 AI再卷數學界,DSP新方法將機器證明成功率提高一倍
AI再卷數學界,DSP新方法將機器證明成功率提高一倍
谷歌的吳宇懷 (Yuhuai Tony Wu)等研究者設計了一種叫做「Draft, Sketch, and Prove」 (DSP)的新方法將非形式化的數學證明轉化為形式化的證明。實驗結果顯示,自動證明器在 miniF2F 上解決的問題比例從 20.9% 提高到了 38.9%。
自動證明數學定理是人工智能的一個初衷,也是一直以來的難題。到目前為止,人類數學家使用了兩種不同的方式來書寫數學。
第一種是大家都熟悉的方式,即用自然語言來描述數學證明。大部分的數學都是以這種方式書寫的,這包括數學課本,數學論文,等等。
第二種稱之為形式化數學(formal mathematics)。這是近半個世紀計算機科學家創造的,用來檢驗數學證明的一種工具。
如今看來,計算機可以被用來驗證數學證明,但它們只有在使用專門設計的證明語言時才能做到這一點,而無法處理數學符號和數學家使用的書面文本的混合體。如果把用自然語言編寫的數學問題轉換為形式化代碼,讓計算機更容易解決它們,或許能夠幫助構建能探索數學新發現的機器。這個過程被稱為形式化(formalisation),自動形式化(autoformalization)指的是自動從自然語言數學翻譯成形式化語言的任務。
形式化證明的自動化是一項具有挑戰性的任務,深度學習方法在該領域尚未大獲成功,這主要是因為形式化數據的稀缺。事實上,形式化證明本身是非常困難的,且只有少數專家能做到,這使得大規模的注釋工作并不現實。最大的形式化證明語料庫是用 Isabelle 代碼 (Paulson, 1994) 編寫的,大小不到 0.6GB,比視覺或自然語言處理中常用的數據集小幾個數量級。為了解決形式證明的稀缺性,以往的研究提出使用合成數據、自監督或強化學習來合成額外的形式化訓練數據。雖然這些方法在一定程度上緩解了數據的不足,但都無法將大量人工撰寫的數學證明充分利用起來。
我們以語言模型 Minerva為例。當在足夠多的數據訓練之后,我們發現它的數學能力非常強,可以在高中數學測試中拿到高于平均分水平。然而這樣的語言模型也有不足,它只能模仿,而不能自主訓練而提高數學水平。形式化證明系統提供了一個訓練環境,但形式化數學的數據非常少。
與形式化的數學不同,非形式化的數學數據是豐富和廣泛可用的。最近,在非形式化數學數據上訓練的大型語言模型展示了令人印象深刻的定量推理能力。然而,它們經常產生錯誤的證明,而自動檢測這些證明中的錯誤推理是很有挑戰性的。
在最近的一項工作中,谷歌的吳宇懷 (Yuhuai Tony Wu)等研究者設計了一種叫做 DSP(Draft, Sketch, and Prove )的新方法,將非形式化的數學證明轉化為形式化的證明,從而同時具備形式化系統提供的邏輯嚴謹性和大量的非形式化數據。

論文鏈接:https://arxiv.org/pdf/2210.12283.pdf
今年早些時候,吳宇懷與幾位合作者使用了 OpenAI Codex 的神經網絡進行自動形式化工作,證明了用大型語言模型將非形式化語句自動翻譯成形式化語句的可行性。DSP 則更進一步,利用大型語言模型從非形式化證明中生成形式化證明草圖。證明草圖由高層次的推理步驟組成,可以由交互式定理證明器這樣的形式化系統來解釋。它們與完整的形式化證明不同,因為它們包含無理由的中間猜想的序列。在 DSP 的最后一步,形式化證明草圖被闡述為一個完整的形式化證明,使用一個自動驗證器來證明所有中間猜想。
吳宇懷表示:現在,我們展示了 LLM 可以將其生成的非形式化證明轉化為經過驗證的形式化證明!
方法
方法部分描述了用于形式化證明自動化的 DSP方法,該方法利用非形式化證明來指導自動形式化定理證明器的證明草圖。這里假設每個問題都有一個非形式化命題和一個描述該問題的形式化命題。整體 pipeline 包括三個階段(如圖 1 所示)。
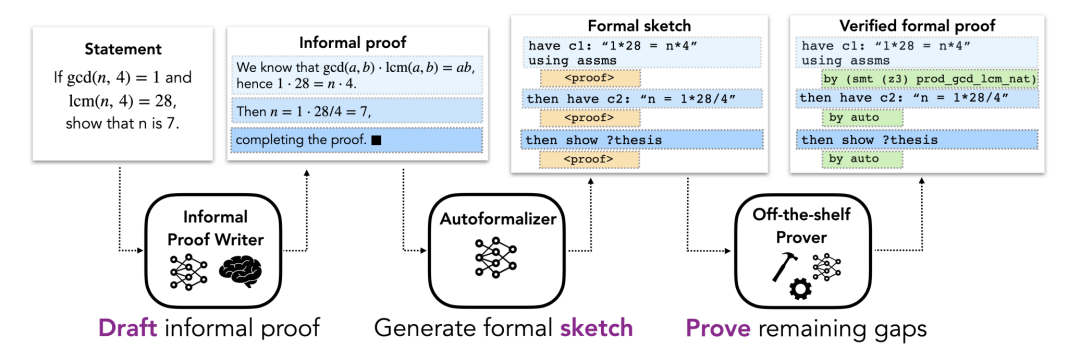
圖 1.
非形式化證明的起草
DSP 方法的初始階段,包括根據問題的自然數學語言描述(可能用 LATEX)為其尋找非形式化證明。由此產生的非形式化證明被看作是后續階段的草稿。在數學教科書中,一般都會提供定理的證明,但有時會缺失或不完整。因此,研究者考慮了與非形式化證明的存在或不存在相對應的兩種情況。
在第一種情況下,研究者假設有一個「真實的」非形式化證明(即由人寫的證明),這是現有數學理論形式化實踐中的典型情況。在第二種情況下,研究者做了一個更普遍的假設,即沒有給出真實的非形式化證明,并且用一個經過非形式化數學數據訓練的大型語言模型來起草證明候選。該語言模型消除了對人類證明的依賴,并能為每個問題產生多種備選解決方案。雖然沒有簡單的方法來自動驗證這些證明的正確性,但非形式化證明只需要在下一階段對生成一個好的形式化證明草圖有用。
將非形式化證明映射為形式化草圖
形式化證明草圖對解決方案的結構進行編碼,并撇開低層次的細節。直觀地說,它是一個部分證明,概述了高層次的猜想命題。圖 2 是一個證明草圖的具體例子。盡管非形式化證明經常撇開低層次的細節,這些細節不能在形式化證明中排出,這使得非形式化證明到形式化證明的直接轉換變得困難。相反,本文建議將非形式化證明映射到共享相同高層結構的形式化證明草圖上。證明草圖中缺少的低層次細節可以由自動證明器來填補。由于大型非形式化 - 形式化平行語料庫不存在,標準的機器翻譯方法不適合這項任務。相反,這里使用一個大型語言模型的小樣本學習能力。具體來說,用了一些包含非形式化證明及其相應的形式化草圖的例子對來 prompt 該模型,然后是一個有待轉換的非形式化證明,然后讓模型生成后續的 token,以獲得所需的形式化草圖。這個模型稱為「自動形式化器」。

圖 2.
證明草圖中的公開猜想
作為這個過程的最后一部分,研究者執行現成的自動證明器來填補證明草圖中缺失的細節,這里的「自動證明器」是指能夠產生形式上可驗證的證明的系統。該框架對自動證明器的具體選擇是不可知的:它可以是符號證明器(如啟發式證明自動化工具)、基于神經網絡的證明器或者混合方法。如果自動證明器成功地填補了證明草圖中的所有空白,它就會返回最終的形式化證明,可以對照問題的規格進行檢查。如果自動證明器失敗(例如,它超過了分配的時間限制),則認為評估是不成功的。
實驗
研究者進行了一系列實驗,包括從 miniF2F 數據集中生成問題的形式化證明,并表明很大一部分定理可以用這種方法自動證明。此處研究了兩種環境,其中非形式化證明是由人類寫的,或者是由一個在數學文本上訓練的大型語言模型起草的。這兩種設置對應于現有理論形式化過程中經常出現的情況,即通常有非形式化證明,但有時作為練習留給讀者,或者由于空白處的限制而缺失。
表 1 展示了在 miniF2F 數據集上發現的成功形式化證明的比例。結果包括本文實驗的四條 baseline,以及帶有人類編寫的證明和模型生成的證明的 DSP 方法。
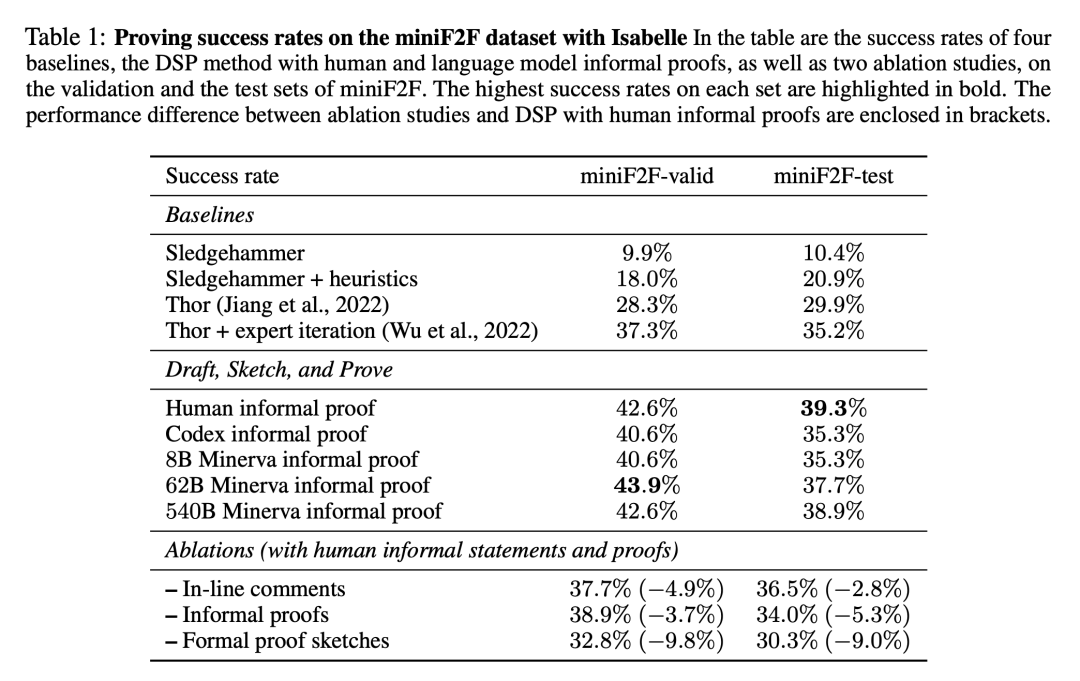
可以看出,附加了 11 種啟發式策略的自動證明器大大增加了 Sledgehammer 的性能,在 miniF2F 的驗證集上將其成功率從 9.9% 提高到 18.0%,在測試集上從 10.4% 提高到 20.9%。兩個使用語言模型和證明搜索的 baseline 在 miniF2F 的測試集上分別達到 29.9% 和 35.2% 的成功率。
基于人類編寫的非形式化證明,DSP 方法在 miniF2F 的驗證和測試集上取得了 42.6% 和 39.3% 的成功率。488 個問題中共有 200 個可以通過這種方式進行證明。Codex 模型和 Minerva(8B)模型在解決 miniF2F 上的問題時給出了非常相似的結果:它們都指導自動驗證器分別解決了驗證集和測試集上 40.6% 和 35.3% 的問題。
當切換到 Minerva(62B)模型時,成功率分別上升到 43.9% 和 37.7%。與人編寫的非形式化證明相比,其在驗證集上的成功率要高 1.3%,在測試集上要低 1.6%。總的來說,Minerva(62B)模型能夠解決 miniF2F 上的 199 個問題,比用人編寫的證明少一個。Minerva(540B)模型在 miniF2F 的驗證集和測試集中分別解決了 42.6% 和 38.9% 的問題,也生成了 199 個成功的證明。
在兩種情況下,DSP 方法都能有效地指導自動證明器:使用人類的非形式化證明或語言模型生成的非形式化證明。DSP 幾乎將證明器的成功率提高了一倍,并在使用 Isabelle 的 miniF2F 上產生了 SOTA 性能。此外,更大的 Minerva 模型在指導自動形式化證明器方面幾乎和人類一樣有幫助。
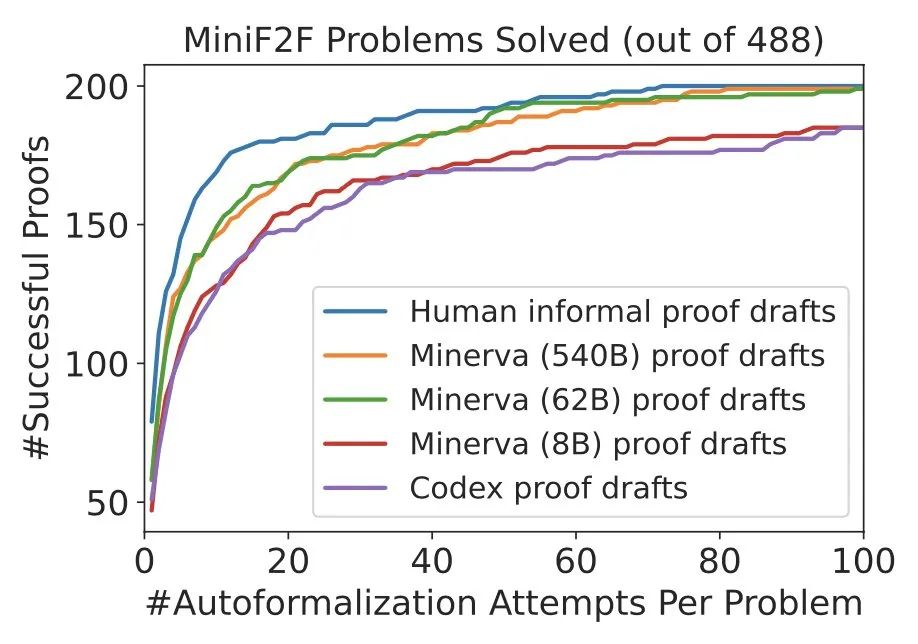
如下圖所示,DSP 方法顯著提高了 Sledgehammer + 啟發式證明器的性能(~20% -> ~40%),在 miniF2F 上實現了新的 SOTA。 Minerva 的 62B 和 540B 版本生成的證明與人類的證明非常相似。
審核編輯 :李倩
-
人工智能
+關注
關注
1799文章
48049瀏覽量
241947 -
語言模型
+關注
關注
0文章
550瀏覽量
10408 -
自然語言處理
+關注
關注
1文章
623瀏覽量
13710
原文標題:AI再卷數學界,DSP新方法將機器證明成功率提高一倍
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大華股份榮獲中國創新方法大賽一等獎
一種降低VIO/VSLAM系統漂移的新方法
大華股份榮獲2024年中國創新方法大賽一等獎

單片集成功率放大器件的工作原理是什么
單片集成功率放大器件的功率通常在多少
用二只OPA548組成功率輸出電路,二只管子的電流工作時一大一小,為什么?
如何提高eCall碰撞測試成功率
實踐JLink 7.62手動增加新MCU型號支持新方法
一種無透鏡成像的新方法

富士康股價飆升一倍,AI服務器需求驅動業績創新高
使隱形可見:新方法可在室溫下探測中紅外光





 工商網監
工商網監
評論