 為什么需要可預期高性能網絡呢?
為什么需要可預期高性能網絡呢?
近日,阿里云智能在SIGCOMM 2022斬獲兩篇關于“可預期高性能網絡”的研究論文“μFAB”和“Solar”。
可預期高性能網絡,是阿里云基礎設施研發的下一代數據中心網絡架構,是一種可以為上層應用提供穩定的可用性、帶寬和低延遲保證的網絡。作為可預期高性能網絡的技術成果之一,本文將對“μFAB”和“Solar”這兩篇發表在SIGCOMM 2022的論文進行深度解讀。
為什么需要“可預期高性能網絡”?
當前的數據中心發展面臨重大挑戰,無論從硬件更迭、應用規模,還是架構演進都對網絡提出了更高的要求。
首先,隨著CPU、GPU、TPU、DPU等新型算力硬件的不斷推陳出新,大量的數據需要網絡進行交互。存儲介質的不斷推陳出新,使得磁盤處理的時延從毫秒級降低到了微秒級,數據讀取的吞吐也得到了極大的提升,從而使得網絡逐漸成為端到端性能的短板。
其次,ML/HPC、存儲、數據庫等大型新型分布式系統和應用,對于性能越來越敏感,作為端到端性能的重要一環,勢必要求網絡提供極致的網絡傳輸服務:例如,ESSD存儲要求百萬IOPS和100微秒的訪問時延,這種情況下任何網絡的抖動都會造成應用性能的下降。另外,分布式機器學習在單集群部署規模已達到10K-100K加速卡的情況下,需要頻繁的數據聚合和再分配,依賴網絡帶寬的保障和微秒級別的網絡時延,系統的瓶頸已經逐漸從計算轉移到了網絡傳輸。
此外,數據中心的資源池化(包括硬盤、GPU,甚至內存等)已成為主流。資源池化能夠帶來應用部署的便利,并且不同資源可以獨立進行演進升級,更能節省資源降低使用成本。但資源池化對網絡有非常苛刻的要求,各種資源至少需要100G以上的接入網絡帶寬和10us以內甚至2us以內的時延。隨著內存池化的研發,對于網絡的依賴會更加迫切。
μFAB:Predictable vFabric on Informative Data Plane
今天,隨著云計算的不斷發展,高性能存儲、分布式機器學習、資源池化等應用和架構的變革,對于網絡傳輸的要求也越來越高,即使微秒級別的網絡異常也會使得應用受影響。傳統的“盡力而為”的網絡服務模型已越來越不適應未來應用的需求。
可預期DCN服務模型
μFAB的目標,是在云數據中心為租戶提供帶寬保障、低延遲保障,以及最大化利用網絡帶寬資源。但在目前的網絡架構中,要同時實現這三點是非常困難,主要原因是:之前的工作通常把網絡當作一個黑盒,利用時延、探測等一系列的啟發式算法來做速率控制和路徑選擇,這樣便造成了需要毫秒級別的收斂時間,難以滿足應用日漸增加的對于性能的需求。 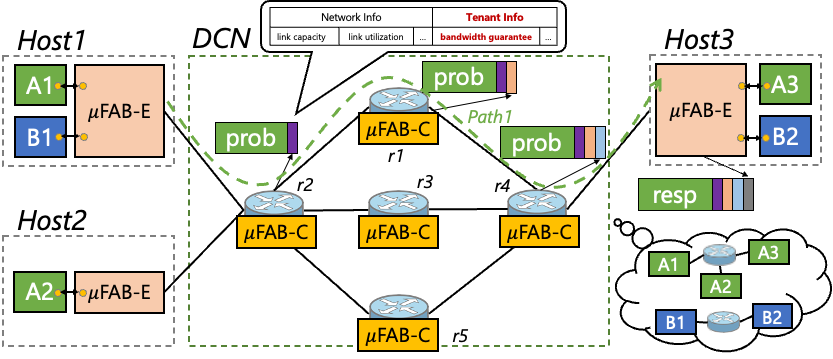
圖 | μFAB的服務模型
μFAB的設計理念則恰好相反,其核心思想是網絡的透明化和信息化,即利用可編程網絡數據平面提供的鏈路狀態和租戶信息,并將這些信息反饋到主機側用于智能的速率控制和路徑選擇。
上圖所示μFAB的服務模型,每個租戶會被分配一個虛擬的網絡(Virtual Fabric),該虛擬網絡為租戶提供最小帶寬保障、最大化利用資源、低長尾延遲等三個SLA保障。而租戶的最小帶寬分配遵循云的彈性部署規范,租戶總帶寬之和不會超過網絡物理總帶寬。μFAB利用可編程網絡提供的精確信息,再通過端網協同的機制達到上述目標。
端網協同的具體工作方式為:一方面,主機側的μFAB-E模塊發送探測包,用以獲取網絡的信息,從而指導其做“速率控制”和“路徑選擇”。另一方面,網絡交換機上的μFAB-C模塊收集鏈路狀態和租戶的信息,并將這些信息做聚合,插入到發過來的探測包中,反饋給μFAB-E。
帶寬延遲保障算法
有了網絡透明化和端網協同,如何才能做到帶寬和時延的保障呢? μFAB使用的是按權重分配的做法,這樣做的好處是可以很快判斷出帶寬是否得到了滿足。發送窗口的計算方法為: 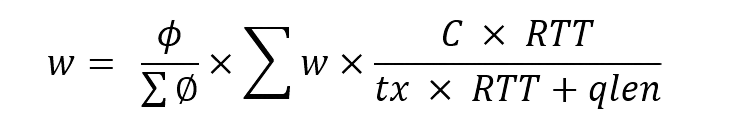
其中,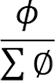 是按租戶的權重進行的按權分配,而
是按租戶的權重進行的按權分配,而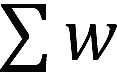 是交換機維護的所有租戶的發送窗口之和,
是交換機維護的所有租戶的發送窗口之和,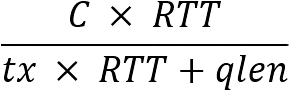 則是根據鏈路的負載進行的調整,用于最大化鏈路利用,同時做擁塞避免。
則是根據鏈路的負載進行的調整,用于最大化鏈路利用,同時做擁塞避免。 、
、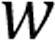 由探測包攜帶到網絡交換機中,
由探測包攜帶到網絡交換機中,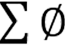 、由交換機維護的租戶信息的聚合,而tx、qlen是交換機維護的網絡鏈路信息。 ?
、由交換機維護的租戶信息的聚合,而tx、qlen是交換機維護的網絡鏈路信息。 ?
那么,當多個租戶同時有流量請求的時候,是不是大家一起發流量就會造成網絡擁塞,從而導致長尾時延呢?μFAB在解決這個問題同時保障長尾低時延的做法是:允許租戶無論何時都可以按照最小帶寬保障發送,只有在網絡有剩余帶寬的情況下,才會逐漸增大發送速率。這么做的原理是,最小帶寬是租戶的SLA保障必須滿足,而盡可能地提高發送速率則是額外的獎勵,時效性要求相對較低。這樣既滿足了租戶對于隨時獲取最小帶寬的承諾,又使得在有多租戶突發流量的沖突的時候,依然能夠保障網絡的長尾時延。
另一個重要的點是,μFAB能夠充分利用整個網絡的帶寬資源,當一個路徑上的帶寬資源已經被分配完時,能夠快速地進行路徑切換,從而使用多個路徑的網絡帶寬資源。在路徑切換時,需要考慮兩種場景:一是當前路徑的帶寬已經不滿足租戶SLA,這種情況需要立刻進行路徑切換,但也要注意不要過于頻繁地連續切換。二是發現有路徑的更多帶寬資源的時候,這種情況的路徑切換是一種最大化利用網絡資源的行為,但相對來說沒有緊迫的時間需求,因此不用做得過于頻繁。
理論分析和硬件實驗 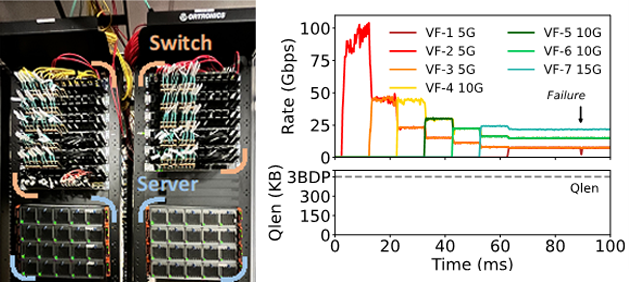
圖 | 測試環境和硬件測試結果
μFAB的理論分析表明:μFAB具備快速收斂,帶寬和時延保障等特性,即使在路徑切換中也能做到快速收斂而不會造成網絡震蕩。我們分別在FPGA和SOC的硬件網卡和Tofino交換機上做了相應的算法實現,并在三層fat-tree的網絡拓撲上做了網絡層驗證和應用層驗證。實驗表明,μFAB能提供給租戶最小帶寬保障和長尾低延遲,同時提供最大化地網絡帶寬利用,即使面對網絡故障的場景下,依然能夠快速收斂。 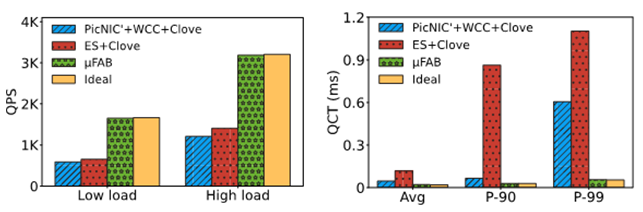
圖 | 應用層實測結果 為了驗證μFAB對于應用的實際增益,我們將一個租戶運行時延敏感型的Memcached,另一個租戶運行大帶寬的MongoDB應用進行對比實驗。實驗表明,μFAB能實現接近于理想狀態下的QPS(Query Per Second)和QCT(Query Completion Time)。這是因為μFAB總是能正確的選擇流量路徑,從而實現性能的隔離,以及快速的響應網絡擁塞。上圖可以看出μFAB能為應用等提供2.5倍的QPS提升、21倍的長尾延遲下降。
From Luna to Solar:The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud
與傳統的“盡力而為(best effort)”的網絡設計理念不同,可預期高性能網絡利用軟硬結合、跨層設計和端網協同的理念,可提供微秒級別的帶寬、延遲保障。
計算存儲分離架構 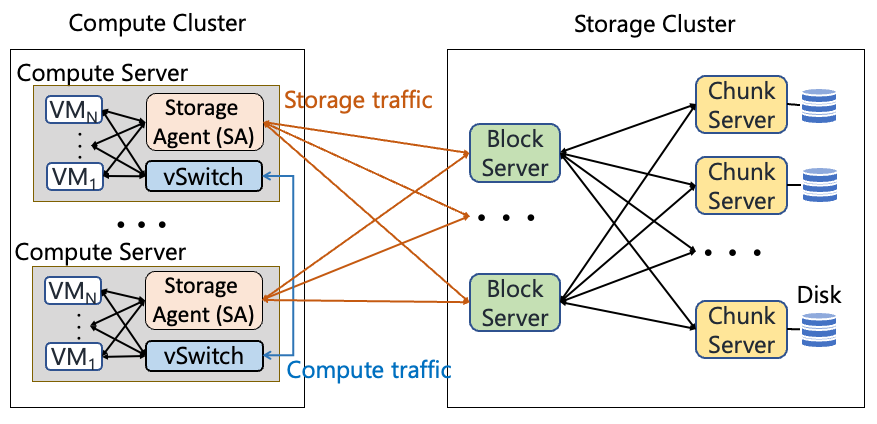
圖 | 計算存儲分離架構
在計算存儲分離架構下,所有的存儲I/O都需要網絡傳遞,因此網絡成為存儲應用的重要瓶頸。而存儲流量本身占了整個DCN的60%左右,大量的流量都是很多的小流組成的,例如40%的流量都不超過4KB。因此,存儲的流量對于帶寬和時延都有極高的要求。
Luna用戶態TCP協議
在應對SSD介質帶來的低時延同時,傳統內核態的tcp協議已然成為端到端性能的瓶頸。與存儲內部網絡使用RDMA來提高性能不同,計算到存儲網絡由于它的特殊要求,例如,需要支持十萬個連接這個規模,同時需要很高的互通性,而選擇了截然不同的協議。
2018年,阿里云在計算到存儲部署了用戶態tcp協議luna,實現了網絡到存儲的零拷貝和無鎖、零共享等機制,長尾延遲降低了80%。支持了新發布的ESSD產品,實現百萬IOPS和100微秒的I/O時延。
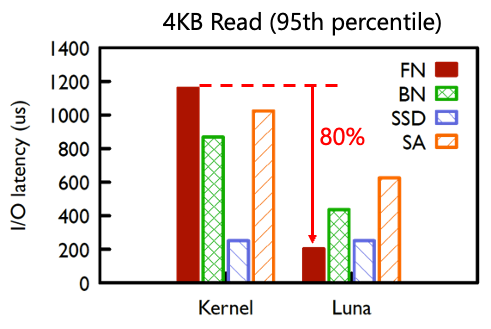
圖 | luna的長尾性能收益
裸金屬下的存儲挑戰
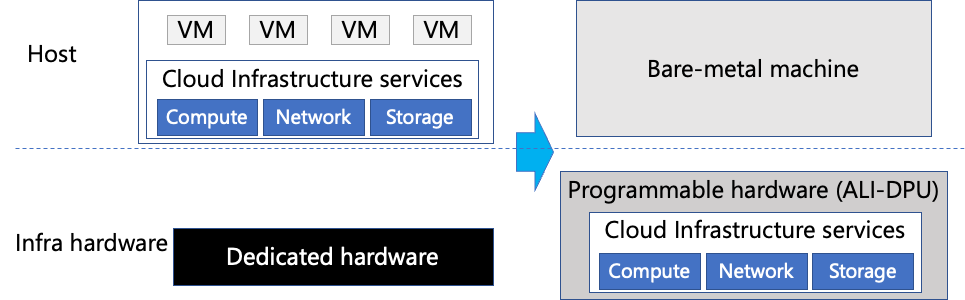
圖 | 裸金屬云的部署 裸金屬云為租戶提供整個物理主機,這樣租戶不僅可以靈活地定制機型和虛擬化平臺,快速上云,還能提供安全和性能的保障。例如,租戶在使用裸金屬服務器時,可以運行自定義的虛擬化平臺(如VMware cloud)或完成多云部署,甚至可以調用硬件底層API功能(如Intel RDT)。
但裸金屬云在提供給租戶更多可能的同時,也面臨自身性能和成本的挑戰。因為在將整個物理服務器交付給租戶的同時,裸金屬也不得不將云基礎設施軟件運行在“非侵入式”的硬件中,通常是網絡設備,如智能網卡、DPU、IPU、交換機等等。這樣的部署面臨著以下兩大挑戰:
● 資源受限:相對于物理服務器,這些網絡設備通常面臨更少的資源和更低的功耗限制。在這種條件下,要實現相同甚至更好的云服務性能變得極具挑戰;
● 帶寬受限:與傳統的虛擬化部署中,hypervisor和租戶使用內存拷貝交互數據不同,裸金屬場景下的虛擬化和數據交互需要經過智能網卡的緩存、處理和轉發,在單個方向上數據會兩次通過智能網卡內的PCIe拷貝,數據在網卡中的雙向拷貝造成帶寬減半。
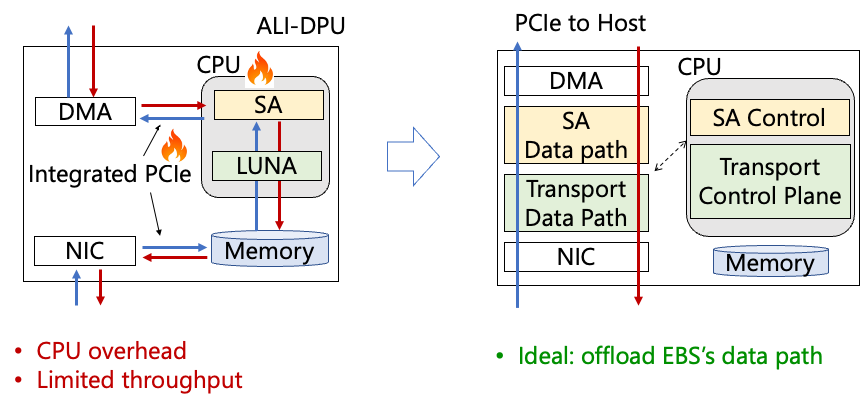
圖 | 裸金屬下存儲前端的挑戰 帶寬減半原因如上圖所示。當租戶發送數據→數據通過主機PCIe到達智能網卡→通過智能網卡內部PCIe到達網卡CPU(一次拷貝)→網卡CPU處理→再通過智能網卡內部PCIe發到網口(二次拷貝),再從網口中發出。同理,租戶從網絡中接收數據也要經歷2次拷貝,例如,當網口提供雙向100Gb/s吞吐時候,租戶實際能獲得的帶寬只有雙向50Gb/s。
理想情況下,我們希望數據平面能夠直達主機PCIe,不用經歷智能網卡內部PCIe的中轉。
存儲與網絡融合的Solar協議
Solar的設計目標是:能夠極大地卸載存儲和網絡處理到硬件網卡中,從而降低CPU開銷,在提供網絡性能的同時規避網絡故障。但面臨的現實問題是存儲和網絡的協議處理都非常復雜,且存在大量的狀態。尤其在資源受限的智能網卡中,能留給存儲使用的資源非常有限。做硬件卸載是非常困難的。
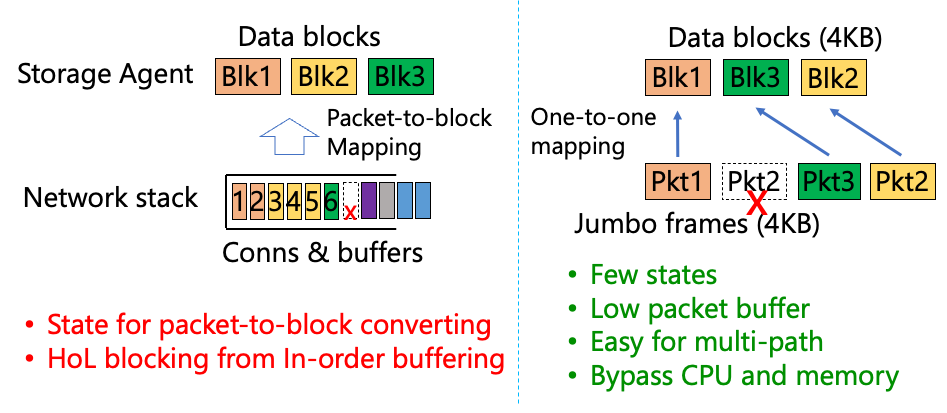
圖 | 存儲硬件卸載的挑戰和解決方案 因此,Solar的設計理念是盡可能地減少協議的復雜度,使得硬件卸載可以非常容易地實現。如上圖所示,具體做法是對網絡和存儲進行跨層融合,利用網絡的jumbo frame使得一個網絡的數據包就直接等效成一個存儲的block。這樣協議上就不需要維護數據包到block的映射,也不會有在丟包后出現的隊首阻塞問題。更少的狀態處理也意味著Solar能夠節省CPU開銷,以及支持多路徑等能力。 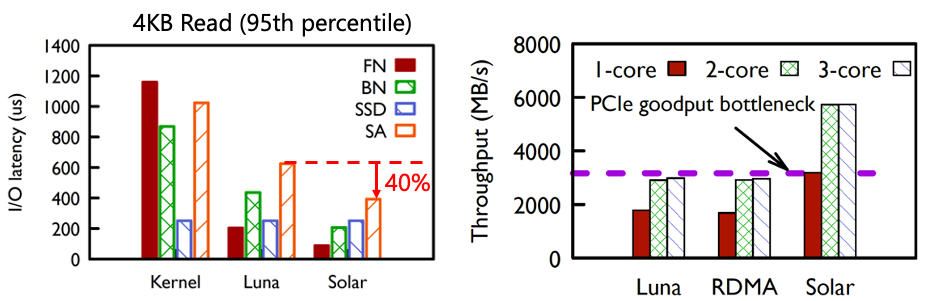
圖 | Solar的性能收益 從線上觀測看到,在采用Solar之后,計算側Storage agent(SA)的長尾時延下降了40%,這是因為Solar采用了存儲流量的數據平面卸載,這樣減少了CPU上的協議處理時延和時延的抖動。同時,由于流量不用經過兩次DPU上的PCIe bus,所以網絡吞吐能夠翻倍。
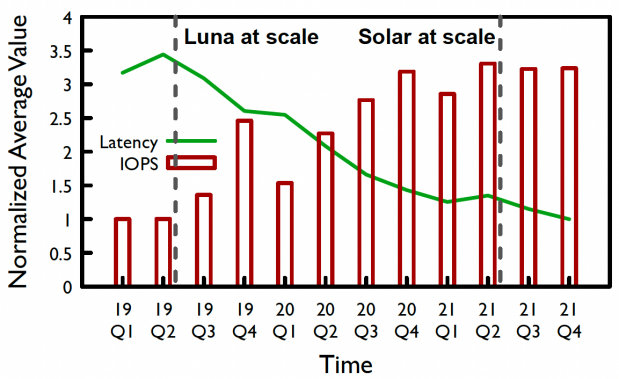
圖 | EBS存儲的時延和帶寬演進 多年的線上實測試數據表明,隨著luna和Solar的規模化部署,ebs存儲的時延在近幾年降低了72%,而IOPS提高了3倍。
結 語
可預期高性能網絡,是阿里云基礎設施為ML/HPC、高性能存儲等新型應用打造的新一代網絡架構,其核心目標是“為應用提供微秒級別的時延和帶寬保障”。μFAB和Solar分別闡述了實現上述目標的兩種重要技術手段:μFAB揭示了端網協同的融合設計,利用可編程網絡提供的精細網絡信息,在端上智能網卡用于速率控制和路徑選擇;Solar闡述了應用和網絡融合的設計理念,利用數據包和數據塊的一一映射,從而極大簡化狀態處理,提高處理吞吐、降低時延。這些設計的部署,極大地提升了網絡傳輸的服務質量,也給云上客戶以及未來算力融合帶來了持續價值。
審核編輯:劉清
-
DPU
+關注
關注
0文章
364瀏覽量
24201 -
TPU
+關注
關注
0文章
141瀏覽量
20740 -
eSSD
+關注
關注
0文章
8瀏覽量
7824
原文標題:深度解讀SIGCOMM 2022“可預期高性能網絡”論文
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區 助力打造高性能原生應用
如何采購高性能的MOS管?

如何設計才能達到符合預期的THD+N性能指標?
這些關鍵詞帶你了解智算中心高性能網絡
芯品# 高性能計算芯片
技術巔峰!探秘國內高性能模擬芯片的未來發展

愛立信吳日平:高性能可編程網絡賦能新型工業化
高性能 Flybuck
介紹一種高性能計算和數據中心網絡架構:InfiniBand(IB)

新款高性能網絡音頻模塊SV-2400V系列模塊介紹

打造穩定快速的家庭網絡,選購高性能4G路由器
如何監測Android網絡類型呢?






 工商網監
工商網監
評論