 以聰明的方式對Python進行編碼
以聰明的方式對Python進行編碼
我們利用Percepio的Tracealyzer來深入了解同一算法的兩種不同實現的性能。具體來說,我們確定使用迭代函數而不是遞歸函數實現生成斐波那契數列的算法性能更高。我們不需要在序列中生成大量條目并測量時間來識別性能差異;相反,我們能夠使用 Tracealyzer 讓我們深入了解實現的性能,同時在序列中僅生成 10 個條目。
由于斐波那契序列生成器是在 Python 中實現的,讓我們進一步擴展一下。關于StackOverflow的一些主要問題與特定算法的最有效和“Pythonic”實現有關。在本文中,我們將研究一個流行的操作:反轉列表。
根據以下關于 StackOverflow 的問題,在反轉列表時,關于一個實現相對于另一個實現的性能存在一些爭論。為了深入了解差異,我們可以在一個簡單的應用程序中實現這兩種技術,如下面的列表所示;我們還包括必要的源代碼,以捕獲 Tracealyzer 評估每個實現的性能所需的標記:
import logging
def example():
list_basis = list(range(10))
logging.basicConfig()
logger = logging.getLogger(‘my-logger’)
logger.info(‘Start’)
reverse_list = reversed(list_basis)
logger.info(‘Stop’)
logger.info(‘Start’)
reverse_list = list_basis[::-1]
logger.info(‘Stop’)
if __name__ == ‘__main__’:
example()
我們創建了一個包含 10 個元素的列表,并使用內置的“反轉”函數以及 Python 中稱為“切片”的技術來反轉列表。切片只是獲取列表中的某些元素并將它們返回到新列表;在我們的例子中,我們正在切片整個列表,但向后遍歷。
與上一篇博客文章一樣,我們可以創建一個 LTTng 會話,運行我們的 Python 腳本,在 Tracealyzer 中打開生成的跟蹤,并評估結果:
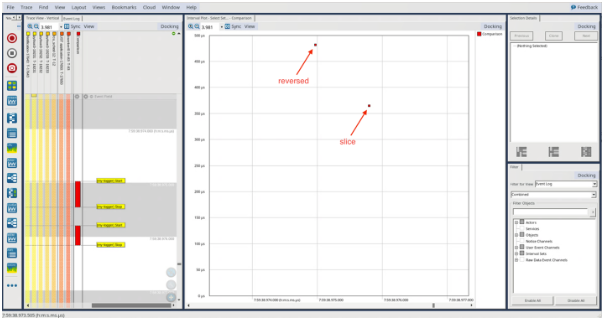
我們可以看到,使用反向函數的實現大約需要 475 微秒,使用切片的實現大約需要 360 微秒。
讓我們看看當我們將初始列表中的元素數量增加 10 倍時會發生什么,從而得到一個由 100 個元素組成的列表:
import lttngust
import logging
def example():
list_basis = list(range(100))
logging.basicConfig()
logger = logging.getLogger(‘my-logger’)
logger.info(‘Start’)
reverse_list = reversed(list_basis)
logger.info(‘Stop’)
logger.info(‘Start’)
reverse_list = list_basis[::-1]
logger.info(‘Stop’)
if __name__ == ‘__main__’:
example()
同樣,我們重新運行必要的步驟來創建 LTTng 會話,運行我們的應用程序,并在 Tracealyzer 中打開生成的跟蹤,它向我們顯示了下圖:
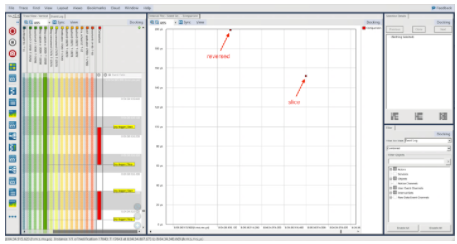
雖然我們看到與以前相同的模式,其中切片技術比反向函數表現更好,但我們可以看到,與只有 10 個元素的結果相比,這兩種機制的絕對時間幾乎減少了一半。這很有趣,因為我們預計,與 100 個元素的情況相比,在 10 個元素的情況下,這兩種技術所花費的時間應該更少。讓我們通過首先更新 Python 腳本來收集更多數據,以允許我們以自動方式收集更多數據:
import lttngust
import logging
import sys
def example(list_size):
list_basis = list(range(list_size))
logging.basicConfig()
logger = logging.getLogger(“my-logger”)
logger.info(“Start”)
reverse_list = reversed(list_basis)
logger.info(“Stop”)
logger.info(“Start”)
reverse_list = list_basis[::-1]
logger.info(“Stop”)
if __name__ == ‘__main__’:
example(int(sys.argv[-1]))
在上面的例子中,我們只是允許自己在列表中傳入我們想要的元素數量。然后我們可以創建以下 bash 腳本,這將允許我們執行 Python 應用程序,連續給它一個 10 和 100 的參數,收集使用反向函數和切片方法反轉列表所需的時間,并存儲該數據;腳本將循環瀏覽每個測試 10 次。
#!/bin/bash
set -e
list_compare() {
echo “Running test with a list size of $1 elements”
lttng create
lttng enable-event --kernel sched_switch
lttng enable-event --python my-logger
lttng start
python3 list_compare.py $1
lttng stop
lttng destroy
}
for i in {1..10}
do
list_compare 10
cp -r ~/lttng-traces/auto* “/home/pi/percepio/elements_10_trace_$i”
chown -R pi: “/home/pi/percepio/elements_10_trace_$i”
mv ~/lttng-traces/auto* ~/lttng-traces/archive/
list_compare 100
cp -r ~/lttng-traces/auto* “/home/pi/percepio/elements_100_trace_$i”
chown -R pi: “/home/pi/percepio/elements_100_trace_$i”
mv ~/lttng-traces/auto* ~/lttng-traces/archive/
done
當我們在 Tracealyzer 中打開生成的跡線并繪制圖表時,我們會看到以下趨勢:
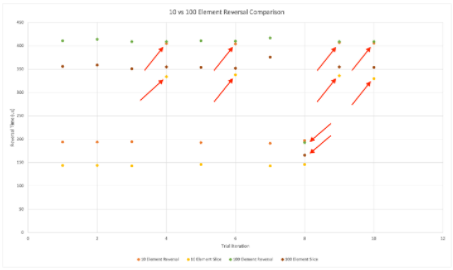
黃色和橙色圖表示 10 個元素列表的反轉時間,綠色和深紅色圖表示 100 個元素列表的反轉時間相同。我們可以看到一些實例,其中 10 個元素列表反轉的執行時間與 100 個元素結果的執行時間一致。類似地,我們可以看到,有一個實例減少了反轉 100 個元素列表的執行時間,并且與反轉 10 個元素列表的執行時間相同。但是,總的來說,我們可以看到反轉 10 個元素列表的執行時間大約是反轉 100 個元素列表所需時間的一半。
也許我們在前一個案例中觀察到了這些異常之一?讓我們分析包含 1000 個元素的結果:
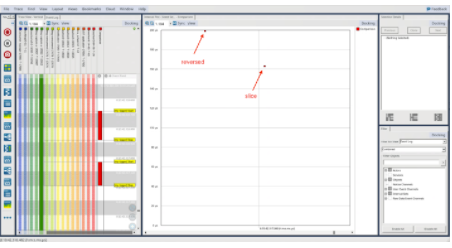
同樣,我們看到相同的模式,與使用反向功能相比,使用切片技術花費的時間更少。但是,即使我們再次將列表中的元素數量增加了 10 倍(達到驚人的 1000 個元素),每個實現的時間與 100 個元素的時間大致相同,與只有 10 個元素相比,時間仍然是一半的時間。
讓我們將列表大小增加到 100k 個元素并觀察結果:
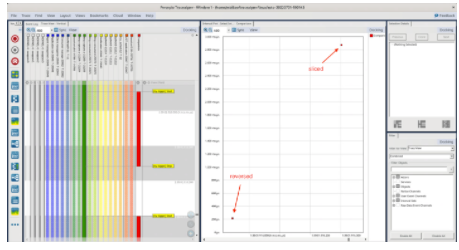
以前我們觀察到切片技術花費的時間大約是反向函數的一半,而在這里我們可以看到相反的情況。事實上,對于 100k 個元素的列表大小,切片技術花費的時間大約延長了 15 倍!
總之,我們從這個簡單的練習中獲得了一些寶貴的見解。首先,與反向函數相比,切片技術似乎花費的時間更少,對于“幾個”元素的列表大小(最多 1000)。但是,當我們將列表大小增加到 100k 個元素時,我們可以看到切片技術比反向函數花費大約 15 倍的時間。其次,當我們運行較小大小列表的多次迭代時,我們確實注意到反轉包含 100 個元素的列表的時間與反轉包含 10 個元素的列表的時間大致相同的實例;然而,總體趨勢是,反轉包含 10 個元素的列表比反轉包含 100 個元素的列表花費的時間更少,這是意料之中的!我們可以更詳細地分析Tracealyzer捕獲的痕跡,以了解觀察到的異常的原因。
這里的關鍵要點是,Percepio 的 Tracealyzer 使我們能夠在沒有太多儀器基礎設施的情況下執行這種詳細的分析;我們能夠辨別出大約 100 微秒的性能數字!
由于Python一直是機器學習的流行語言,因此我們必須擁有一個工具,可以快速將一種算法的性能與另一種算法的性能進行比較。我們可以開發一些小函數來隔離我們要評估的算法,并使用 Tracealyzer 為我們提供有關算法在不同維度的性能的必要見解。Tracealyzer還可以快速發現可能需要進一步分析的異常行為。
審核編輯:郭婷
-
函數
+關注
關注
3文章
4333瀏覽量
62688 -
python
+關注
關注
56文章
4797瀏覽量
84752
發布評論請先 登錄
相關推薦
如何在程序中以編碼方式來控制JBOSS
圍繞神經網絡知識和網絡應用方式展開Python和R語言實戰編碼

學習Python的最佳方式取決于你個人的學習方式
CRC算法原理和CRC編碼的實現方式與使用Verilog對CRC編碼進行描述
NVIDIA推出適用于Python的VPF,簡化開發GPU加速視頻編碼/解碼
AI和聰明的算法之間的區別在于它的編程方式
Python的學習和使用經驗說明

Python中的默認編碼
Python字符編碼轉換





 工商網監
工商網監
評論