

摘要
基于圖像的3D目標檢測是自動駕駛領域的一個基本問題,也是一個具有挑戰性的問題,近年來受到了業界和學術界越來越多的關注。得益于深度學習技術的快速發展,基于圖像的3D檢測取得了顯著的進展。特別是,從2015年到2021年,已經有超過200篇研究這個問題的著作,涵蓋了廣泛的理論、算法和應用。
然而,到目前為止,還沒有一個調查來收集和組織這方面的知識。本文首次對這一新興的不斷發展的研究領域進行了全面綜述,總結了基于圖像的3D檢測最常用的流程,并對其各個組成部分進行了深入分析。此外,作者還提出了兩個新的分類法,將最先進的方法組織成不同的類別,以期提供更多的現有方法的系統綜述,并促進與未來作品的公平比較。
在回顧迄今為止所取得的成就的同時,作者也分析了當前在該領域的挑戰,并討論了基于圖像的3D目標檢測的未來發展方向。
簡介
自動駕駛有可能從根本上改變人們的生活,提高機動性,減少旅行時間、能源消耗和排放。因此,毫不奇怪,在過去的十年里,研究和工業界都在努力開發自動駕駛汽車。作為自動駕駛的關鍵技術之一,3D 目標檢測已經受到了很多關注。
特別是,最近,基于深度學習的3D 目標檢測方法越來越受歡迎。根據輸入數據是圖像還是LiDAR信號(通常表示為點云) ,現有的3D目標檢測方法可以大致分為兩類。與基于激光雷達的方法相比,僅從圖像中估計3D邊界框的方法面臨著更大的挑戰,因為從2D輸入數據中恢復3D信息是一個不適定的問題。
然而,盡管存在這種固有的困難,在過去的六年中,基于圖像的3D目標檢測方法在計算機視覺(CV)領域得到了迅速發展。在這個領域的頂級會議和期刊上已經發表了超過80篇論文,在檢測準確性和推理速度方面取得了一些突破。
在本文中,作者首次全面和結構化地綜述了基于深度學習技術的基于圖像的3D目標檢測的最新進展。特別地,本調研總結了該領域以前的研究工作,從開拓性的方法,再到最新的方法。
本文的主要貢獻可以歸納如下:
據作者所知,這是第一個基于圖像的自動駕駛3D檢測方法的綜述研究工作。本文回顧了80多種基于圖像的3D 檢測器和200多種相關的研究工作。
作者對這個問題的關鍵方面進行了全面的回顧和深入的分析,包括數據集、評估指標、檢測流程和技術細節。
作者提出了兩種新的分類方法,目的是幫助讀者更容易地獲得這個新的和不斷發展的研究領域的知識。
作者總結了基于圖像的3D 檢測的主要問題和未來的挑戰,概述了一些潛在的研究方向。
任務
給定 RGB 圖像和相應的相機參數,基于圖像的3D目標檢測的目標是對感興趣的目標進行分類和定位。每個目標都由其類別和3D世界空間中的邊界框表示。
一般來說,3D邊界框是通過它的位置[ x,y,z ] ,尺寸[ h,w,l ]和方向[ θ,φ,ψ ]相對于一個預定義的參考坐標系(例如記錄數據的自車)來參數化的。在絕大多數自動駕駛情況下,只考慮繞Y軸的航向角θ (偏航角)。下圖在2D圖像平面和鳥瞰圖上顯示了一個示例結果。
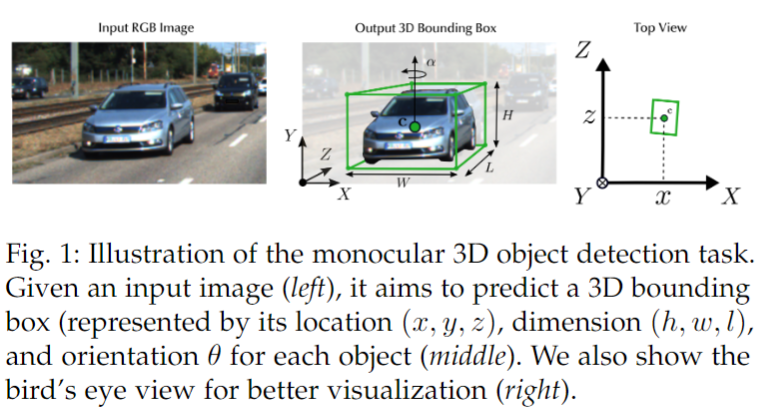
雖然基于圖像的3D 目標檢測的一般問題可以如上所述,但值得一提的是:
除了類別和3D 邊界框之外,一些基準還需要額外的預測,例如 KITTI 數據集的2D 邊界框[5]和 nuScenes 數據集的速度/屬性[6]。
雖然最初只提供圖像和相機參數,但輔助數據(如多目,CAD模型,激光雷達信號等)的采用在這個領域是常見的。
數據集和評估
數據集
常用數據集見下表:
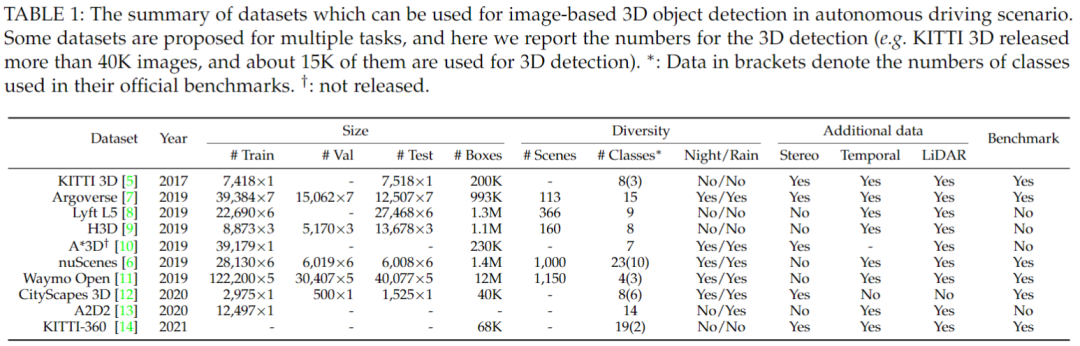
在這些數據集中,KITTI 3D [5]、nuScenes [6]和Waymo Open[11]是最常用的,極大地推動了3D檢測的發展。
在過去十年的大部分時間里,KITTI 3D 是唯一支持開發基于圖像的 3D 檢測器的數據集。KITTI 3D 提供分辨率為 1280×384 像素的前視圖像。2019 年引入了 nuScenes 和 Waymo Open數據集。
在 nuScenes 數據集中,六個攝像頭用于生成分辨率為 1600×900 像素的 360°視圖。同樣,Waymo Open 也使用 5 個同步攝像頭進行 360°全景拍攝,圖像分辨率為 1920×1280 像素。
KITTI 3D 數據集
是在德國卡爾斯魯厄的白天和良好的天氣條件下捕獲的。它主要評估三個類別(汽車、行人和自行車)的目標,根據2D框的高度、遮擋和截斷將它們分為三個難度級別。提供7481張訓練圖和7518張測試圖。
nuScenes 數據集
包含在波士頓和新加坡拍攝的 1000 個 20 年代的場景。與 KITTI 3D 基準測試不同的是,這些場景是在一天中的不同時間(包括夜晚)和不同的天氣條件下(例如雨天)捕獲的。3D 檢測任務有十個類別的目標,nuScenes 還為每個類別標注屬性標簽,例如汽車的移動或靜止,有或沒有騎手的自行車。
這些屬性可以看作是一個細粒度的類標簽,并且在nuScenes benchmark中也考慮了屬性識別的準確性。其分別提供28130幀、6019幀、6008幀用于訓練、驗證和測試(每幀6張圖)。
Waymo Open 數據集
涵蓋了 1150 個場景,分別在鳳凰城、山景城和舊金山在多種天氣條件下(包括夜間和雨天)拍攝。與 KITTI 3D 類似,Waymo Open 也根據每個 3D 邊界框中包含的 LiDAR 點的數量為 3D 檢測任務定義了兩個難度級別。其基準中感興趣的目標包括車輛、行人和騎自行車的人。其提供122200幀用于訓練、30407幀用于驗證、40077幀用于測試(每幀有5張圖)。
評估指標
與 2D 目標檢測相同,平均精度 (AP)構成了 3D目標檢測中使用的主要評估指標。從其原始定義開始,每個數據集都應用了特定的修改,從而產生了特定于數據集的評估指標。
在這里,作者首先回顧一下原始的 AP 指標,然后介紹其在最常用的基準測試中采用的變體,包括 KITTI3D、nuScenes 和 Waymo Open。
AP指標回顧
最常用的一種方法,即真值 A 與預測的3D 邊界框 B 之間的交并比(IoU) ,定義為: IoU (A,B) = | A ∩ B | /| A ∪ B | 。
將匹配的IoU與一定的閾值進行比較,用來判斷一個匹配預測是真正例(TP)還是假正例(FP)。然后,根據公式:r = TP/(TP + FN),p = TP/(TP + FP),其中 FN 表示假反例,可以從排序(通過置信度)檢測結果計算召回和精度。精度可以看作是召回的函數,即 p (r)。此外,為了減少“擺動”對精度-召回曲線的影響,使用插值精度值計算 AP ,公式如下:
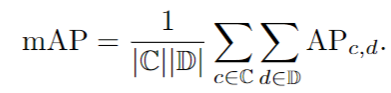
其中 R是預定義的召回位置集和 pinterp (r)是插值函數,定義為:
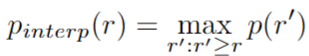
這意味著,不是在召回 r 處對實際觀察到的精度值進行平均,而是采用大于或等于 r 的召回值的最大精度。
特殊的一些指標
KITTI 3D 基準: KITTI 3D 采用 AP 作為主要指標,并引入了一些修改。第一種方法是在3D空間中進行IoU的計算。此外,KITTI 3D 采納了Simonelli等[30]的建議,將上面的傳統AP指標的 R11 = {0,1/10,2/10,3/10,... ,1}替換為 R40 = {1/40,2/40,3/40,... ,1} ,這是一個更密集的抽樣,去除了0的召回位置。
此外,由于目標的高度不像自動駕駛場景中的其他目標那么重要,鳥瞰(BEV)檢測,在一些工作中也被稱為3D 定位任務[31],[32],[33],可以被看作是3D 檢測的替代方案。
計算過程的主題,BEV AP,這項任務是相同的3D AP,但計算的 IoU 是在平面,而不是3D 空間。這個任務也包含在其他一些基準測試中,比如 Waymo Open [11]。此外,KITTI 3D 還提出了一種新的度量方法——平均方向相似度(AOS)來評估方向估計的精度。AOS 表示為:
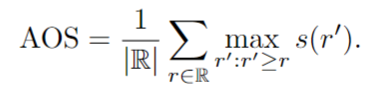
方向相似性s(r)∈[0,1]定義為:
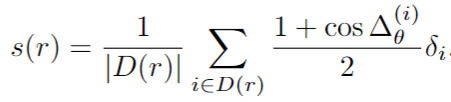
其中 D (r)表示在召回率r下的所有目標檢測結果的集合,delta(i) θ 是檢測的估計值和真值方向之間的角度差。為了懲罰對單個目標的多次檢測,KITTI 3D 強制 δi=1,如果檢測i已被分配到一個真值邊界框,如果它沒有被分配δi=0。請注意,所有 AP 指標都是針對每個難度級別和類別獨立計算的。
Waymo Open Benchmark: Waymo Open 也采用了 AP 度量標準,只做了一個小小的修改: 用 R21 = {0,1/20,2/20,3/20,... ,1}代替 傳統AP的R11。此外,考慮到精確的航向角預測對于自動駕駛至關重要,而 AP 指標沒有航向的概念,Waymo Open 進一步提出了以航向加權的 Average Precision (APH)作為其主要指標。
具體來說,APH 將航向信息整合到精度計算中。每個真正例是由定義為min (| θ-θ* | ,2π-| θ-θ* |)/π 的航向精度加權的,其中 θ 和 θ* 是預測的航向角和真值航向角,以弧度[-π,π ]為單位。值得注意的是,APH 聯合評估3D檢測和方向估計的性能,而 AOS 只是為方向估計而設計的。
nuScenes Benchmatk: nuScenes提供了一種新的AP評估方法,特別是,它與一定的距離閾值(例如2m) 內,使用平面上的2D 中心距離來匹配預測和真值,而不是直接引入IoU。此外,nuScenes 計算 AP 作為精確召回曲線下的歸一化區域,其召回率和精確度均在10% 以上。最后,計算了匹配閾值 D = {0.5,1,2,4} m 和類集 C:
然而,這個度量標準只考慮了目標的定位,而忽略了其他方面的影響,比如維度和方向。為了彌補這一缺陷,nuScenes 還提出了一組TP 指標 ,用于分別使用所有真正例(在匹配過程中確定的中心距離 = 2m)來測量每個預測誤差。所有五個 TP 指標都被設計為真正例,定義如下 :
平均平移誤差(ATE)是2D平面上目標中心的歐氏距離(米為單位)。
平均尺度誤差(ASE)是方向和平移對齊后的3D IoU 誤差(1-IoU)。
平均方向誤差(AOE)是預測值和真值之間最小的偏航角差(以弧度為單位)。
平均速度誤差(AVE)是作為2D(以 m/s 為單位)速度差的 L2范數的絕對速度誤差。
平均屬性錯誤(AAE)定義為1減屬性分類精度(1-acc)。
此外,對于每個 TP 度量,nuScenes 還計算所有目標類別的平均 TP 度量(mTP) :
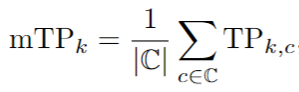
其中 TPk 表示分類 c 的第k個TP 度量(例如 k = 1表示 ATE)。最后,為了將所有提到的指標集成到一個標量得分中,nuScenes 進一步提出了 nuScenes 檢測得分(NDS) ,它結合了nuScenes 中定義的 mAP 和nuScenes 中定義的 mTPk:
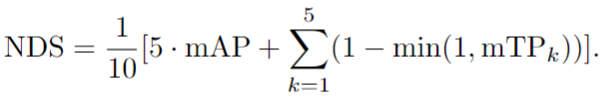
框架
分類
作者將現有的基于圖像的3D檢測器分為兩類:
基于2D特征的方法。這些方法首先從2D特征中估計圖像平面中目標的2D位置(以及其他項目,如方向、深度等) ,然后將2D檢測提升到3D空間中。
在此基礎上,這些方法也可以稱為“基于結果提升的方法”。此外,由于這些方法通常與2D檢測模型具有相似的結構,因此可以通過2D檢測中常用的分類法(即基于區域的方法和單目方法)進一步對它們進行分類。
基于3D特征的方法。這些方法基于3D特征對目標進行預測,從而可以直接在3D空間中對目標進行定位。此外,根據如何獲得3D 特征,這些方法可以進一步分為“基于特征提升的方法”和“基于數據提升的方法”。顧名思義,前者通過提升2D特征來獲得3D特征,而后者直接從2D圖像轉換的3D數據中提取3D特征。
主流的一些基于圖像的3D目標檢測方法如下圖所示:
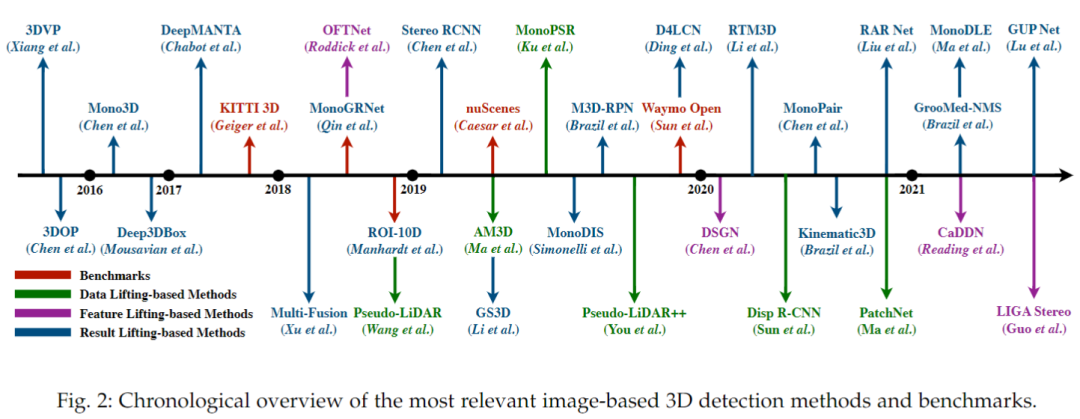
基于2D特征的方法
第一類是“基于2D特征的方法”。給定輸入圖像,他們首先從2D 特征中估計2D 位置,方向和尺寸,然后從這些結果(和其他一些中間結果)恢復3D 位置。因此,這些方法也可以稱為“基于結果提升的方法”。為了得到目標的3D位置[ x,y,z ] ,一個直觀且常用的解決方案是使用 CNN 估計深度值,然后使用以下映射關系:
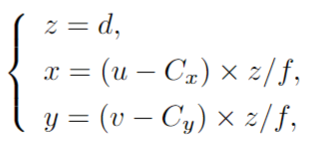
將2D投影提升到3D空間,其中(Cx,Cy)是中心點,f是焦距,(u,v)是目標的2D位置。還要注意的是,這些方法只需要目標中心的深度,這與需要密集深度圖的方法不同,例如偽激光雷達[34]。此外,由于這些方法在總體框架上類似于2D檢測器,為了更好地表示,作者將它們進一步分為兩個子類: 基于區域的方法和單目方法。
基于區域的方法
基于區域的方法遵循在2D目標檢測中R-CNN 系列的思想[35],[36],[37]。在這個框架中,從輸入圖像生成獨立于類別的區域proposal后,通過 CNN 從這些區域提取特征[37] ,[38]。最后,R-CNN 使用這些特性來進一步完善proposal,并確定他們的類別標簽。本文總結了基于區域的3D圖像檢測框架的新設計。
生成proposal: 與2D檢測領域中常用的proposal生成方法[39],[40]不同,生成3D檢測proposal的簡單方法是在地面平面上平鋪3D anchor(proposal的形狀模板) ,然后將它們投影到圖像平面上作為proposal。然而,這種設計通常會導致巨大的計算開銷。
為了減少搜索空間,Chen等[2],[1],[41]提出了開創性的Mono3D 和3DOP,分別使用基于單目和多目方法的領域特定先驗(例如形狀,高度,位置分布等)去除低置信度的proposal。此外,Qin等[42]提出了另一種方案,在2D前視圖中估計一個目標置信度圖,并且在后續步驟中只考慮具有高目標置信度的潛在anchor。
總之,3DOP [1]和 Mono3D [2]使用幾何先驗計算方案的置信度,而Qin等[42]使用網絡來預測置信度圖。使用區域proposal網絡(RPN)[37] ,檢測器可以使用來自最后共享卷積層的特征而不是外部算法來生成2D proposal,這節省了大部分計算成本,并且大量基于圖像的3D 檢測器[43],[44] ,[45],[46],[30],[17],[47],[48],[49],[50],[42],[51],[52],[53],[54]采用了這種設計。
引入空間信息: Chen等[47]將 RPN 和 R-CNN 結合的設計擴展到多目3D檢測。他們提出分別從左右兩幅圖像中提取特征,并利用融合特征生成proposal,預測最終結果。這種設計允許 CNN 隱式地從多目中學習視差/深度,并被以下基于多目的3D 檢測器所采用[50],[55],[53]。同樣為了提供深度信息,Chen[45]提出了另一種方案,多融合單目3D 檢測。
具體而言,他們首先使用現成的深度估計器[56],[57]為輸入圖像生成深度圖,然后為 RGB圖和深度圖設計具有多種信息融合策略的基于區域的檢測器。值得注意的是,為單目圖像提供深度提示的策略是由幾個工作[58],[34],[33],[59],[60],[61],[62],[34],[63],[64],[65]。然而,Stereo R-CNN [47]和 Multi-Fusion [45]在高級范式中是相似的,因為它們都采用基于區域的框架并引入另一個圖像(或地圖)來提供空間線索。
Single-Shot 方法
Single-Shot 目標檢測器直接預測類概率并從每個特征位置回歸3D 框的其他屬性。因此,這些方法通常比基于區域的方法具有更快的推理速度,這在自動駕駛的情況下是至關重要的。在Single-Shot 方法中只使用 CNN 層也促進了它們在不同硬件架構上的部署。
此外,相關文獻[66],[18],[67],[21]表明,這些Single-Shot 檢測器也可以取得良好的性能。基于以上原因,近年來許多方法都采用了這一框架。目前,在基于圖像的3D檢測中有兩種Single-Shot 原型。首先是anchor-based的,由[68]提出。
特別是,這個檢測器本質上是一個定制的 RPN 單目3D 檢測,它為給定的圖像生成2D anchor和3D anchor。與類別無關的2D anchor不同,3D anchor的形狀通常與其語義標簽有很強的相關性,例如,形狀為“1.5 m × 1.6 m × 3.5 m”的anchor通常是小汽車而不是行人。
因此,這種3D RPN 可以作為Single-Shot 的3D檢測器,并已被多種方法采用[60],[69],[70],[61]。此外,在2019年,Zhou等[18]提出了一個名為 CenterNet 的anchor-free Single-Shot 檢測器,并將其擴展到基于圖像的3D檢測。特別地,這個框架將目標編碼為一個單點(目標的中心點) ,并使用關鍵點估計來找到它。
此外,幾個平行的head被用來估計目標的其他屬性,包括深度,尺寸,位置和方向。盡管這個檢測器在架構上看起來非常簡單,但是它在多個任務和數據集中都能達到很好的性能。后來,很多以下作品[71],[72],[73],[74],[75],[76],[77],[22],[21],[78],[79]采用了這種設計。
基于3D 特征的方法
另一個分支是“基于3D 特征的方法”。這些方法的主要特點是首先從圖像中生成3D特征,然后直接估計3D空間中包括3D位置在內的3D邊界框的所有屬性。根據如何獲得3D特征,作者進一步將這些方法分組為“基于特征提升的方法”和“基于數據提升的方法”。
基于特征提升的方法
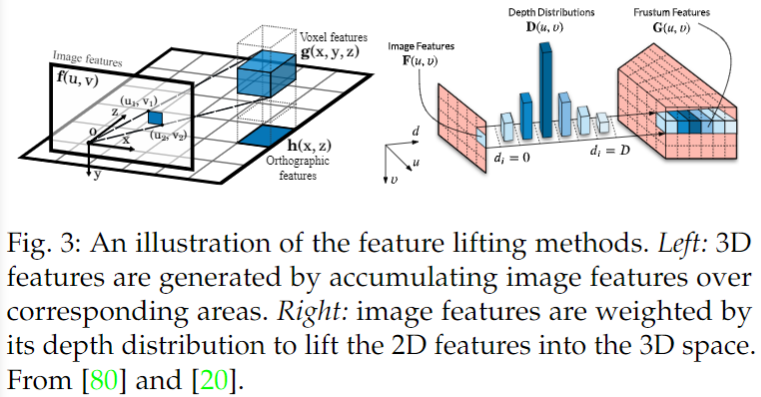
基于特征提升的方法的總體思想是將圖像坐標系中的2D圖像特征轉換為世界坐標系中的3D體素特征。此外,現有的基于特征提升的方法[80],[81],[20],[82],[83]進一步折疊沿垂直維度的3D 體素特征,對應于目標的高度,以在估計最終結果之前生成 BEV 特征。對于這類方法,關鍵問題是如何將2D圖像特征轉換為3D體素特征。
單目方法特征提升: 提出了一種基于檢索的檢測模型OFTNet 來實現特征提升。他們通過在前視圖特征區域積累對應于每個體素的左下角(u1,v2)和右下角(u2,v2)的投影的2D 特征來獲得體素特征:
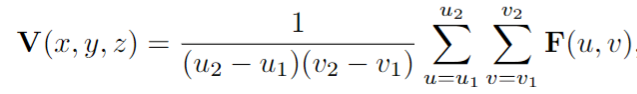
其中 V (x,y,z)和 F (u,v)表示給定體素(x,y,z)和像素(u,v)的特征。不同的是,Reading等以反向投影的方式實現特征提升[84]。
首先,將連續深度空間離散為多重空間,并將深度估計作為一個分類任務,這樣深度估計的輸出就是這些空間的分布 D,而不是單個值。然后,每個特征像素 F (u,v)通過其在 D (u,v)中的相關深度二分概率來加權,以生成3D平截頭體特征:
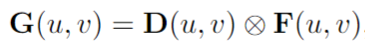
注意這個平截頭體特性是基于圖像深度坐標系(u,v,d) ,這需要使用相機參數來生成體素特征,并與3D世界坐標系(x,y,z)對齊。下圖顯示了這兩種方法。
多目方法的特征提升: 由于有了先進的立體匹配技術,從多目圖像對中構建3D 特征比從單目圖像中構建更容易實現。Chen等[81]提出了深度立體幾何網絡(DSGN) ,實現了以多目圖像為輸入的特征提升。他們首先從多目對中提取特征,然后建立4D 平面掃描體遵循經典的平面掃描方法[85] ,[86] ,[87] ,將左圖像特征和重新投影的右圖像特征以等間隔的深度值連接起來。然后,在生成用于預測最終結果的 BEV 圖之前,將這個4D 體轉換為3D 世界空間。
基于數據提升的方法
在基于數據提升的方法中,將2D 圖像轉換為3D 數據(例如點云)。然后從生成的數據中提取3D 特征。在本節中,作者首先介紹偽 LiDAR 流程,它將圖像提升到點云,以及為它設計的改進。然后介紹了基于圖像表示的提升方法和其他提升方案。
偽激光雷達流程: 得益于深度估計,視差估計和基于激光雷達的3D目標檢測,一個新的流程被提出來建立基于圖像的方法和基于激光雷達的方法之間的橋梁。在這個流程中,作者首先需要從圖像估計密度深度圖[56] [57],(或視差圖[55],[88],然后將它們轉換為深度圖[34])。然后,使用公式導出像素(u,v)的3D位置(x,y,z)。通過將所有像素反向投影到3D 坐標系中,可以生成偽 LiDAR 信號:
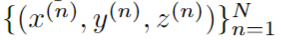
其中 N 是像素數。之后,基于 LiDAR 的檢測方法[32],[89],[90],[91]可以使用偽 LiDAR 信號作為輸入。這個流程中使用的數據表示的比較如下圖所示。
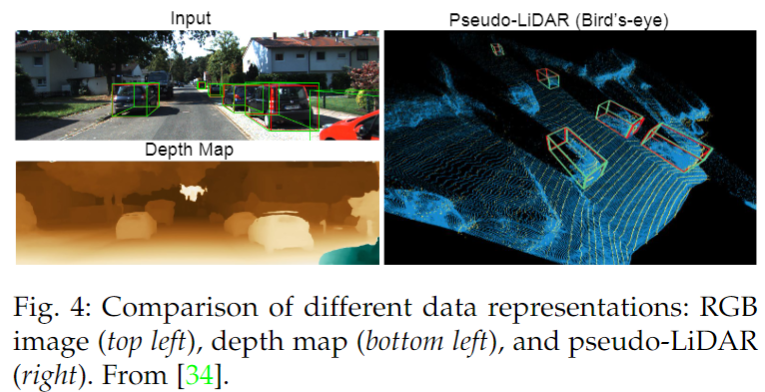
偽激光雷達流程的成功顯示了空間特征在這一任務中的重要性,突破了基于圖像的方法和基于激光雷達的方法之間的障礙,使其有可能應用到其他領域的先進技術。
提高深度圖(或由此產生的偽激光雷達信號)的質量: 理論上,基于偽激光雷達的模型的性能很大程度上取決于深度圖的質量,一些工作[34],[33],[92]通過采用不同的深度估計已經證實了這一點。除了深度估計[56],[57],[93]和立體匹配[51],[88],[92]的改進之外,還有其他一些方法可以提高深度圖的質量。注意,視差中的一個較小的誤差將導致對遠距離目標的深度誤差較大,這是基于偽激光雷達的方法的主要弱點。
為此,You等[94]提出將視差cost量轉換為深度cost量,并直接端到端學習深度,而不是通過視差轉換。Peng等[50]采用了非均勻視差量化策略來保證均勻的深度分布,這也可以減少遠距離目標的視差深度變換誤差。此外,直接提高偽激光雷達信號的精度也是一種選擇。
為此,You等[94]建議使用廉價的稀疏激光雷達(例如4波束激光雷達)來校正深度估計器的系統偏差。這些設計可以顯著提高產生的偽 LiDAR 信號的準確性,特別是對于遠距離目標。
聚焦前景目標: 原有的偽激光雷達模型估計輸入圖像的完整視差/深度映射。這種選擇引入了大量不必要的計算成本,可能會分散網絡對前景目標的注意力,因為只有對應于前景目標的像素是后續步驟的焦點。在此基礎上,提出了幾種改進方法。
具體來說,類似于基于 LiDAR 的3D 檢測器 F-PointNet [32] ,Ma等[33]使用2D 邊界框去除背景點。此外,他們還提出了一種基于動態閾值的方案來進一步去除噪聲點。與2D 邊界框相比,[59],[53],[54],[51]中的方法采用實例mask,這是一個更好的過濾器,但需要額外的數據與真值mask。
此外,Wang等[95]和 Li等[96]建議在深度估計階段解決這個問題。他們使用2D邊界框作為mask,將輸入圖像的像素分為前景和背景,并對前景像素應用更高的訓練權重。因此,前景區域的深度值比基線更準確,從而提高了3D檢測性能。請注意,像素的可信度屬于前景/背景,可以作為額外的特征來增強偽 LiDAR 點[96]。
其他信息豐富輸入數據: 如前所述,大多數基于偽激光雷達的方法只采用最終得到的偽激光雷達信號作為輸入。另一個改進方向是用其他信息豐富輸入數據。Ma等人[33]使用基于注意力的模塊將每個像素的 RGB 特征與其相應的3D 點融合。
此外,還利用 RoI 級的 RGB 特性為偽激光雷達信號提供補充信息。Pon等[53]建議使用像素級部分定位圖來增強偽 LiDAR 信號的幾何信息(類似于基于 LiDAR 的3D 檢測器[97])。特別地,他們使用 CNN 分支來預測3D邊界框中每個像素/點的相對位置,然后使用這個相對位置來豐富偽 LiDAR 信號。
端對端訓練: 基于偽激光雷達的檢測方法一般分為深度估計和3D檢測兩部分,不能進行端到端的訓練。對于這個問題,Qi等[98]提出了一個可微表示變化(CoR)模塊,允許梯度從3D檢測網絡反向傳播到深度估計網絡,整個系統可以從聯合訓練中受益。
基于圖像表示的方法: 為了探索基于偽 LiDAR 的方法成功的根本原因,Ma等[63]提出了 PatchNet,一種基于圖像表示的原始偽 LiDAR 模型的等效實現[34] ,并取得了幾乎相同的性能。這表明,數據提升是偽激光雷達系列成功的關鍵,它將圖像坐標系中的2D位置提升到世界坐標系中的3D位置,而非數據表示。
Simonelli等[16]對 PatchNet 進行了擴展,通過使用置信度head對3D 邊界框進行置信度評分,從而獲得更好的性能。大多數基于偽 LiDAR 方法的設計都可以很容易地用于基于圖像表示的方法。此外,受益于深入研究的2D CNN 設計,基于圖像的數據提升模型可能具有更大的潛力[63]。
其他提升方法: 與以前引入的通過深度估計和實現數據提升的模型不同,Srivastava等[99]引入了另一種提升數據的方法。具體而言,他們使用生成對抗網絡(GAN)[100] ,[101]將前視圖轉換為 BEV 圖,其中生成器網絡旨在生成與給定圖像對應的 BEV 圖,并且鑒別器網絡用于對生成的 BEV 圖進行分類。
此外,Kim等[102]提出使用逆透視映射將前視圖像轉換為 BEV 圖像。在獲得 BEV 圖像后,這兩個工作可以使用基于 BEV 的3D 檢測器,如 MV3D [31]或 BirdNet [103]來估計最終結果。
組件比較
本節,作者將比較3D 目標檢測器的每個必需組件。與框架級設計相比,下面的設計通常是模塊化的,可以靈活地應用于不同的算法。
特征提取
與 CV中的其他任務一樣,良好的特征表示是構建高性能基于圖像的3D 檢測器的關鍵因素。最近的大多數方法使用標準的 CNN 作為它們的特征提取器,而一些方法偏離了這一點,引入了更好的特征提取方法。
標準骨干網絡
雖然一般輸入數據只是 RGB 圖像,但基于特征提升的方法和基于數據提升的方法便于使用2D CNN [104],[105],[106],[107],[108],3D CNN [109],[110]和點式CNN [111],[112],[113]作為骨干網絡。
局部卷積
如下圖所示,Brazil an Liu [68]建議使用兩個平行的分支來分別提取空間不變特征和空間感知特征。
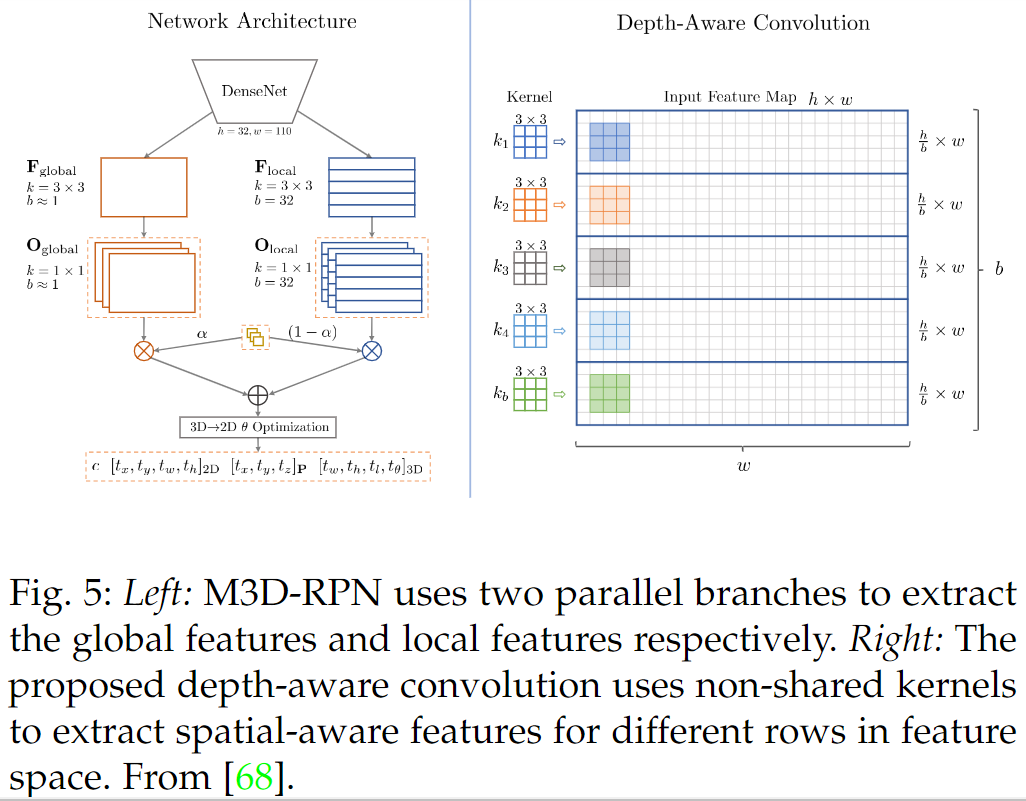
特別是,為了更好地捕捉單目圖像中的空間感知線索,他們進一步提出了一種局部卷積: 深度感知卷積。提出的操作使用非共享卷積內核來提取不同行的特征。最后,在估計最終結果之前,將空間感知特征與空間不變特征相結合。注意,非共享內核將引入額外的計算成本,并且[68]也提出了這個方案的有效實現。
特征注意力機制
自Hu等[114]將注意機制[115]引入 CNN 以來,提出了許多注意力塊[114],[116],[117]。盡管這些方法的細節各不相同,但它們通常有著相同的關鍵思想: 按照特定維度(例如,通道維度)重新加權特性。
深度增強特征學習
為了提供 RGB 圖像中不可用的深度信息,一種直觀的方案是使用深度圖(通常從現成的模型或子網絡獲得)來增強 RGB 特征[45] ,[58]。此外,還提出了一些有效的深度增強特征學習方法。尤其是,Ding等[60]提出了一種局部卷積網絡,他們使用深度圖作為指導來學習 RGB 圖像不同擴張率的動態局部卷積濾波器。
特征模擬
最近,一些方法提出在 LiDAR 模型的指導下學習基于圖像的模型的特征。特別是,Ye等[65]采用偽 LiDAR (數據提升)流程,并強制從偽 LiDAR 信號中學習的特征應與從真正的 LiDAR 信號中學習的特征相似。同樣,Guo 等[82]將該機制應用于基于特征提升的方法,并在轉換后的體素特征(或 BEV 特征)中進行特征模擬。
此外,Chong等[3]將該方案推廣到結果提升方法。它們都將所學到的知識從基于激光雷達的模型轉移到潛在特征空間中的基于圖像的模型,這些工作的成功表明基于圖像的方法可以從特征模擬中受益。
特征對齊
在3D檢測任務中只考慮了偏航角。然而,當顛簸/俯仰角度不為零時,這種設計將導致不對齊問題,下圖說明了這個問題。
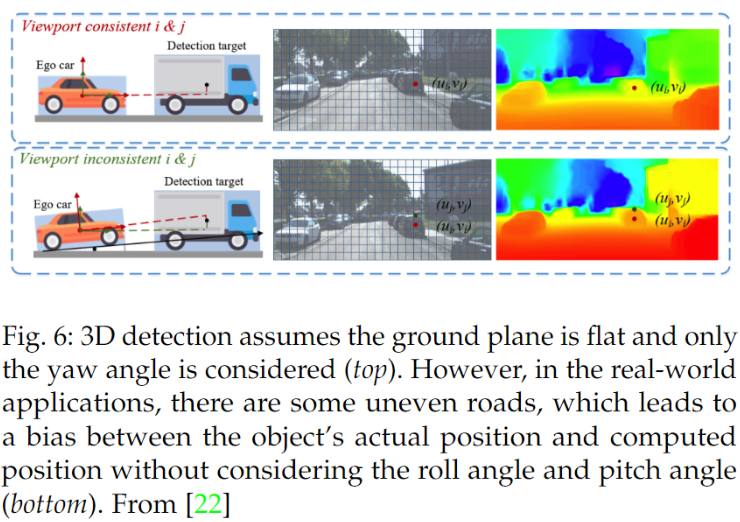
為了這個問題,Zhou等[22]提出了一種特征對齊方案。特別地,他們首先使用子網絡估計自姿態,然后設計一個特征轉移網絡,根據估計的相機姿態,在內容級別和風格級別上對齊特征。最后,他們使用校正后的特征來估計 3D 邊界框。
特征池化
Li等[118]為基于圖像的3D檢測提出了一個新的特征池化方案。如下圖所示,對于給定的3D anchor,他們從可見表面提取特征,并通過透視變換將其扭曲成規則形狀(例如7 × 7特征映射)。
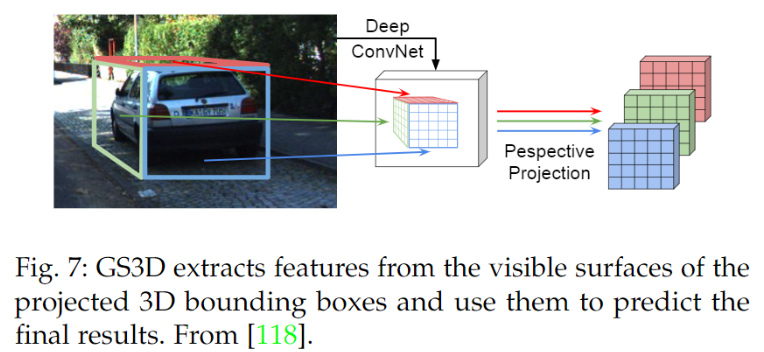
然后,將這些特征映射結合起來,用于提煉最終結果的proposal。請注意,這些特征可以通過深度 ConvNetPest 投影進一步增強。使用 RoI Pool [37]或 RoI Align [38]連接從2D anchor提取的特征。
結果預測
獲得 CNN 特征后,從提取的特征預測3D檢測結果。作者將結果預測的新穎設計分為不同的方面,并討論了這些方法。
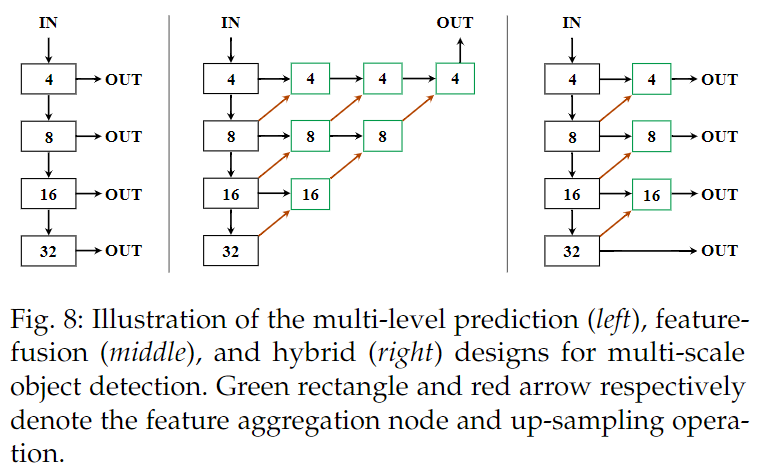
多尺度預測
基線模型是使用最后一個 CNN 層的特征來預測結果[45] ,[34] ,[63] ,[16]。然而,這個方案的主要挑戰來自于目標的不同尺度。特別是,CNN 通常分層提取特征,導致不同層次的特征有不同的感受野和語義層次。
因此,很難預測所有的目標使用特定的層特征。為了解決這個問題,人們提出了許多方法,大致分為層次方法和核級方法。比如FPN、可變形卷積等,下圖是一個例子:
分布外樣本
由于范圍、截斷、遮擋等原因,不同的目標往往具有不同的特征,從一個統一的網絡中預測同一目標可能不是最優的。基于這個問題,[63] ,[16] ,[77]采取了自組合策略。特別是,Ma等人[63]根據深度值(或 KITTI 3D 數據集定義的“難度”級別)將目標分為三個簇,并使用不同的head并行預測它們。
Simonelli等[16]擴展了這種設計,為每個head增加了一個重新評分模塊。Zhang等[77]根據目標的截斷級別將其解耦為兩種情況,并對其應用不同的標簽分配策略和損失函數。此外,Ma等[72]觀察到,一些遠距離的目標幾乎不可能準確定位,減少它們的訓練權重(或直接從訓練集中移除這些樣本)可以提高整體性能。
這種策略的潛在機制具有相同的目標[63] ,[16] ,[77] ,即避免從分布外的樣本分散到模型訓練。
深度估計的投影建模
與獨立的深度估計任務相比,3D 檢測中的深度估計有更多的幾何先驗,投影建模是最常用的一種。特別地,3D目標框的高度與其2D投影的高度之間的幾何關系可表示為:
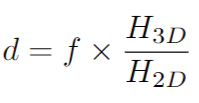
其中d和f 分別表示目標的深度和相機的焦距。2D檢測框的高度用來近似 H2D,因此他們可以使用估計的參數來計算粗略的深度。然而,當使用2D 邊界框(表示為 Hbbox2D)的高度作為 H2D時,會引入外部噪聲,因為 H2D不等于Hbbox2D。為了緩解這個問題,Luet al。[75]提出了一種基于不確定性的方案,該方案在投影建模中對幾何不確定性進行建模。
此外,Barabanau等[44]利用 CAD 模型對汽車的關鍵點進行了標注,并利用2D/3D 關鍵點的高度差來獲得深度。與之不同的是,Zhang等人[123]修正了上面的d計算公式,考慮了目標的位置、維度和方向的相互作用,并建立了3D檢測框與其2D投影之間的關系。簡而言之,GUPNet [75]捕獲了噪聲透視投影建模中的不確定性,Barabanau等[44]通過重新標記消除了噪聲,而 Zhang 等[123]通過數學建模解決了誤差。
多任務預測
作為多任務學習的3D 檢測。3D檢測可以看作是一個多任務的學習問題,因為它需要同時輸出類別標簽,位置,尺寸和方向。許多工作[131] ,[132] ,[133]已經表明,CNN 可以從多任務的聯合訓練中受益。同樣,Ma等[72]觀察到2D檢測可以作為單目3D檢測的輔助任務,并為神經網絡提供額外的幾何線索。
此外,Guo 等[82]發現這對多目3D檢測也是有效的。注意,在某些方法[68]、[30]、[34]、[33]、[63]中,2D 檢測是必需的組件,而不是輔助任務。發現額外的關鍵點估計任務可以進一步豐富 CNN 的特征,估計的關鍵點可以用來進一步優化深度估計子任務[43] ,[78] ,[74]。
此外,深度估計也可以為3D檢測模型提供有價值的線索。具體而言,許多工作[23] ,[81] ,[82] ,[3]進行了額外的深度估計任務,以指導共享的 CNN 特征來學習空間特征,Parket 等[135]表明,大規模深度估計數據集的預訓練可以顯著提高他們的3D檢測器的性能。
損失函數
損失函數是數據驅動模型不可缺少的一部分,3D 檢測的損失函數可以簡化為:
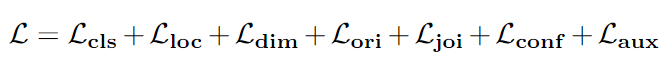
特別地,分類損失用于識別候選框的類別并給予置信度。位置損失 Lloc、維度損失 Ldim 和方向損失 Lori 分別用于回歸3D邊界框所需的項,即位置、維度和方向。最后三個損失項目是可選的。特別是,lossLjoi,例如角點損失[58] ,可以在一個單損失函數中共同優化位置、維數和方向。置信度損失 Lconf 被設計用來給檢測到的檢測框更好的置信度。最后,輔助損失可以引入額外的幾何線索到 CNN。具體的損失函數細節可詳見原文。
后處理
后處理從 CNN 獲得結果后,采用一些后處理步驟去除冗余檢測結果或改進檢測結果。這些步驟大致可以分為兩類: 非極大值抑制(NMS)和后優化。
NMS
傳統 NMS: 一般來說,原始檢測結果有多個冗余邊界框覆蓋單個目標,NMS 的設計使得單個目標僅被一個估計的邊界框覆蓋。下圖給出了傳統 NMS 的偽代碼。

選擇最大分數的邊界框,從檢測結果中去除所有與之有高重疊的邊界框。這個過程遞歸地應用于其余的框中,以獲得最終的結果。
NMS 的變體: 為了避免移除有效目標,Bodlaet 等[145]只是降低了高重疊目標的分數,而不是丟棄它們(Soft NMS)。[146]觀察分類評分與檢測框質量之間的不匹配,并提出回歸分配評分,即 IoU 評分,以發揮(IoU Guided NMS))作用。由于單目3D 檢測器的主要問題是定位誤差[72] ,[80] ,其中深度估計是恢復目標位置的核心問題,Shiet 等[127]使用方法來捕獲估計深度的不確定性,并使用深度不確定度 σ 深度來標準化應用 NMS (Depth Guided NMS)時的得分 σ 深度。據[147] ,[148] ,非極大分數的檢測框也可能具有高質量的定位,并建議通過加權平均高重疊檢測框(加權 NMS)來更新。
同樣,Heet 等[141]也采用加權平均機制,更新平均規則。特別地,他們在高斯分布下建立了檢測框各項的不確定度模型,然后設置了僅與 IoU 和不確定度(Softer NMS)相關的平均規則。劉等[149]建議對不同密度的目標使用動態 NMS 閾值 Ω(自適應 NMS)。
注意,上面提到的一些算法[145] ,[141] ,[148] ,[149] ,[146] ,[147]最初被提出用于2D檢測,但它們可以很容易地應用于3D檢測。此外,[148] ,[141]也可以被視為后優化方法,因為他們除了消除重復檢測,還在 NMS 過程中更新預測結果。
Kumaret 等[70]提出了一種可區分的 NMS 單目3D 檢測方法。通過這種設計,損失函數可以直接對 NMS 后的結果進行操作。此外,對于基于多攝像機的全景數據集,例如 nuScenes和 Waymo Open,需要全局 NMS 來消除重疊圖像的重復檢測結果。
后優化
為了提高檢測框的質量,一些方法選擇在后優化步驟中通過建立幾何約束來進一步細化 CNN 的輸出。
Brazil 和 Liu [68]提出了一種基于投影3D邊界框和2D邊界框的一致性來調整方向 θ 的后優化方法。特別是,他們迭代添加一個小偏移量的預測取向 θ 和投影更新的3D檢測框到2D圖像平面。然后,他們選擇接受這個更新或通過檢查2D 邊界框和投影的3D 邊界框之間的相似性是增加還是減少來調整偏移量。
另一種后優化方法是建立在目標的3D 關鍵點和2D 關鍵點之間的一對一匹配的基礎上。具體來說,Li等[74]生成2D 關鍵點標注(角點版本,可視化參見下圖):
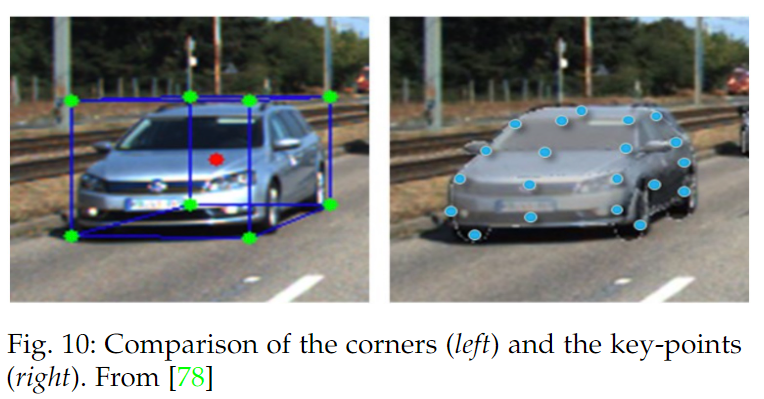
然后用它們的3D 檢測器中的2D 關鍵點估計最終結果。之后,他們恢復世界空間中的3D 角點,并將其投射到圖像平面中。最后,他們通過使用 Gauss-Newton [150]或 Levenberg-MarQuardt算法[151]最小化配對像素的像素距離來更新估計的參數。
利用輔助數據
由于缺乏輸入數據中的深度信息,從 RGB 圖像進行3D 目標檢測是一項具有挑戰性的任務。為了更準確地估計3D 邊界框,許多方法都試圖應用輔助數據并提取RGB 圖像的互補特征。
CAD 模型
CAD 模型已經被用作多個3D相關任務的輔助數據,例如[153] ,[154] ,[155] ,以提供豐富的幾何細節,并可以從公共數據集中收集。在基于圖像的3D目標檢測任務中,CAD 模型主要有兩種考慮方式。
自動標注
CAD 模型的主要應用是自動生成細粒度的標注,以提供更多的監督信號。特別是,一些工作[156] ,[44] ,[78]從開源數據集中收集 CAD 模型,并在每個數據集上標注固定數量的關鍵點。
然后,他們將每個真值的3D 邊界框綁定到其最接近的 CAD 模型(根據3D 維度) ,與所選 CAD 相關聯的3D 頂點被投影到圖像平面中以獲得2D 關鍵點標注。
xiang等[15]和 Sunet 等[51]提出通過將整個 CAD 模型投影到圖像平面而不是預先定義的關鍵點來生成語義mask標注。此外,實例mask可以通過深度排序來區分。請參見下圖。
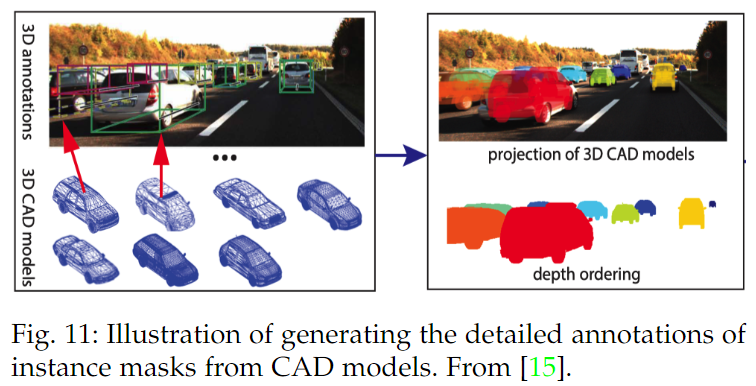
特別地,類似于實例掩模的生成,他們將 CAD 模型投影到立體圖像中,并通過比較左右圖像中的投影坐標來生成視差值。
總之,CAD 模型可以用來生成高質量的標注,包括關鍵點、實例mask和視差圖。
數據增強
CAD 模型也可以考慮數據增強。具體來說,復制粘貼策略[159]是一個強大的數據增強的策略,并已應用于基于圖像的3D 檢測[58] [24]。特別是與直接復制和粘貼 RoI 紋理相比[160] [24],Alhaijaet 等[161]和 Manhardtet 等[58]使用 CAD 模型來增強城市駕駛場景。他們渲染高質量的 CAD 模型,并將其覆蓋在真實的圖像之上。通過這種方式,更真實的合成圖像(見下圖)和更多的訓練樣本與新的姿態產生。

LiDAR 信號
LiDAR 數據有豐富的空間信息,這是圖像數據所欠缺的。在這里,作者總結了現有的基于圖像的方法,只在訓練階段應用激光雷達信號,推理階段不引入額外開銷。
LiDAR作為監督信號
總的來說,相關的技術貢獻可以大致分為以下幾類。
由激光雷達信號產生深度標注。 幾乎所有的方法都需要深度圖,并且總是需要深度估計的子任務。LiDAR生成的深度圖更準確。
利用激光雷達信號生成mask標注。 有些工作[32] ,[53] ,[54] ,[34]使用激光雷達信號來生成實例mask。特別地,激光雷達點的語義標簽可以通過檢查它們是否位于3D邊界框中來確定。然后他們將這些點投影到圖像平面上,并將mask標簽分配給相應的圖像像素。
在訓練階段提供額外的指導。 從 LiDAR 信號訓練的模型可以作為基于圖像的模型的教師網絡,并通過知識蒸餾機制將學習的空間信息傳遞給基于圖像的方法[163]。
用 GAN 實現數據提升。 基于數據提升的方法在基于圖像的3D 檢測中很流行,GAN 為數據提升提供了潛在的選擇[99]。特別地,生成器網絡的目標是輸出輸入的2D圖像的3D表示,而鑒別器網絡負責通過將數據與真實的 LiDAR 信號進行比較來確定是否生成了數據。在該流程中,激光雷達信號僅在訓練階段作為鑒別器網絡的輸入。在推理階段,去除鑒別器網絡,并將生成器網絡的輸出反饋給一個現成的基于激光雷達的3D檢測器,以獲得最終的結果。
利用稀疏LiDAR信號進行深度校正
許多現有的基于圖像的3D 檢測模型,特別是偽激光雷達系列,使用估計的深度映射來提供空間信息。然而,無論是單目深度估計[56] ,[57] ,[93]還是立體匹配[88] ,[55] ,深度圖的準確性仍然不是很準確,特別是對于遙遠的目標。特別是,深度估計方法確實能夠捕獲目標,但是它們不能精確地估計目標的深度。基于這一觀測結果,pseudo-LiDAR++[94]提議利用激光雷達信號來糾正這一系統誤差。更重要的是,只需要幾個點作為“地標”,模擬的4光束 LiDAR可以顯著提高估計深度地圖的質量。只有4束激光的激光雷達傳感器比64束要便宜兩個數量級。此外,還有一些其他的方法,如[31] ,[164] ,[32] ,[165] ,試圖將 RGB 圖像和完整的 LiDAR 信號融合到一個3D檢測模型中。
外部數據
眾所周知,額外的訓練數據通常可以提高神經網絡的表示能力,緩解過擬合問題。基于這種思想,許多工作建議使用額外的開源數據集來增加給定的訓練數據。
深度估計的附加數據
深度估計是基于圖像的3D目標檢測的一個核心子問題,許多工作已經表明,引入附加的深度訓練數據可以顯著提高3D檢測器的整體性能。在這里,作者根據所使用的數據集總結這些方法,并強調潛在的數據泄漏問題。
KITTI Depth: 為了提供深度信息,許多方法都會在一個更大的數據集上訓練一個獨立的 CNN,KITTI Depth是最常用的一個,因為它與 KITTI 3D 具有相似的分布。具體來說,KITTI Depth 有23,488個訓練樣本,而且許多工作在這個數據集上訓練他們的深度估計器,并為 KITTI 3D 生成深度地圖。這些估計的深度圖可以作為輸入數據[34] ,[33] ,[59] ,[62] ,[63] ,[16] ,[166] ,[64] ,[65] ,[95]或增加輸入圖像[45] ,[60] ,[61] ,[130] ,[58]。
DDAD15M: 這個數據集是 DDAD 數據集的擴展版本[167] ,包含大約15M 幅城市駕駛場景的圖像,用于深度估計。Parket 等[23]提出,與從頭開始訓練和從 ImageNet 預訓練模型進行微調相比,這個大規模數據集的預訓練可以提供網絡的豐富的幾何學之前,并大大提高最終性能。場景流程[168]。
場景流是一個合成的數據集,它提供了超過30K 的立體圖像對和密集的標注。為了進一步提高立體匹配的準確性,許多工作,包括[45] ,[34] ,[53] ,[54] ,[94] ,[98] ,[63] ,在這個數據集上預訓練立體網絡用于他們的3D 檢測器。
Data leakage: 如上所述,一些方法選擇在 KITTI Depth或 KITTI 多目上預訓練一個子網絡。遺憾的是, KITTI Depth/多目訓練集和 KITTI 3D 驗證集之間存在重疊,這可能導致Data leakage問題。Wanget 等[34]意識到這個問題,建議從 KITTI 3D 的訓練分裂提供的圖像重新訓練他們的差異估計模型,但是單目深度估計器中的這個問題仍然存在。
更糟糕的是,單目3D 檢測器[34] ,[33] ,[60] ,[45] ,[62] ,[59] ,[61] ,[65] ,[63] ,[64] ,[130] ,[166]與預先計算的深度圖繼承了這個問題,這導致了 KITTI 3D 驗證集上的不公平和不可靠的比較。最近,Simonelliet 等[16]重新討論了這個問題,并提供了一種新的訓練/驗證分割,通過比較每幅圖像對應的 GPS 數據來避免重疊。不幸的是,他們的實驗結果表明,不能完全修復,建議未來的工作在建立他們的模型時考慮這個問題。
半監督學習無標記數據
由于現有的數據集通常只標注收集數據的關鍵幀,存在大量未標記的原始數據,這些數據可以進一步利用半監督學習(SSL)方法。Penget 等[169]將偽標記范式引入到單目3D 檢測中。特別是,他們使用帶標注的關鍵幀訓練一個基于 LiDAR 的模型,并為剩余的未標記數據生成偽標簽。
然后,利用偽標注數據訓練單目3D檢測器,并利用增強訓練集進行訓練。請注意,這個方案涉及另一種輔助數據,LiDAR 信號,以及更多的 SSL 方法,如[170] ,[171]沒有其他依賴關系,可以在未來的工作中進行研究。
其他
CityScapes[172] 實例mask在許多基于圖像的3D 檢測器中起著重要作用,例如[59] ,[55] ,[53] ,[54] ,而3D 檢測數據集中沒有真值。除了使用 CAD 模型或 LiDAR 信號生成標簽之外,Weng 和 Kitani [59]介紹了另一種訓練分割網絡的方法。特別是,他們在 CityScapes 上預先訓練他們的分割模型,CityScapes 包含了5000張自動駕駛場景中的像素標注圖像,并在 KITTI 多目上對其進行微調。然后他們確定分割網絡的權重并用它來預測系統中的mask。有些工作像[69] ,[22]需要估計自運動來支持他們提出的設計。不幸的是,KITTI 3D 沒有提供這種標注。在這種情況下,Brazil 等人[69]從 GPS/IMU 設備記錄的 KITTI 原始數據中獲得自運動真值。
時間序列
時間線索對于人類視覺系統至關重要,最近的一項工作[69]將時間序列應用于單目3D 檢測。特別地,Brazil 等[69]首先使用修改后的 M3D-RPN [68]來估計來自單獨圖像的3D 檢測框,然后連接相鄰幀的特征并估計相機的自運動。最后,他們使用3D卡爾曼濾波器[173]來更新估計的檢測框,同時考慮到目標的運動和自車運動。
值得注意的是,初始結果仍然是從單幀預測,并且3D卡爾曼濾波器主要用于更新結果,以保證圖像序列之間結果的時間一致性。從這個角度來看,這種方法可以看作是一種后處理。此外,利用3D卡爾曼濾波器,這種方法還可以預測目標的速度,而不需要任何標注。
多目
為了提供單目圖像中缺乏的深度信息,許多方法在其模型中使用立體對。多目圖像的主要應用可以分為兩類: 生成更好的深度圖和豐富特征。從多目圖種生成更好的深度圖方法,包括基于偽激光雷達的方法和深度增強特征學習的方法,都需要深度圖作為輸入。
與單目深度估計相比,多目圖像[55] ,[88] ,[92]估計的深度圖一般更準確,幾個工作[45],[33],[34]的實驗表明,高質量的深度圖(特別是前景區[95])可以顯著提高這些方法的最終性能。使用多目對豐富特征圖是另一個應用方向。許多方法以不同的方式提出他們的解決方案,包括但不限于特征融合[47] ,[55] ,注意力機制[42] ,50 ,并建立更好的特征表示(如cost量[50] ,[81] ,[82])。
輸入數據作為分類
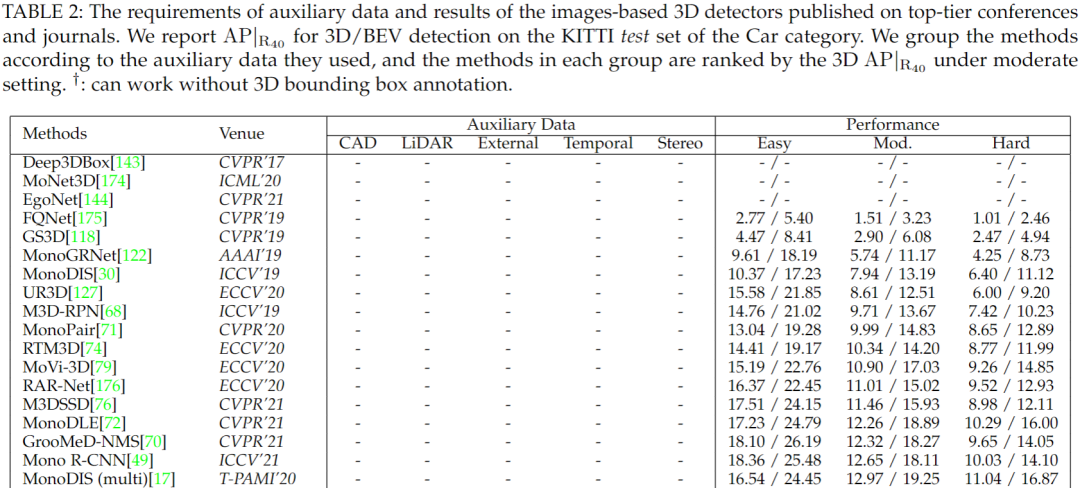
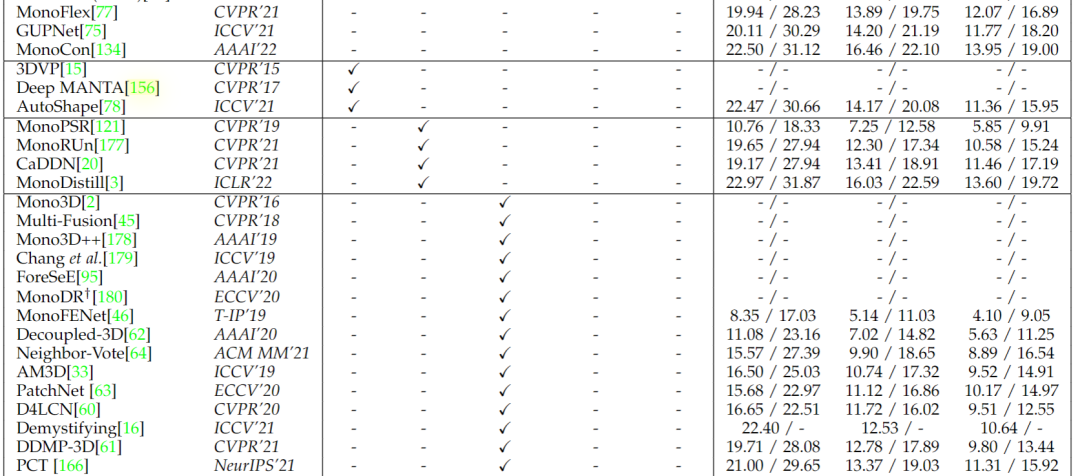
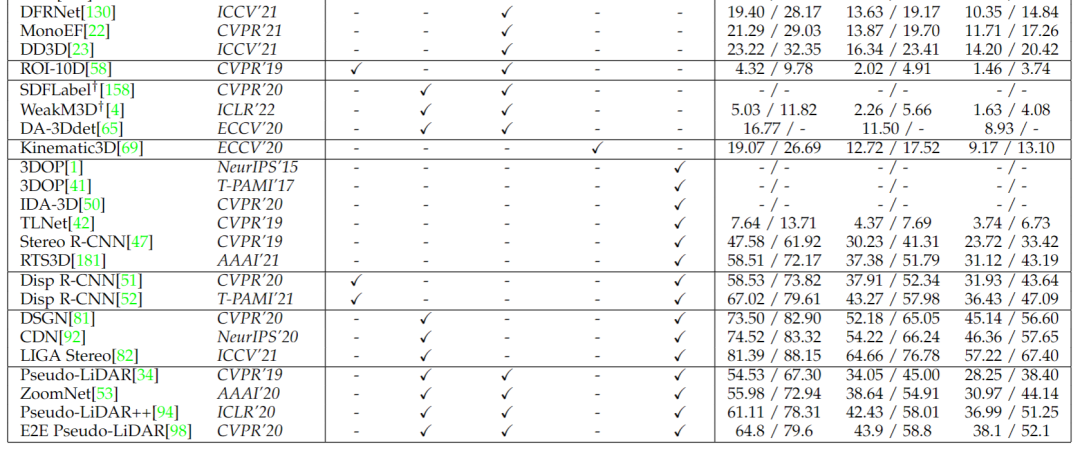
在上述部分中,作者總結了輔助數據的主要應用,包括 CAD 模型,LiDAR 信號,外部數據,時間序列和多目圖像。為了更好地說明這些數據對算法的影響,作者展示了現有方法在最常用的 KITTI 3D數據集上獲得的結果和使用的輔助數據。從這些結果中,作者可以發現以下觀察結果:
大多數方法在其模型中采用至少一種輔助數據,這表明輔助數據的廣泛應用,從單個圖像估計3D邊界框充滿挑戰。
立體圖像為基于圖像的3D檢測提供了最有價值的信息,在推理階段利用這類數據的方法的效果明顯優于其他方法。
雖然視頻中的時間視覺特征對視知覺系統至關重要,但利用時間序列的方法只有一種[69] ,并鼓勵在未來的工作中更多地使用這類數據。
現有方法的性能得到迅速和不斷的改善。以沒有任何輔助數據的方法為例,KITTI 基準(中等設置)的 SOTA 性能已經從1.51(FQNet [122] ,發表于 AAAI’22)上升到16.46(MonoCon [134] ,發表于 CVPR’19) ,因為輸入數據可能在現有算法中是不同的,這些數據對3D 檢測器的好處也是不同的,不考慮他們使用的數據比較方法是不公平的。因此,作者認為算法的基本輸入數據也可以作為分類學,并且應該在相同的設置下進行比較。下表是基于圖像的3D 檢測器的輔助數據和結果。
未來方向
深度估計
基于圖像的3D目標檢測的性能很大程度上依賴于估計目標的精確距離的能力。因此,分析和提高3D目標檢測器的深度估計能力是一個發展方向。最近的許多工作,如[20] ,[49] ,[75] ,[92] ,[95] ,[25] ,試圖解決這個問題,提出了回歸目標和損失函數的替代定義,并表明仍然有很大的改進空間。
引入偽激光雷達方法[34] ,[33] ,[59] ,其中3D 目標檢測器已經與預先訓練的深度估計器配對,并證明可以獲得更好的整體性能。雖然這是一個有希望的初步步驟,深度和檢測方法仍然是完全獨立的。為了克服這個問題,[98] ,[135]建議將3D檢測和深度估計加入到一個單一的多任務網絡中。他們證明,當這兩個任務一起訓練并且有可能從彼此中受益時,3D 檢測性能提高得更多。作者相信這些結果將顯示和驗證深度和檢測結合的潛力,強調這將構成相關的未來方向。
超越完全監督的學習
創建3D 檢測數據集是一個極其昂貴和耗時的操作。它通常涉及不同技術(如激光雷達、全球定位系統、相機)之間的協同作用,以及大量的標注人員。標注過程的要求非常高,即使有許多質量檢查,也不可避免地會受到錯誤的影響。有鑒于此,作者需要看到幾乎所有的3D目標檢測方法都是受到全面監督的,即需要對3D邊界框標注進行訓練。
與其他相關社區的完全監督要求已經放松的相反,深度估計[56] ,[185]或基于 LiDAR 的3D 檢測[186] ,[187] ,[188] ,[189] ,很少有人致力于探索半自監督或自監督方法[180] ,[190] ,[4]。在這方面,值得強調的方法在[180] ,其中引入了可微渲染模塊,使得開發輸入 RGB 圖像作為唯一的監督來源。
另外,鑒于最近在通用場景(如 NeRF [191])和真實目標(如[192] ,[193])的可微渲染領域取得的進展,作者相信這個特殊的方向是非常有價值的,能夠潛在地放松對3D 框標注的要求。
多模態
正如前面討論的,圖像數據和 LiDAR 數據都有它們的優勢,一些方法,如[31] ,[89] ,[32] ,[164] ,[165] ,最近已經開始將這兩種類型的數據集成到一個單一的模型中。然而,這一領域的研究還處于起步階段。此外,還可以考慮其他數據模式,以進一步提高算法的準確性和魯棒性。
例如,與激光雷達相比,Radar設備具有更長的傳感距離,可用于提高遠距離目標的精度。另外,Radar在雨天、霧天等極端天氣條件下更加穩定。然而,雖然同步Radar數據已經在一些數據集中提供了[6] ,[194] ,[195] ,但是只有少數幾種方法[195] ,[196] ,[197]研究如何使用它們。另一個例子是來自熱成像相機的數據[198] ,它提供了新的機會,通過處理不利的照明條件來提高檢測的準確性。總之,理想的檢測算法應該整合各種數據,以覆蓋異質性和極端條件。
時間序列
在現實世界中,人類駕駛員依靠連續的視覺感知來獲取周圍環境的信息。然而,該領域的大多數工作從單幀的角度解決了3D 檢測問題,這顯然是次優的,只有一個最近的工作[69]開始考慮時間線索和約束。另一方面,大量的工作已經證明了在許多任務中使用視頻數據的有效性,包括2D 檢測[199] ,[200] ,深度估計[201] ,[202] ,分割[203] ,[204]和基于激光雷達的3D 檢測[205] ,[206] ,[207]。
這些相關領域的成功表明了在3D檢測任務中利用視頻數據的潛力,并且通過引入時間數據和在時空中建立新的約束可以實現新的突破。關于序列的使用,一個特別有趣的未來方向是它們可以用于放松全面監督的要求。如果結合已經可用的輸入 RGB 圖像實際上,他們被證明是能夠自監督深度估計[208]。
有鑒于此,有理由認為,如果同樣的監督也將用于恢復目標的形狀和外觀,同樣的方法可以用于執行3D 目標檢測,正如[193] ,[180]所建議的。最后一個相關方向由速度估計表示。一些數據集,例如 nuScenes [6] ,實際上不僅需要估計目標的3D 檢測框,還需要估計它們的速度。這引入了另一個極具挑戰性的任務,需要通過使用多個圖像來解決。
泛化
泛化在自動駕駛汽車的安全性方面起著重要作用。在這方面,不幸的是,眾所周知,基于圖像的3D目標檢測方法在測試看不見的數據集、目標或具有挑戰性的天氣條件時,性能會有相當大的下降。
在表5中可以找到一個例子,其中作者顯示了基于圖像的基線(連同 LiDAR 基線)在流行的 nuScenes 數據集的子集上的性能,這些子集包含雨水或夜間捕獲的圖像。在導致這種性能下降的許多因素中,幾乎所有基于圖像的3D 檢測器都是依賴于相機的。他們期望相機內在參數在訓練和測試階段之間保持不變。
克服這種局限性的初步嘗試已經在[209]中得到了發展,但是作者相信這個方向應該進一步探索。另一個關鍵因素來自于這樣一個事實,許多基于圖像的3D 目標檢測方法依賴于數據集特定的目標優先級。平均目標3D 范圍,以作出他們的預測。
如果測試在不同的數據集中的目標,如汽車,顯著偏離這些平均范圍,那么3D 檢測器可能會失敗。由于解決這個問題的努力非常有限[210] ,[211] ,[212] ,[213] ,并且獨特地集中在基于 LiDAR 的方法上,作者認為這也構成了相關的未來方向。
結論
本文提供了基于圖像的自動駕駛3D檢測的最新發展的綜合調查。作者已經看到,從2015年到2021年,已經發表了大量關于這一主題的論文。為了系統地總結這些方法,作者首先根據它們的高層結構對現有方法進行分類。然后,對這些算法進行了詳細的比較,討論了3D檢測的每個必要組成部分,如特征提取,損失函數,后處理等。
作者還討論了輔助數據在這一領域的應用,支持需要一個系統的總結,如本調查和更好的協議,以便在未來的工作中進行公平的比較。最后,作者描述了這一領域的一些公開挑戰和潛在方向,這些挑戰和方向可能會在未來幾年激發新的研究。
審核編輯:劉清
-
檢測器
+關注
關注
1文章
887瀏覽量
48401 -
RGB
+關注
關注
4文章
803瀏覽量
59567 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46557
原文標題:純視覺3D檢測綜述!一文詳解3D檢測現狀、趨勢和未來方向!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
新能源車軟件單元測試深度解析:自動駕駛系統視角

康謀分享 | 3DGS:革新自動駕駛仿真場景重建的關鍵技術

?超景深3D檢測顯微鏡技術解析
【實戰】Python+OpenCV車道線檢測識別項目:實現L2級別自動駕駛必備(配套課程+平臺實踐)

淺析基于自動駕駛的4D-bev標注技術

CASAIM自動化檢測設備3D尺寸檢測形位公差測量設備
使用STT全面提升自動駕駛中的多目標跟蹤
人工智能的應用領域有自動駕駛嗎

神經重建在自動駕駛模擬中的應用






 工商網監
工商網監

評論