


簡 介:據《福布斯》報道,每天大約會有 250 萬字節的數據被產生。然后,可以使用數據科學和機器學習技術對這些數據進行分析,以便提供分析和作出預測。盡管在大多數情況下,在開始任何統計分析之前,需要先對最初收集的數據進行預處理。有許多不同的原因導致需要進行預處理分析,例如:
收集的數據格式不對(如 SQL 數據庫、JSON、CSV 等)
缺失值和異常值
標準化
減少數據集中存在的固有噪聲(部分存儲數據可能已損壞)
數據集中的某些功能可能無法收集任何信息以供分析
在本文中,我將介紹如何使用 python 減少 kaggle Mushroom Classification 數據集中的特性數量。本文中使用的所有代碼在?kaggle 和我的?github 帳號上都有。減少統計分析期間要使用的特征的數量可能會帶來一些好處,例如:
提高精度
降低過擬合風險
加快訓練速度
改進數據可視化
增加我們模型的可解釋性
事實上,統計上證明,當執行機器學習任務時,存在針對每個特定任務應該使用的最佳數量的特征(圖 1)。如果添加的特征比必要的特征多,那么我們的模型性能將下降(因為添加了噪聲)。真正的挑戰是找出哪些特征是最佳的使用特征(這實際上取決于我們提供的數據量和我們正在努力實現的任務的復雜性)。這就是特征選擇技術能夠幫到我們的地方!
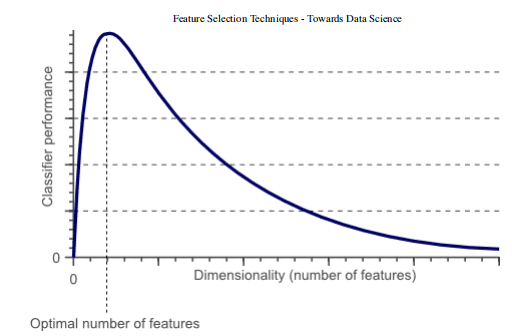
圖 1:分類器性能和維度之間的關系特征選擇 有許多不同的方法可用于特征選擇。其中最重要的是:1.過濾方法=過濾我們的數據集,只取包含所有相關特征的子集(例如,使用 Pearson 相關的相關矩陣)。2.遵循過濾方法的相同目標,但使用機器學習模型作為其評估標準(例如,向前/向后/雙向/遞歸特征消除)。我們將一些特征輸入機器學習模型,評估它們的性能,然后決定是否添加或刪除特征以提高精度。因此,這種方法可以比濾波更精確,但計算成本更高。3.嵌入方法。與過濾方法一樣,嵌入方法也使用機器學習模型。這兩種方法的區別在于,嵌入的方法檢查 ML 模型的不同訓練迭代,然后根據每個特征對 ML 模型訓練的貢獻程度對每個特征的重要性進行排序。
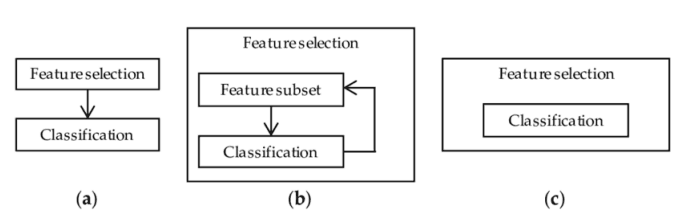
圖 2:過濾器、包裝器和嵌入式方法表示 [3]實踐 在本文中,我將使用 Mushroom Classification 數據集,通過查看給定的特征來嘗試預測蘑菇是否有毒。在這樣做的同時,我們將嘗試不同的特征消除技術,看看它們會如何影響訓練時間和模型整體的精度。首先,我們需要導入所有必需的庫。


X = df.drop(['class'], axis = 1)
Y = df['class']
X = pd.get_dummies(X, prefix_sep='_')
Y = LabelEncoder().fit_transform(Y)
X2 = StandardScaler().fit_transform(X)
X_Train, X_Test, Y_Train, Y_Test = train_test_split(X2, Y, test_size = 0.30, 特征重要性
基于集合的決策樹模型(如隨機森林)可以用來對不同特征的重要性進行排序。了解我們的模型最重要的特征對于理解我們的模型如何做出預測(使其更易于解釋)是至關重要的。同時,我們可以去掉那些對我們的模型沒有任何好處的特征。
start = time.process_time()
trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train,Y_Train)
print(time.process_time() - start)
predictionforest = trainedforest.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
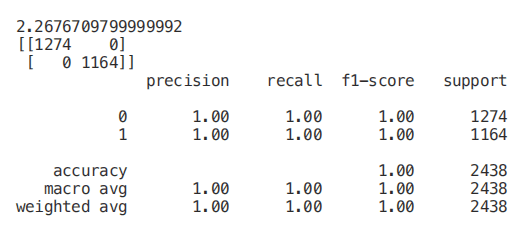
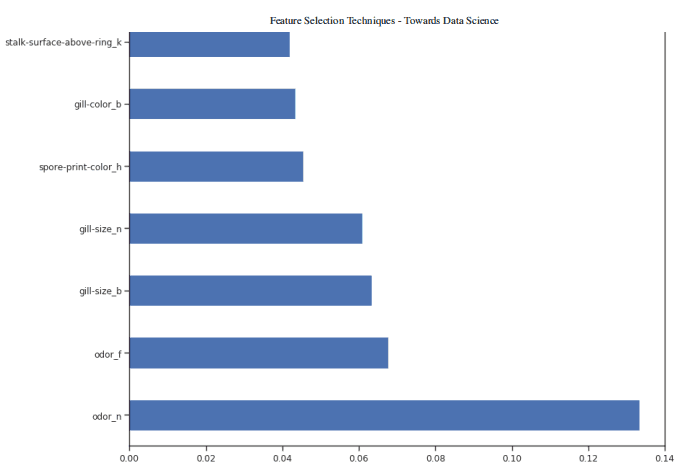
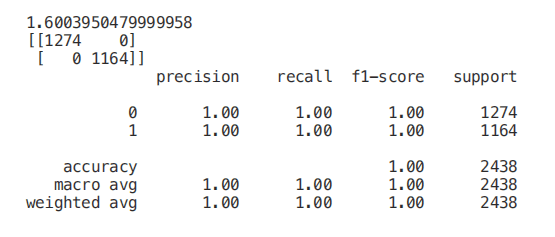
一旦我們的隨機森林分類器得到訓練,我們就可以創建一個特征重要性圖,看看哪些特征對我們的模型預測來說是最重要的(圖 4)。在本例中,下面只顯示了前 7 個特性。
figure(num=None, figsize=(20, 22), dpi=80, facecolor='w', edgecolor='k')
feat_importances = pd.Series(trainedforest.feature_importances_, index= X.columns)
feat_importances.nlargest(7).plot(kind='barh')
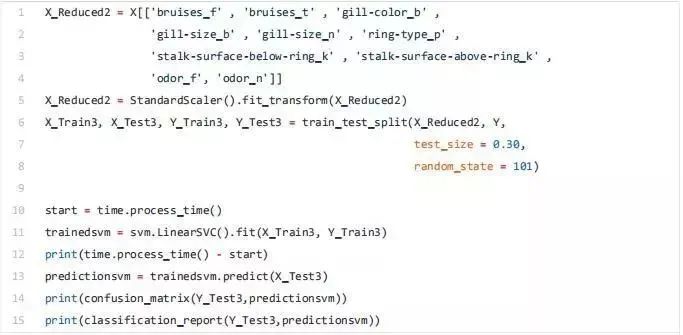
X_Reduced = X[['odor_n','odor_f', 'gill-size_n','gill-size_b']]
X_Reduced = StandardScaler().fit_transform(X_Reduced)
X_Train2, X_Test2, Y_Train2, Y_Test2 = train_test_split(X_Reduced, Y, test_size = 0.30, random_state = 101)
start = time.process_time()
trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train2,Y_Train2)
print(time.process_time() - start)
predictionforest = trainedforest.predict(X_Test2)
print(confusion_matrix(Y_Test2,predictionforest))
print(classification_report(Y_Test2,predictionforest))
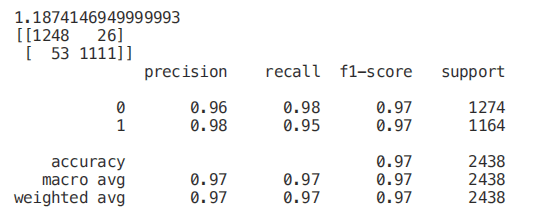
start = time.process_time()
trainedtree = tree.DecisionTreeClassifier().fit(X_Train, Y_Train)
print(time.process_time() - start)
predictionstree = trainedtree.predict(X_Test)
print(confusion_matrix(Y_Test,predictionstree))
print(classification_report(Y_Test,predictionstree))
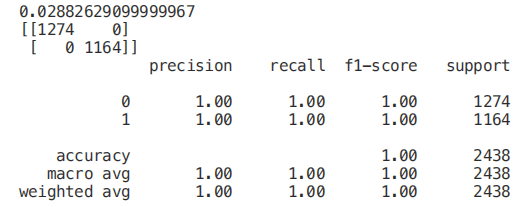
import graphviz
from sklearn.tree import DecisionTreeClassifier, export_graphviz
data = export_graphviz(trainedtree,out_file=None,feature_names= X.columns,
class_names=['edible', 'poisonous'],
filled=True, rounded=True,
max_depth=2,
special_characters=True)
graph = graphviz.Source(data)
graph
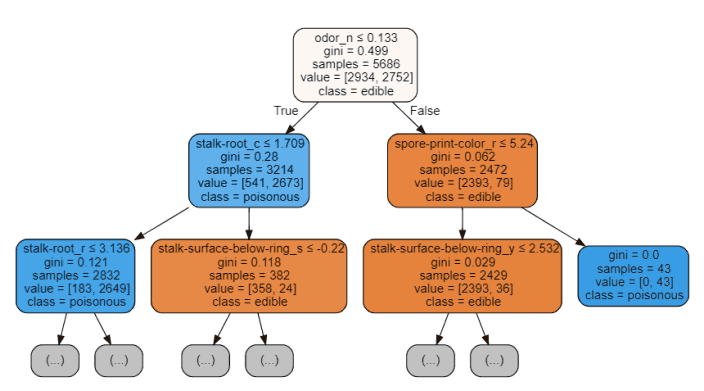
圖 5:決策樹可視化
遞歸特征消除(RFE)
遞歸特征消除(RFE)將機器學習模型的實例和要使用的最終期望特征數作為輸入。然后,它遞歸地減少要使用的特征的數量,采用的方法是使用機器學習模型精度作為度量對它們進行排序。創建一個 for 循環,其中輸入特征的數量是我們的變量,這樣就可以通過跟蹤在每個循環迭代中注冊的精度,找出我們的模型所需的最佳特征數量。使用 RFE 支持方法,我們可以找出被評估為最重要的特征的名稱(rfe.support 返回一個布爾列表,其中 true 表示一個特征被視為重要,false 表示一個特征不重要)。
from sklearn.feature_selection import RFE
model = RandomForestClassifier(n_estimators=700)
rfe = RFE(model, 4)
start = time.process_time()
RFE_X_Train = rfe.fit_transform(X_Train,Y_Train)
RFE_X_Test = rfe.transform(X_Test)
rfe = rfe.fit(RFE_X_Train,Y_Train)
print(time.process_time() - start)
print("Overall Accuracy using RFE: ", rfe.score(RFE_X_Test,Y_Test))
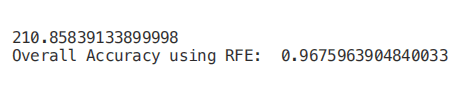
SelecFromModel
selectfrommodel 是另一種 scikit 學習方法,可用于特征選擇。此方法可用于具有 coef 或 feature 重要性屬性的所有不同類型的 scikit 學習模型(擬合后)。與 rfe 相比,selectfrommodel 是一個不太可靠的解決方案。實際上,selectfrommodel 只是根據計算出的閾值(不涉及優化迭代過程)刪除不太重要的特性。為了測試 selectfrommodel 的有效性,我決定在這個例子中使用一個 ExtraTreesClassifier。ExtratreesClassifier(極端隨機樹)是基于樹的集成分類器,與隨機森林方法相比,它可以產生更少的方差(因此減少了過擬合的風險)。隨機森林和極隨機樹的主要區別在于極隨機樹中節點的采樣不需要替換。
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectFromModel
model = ExtraTreesClassifier()
start = time.process_time()
model = model.fit(X_Train,Y_Train)
model = SelectFromModel(model, prefit=True)
print(time.process_time() - start)
Selected_X = model.transform(X_Train)
start = time.process_time()
trainedforest = RandomForestClassifier(n_estimators=700).fit(Selected_X, Y_Train)
print(time.process_time() - start)
Selected_X_Test = model.transform(X_Test)
predictionforest = trainedforest.predict(Selected_X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
-
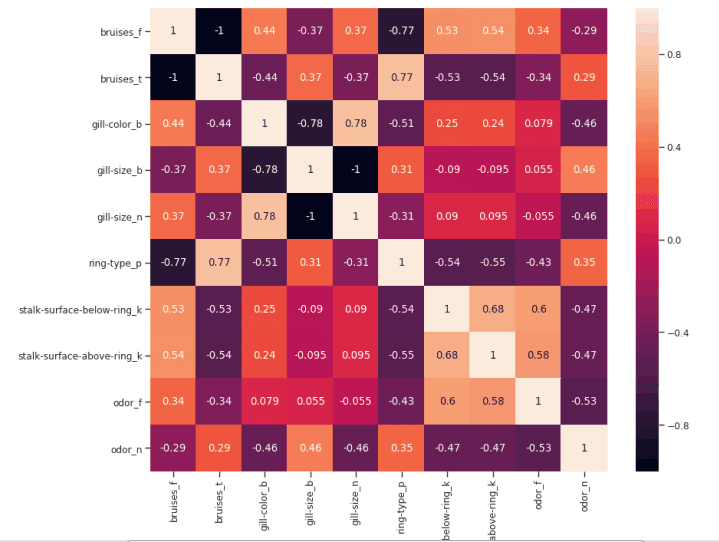
如果兩個特征之間的相關性為 0,則意味著更改這兩個特征中的任何一個都不會影響另一個。
-
如果兩個特征之間的相關性大于 0,這意味著增加一個特征中的值也會增加另一個特征中的值(相關系數越接近 1,兩個不同特征之間的這種聯系就越強)。
-
如果兩個特征之間的相關性小于 0,這意味著增加一個特征中的值將使減少另一個特征中的值(相關性系數越接近-1,兩個不同特征之間的這種關系將越強)。
Numeric_df = pd.DataFrame(X)
Numeric_df['Y'] = Y
corr= Numeric_df.corr()
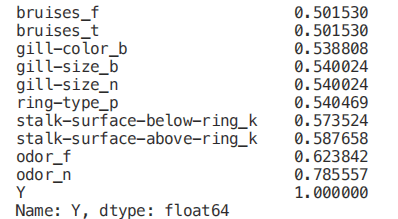
corr_y = abs(corr["Y"])
highest_corr = corr_y[corr_y >0.5]
highest_corr.sort_values(ascending=True)
figure(num=None, figsize=(12, 10), dpi=80, facecolor='w', edgecolor='k')
corr2 = Numeric_df[['bruises_f' , 'bruises_t' , 'gill-color_b' , 'gill-size_b' , 'gill-size_n' , 'ring-type_p' , 'stalk-surface-below-ring_k' , 'stalk-surface-above-ring_k' , 'odor_f', 'odor_n']].corr()
sns.heatmap(corr2, annot=True, fmt=".2g")

單變量選擇單變量特征選擇是一種統計方法,用于選擇與我們對應標簽關系最密切的特征。使用 selectkbest 方法,我們可以決定使用哪些指標來評估我們的特征,以及我們希望保留的 k 個最佳特征的數量。根據我們的需要,提供不同類型的評分函數:
-
Classification = chi2, f_classif, mutual_info_classif
-
Regression = f_regression, mutual_info_regression
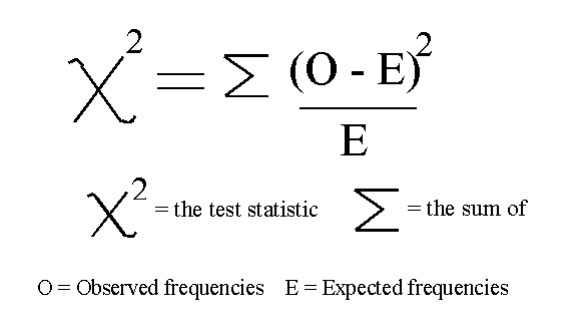
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
min_max_scaler = preprocessing.MinMaxScaler()
Scaled_X = min_max_scaler.fit_transform(X2)
X_new = SelectKBest(chi2, k=2).fit_transform(Scaled_X, Y)
X_Train3, X_Test3, Y_Train3, Y_Test3 = train_test_split(X_new, Y, test_size = 0.30, random_state = 101)
start = time.process_time()
trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train3,Y_Train3)
print(time.process_time() - start)
predictionforest = trainedforest.predict(X_Test3)
print(confusion_matrix(Y_Test3,predictionforest))
print(classification_report(Y_Test3,predictionforest))
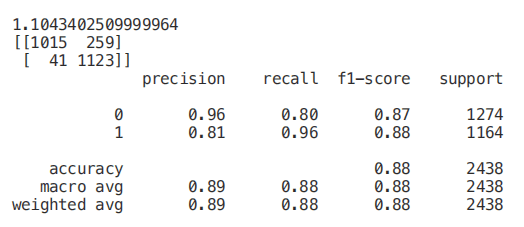
from sklearn.linear_model import LassoCV
regr = LassoCV(cv=5, random_state=101)
regr.fit(X_Train,Y_Train)
print("LassoCV Best Alpha Scored: ", regr.alpha_)
print("LassoCV Model Accuracy: ", regr.score(X_Test, Y_Test))
model_coef = pd.Series(regr.coef_, index = list(X.columns[:-1]))
print("Variables Eliminated: ", str(sum(model_coef == 0)))
print("Variables Kept: ", str(sum(model_coef != 0)))

figure(num=None, figsize=(12, 10), dpi=80, facecolor='w', edgecolor='k')
top_coef = model_coef.sort_values()
top_coef[top_coef != 0].plot(kind = "barh")
plt.title("Most Important Features Identified using Lasso (!0)")
-
python
+關注
關注
56文章
4828瀏覽量
86999 -
數據集
+關注
關注
4文章
1224瀏覽量
25486
原文標題:收藏 | 機器學習特征選擇方法總結
文章出處:【微信號:機器視覺沙龍,微信公眾號:機器視覺沙龍】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
工業設備數據集中監控可視化管理平臺是什么
Python Connector for InterBase連接解決方案
使用Python實現xgboost教程
適用于MySQL和MariaDB的Python連接器:可靠的MySQL數據連接器和數據庫
適用于Oracle的Python連接器:可訪問托管以及非托管的數據庫
CAN通信節點多時,如何減少寄生電容和保障節點數量?

請問使用AFE4400SPO2EVM測試完之后,GUI里面的數據如何作為原始數據導入到python操作界面里呢?
在沖壓機數據采集中,運用了深控技術“不需要點表的工業網關”等如何確保數據的準確性和實時性?

設計帶ADC電路時,如何用模擬地與數字地進行分割來減少數字地對模擬地的影響?
使用Python進行串口通信的案例
樓宇集中控制照明系統
對比Python與Java編程語言
怎么判斷需要集中補償還是分組補償






 工商網監
工商網監

評論