 基于RISC-V軟核CPU的國產FPGA CNN異構方案的實現
基于RISC-V軟核CPU的國產FPGA CNN異構方案的實現
摘要:現場可編程門陣列(FPGA)具有低功耗、高性能和靈活性的特點。FPGA神經網絡加速的研究正在興起,但大多數研究都基于國外的FPGA器件。為了改善國內FPGA的現狀,提出了一種新型的卷積神經網絡加速器,用于配備輕量級RISC-V軟核的國產FPGA(紫光同創PG2L100H)。所提出的加速器的峰值性能達到153.6 GOP/s,僅占用14K LUT(查找表)、32個DRM(專用RAM模塊)和208個APM(算術處理模塊)。所提出的加速器對于大多數邊緣AI應用和嵌入式系統具有足夠的計算能力,為國內FPGA提供了可能的AI推理加速方案。
背景
卷積神經網絡在機器視覺任務中越來越流行,包括圖像分類和目標檢測。如何在有限的條件下充分發揮FPGA的最大性能是各研究者的主要方向。如今,大多數CCN使用外國FPGA器件。由于國內FPGA起步較晚,其相關開發工具和設備落后于其他外國制造商。因此,在國內FPGA上構建高性能CNN并替換現有成熟的異構方案是一項具有挑戰性的任務。
Zhang[1]于2015年首次對卷積網絡推理中的數據共享和并行性進行了深入分析和探索。Guo[2]提出的加速器在214MHz下達到了84.3 GOP/s的峰值性能。2016年,Qiu[3]更深入地探索了使用行緩沖器的加速器。本文提出了一種更高效、更通用的卷積加速器。提出的加速器峰值性能達到153.6GOP/s,僅占用14K LUT、32個DRM和208個APM。本文的章節安排如下,第2節介紹了我們提出的加速器的詳細設計以及基于RISC-V的加速器實現的控制調度方案。第3節給出了實驗結果。
系統設計
整個RISC-V片上系統設計如圖1所示。該系統主要由RISC-V軟核CPU、指令/數據存儲器、總線橋、外圍設備、DMA(直接存儲器訪問)和卷積加速器組成。
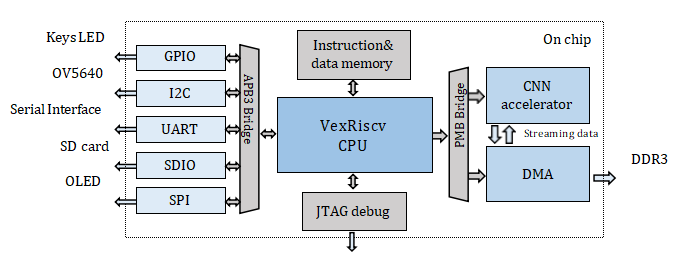
Fig. 1. 片上RISC-V系統設計圖
我們的工作主要在三個方面。首先,我們使用軟核CPU作為片上系統的主控,控制外設,DMA,CNN加速器來實現數據調度和操作。其次,1D(一維)加速器被設計用于改變緩沖機制。第三,為紫光同創的FPGA設備設計了一個DMA IP,用于卷積加速的應用。
A、RISC-V 軟核CPU 架構
軟核。使用RISC-V軟核VexRiscv代替Ibex[4]構建RISC-V的片上系統和面向軟件的方法可以使VexRiscv具有高度的靈活性和可擴展性。
接口。I2C和SPI等外圍設備通過APB3總線連接到RISC-V軟核。DMA和加速器通過PMB總線連接到RISC-V軟核。
指令與數據存儲。程序被交叉編譯以獲得一個特定的文件,該文件由JTAG燒錄到片上指令/數據存儲器中。
B、CNN 加速器結構
輸入緩存。使用乒乓緩存來實現緩沖區,可以有效地提高吞吐量。
輸出緩存。權重緩存模塊由一系列分布式RAM和串行到并行單元組成。
卷積。圖2中的1D卷積模塊分為四組,其中包含四個1D卷曲單元。每個單元負責1D卷積的一個信道。
合并。積分模塊有四組加法器樹。每組加法器樹將每組卷積運算單元的結果相加,得到單向輸出結果。
累加。累加模塊中有四組FIFO和四個加法器。加速器一次只能接收四個通道的輸入特征圖數據。
量化。該量化模塊由乘法單元和移位單元組成。它通過比例變換將24位累加結果重新轉換為8位[5]。
激活。激活功能通過查找由一系列分布式RAM組成的表來實現。它存儲ReLu、Leaky ReLu和sigmoid函數的INT8函數表。
池化。確定當前卷積層是否與池化層級聯,然后決定是否使用池化模塊來完成池化操作。
輸出緩存。輸出緩沖器由FIFO而不是乒乓緩存實現。輸出高速緩存FIFO將結果存儲回片外存儲器,作為下一卷積層的輸入。
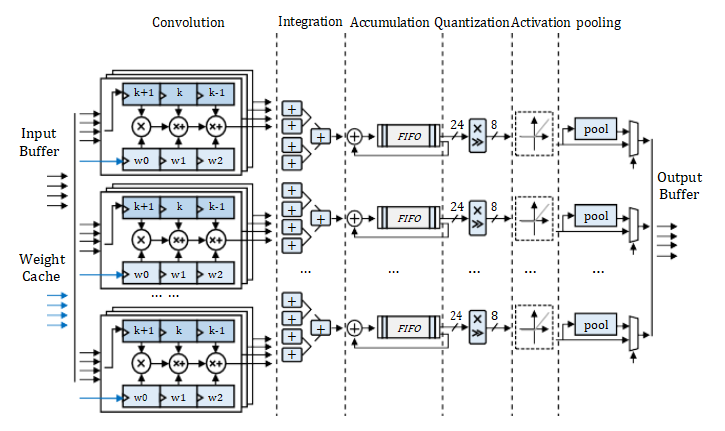
Fig. 2. CNN 加速器實現
C、DMA 結構
神經網絡不僅對計算能力有很高的要求,而且對內存也有很大的需求。中低端FPGA通常需要DDR SRAM(雙數據速率同步動態隨機存取存儲器)來承載整個神經網絡和所有中間運算結果的權重。紫光同創的FPGA的DDR3內存驅動器IP為用戶提供了簡化AXI4總線的內存訪問接口。
由于Simpled AXI和AXI之間的標準差異,需要新的DMA設計。DMA設計如下。讀和寫地址通道由RISC-V軟核直接控制。讀寫數據通道的FIFO用作卷積加速器和DDR3驅動器IP的緩沖器,以完成端口轉換。
D、實現細節
1、一維卷積單元陣列設計
神經網絡不僅對計算能力有很高的要求,而且對內存也有很大的需求。中低端FPGA通常需要DDR SRAM(雙數據速率同步動態隨機存取存儲器)來承載整個神經網絡和所有中間運算結果的權重。紫光同創的FPGA的DDR3內存驅動器IP為用戶提供了簡化AXI4總線的內存訪問接口。
由于Simpled AXI和AXI之間的標準差異,需要新的DMA設計。DMA設計如下。讀和寫地址通道由RISC-V軟核直接控制。讀寫數據通道的FIFO用作卷積加速器和DDR3驅動器IP的緩沖器,以完成端口轉換。
2、卷積加速器控制
本文提出了一種基于指令隊列的設計,以減少RISC-V軟核中DMA和加速器的響應延遲。RISC-V CPU可以連續發送多個存儲器讀寫請求指令和多個操作調度控制指令,而不用等待DMA和加速器的反饋。DMA和加速器從隊列中獲取指令,任務完成后直接從隊列中取出下一條指令,無需等待相應的CPU,從而實現低延遲調度。
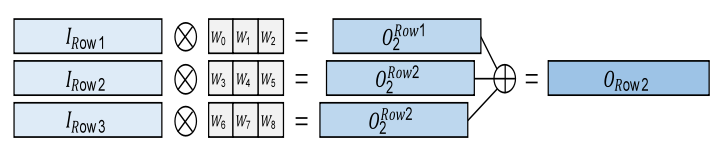
Fig. 3. 1X3 一維卷積原理圖
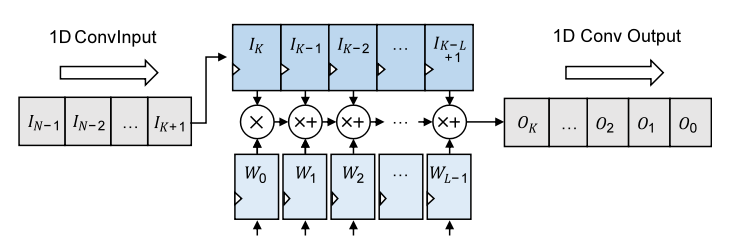
Fig. 4. 一維卷積單元硬件實現
實現結果和備注
通過在PG2L100H和X7Z020上實現相同配置的CNN加速器,完成了CNN加速器的性能測試,驗證了國產FPGA CNN加速方案的可行性。加速器的資源消耗和性能如表I和表II所示。
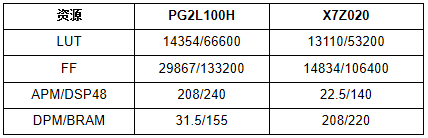
TABLE I 資源利用
PG2L100H和X7Z020的資源消耗相似。PG2L100H需要額外的邏輯資源來構建VexRiscv CPU,而X7Z020為AXI DMA IP使用更多的邏輯資源。就加速器性能而言,可從表II中看出。由于FPGA器件架構的差異,與X7Z020相比,加速器的卷積運算在PG2L100H上只能在200MHz下實現更好的收斂。RISC-V軟核只能在100MHz下實現定時收斂。
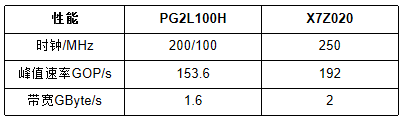
TABLE II 性能對比
我們提出了一種基于RISC-V的一維卷積運算的新設計。該加速器在國內FPGA上的實現和部署已經完成,其性能與具有相同規模硬件資源的國外FPGA相當。
本文論證了基于國產FPGA的CNN異構方案的可行性,該研究是國產FPGA應用生態中CNN加速領域的一次罕見嘗試。
審核編輯 :李倩
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603010 -
存儲器
+關注
關注
38文章
7484瀏覽量
163765 -
RISC-V
+關注
關注
45文章
2270瀏覽量
46131
發布評論請先 登錄
相關推薦
SiFive 推出高性能 Risc-V CPU 開發板 HiFive Premier P550

《RISC-V能否復制Linux 的成功?》
飛凌嵌入式T113-i開發板RISC-V核的實時應用方案

RISC-V發展及FPGA廠商為什么選擇RISC-V

國產RISC-V案例分享,基于全志T113-i異構多核平臺!
國產RISC-V基于全志T113-i異構多核平臺
基于國產異構雙核(RISC-V+FPGA)處理器,AG32開發板開發資料
淺談國產異構雙核RISC-V+FPGA處理器AG32VF407的優勢和應用場景
Imagination CPU 系列研討會 | RISC-V 平臺的性能分析和調試

國產RISC-V MCU推薦
Achronix與Bluespec聯合宣布推出一款支持Linux的RISC-V軟處理器
品讀《基于FPGA與RISC-V的嵌入式系統設計》
瑞薩推出采用自研CPU內核的通用32位RISC-V MCU 加強RISC-V生態系統布局
Imagination:RISC-V CPU的重要力量





 工商網監
工商網監
評論