


來自谷歌和波士頓大學(xué)的研究者提出了一種「個性化」的文本到圖像擴散模型 DreamBooth,能夠適應(yīng)用戶特定的圖像生成需求。
近來,文本到圖像模型成為一個熱門的研究方向,無論是自然景觀大片,還是新奇的場景圖像,都可能使用簡單的文本描述自動生成的。
其中,渲染天馬行空的的想象場景是一項具有挑戰(zhàn)性的任務(wù),需要在新的場景中合成特定主題(物體、動物等)的實例,以便它們自然無縫地融入場景。
一些大型文本到圖像模型基于用自然語言編寫的文本提示(prompt)實現(xiàn)了高質(zhì)量和多樣化的圖像合成。這些模型的主要優(yōu)點是從大量的圖像 - 文本描述對中學(xué)到強大的語義先驗,例如將「dog」這個詞與可以在圖像中以不同姿勢出現(xiàn)的各種狗的實例關(guān)聯(lián)在一起。
雖然這些模型的合成能力是前所未有的,但它們?nèi)狈δ7陆o定參考主題的能力,以及在不同場景中合成主題相同、實例不同的新圖像的能力。可見,已有模型的輸出域的表達(dá)能力有限。

為了解決這個問題,來自谷歌和波士頓大學(xué)的研究者提出了一種「個性化」的文本到圖像擴散模型 DreamBooth,能夠適應(yīng)用戶特定的圖像生成需求。

論文地址:https://arxiv.org/abs/2208.12242
項目地址:https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
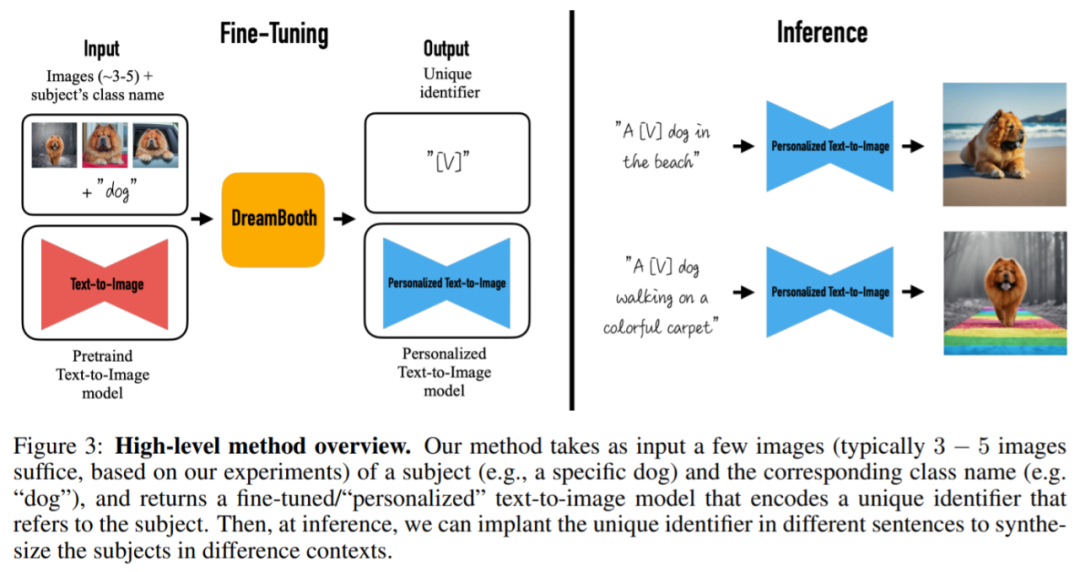
該研究的目標(biāo)是擴展模型的語言 - 視覺字典,使其將新詞匯與用戶想要生成的特定主題綁定。一旦新字典嵌入到模型中,它就可以使用這些詞來合成特定主題的新穎逼真的圖像,同時在不同的場景中進(jìn)行情境化,保留關(guān)鍵識別特征,效果如下圖 1 所示。

具體來說,該研究將給定主題的圖像植入模型的輸出域,以便可以使用唯一標(biāo)識符對其進(jìn)行合成。為此,該研究提出了一種用稀有 token 標(biāo)識符表示給定主題的方法,并微調(diào)了一個預(yù)訓(xùn)練的、基于擴散的文本到圖像框架,該框架分兩步運行;從文本生成低分辨率圖像,然后應(yīng)用超分辨率(SR)擴散模型。
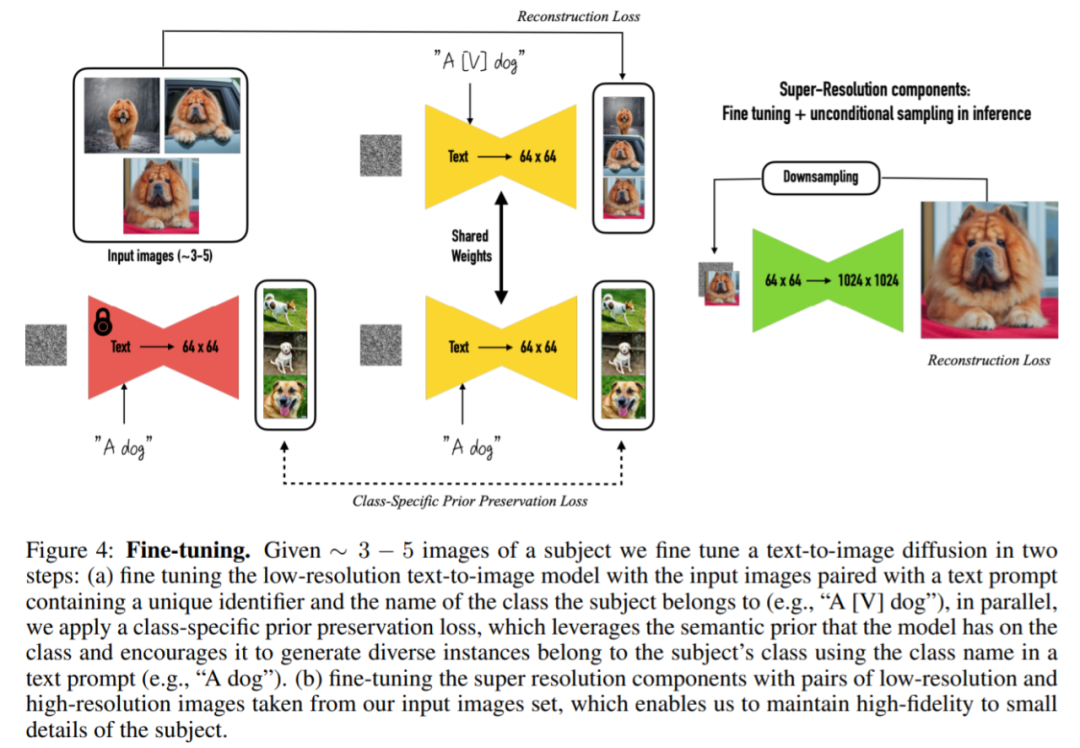
首先該研究使用包含唯一標(biāo)識符(帶有主題類名,例如「A [V] dog」)的輸入圖像和文本提示微調(diào)低分辨率文本到圖像模型。為了防止模型將類名與特定實例過擬合和語義漂移,該研究提出了一種自生的、特定于類的先驗保存(preservation)損失,它利用嵌入模型中類的先驗語義,鼓勵模型生成給定主題下同一類中的不同實例。
第二步,該研究使用輸入圖像的低分辨率和高分辨率版本對超分辨率組件進(jìn)行微調(diào)。這允許模型對場景主題中小而重要細(xì)節(jié)保持高保真度。
我們來看一下該研究提出的具體方法。
方法介紹
給定 3-5 張捕獲的圖像,這些圖像沒有文字描述,本文旨在生成具有高細(xì)節(jié)保真度和由文本提示引導(dǎo)變化的新圖像。該研究不對輸入圖像施加任何限制,并且主題圖像可以具有不同的上下文。方法如圖 3 所示。輸出圖像可對原始圖像進(jìn)行修改,如主題的位置,更改主題的屬性如顏色、形狀,并可以修改主體的姿勢、表情、材質(zhì)以及其他語義修改。
更具體的說,本文方法將一個主題(例如,一只特定的狗)和相應(yīng)類名(例如,狗類別)的一些圖像(通常 3 - 5 張圖)作為輸入,并返回一個經(jīng)過微調(diào) / 個性化的文本到圖像模型,該模型編碼了一個引用主題的唯一標(biāo)識符。然后,在推理時,可以在不同的句子中植入唯一標(biāo)識符來合成不同語境中的主題。
該研究的第一個任務(wù)是將主題實例植入到模型的輸出域,并將主題與唯一標(biāo)識符綁定。該研究提出了設(shè)計標(biāo)識符的方法,此外還設(shè)計了一種監(jiān)督模型微調(diào)過程的新方法。
為了解決圖像過擬合以及語言漂移問題,該研究還提出了一種損失( Prior-Preservation Loss ),通過鼓勵擴散模型不斷生成與主題相同的類的不同實例,從而減輕模型過擬合、語言漂移等問題。
為了保留圖像細(xì)節(jié),該研究發(fā)現(xiàn)應(yīng)該對模型的超分辨率(SR)組件進(jìn)行微調(diào),本文在經(jīng)過預(yù)訓(xùn)練的 Imagen 模型的基礎(chǔ)上來完成。具體過程如圖 4 所示,給定同一主題的 3-5 張圖像,之后通過兩個步驟微調(diào)文本到圖像的擴散模型:
稀有 token 標(biāo)識符表示主題
該研究將主題的所有輸入圖像標(biāo)記為「a [identifier] [class noun]」,其中 [identifier] 是鏈接到主題的唯一標(biāo)識符,而 [class noun] 是主題的粗略類別描述符 (例如貓、狗、手表等)。該研究在句子中特別使用了類描述符,以便將類的先驗與主題聯(lián)系起來。
效果展示
下面是 Dreambooth 一個穩(wěn)定擴散的實現(xiàn)(參考項目鏈接)。定性結(jié)果:訓(xùn)練圖像來自「Textual Inversion」庫:

訓(xùn)練完成后,在「photo of a sks container」提示下,模型生成的集裝箱照片如下:

在提示中加個位置「photo of a sks container on the beach」,集裝箱出現(xiàn)在沙灘上;

綠色的集裝箱顏色太單一了,想加點紅色,輸入提示「photo of a red sks container」就能搞定:

輸入提示「a dog on top of sks container」就能讓小狗坐在箱子里:

下面是論文中展示的一些結(jié)果。生成不同畫家風(fēng)格的關(guān)于狗狗的藝術(shù)圖:

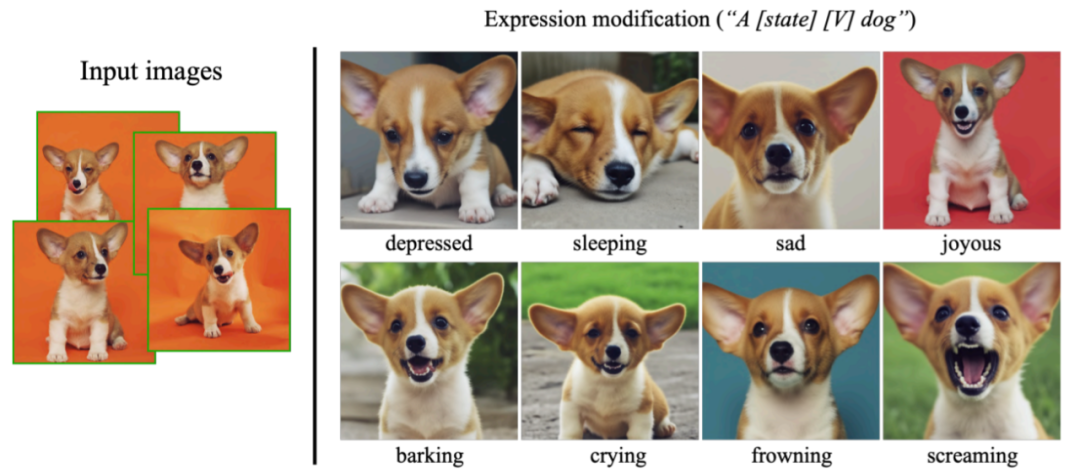
該研究還可以合成輸入圖像中沒有出現(xiàn)的各種表情,展示了模型的外推能力:
審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41374 -
模型
+關(guān)注
關(guān)注
1文章
3527瀏覽量
50498
原文標(biāo)題:谷歌提出DreamBooth:新擴散模型!只需3張圖一句話,AI就能定制照片級圖像!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
利用API提升電商用戶體驗:個性化推薦系統(tǒng)

2025年電商API發(fā)展趨勢:智能化與個性化
無法使用OpenVINO?在 GPU 設(shè)備上運行穩(wěn)定擴散文本到圖像的原因?
EM儲能網(wǎng)關(guān) ZWS智慧儲能云應(yīng)用(13) — 企業(yè)個性化配置

個性化醫(yī)療的挑戰(zhàn),微流液體監(jiān)測

Melexis LED驅(qū)動方案助力汽車制造商打造個性化車內(nèi)空間
電梯按需維保:個性化定制的電梯維護方案

【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術(shù)解讀
ComplexHeatmap包:個性化熱圖繪制利器
語音芯片賦能可穿戴設(shè)備:開啟個性化音頻新體驗
智慧路燈照明管理系統(tǒng),呈現(xiàn)個性化城市照明效果

擴散模型的理論基礎(chǔ)







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論