 AMD能在服務器領域實現領跑嗎
AMD能在服務器領域實現領跑嗎
AMD能在服務器領域實現領跑嗎?
由于驗證周期長,服務器行業轉向新供應商的速度很慢。安全的選擇是堅持現有的供應商,無論是幾十年前的 IBM,還是現在的英特爾。不過,AMD表示“堅持使用至強并不安全”。
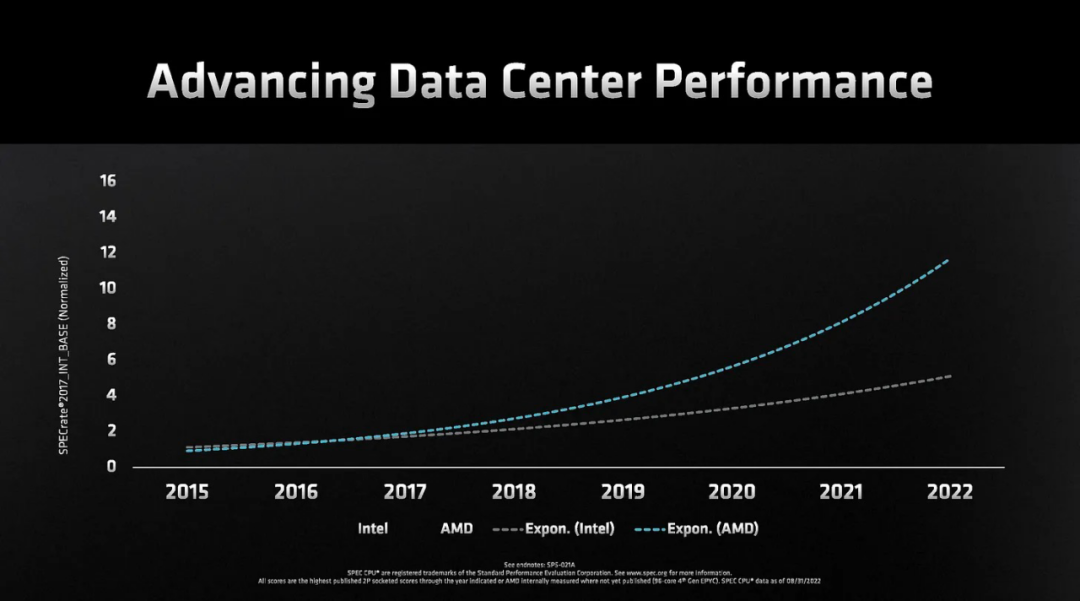
第四代 Epyc Genoa 的發布標志著 AMD 在大多數性能指標上連續三代擊敗英特爾。Rome和Milan讓云玩家開始大量購買 AMD,而Genoa可能會征服剩余的大多數市場和終端用戶。SemiAnalysis 認為,Genoa和Sapphire Rapids的差距大于Milan和Ice Lake之間的差距。這種差距只會持續擴大到 2024 年底,但可能會在 2025 年出現 Sierra Forrest 和 Granite Rapids之間減少。
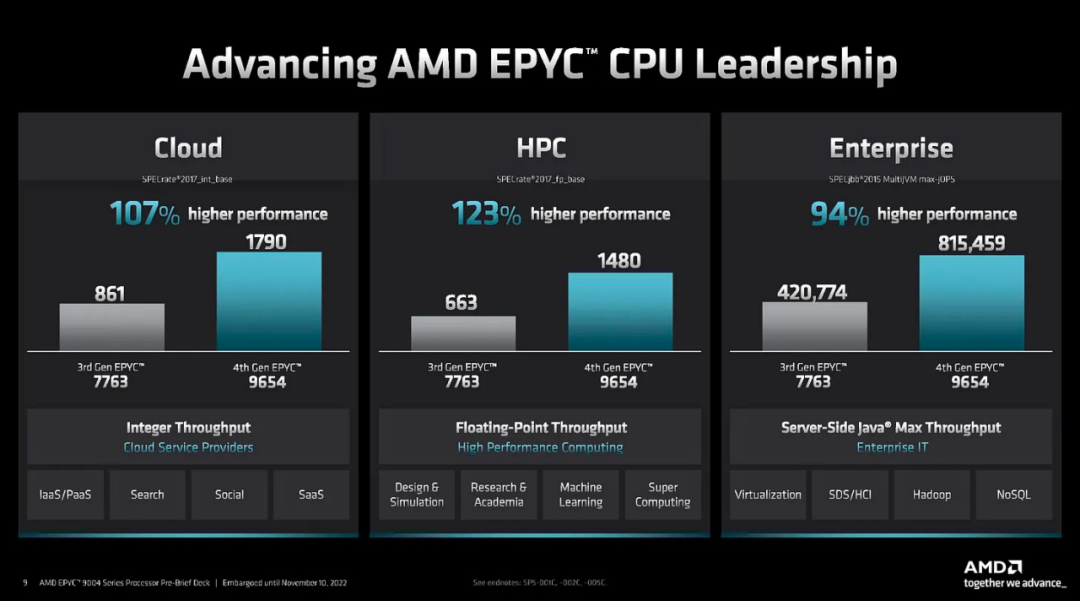
AMD 正在推出越來越多的 CPU 變體。雖然 CPU 用于通用工作負載,但針對各種終端市場的定制正在增加。在第 4 代中,有 4 個變體。Genoa是通用的和主流的。
Bergamo 適用于云原生工作負載。IO die 和平臺與 Genoa 共享,所以很多方面都相似,只是將 Zen 4 核心替換為 Zen 4C 核心,它具有相同的核心架構和 L2 緩存,每個核心只有一半的 L3 緩存。Zen 4C 的內核布局以犧牲頻率為代價實現密度最大化。
Genoa還將有另一個名為 Genoa X 的變體,用于“技術”。這是一個奇怪的定義,但它適用于計算流體動力學、EDA 和其他需要更多緩存的工作負載。Genoa X 將是 Genoa具有 3D V-Cache 和多個潛在的變體。
Siena是給電信公司和邊緣的。由于較低的功率和資本支出需求,我們還會說它適用于某些企業部署。從內存到核心數量,Siena大概是Genoa或Bergamo的 1/2。
最后,AMD 的下一代被稱為 Turin,預計將在 2024 年上半年推出。它有更多的系列和變體。
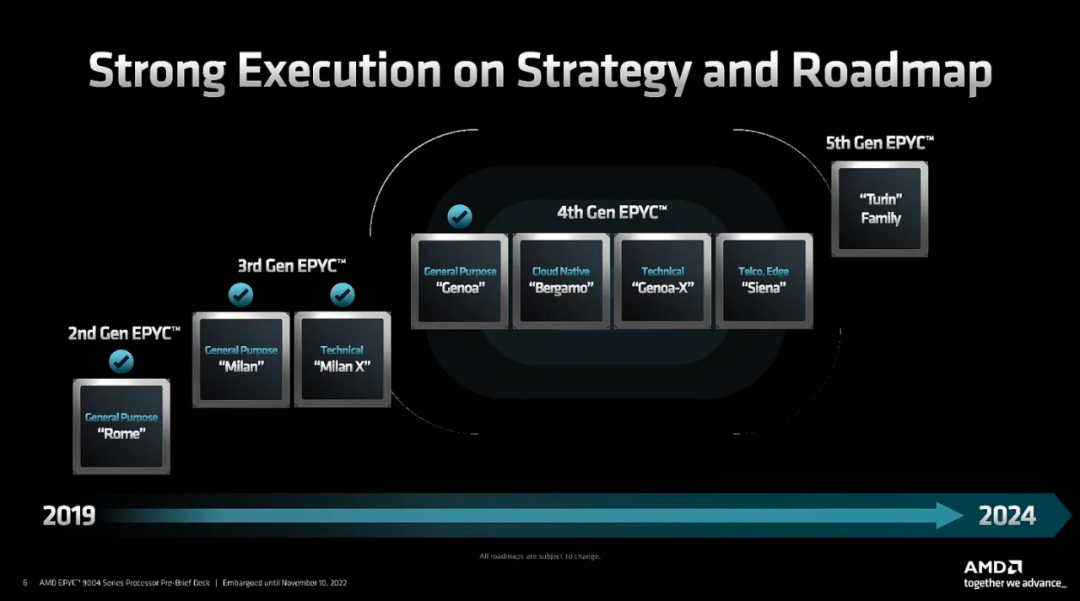
總結一下, Genoa 的性能是 Milan 的 2 倍左右,而功耗只有適度的增加。由于增加了 AVX512 和超大的內存帶寬提升,浮點增益更大

規格沒有什么大的改變,96 個內核、12 個 DDR5 通道和 160 個 PCIe Gen 5 通道(其中 64 個支持 CXL)。附加 CXL 的內存加密對于多租戶云架構的安全性至關重要。CXL 內存 ASIC/設備不需要支持來支持加密,這不依賴于任何特定的 ASIC。

Genoa 的核心是 Zen 4 核心。性能大幅提升,IPC 提高了 14%,由于 L2 大小增加了 2 倍,顯著提高了頻率和平均延遲。前端占 IPC 改進的 40%,加載/存儲改進占 24%,分支預測占 20%,L2 緩存/執行引擎每個是 8%。

AVX512是一個浮點向量指令庫。英特爾以 512 位寬實現它,但這也意味著它在芯片層面的成本太高,而且英特爾沒有在客戶端芯片上包含該功能。此外,當 AVX512 點亮時,芯片的時鐘速度會下降,芯片上的其他工作負載也會受到影響。AMD 通過將其拆分為跨 256 位單元的多個周期,走了一條更加智能的路線。這意味著不存在noisy neighbor問題,并且芯片面積影響仍然很小。

安全性總是很重要, AMD 比英特爾具有優勢的多個核心和 SOC 級別的安全功能。最值得注意的一個與 SMT 或超線程有關。Ampere Computing 喜歡提出每個內核運行多個線程是不安全的論點。帶有 SEV-SNP 的 AMD 正在應對這個問題。如果實現此功能,安全客戶線程可以選擇在共享核心上有活動的同級線程時不運行。這可以防止旁通道攻擊,例如 Spectre 和 Meltdown。
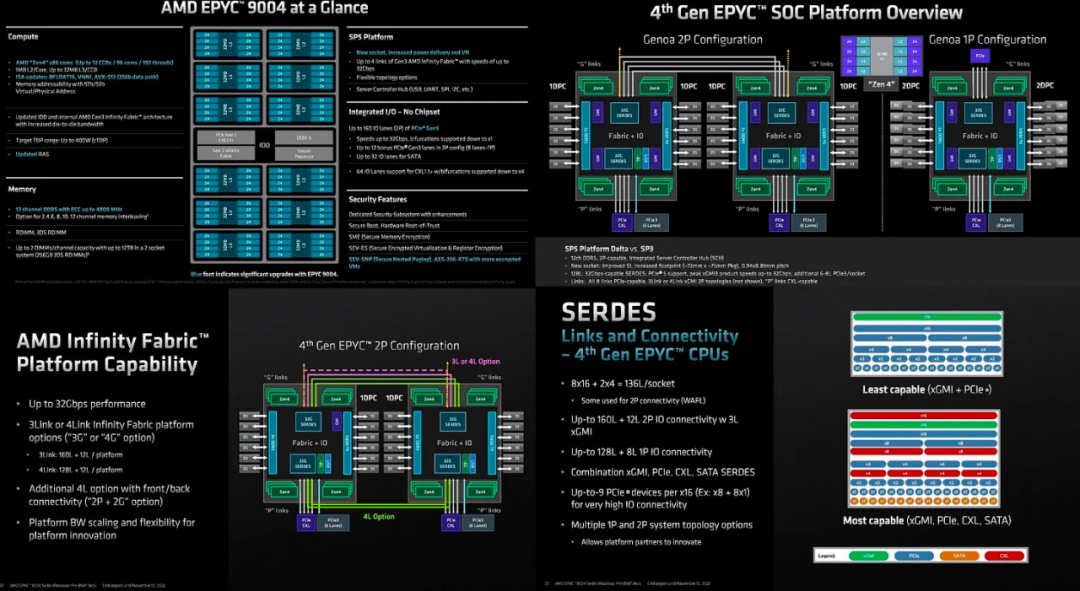
隨著第四代 Epyc 的推出,IO Die 可以說是一個更大、更重要的變化。它建立在 N6 進程節點上,而不是像 CPU 小芯片那樣的 N5。IO 芯片現在得到了加強,可以通過一個更大的、具有更多層的封裝與 12 個小芯片通信。
另一個值得注意的點是插座完全重新設計。安裝機制更堅固,引腳間距更窄,為 0.94 x 0.81mm。尺寸從 58mm x 75mm 增加到 72mm x 75mm。對于像 Unimicron 這樣的公司來說,更大的封裝和更多的層是一件大事
AMD 的 IO 可擴展性非常值得關注。他們使用具有組合功能的 SerDes。從本質上講,這些 SerDes 可以具有多種特性,使得所連接的選項非常可配置。該平臺可以配置 3 個或 Infinity 結構通道,從而在 2S 配置中實現可擴展的 PCIe 通道數。每臺 2S 服務器可以有 3 個 Infinity 結構通道和 160 個 PCIe 通道以及另外 12 個用于平臺的 PCIe 鏈路,或者用于平臺的 4 個 IFIS、128 個 PCIe 和 12 個 PCIe。每個 16x PCIe 根聯合體可以縮減為 9 個 PCIe 設備,其中 1 個 8x 設備 + 8 個 1x 設備。

鑒于Genoa大幅提高 IO 速度,正確利用該帶寬至關重要。增強的 AVIC 減少了虛擬化 IO 設備的開銷。這可以實現更高的帶寬利用率和更少的 CPU 開銷。Milan有一個更早的版本,但它更像是原型。現在使用 Genoa,IO 設備具有接近原生的性能。使用運行 InfiniBand 的 Nvidia 的 Mellanox Connect X7 進行的測試。

Genoa在內存成本方面進行了關鍵改進,這是服務器 BOM 的 50%,這一點不容小覷。
值得注意的是對 72 位和 80 位 DIMM 的支持。大多數服務器將使用 80 位 ECC,但一些超大規模服務器希望減少到 72 位。相對于非 ECC 內存所具有的 64 位,仍有一些 ECC 功能,但比廣泛使用的關鍵任務 80 位要少。這里的優點是用于奇偶校驗檢查的 DRAM 裸片減少了 1 個。“有界故障”功能也有助于解決此問題,因為如果在存儲設備中檢測到錯誤,則可以映射這些問題。
另一個重要特征是雙列與單列內存。Milan 和大多數 Intel 平臺,雙列內存對于最大化性能至關重要。例如,Milan有 25% 的性能增量。在Genoa,這一比例降至 4.5%。這是另一個可觀的成本改進,因為可以使用更便宜的單列內存。
Genoa的內存延遲比Milan高,Genoa為 118ns,而Milan為 105ns。AMD 表示,其中只有 3ns 來自更大的 IO 芯片,Genoa為 73ns,而Milan為 70ns。大多數內存延遲影響來自 DDR5 內存設備本身。DDR5 上為 35ns,而 DDR4 上為 25ns。這是由于 DDR5 不成熟、更大的存儲庫大小以及架構中的其他變化導致的更寬松的時序。內存延遲影響很大,但 SOC 級別的微小增加令人驚訝。

IO Die 到 Core Complex Die 的連接得到了極大的改進。每比特傳輸的功率降至2pj/bit 以下。作為參考,EMIB 聲稱為 ~0.5pj/bit。最值得注意的方面是有一個新的 GMI3-Wide 格式。對于客戶Zen 4 和前幾代 Zen 小芯片,IOD 和 CCD 之間有 1 個 GMI 鏈接。使用 Genoa,在較低的核心數、較低的 CCD SKU 中,可以將多個 GMI 鏈路連接到 CCD。這是可用于較低核心數 SKU 的帶寬的大幅增加。具體來說,這將有助于關系數據庫和高頻 SKU,其中每核許可成本很高。
電源管理得到增強。Genoa 有 2 種基本的電源管理模式,性能確定性或電源確定性。由于熱和硅的變化,不同芯片上的不同工作負載之間可能存在許多差異。考慮到制造涉及數千個工藝步驟,硅不是確定性的。
性能決定論適用于希望獲得持續性能的公司。它在允許的情況下消耗更少的功率,并且性能保持穩定。大多數客戶會選擇此選項,因為穩定性至關重要。
功率確定性是為了保持功耗穩定并提高和降低性能。考慮到硅抽簽、熱預算和工作負載等因素,芯片將提高和降低時鐘速度。
除了電源管理模式外,Genoa 芯片還有一個可配置的 TDP。峰值提升行為將根據選擇的選項而有所不同。時鐘提升基于可靠性和峰值功率傳輸。高活動工作負載將以較低的頻率運行。考慮了系統和芯片裕量。與消費級平臺相比,功率預算不會長期超出。TDP 只能超過 10 毫秒。
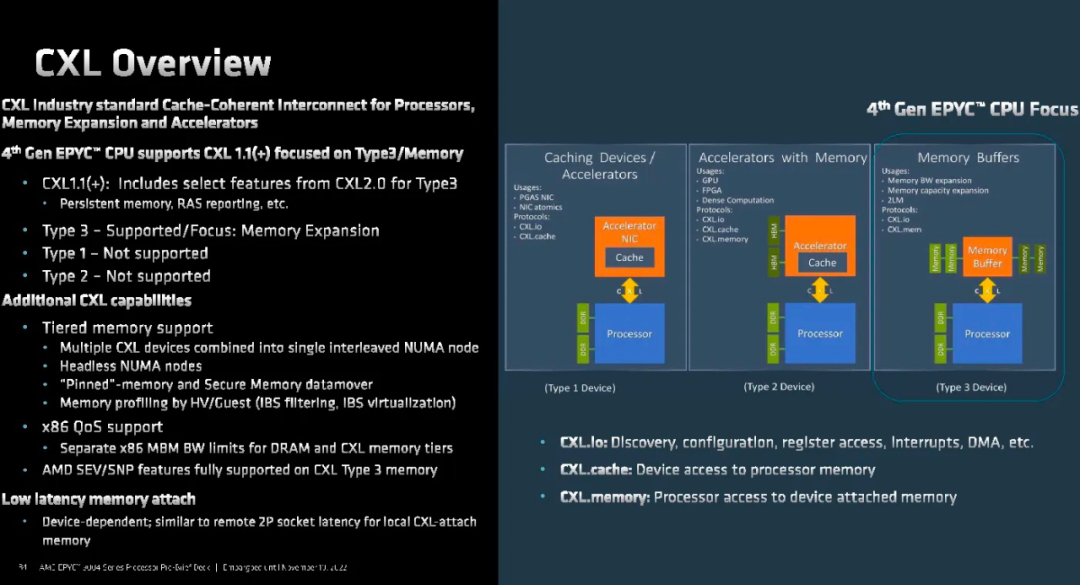
AMD 通常支持 CXL 1.1,但支持 Type 3 內存設備的 CXL 2.0。

值得一提的是,CXL 的 64 個通道可以分成 16 個 4x 器件。Sapphire Rapids不具備 CXL 通道分叉的能力。如果一個連接 4x 或 8x CXL 設備,這將消耗所有 16 個通道。Emerald Rapids 修復了該功能,但那是一年之后的事情。虛擬機管理程序無法更改來賓的內存分配,這對于在云中使用 CXL 附加內存的用戶來說是巨大的。
AMD 的性能支柱是每插槽性能領先、每核心性能領先、所有工作負載和細分市場的領先地位,以及 TCO 和可持續性方面的領先地位。
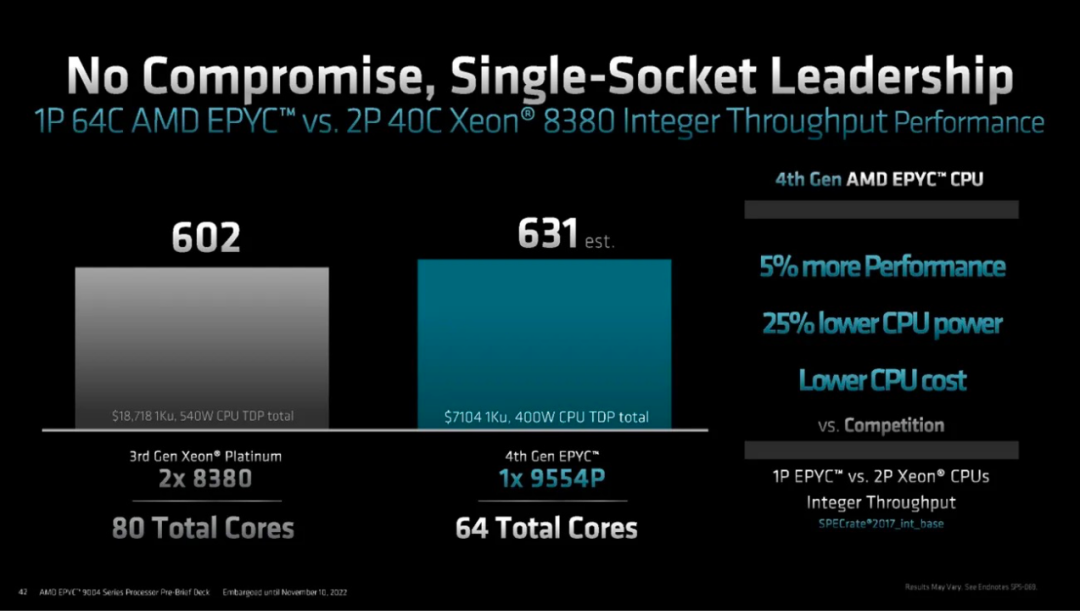
中端 Genoa 芯片與 2 個高端 Xeon 芯片的 1 個比較最好地說明了這一點。AMD 具有更高的性能、更低的功耗、更低的 CPU 成本、更少的內核。
AMD 的領先優勢是開創性的。需要注意的一件事是,當每個內核的軟件許可成本開始發揮作用時,這種領先優勢在 TCO 方面會進一步擴大。這在運行 VMMark 的企業基準測試中得到了最好的體現。VMMark 每個磁貼運行 19 個具有代表性的 VM,然后查看可以運行多少磁貼以及速度。Genoa速度更快,可以處理更多的虛擬機。
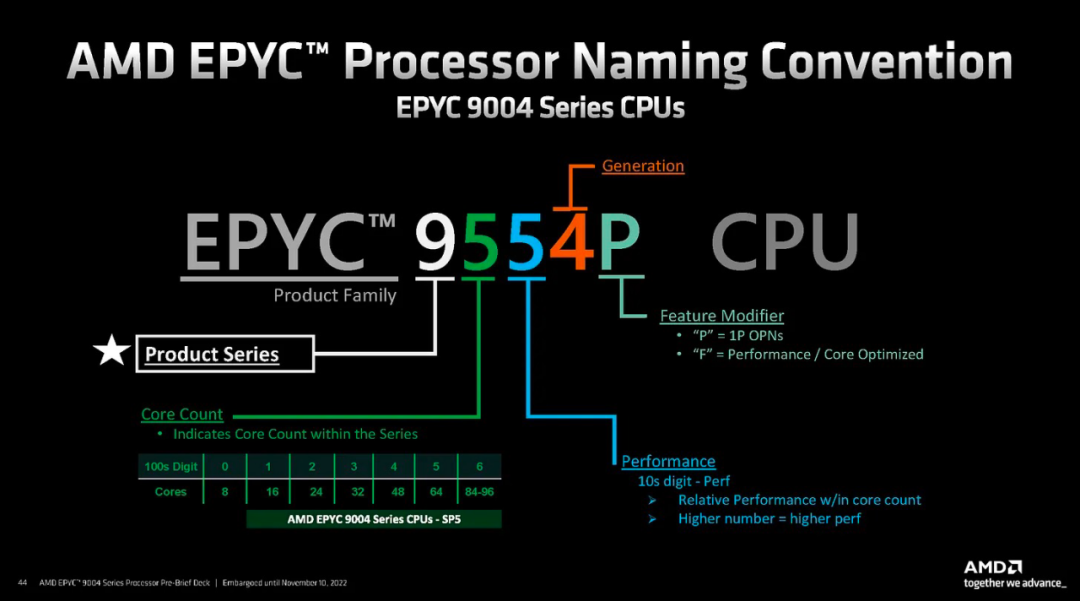
SKU 命名非常簡單明了,每個數字都表示關鍵信息。
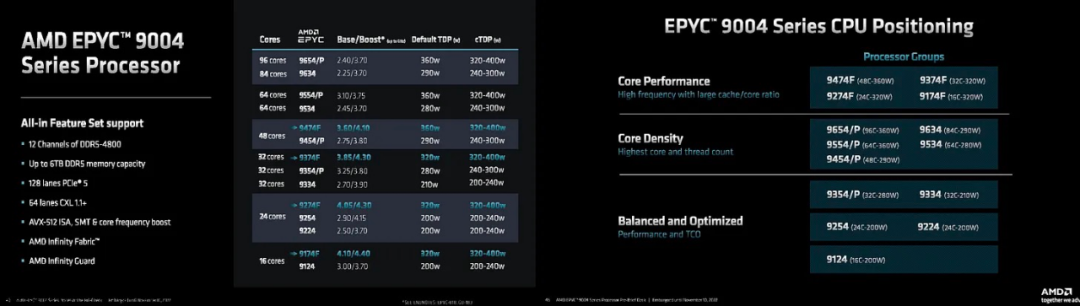
AMD 使 SKU 堆棧保持簡單。與英特爾不同,沒有一堆 SKU 鎖定功能。有3個通用類別和18個SKU。核心性能 (F)、核心密度和平衡/TCO 優化。他們基于 1 個插槽與 2 個插槽支持進行細分。每個核心的價格也保持相對平穩。
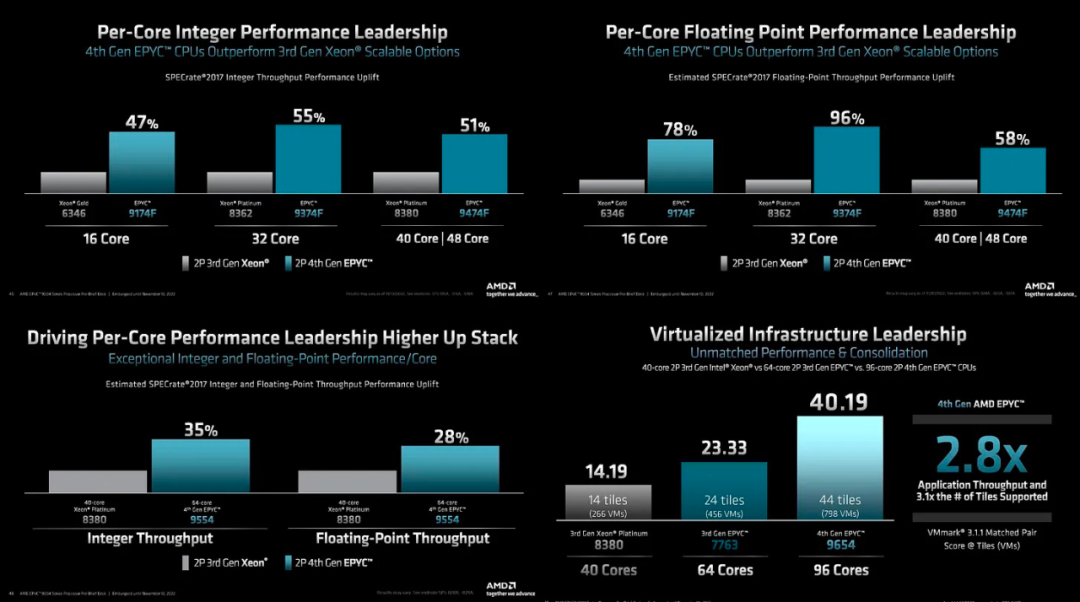
在 Genoa 中,AMD 在整數工作負載上的每核性能領先通常約為 50%,在浮點上則高達 96%,后者大部分是由于內存帶寬和緩存。
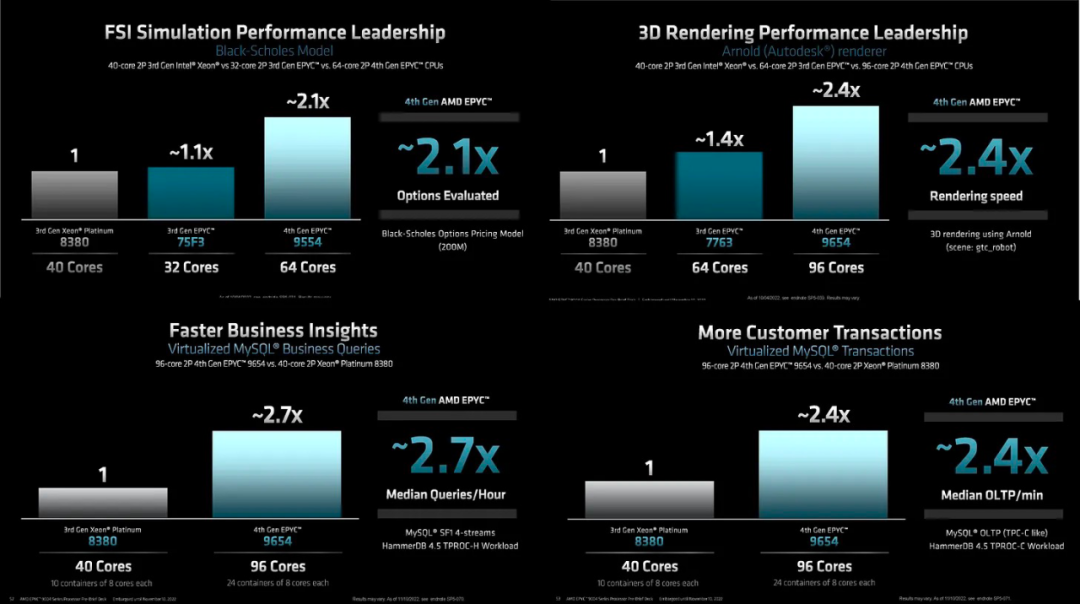
SQL 基準測試值得注意,因為在一些數據庫基準測試中,AMD 由于其較高的核心到核心延遲而落后。他們仍然會在其中許多方面落后,但在一些常用的方面差距正在縮小。Sapphire Rapids 的單片和 4 管芯高級封裝方法的優勢在于,這些海量關系數據庫將大大降低內核之間的延遲。

在 HPC 性能比較中,96C 顯示它仍然受到內存帶寬的限制,但 32C 與 32C 顯示Genoa的帶寬優勢是巨大的。

服務器整合是這里的重頭戲。

如果使用 2P 與 2P 或 2P 與 1P 服務器,數字會有所不同,但結果是相似的。通常 3 個 CPU 合并為 1 個 CPU。

過去,AMD面對著一些問題,如工作負載不會在其中擴展,一些應用程序甚至會崩潰。Genoa擁有如此多的核心,能夠訪問大多數軟件 ISV,因此Genoa結束了過去時期大部分痛苦。

最后一個點是關于機密計算。機密計算意味著軟件不需要信任擁有硬件的所有者,同時能夠保證數據安全。靜態和動態數據,加密是一個很好理解的答案,但在使用中,答案很復雜。雖然Genoa并沒有完全實現機密計算的愿景,但它在該領域帶來了許多創新,使其更加接近。
審核編輯:郭婷
-
amd
+關注
關注
25文章
5475瀏覽量
134276 -
服務器
+關注
關注
12文章
9227瀏覽量
85620
原文標題:詳解AMD Genoa
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
聯想發布基于第五代AMD EPYC處理器的服務器產品
負載均衡服務器與服務器如何連接?
獨立服務器與云服務器的區別
新加坡服務器如何實現免備案?
云服務器是虛擬技術嗎
突破與解耦:Chiplet技術讓AMD實現高性能計算與服務器領域復興







 工商網監
工商網監
評論