚至黃金,它們在當今生成式人工智能時代中的作用不可或缺。那么,為什么GPU在人工智能發(fā)展中如此重要呢?什么是GPU圖形處理器(GPU)是一種通常用于進

為什么跑AI往往用GPU而不是CPU?
GPU的能力,并且支持的GPU數(shù)量越多,就代表其AI性能越強大。那么問題來了,為什么是GPU而不是CPU?GPU難道不是我們?nèi)粘J褂玫碾娔X里
大模型時代,國產(chǎn)GPU面臨哪些挑戰(zhàn)
電子發(fā)燒友網(wǎng)報道(文/李彎彎)隨著人工智能技術(shù)的快速發(fā)展,對GPU計算能力的需求也越來越高。國內(nèi)企業(yè)也正在不斷提升GPU性能,以滿足日益增長的應(yīng)用需求。然而,相較于國際巨頭,國內(nèi)GPU

國產(chǎn)GPU在AI大模型領(lǐng)域的應(yīng)用案例一覽
電子發(fā)燒友網(wǎng)報道(文/李彎彎)近一年多時間,隨著大模型的發(fā)展,GPU在AI領(lǐng)域的重要性再次凸顯。雖然相比英偉達等國際大廠,國產(chǎn)GPU起步較晚、聲勢較小。不過近幾年,國內(nèi)不少

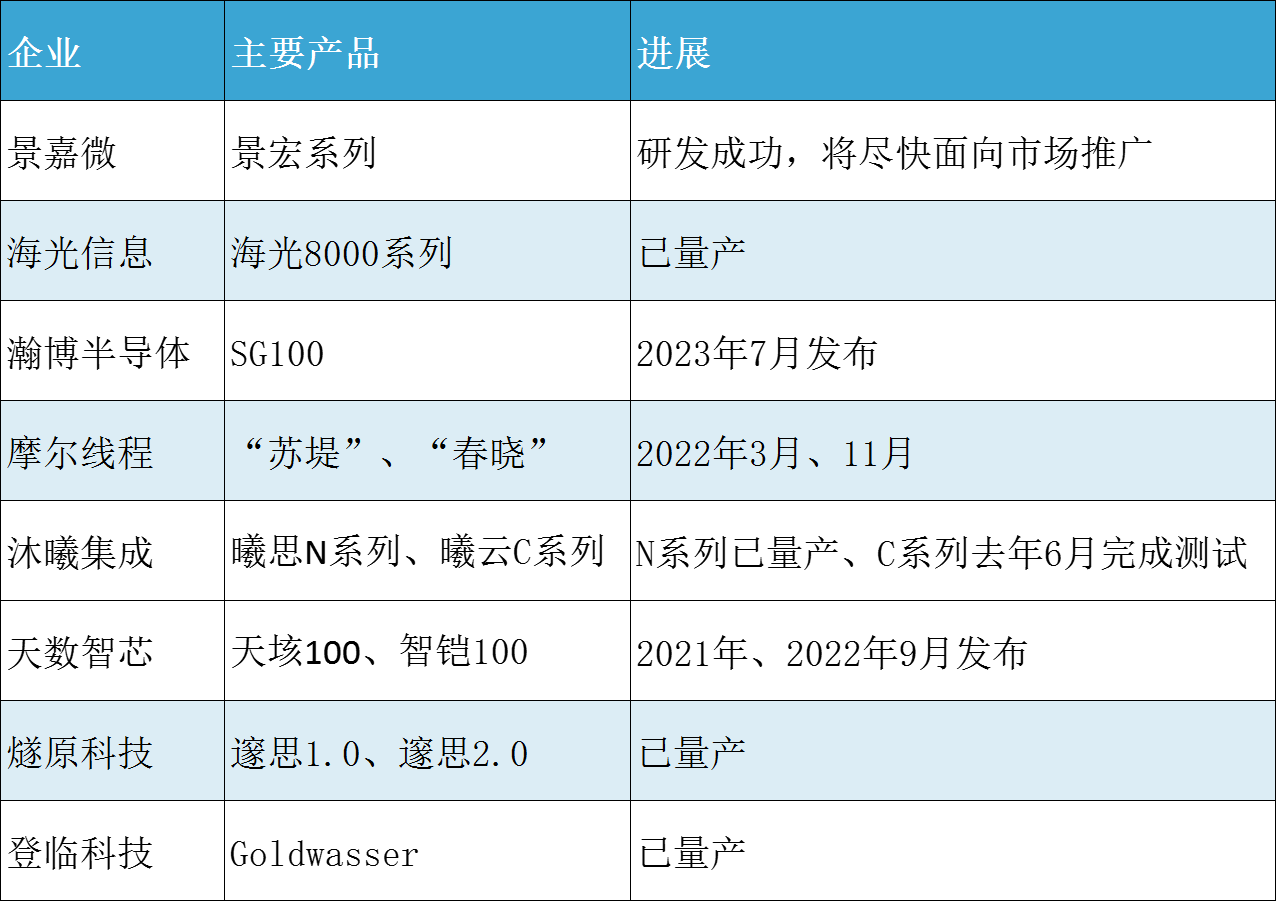
盤點國產(chǎn)GPU在支持大模型應(yīng)用方面的進展
,近些年國內(nèi)也有不少GPU企業(yè)在逐步成長,雖然在大模型的訓(xùn)練和推理方面,與英偉達GPU差距極大,但是不可忽視的是,不少國產(chǎn)GPU企業(yè)也在AI
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
基礎(chǔ)設(shè)施,人們?nèi)匀粵]有定論。如果 Mipsology 成功完成了研究實驗,許多正受 GPU 折磨的 AI 開發(fā)者將從中受益。
GPU 深度學(xué)習(xí)面臨的挑戰(zhàn)
三維圖形是 GPU 擁有如此
發(fā)表于 03-21 15:19
硅光計算芯片:AI芯片國產(chǎn)化的關(guān)鍵突破口
大模型訓(xùn)練和推理的硬件以通用圖形處理單元(GPU)為主,2022年全球GPU市場規(guī)模達到448.3億美元,美國AI芯片巨頭英偉達公司占有80%的市場份額并仍在持續(xù)攀升。
發(fā)表于 01-19 14:12
?5387次閱讀
GPU技術(shù)、生態(tài)及算力分析
對比AMD從2013年開始建設(shè)GPU生態(tài),近10年時間后用于通用計算的ROCm開放式軟件平臺才逐步有影響力,且還是在兼容CUDA的基礎(chǔ)上。因此我們認為國內(nèi)廠商在軟件和生態(tài)層面與英偉達CUDA生態(tài)的差距較計算性能更為明顯。

如何能夠?qū)崿F(xiàn)通用FPGA問題?
FPGA 是一種偽通用計算加速器,與 GPGPU(通用 GPU)類似,F(xiàn)PGA 可以很好地卸載特定類型的計算。從編程角度上講,F(xiàn)PGA 比 CPU 更難,但從工作負載角度上講 FPGA
發(fā)表于 12-29 10:29
?459次閱讀





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論