


最近幾年,FPGA這個概念越來越多地出現(xiàn)。例如,比特幣挖礦,就有使用基于FPGA的礦機。還有,之前微軟表示,將在數(shù)據(jù)中心里,使用FPGA“代替”CPU,等等。
其實,對于專業(yè)人士來說,F(xiàn)PGA并不陌生,它一直都被廣泛使用。但是,大部分人還不是太了解它,對它有很多疑問——FPGA到底是什么?為什么要使用它?相比 CPU、GPU、ASIC(專用芯片),F(xiàn)PGA有什么特點?……
今天,帶著這一系列的問題,我們一起來——揭秘FPGA。
一、為什么使用 FPGA?
眾所周知,通用處理器(CPU)的摩爾定律已入暮年,而機器學(xué)習(xí)和 Web 服務(wù)的規(guī)模卻在指數(shù)級增長。
人們使用定制硬件來加速常見的計算任務(wù),然而日新月異的行業(yè)又要求這些定制的硬件可被重新編程來執(zhí)行新類型的計算任務(wù)。
FPGA 正是一種硬件可重構(gòu)的體系結(jié)構(gòu)。它的英文全稱是Field Programmable Gate Array,中文名是現(xiàn)場可編程門陣列。
FPGA常年來被用作專用芯片(ASIC)的小批量替代品,然而近年來在微軟、百度等公司的數(shù)據(jù)中心大規(guī)模部署,以同時提供強大的計算能力和足夠的靈活性。
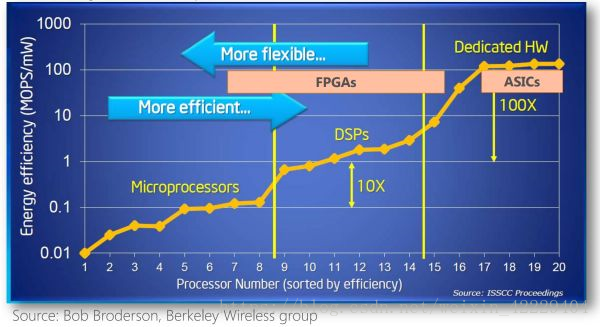
不同體系結(jié)構(gòu)性能和靈活性的比較
FPGA 為什么快?「都是同行襯托得好」。
CPU、GPU 都屬于馮·諾依曼結(jié)構(gòu),指令譯碼執(zhí)行、共享內(nèi)存。FPGA 之所以比 CPU 甚至 GPU 能效高,本質(zhì)上是無指令、無需共享內(nèi)存的體系結(jié)構(gòu)帶來的福利。
馮氏結(jié)構(gòu)中,由于執(zhí)行單元(如 CPU 核)可能執(zhí)行任意指令,就需要有指令存儲器、譯碼器、各種指令的運算器、分支跳轉(zhuǎn)處理邏輯。由于指令流的控制邏輯復(fù)雜,不可能有太多條獨立的指令流,因此 GPU 使用 SIMD(單指令流多數(shù)據(jù)流)來讓多個執(zhí)行單元以同樣的步調(diào)處理不同的數(shù)據(jù),CPU 也支持 SIMD 指令。
而 FPGA 每個邏輯單元的功能在重編程(燒寫)時就已經(jīng)確定,不需要指令。
馮氏結(jié)構(gòu)中使用內(nèi)存有兩種作用。一是保存狀態(tài),二是在執(zhí)行單元間通信。
由于內(nèi)存是共享的,就需要做訪問仲裁;為了利用訪問局部性,每個執(zhí)行單元有一個私有的緩存,這就要維持執(zhí)行部件間緩存的一致性。
對于保存狀態(tài)的需求,F(xiàn)PGA 中的寄存器和片上內(nèi)存(BRAM)是屬于各自的控制邏輯的,無需不必要的仲裁和緩存。
對于通信的需求,F(xiàn)PGA 每個邏輯單元與周圍邏輯單元的連接在重編程(燒寫)時就已經(jīng)確定,并不需要通過共享內(nèi)存來通信。
說了這么多三千英尺高度的話,F(xiàn)PGA 實際的表現(xiàn)如何呢?我們分別來看計算密集型任務(wù)和通信密集型任務(wù)。
計算密集型任務(wù)的例子包括矩陣運算、圖像處理、機器學(xué)習(xí)、壓縮、非對稱加密、Bing 搜索的排序等。這類任務(wù)一般是 CPU 把任務(wù)卸載(offload)給 FPGA 去執(zhí)行。對這類任務(wù),目前我們正在用的 Altera(似乎應(yīng)該叫 Intel 了,我還是習(xí)慣叫 Altera……)Stratix V FPGA 的整數(shù)乘法運算性能與 20 核的 CPU 基本相當(dāng),浮點乘法運算性能與 8 核的 CPU 基本相當(dāng),而比 GPU 低一個數(shù)量級。我們即將用上的下一代 FPGA,Stratix 10,將配備更多的乘法器和硬件浮點運算部件,從而理論上可達到與現(xiàn)在的頂級 GPU 計算卡旗鼓相當(dāng)?shù)挠嬎隳芰Α?/span>
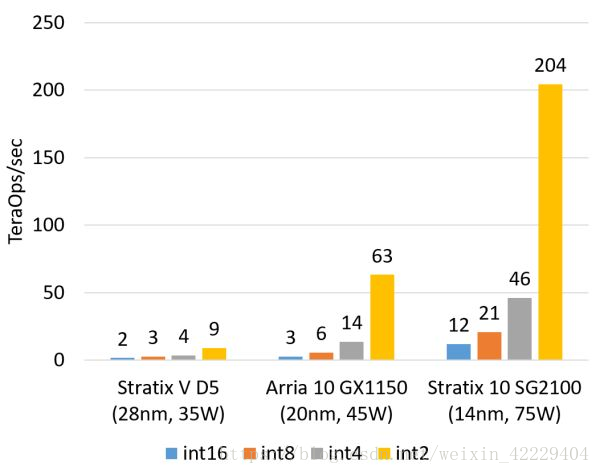
FPGA 的整數(shù)乘法運算能力(估計值,不使用 DSP,根據(jù)邏輯資源占用量估計)
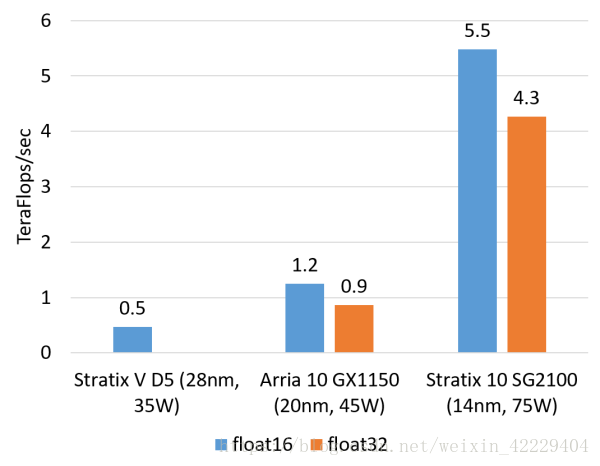
FPGA 的浮點乘法運算能力(估計值,float16 用軟核,float 32 用硬核)
在數(shù)據(jù)中心,F(xiàn)PGA 相比 GPU 的核心優(yōu)勢在于延遲。
像 Bing 搜索排序這樣的任務(wù),要盡可能快地返回搜索結(jié)果,就需要盡可能降低每一步的延遲。
如果使用 GPU 來加速,要想充分利用 GPU 的計算能力,batch size 就不能太小,延遲將高達毫秒量級。
使用 FPGA 來加速的話,只需要微秒級的 PCIe 延遲(我們現(xiàn)在的 FPGA 是作為一塊 PCIe 加速卡)。
未來 Intel 推出通過 QPI 連接的 Xeon + FPGA 之后,CPU 和 FPGA 之間的延遲更可以降到 100 納秒以下,跟訪問主存沒什么區(qū)別了。
FPGA 為什么比 GPU 的延遲低這么多?
這本質(zhì)上是體系結(jié)構(gòu)的區(qū)別。
FPGA 同時擁有流水線并行和數(shù)據(jù)并行,而 GPU 幾乎只有數(shù)據(jù)并行(流水線深度受限)。
例如處理一個數(shù)據(jù)包有 10 個步驟,F(xiàn)PGA 可以搭建一個 10 級流水線,流水線的不同級在處理不同的數(shù)據(jù)包,每個數(shù)據(jù)包流經(jīng) 10 級之后處理完成。每處理完成一個數(shù)據(jù)包,就能馬上輸出。
而 GPU 的數(shù)據(jù)并行方法是做 10 個計算單元,每個計算單元也在處理不同的數(shù)據(jù)包,然而所有的計算單元必須按照統(tǒng)一的步調(diào),做相同的事情(SIMD,Single Instruction Multiple Data)。這就要求 10 個數(shù)據(jù)包必須一起輸入、一起輸出,輸入輸出的延遲增加了。
當(dāng)任務(wù)是逐個而非成批到達的時候,流水線并行比數(shù)據(jù)并行可實現(xiàn)更低的延遲。因此對流式計算的任務(wù),F(xiàn)PGA 比 GPU 天生有延遲方面的優(yōu)勢。
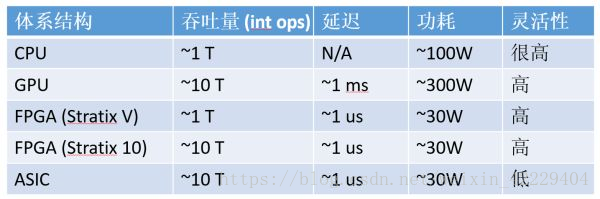
計算密集型任務(wù),CPU、GPU、FPGA、ASIC 的數(shù)量級比較(以 16 位整數(shù)乘法為例,數(shù)字僅為數(shù)量級的估計
ASIC 專用芯片在吞吐量、延遲和功耗三方面都無可指摘,但微軟并沒有采用,出于兩個原因:
數(shù)據(jù)中心的計算任務(wù)是靈活多變的,而 ASIC 研發(fā)成本高、周期長。好不容易大規(guī)模部署了一批某種神經(jīng)網(wǎng)絡(luò)的加速卡,結(jié)果另一種神經(jīng)網(wǎng)絡(luò)更火了,錢就白費了。FPGA 只需要幾百毫秒就可以更新邏輯功能。FPGA 的靈活性可以保護投資,事實上,微軟現(xiàn)在的 FPGA 玩法與最初的設(shè)想大不相同。
數(shù)據(jù)中心是租給不同的租戶使用的,如果有的機器上有神經(jīng)網(wǎng)絡(luò)加速卡,有的機器上有 Bing 搜索加速卡,有的機器上有網(wǎng)絡(luò)虛擬化加速卡,任務(wù)的調(diào)度和服務(wù)器的運維會很麻煩。使用 FPGA 可以保持?jǐn)?shù)據(jù)中心的同構(gòu)性。
接下來看通信密集型任務(wù)。
相比計算密集型任務(wù),通信密集型任務(wù)對每個輸入數(shù)據(jù)的處理不甚復(fù)雜,基本上簡單算算就輸出了,這時通信往往會成為瓶頸。對稱加密、防火墻、網(wǎng)絡(luò)虛擬化都是通信密集型的例子。
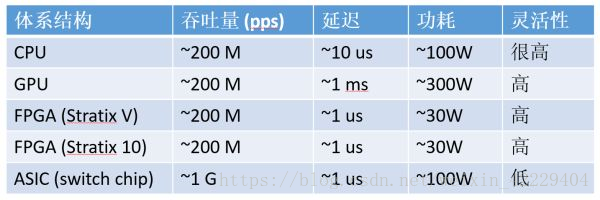
通信密集型任務(wù),CPU、GPU、FPGA、ASIC 的數(shù)量級比較(以 64 字節(jié)網(wǎng)絡(luò)數(shù)據(jù)包處理為例,數(shù)字僅為數(shù)量級的估計)
對通信密集型任務(wù),F(xiàn)PGA 相比 CPU、GPU 的優(yōu)勢就更大了。
從吞吐量上講,F(xiàn)PGA 上的收發(fā)器可以直接接上 40 Gbps 甚至 100 Gbps 的網(wǎng)線,以線速處理任意大小的數(shù)據(jù)包;而 CPU 需要從網(wǎng)卡把數(shù)據(jù)包收上來才能處理,很多網(wǎng)卡是不能線速處理 64 字節(jié)的小數(shù)據(jù)包的。盡管可以通過插多塊網(wǎng)卡來達到高性能,但 CPU 和主板支持的 PCIe 插槽數(shù)量往往有限,而且網(wǎng)卡、交換機本身也價格不菲。
從延遲上講,網(wǎng)卡把數(shù)據(jù)包收到 CPU,CPU 再發(fā)給網(wǎng)卡,即使使用 DPDK 這樣高性能的數(shù)據(jù)包處理框架,延遲也有 4~5 微秒。更嚴(yán)重的問題是,通用 CPU 的延遲不夠穩(wěn)定。例如當(dāng)負(fù)載較高時,轉(zhuǎn)發(fā)延遲可能升到幾十微秒甚至更高(如下圖所示);現(xiàn)代操作系統(tǒng)中的時鐘中斷和任務(wù)調(diào)度也增加了延遲的不確定性。
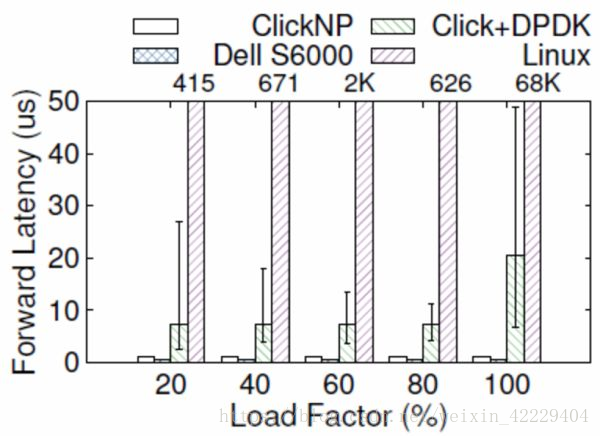
ClickNP(FPGA)與 Dell S6000 交換機(商用交換機芯片)、Click+DPDK(CPU)和 Linux(CPU)的轉(zhuǎn)發(fā)延遲比較,error bar 表示 5% 和 95%。來源:[5]
雖然 GPU 也可以高性能處理數(shù)據(jù)包,但 GPU 是沒有網(wǎng)口的,意味著需要首先把數(shù)據(jù)包由網(wǎng)卡收上來,再讓 GPU 去做處理。這樣吞吐量受到 CPU 和/或網(wǎng)卡的限制。GPU 本身的延遲就更不必說了。
那么為什么不把這些網(wǎng)絡(luò)功能做進網(wǎng)卡,或者使用可編程交換機呢?ASIC 的靈活性仍然是硬傷。
盡管目前有越來越強大的可編程交換機芯片,比如支持 P4 語言的 Tofino,ASIC 仍然不能做復(fù)雜的有狀態(tài)處理,比如某種自定義的加密算法。
綜上,在數(shù)據(jù)中心里 FPGA 的主要優(yōu)勢是穩(wěn)定又極低的延遲,適用于流式的計算密集型任務(wù)和通信密集型任務(wù)。
二、微軟部署 FPGA 的實踐
2016 年 9 月,《連線》(Wired)雜志發(fā)表了一篇《微軟把未來押注在 FPGA 上》的報道 [3],講述了 Catapult 項目的前世今生。
緊接著,Catapult 項目的老大 Doug Burger 在 Ignite 2016 大會上與微軟 CEO Satya Nadella 一起做了 FPGA 加速機器翻譯的演示。
演示的總計算能力是 103 萬 T ops,也就是 1.03 Exa-op,相當(dāng)于 10 萬塊頂級 GPU 計算卡。一塊 FPGA(加上板上內(nèi)存和網(wǎng)絡(luò)接口等)的功耗大約是 30 W,僅增加了整個服務(wù)器功耗的十分之一。
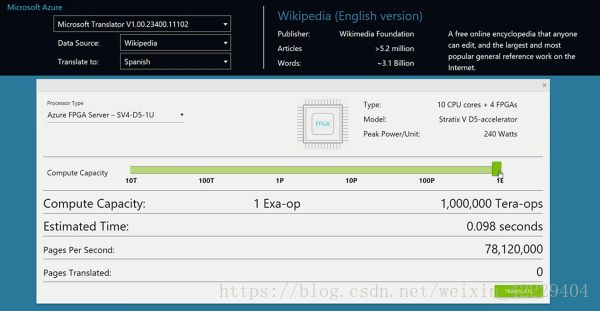
Ignite 2016 上的演示:每秒 1 Exa-op (10^18) 的機器翻譯運算能力
微軟部署 FPGA 并不是一帆風(fēng)順的。對于把 FPGA 部署在哪里這個問題,大致經(jīng)歷了三個階段:
專用的 FPGA 集群,里面插滿了 FPGA
每臺機器一塊 FPGA,采用專用網(wǎng)絡(luò)連接
每臺機器一塊 FPGA,放在網(wǎng)卡和交換機之間,共享服務(wù)器網(wǎng)絡(luò)
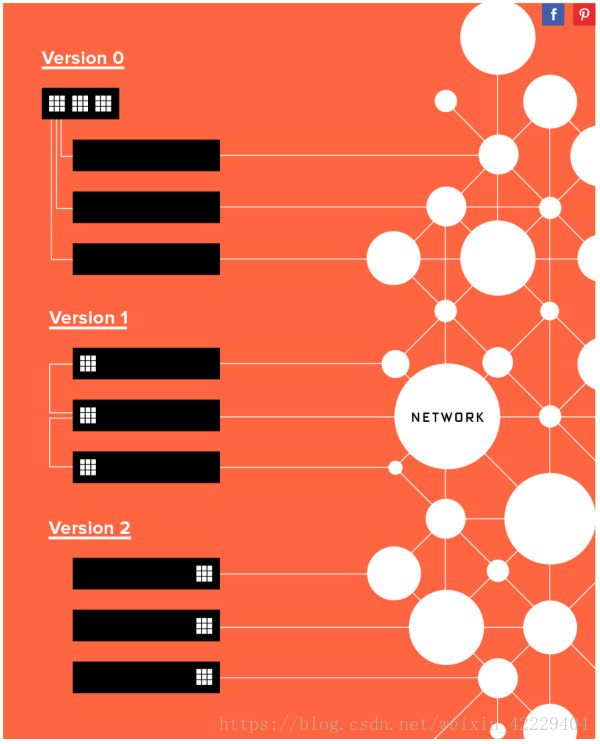
微軟 FPGA 部署方式的三個階段,來源:[3]
第一個階段是專用集群,里面插滿了 FPGA 加速卡,就像是一個 FPGA 組成的超級計算機。
下圖是最早的 BFB 實驗板,一塊 PCIe 卡上放了 6 塊 FPGA,每臺 1U 服務(wù)器上又插了 4 塊 PCIe 卡。

最早的 BFB 實驗板,上面放了 6 塊 FPGA。來源:[1]
可以注意到該公司的名字。在半導(dǎo)體行業(yè),只要批量足夠大,芯片的價格都將趨向于沙子的價格。據(jù)傳聞,正是由于該公司不肯給「沙子的價格」 ,才選擇了另一家公司。
當(dāng)然現(xiàn)在數(shù)據(jù)中心領(lǐng)域用兩家公司 FPGA 的都有。只要規(guī)模足夠大,對 FPGA 價格過高的擔(dān)心將是不必要的。
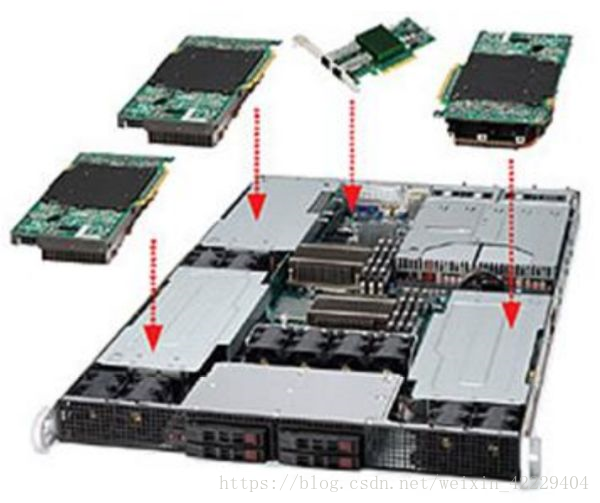
最早的 BFB 實驗板,1U 服務(wù)器上插了 4 塊 FPGA 卡。來源:[1]
像超級計算機一樣的部署方式,意味著有專門的一個機柜全是上圖這種裝了 24 塊 FPGA 的服務(wù)器(下圖左)。
這種方式有幾個問題:
不同機器的 FPGA 之間無法通信,F(xiàn)PGA 所能處理問題的規(guī)模受限于單臺服務(wù)器上 FPGA 的數(shù)量;
數(shù)據(jù)中心里的其他機器要把任務(wù)集中發(fā)到這個機柜,構(gòu)成了 in-cast,網(wǎng)絡(luò)延遲很難做到穩(wěn)定。
FPGA 專用機柜構(gòu)成了單點故障,只要它一壞,誰都別想加速了;
裝 FPGA 的服務(wù)器是定制的,冷卻、運維都增加了麻煩。

部署 FPGA 的三種方式,從中心化到分布式。來源:[1]
一種不那么激進的方式是,在每個機柜一面部署一臺裝滿 FPGA 的服務(wù)器(上圖中)。這避免了上述問題 (2)(3),但 (1)(4) 仍然沒有解決。
第二個階段,為了保證數(shù)據(jù)中心中服務(wù)器的同構(gòu)性(這也是不用 ASIC 的一個重要原因),在每臺服務(wù)器上插一塊 FPGA(上圖右),F(xiàn)PGA 之間通過專用網(wǎng)絡(luò)連接。這也是微軟在 ISCA'14 上所發(fā)表論文采用的部署方式。

Open Compute Server 在機架中。來源:[1]

Open Compute Server 內(nèi)景。紅框是放 FPGA 的位置。來源:[1]

插入 FPGA 后的 Open Compute Server。來源:[1]

FPGA 與 Open Compute Server 之間的連接與固定。來源:[1]
FPGA 采用 Stratix V D5,有 172K 個 ALM,2014 個 M20K 片上內(nèi)存,1590 個 DSP。板上有一個 8GB DDR3-1333 內(nèi)存,一個 PCIe Gen3 x8 接口,兩個 10 Gbps 網(wǎng)絡(luò)接口。一個機柜之間的 FPGA 采用專用網(wǎng)絡(luò)連接,一組 10G 網(wǎng)口 8 個一組連成環(huán),另一組 10G 網(wǎng)口 6 個一組連成環(huán),不使用交換機。
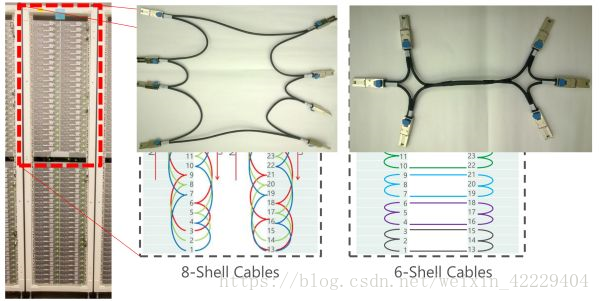
機柜中 FPGA 之間的網(wǎng)絡(luò)連接方式。來源:[1]
這樣一個 1632 臺服務(wù)器、1632 塊 FPGA 的集群,把 Bing 的搜索結(jié)果排序整體性能提高到了 2 倍(換言之,節(jié)省了一半的服務(wù)器)。
如下圖所示,每 8 塊 FPGA 穿成一條鏈,中間用前面提到的 10 Gbps 專用網(wǎng)線來通信。這 8 塊 FPGA 各司其職,有的負(fù)責(zé)從文檔中提取特征(黃色),有的負(fù)責(zé)計算特征表達式(綠色),有的負(fù)責(zé)計算文檔的得分(紅色)。
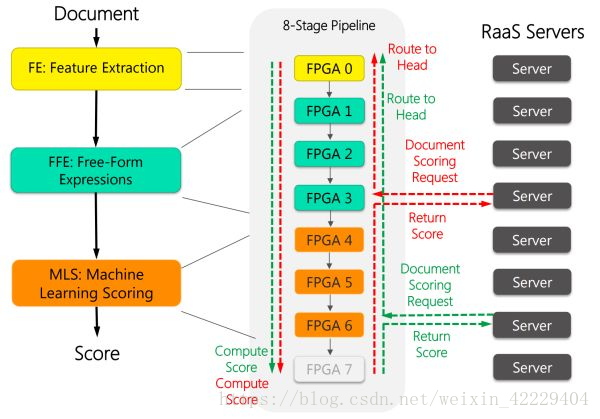
FPGA 加速 Bing 的搜索排序過程。來源:[1]
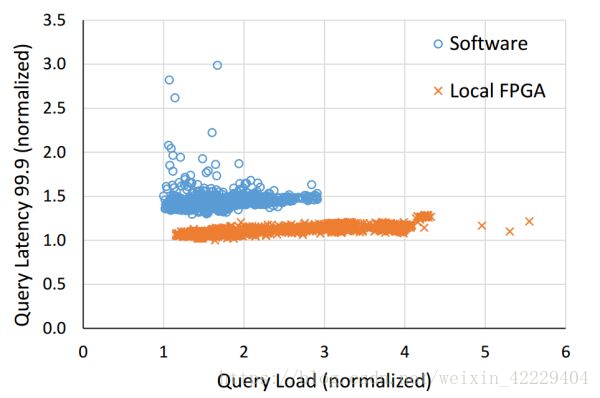
FPGA 不僅降低了 Bing 搜索的延遲,還顯著提高了延遲的穩(wěn)定性。來源:[4]
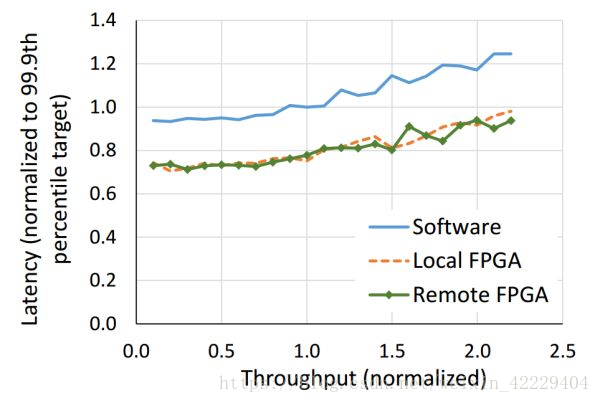
本地和遠程的 FPGA 均可以降低搜索延遲,遠程 FPGA 的通信延遲相比搜索延遲可忽略。來源:[4]
FPGA 在 Bing 的部署取得了成功,Catapult 項目繼續(xù)在公司內(nèi)擴張。
微軟內(nèi)部擁有最多服務(wù)器的,就是云計算 Azure 部門了。
zure 部門急需解決的問題是網(wǎng)絡(luò)和存儲虛擬化帶來的開銷。Azure 把虛擬機賣給客戶,需要給虛擬機的網(wǎng)絡(luò)提供防火墻、負(fù)載均衡、隧道、NAT 等網(wǎng)絡(luò)功能。由于云存儲的物理存儲跟計算節(jié)點是分離的,需要把數(shù)據(jù)從存儲節(jié)點通過網(wǎng)絡(luò)搬運過來,還要進行壓縮和加密。
在 1 Gbps 網(wǎng)絡(luò)和機械硬盤的時代,網(wǎng)絡(luò)和存儲虛擬化的 CPU 開銷不值一提。隨著網(wǎng)絡(luò)和存儲速度越來越快,網(wǎng)絡(luò)上了 40 Gbps,一塊 SSD 的吞吐量也能到 1 GB/s,CPU 漸漸變得力不從心了。
例如 Hyper-V 虛擬交換機只能處理 25 Gbps 左右的流量,不能達到 40 Gbps 線速,當(dāng)數(shù)據(jù)包較小時性能更差;AES-256 加密和 SHA-1 簽名,每個 CPU 核只能處理 100 MB/s,只是一塊 SSD 吞吐量的十分之一。

網(wǎng)絡(luò)隧道協(xié)議、防火墻處理 40 Gbps 需要的 CPU 核數(shù)。來源:[5]
為了加速網(wǎng)絡(luò)功能和存儲虛擬化,微軟把 FPGA 部署在網(wǎng)卡和交換機之間。
如下圖所示,每個 FPGA 有一個 4 GB DDR3-1333 DRAM,通過兩個 PCIe Gen3 x8 接口連接到一個 CPU socket(物理上是 PCIe Gen3 x16 接口,因為 FPGA 沒有 x16 的硬核,邏輯上當(dāng)成兩個 x8 的用)。物理網(wǎng)卡(NIC)就是普通的 40 Gbps 網(wǎng)卡,僅用于宿主機與網(wǎng)絡(luò)之間的通信。
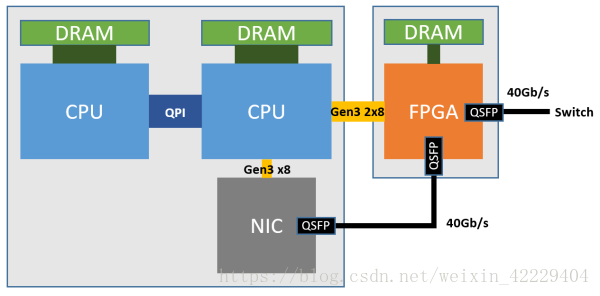
Azure 服務(wù)器部署 FPGA 的架構(gòu)。來源:[6]
FPGA(SmartNIC)對每個虛擬機虛擬出一塊網(wǎng)卡,虛擬機通過 SR-IOV 直接訪問這塊虛擬網(wǎng)卡。原本在虛擬交換機里面的數(shù)據(jù)平面功能被移到了 FPGA 里面,虛擬機收發(fā)網(wǎng)絡(luò)數(shù)據(jù)包均不需要 CPU 參與,也不需要經(jīng)過物理網(wǎng)卡(NIC)。這樣不僅節(jié)約了可用于出售的 CPU 資源,還提高了虛擬機的網(wǎng)絡(luò)性能(25 Gbps),把同數(shù)據(jù)中心虛擬機之間的網(wǎng)絡(luò)延遲降低了 10 倍。
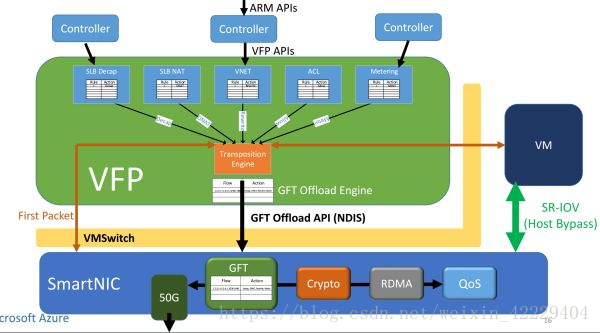
網(wǎng)絡(luò)虛擬化的加速架構(gòu)。來源:[6]
這就是微軟部署 FPGA 的第三代架構(gòu),也是目前「每臺服務(wù)器一塊 FPGA」大規(guī)模部署所采用的架構(gòu)。
FPGA 復(fù)用主機網(wǎng)絡(luò)的初心是加速網(wǎng)絡(luò)和存儲,更深遠的影響則是把 FPGA 之間的網(wǎng)絡(luò)連接擴展到了整個數(shù)據(jù)中心的規(guī)模,做成真正 cloud-scale 的「超級計算機」。
第二代架構(gòu)里面,F(xiàn)PGA 之間的網(wǎng)絡(luò)連接局限于同一個機架以內(nèi),F(xiàn)PGA 之間專網(wǎng)互聯(lián)的方式很難擴大規(guī)模,通過 CPU 來轉(zhuǎn)發(fā)則開銷太高。
第三代架構(gòu)中,F(xiàn)PGA 之間通過 LTL (Lightweight Transport Layer) 通信。同一機架內(nèi)延遲在 3 微秒以內(nèi);8 微秒以內(nèi)可達 1000 塊 FPGA;20 微秒可達同一數(shù)據(jù)中心的所有 FPGA。第二代架構(gòu)盡管 8 臺機器以內(nèi)的延遲更低,但只能通過網(wǎng)絡(luò)訪問 48 塊 FPGA。為了支持大范圍的 FPGA 間通信,第三代架構(gòu)中的 LTL 還支持 PFC 流控協(xié)議和 DCQCN 擁塞控制協(xié)議。
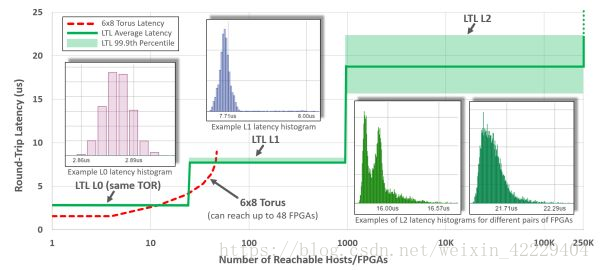
縱軸:LTL 的延遲,橫軸:可達的 FPGA 數(shù)量。來源:[4]
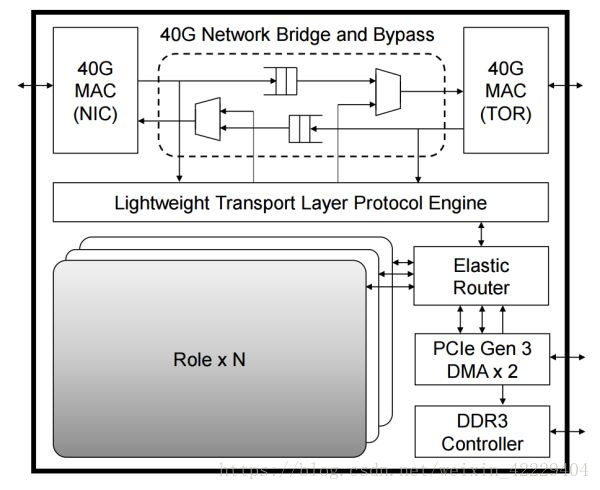
FPGA 內(nèi)的邏輯模塊關(guān)系,其中每個 Role 是用戶邏輯(如 DNN 加速、網(wǎng)絡(luò)功能加速、加密),外面的部分負(fù)責(zé)各個 Role 之間的通信及 Role 與外設(shè)之間的通信。來源:[4]
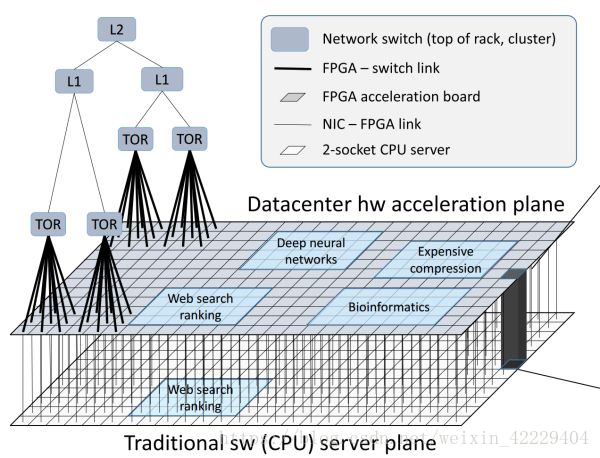
FPGA 構(gòu)成的數(shù)據(jù)中心加速平面,介于網(wǎng)絡(luò)交換層(TOR、L1、L2)和傳統(tǒng)服務(wù)器軟件(CPU 上運行的軟件)之間。來源:[4]
通過高帶寬、低延遲的網(wǎng)絡(luò)互聯(lián)的 FPGA 構(gòu)成了介于網(wǎng)絡(luò)交換層和傳統(tǒng)服務(wù)器軟件之間的數(shù)據(jù)中心加速平面。
除了每臺提供云服務(wù)的服務(wù)器都需要的網(wǎng)絡(luò)和存儲虛擬化加速,F(xiàn)PGA 上的剩余資源還可以用來加速 Bing 搜索、深度神經(jīng)網(wǎng)絡(luò)(DNN)等計算任務(wù)。
對很多類型的應(yīng)用,隨著分布式 FPGA 加速器的規(guī)模擴大,其性能提升是超線性的。
例如 CNN inference,當(dāng)只用一塊 FPGA 的時候,由于片上內(nèi)存不足以放下整個模型,需要不斷訪問 DRAM 中的模型權(quán)重,性能瓶頸在 DRAM;如果 FPGA 的數(shù)量足夠多,每塊 FPGA 負(fù)責(zé)模型中的一層或者一層中的若干個特征,使得模型權(quán)重完全載入片上內(nèi)存,就消除了 DRAM 的性能瓶頸,完全發(fā)揮出 FPGA 計算單元的性能。
當(dāng)然,拆得過細(xì)也會導(dǎo)致通信開銷的增加。把任務(wù)拆分到分布式 FPGA 集群的關(guān)鍵在于平衡計算和通信。
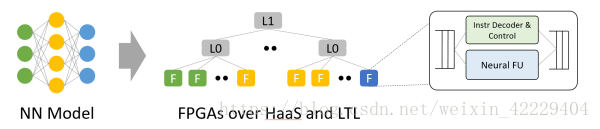
從神經(jīng)網(wǎng)絡(luò)模型到 HaaS 上的 FPGA。利用模型內(nèi)的并行性,模型的不同層、不同特征映射到不同 FPGA。來源:[4]
在 MICRO'16 會議上,微軟提出了 Hardware as a Service (HaaS) 的概念,即把硬件作為一種可調(diào)度的云服務(wù),使得 FPGA 服務(wù)的集中調(diào)度、管理和大規(guī)模部署成為可能。
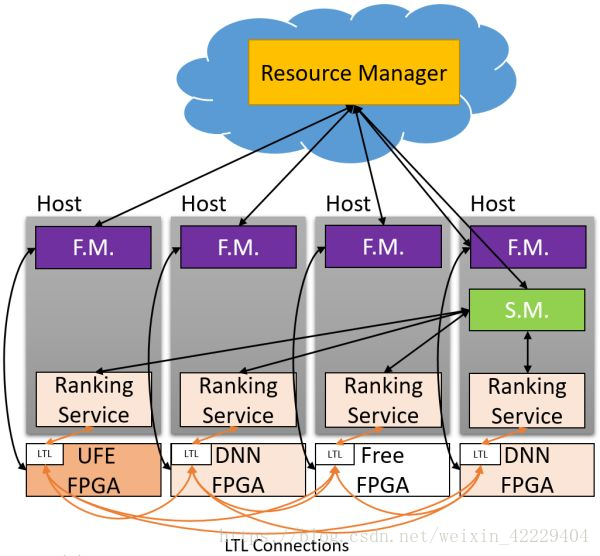
Hardware as a Service (HaaS)。來源:[4]
從第一代裝滿 FPGA 的專用服務(wù)器集群,到第二代通過專網(wǎng)連接的 FPGA 加速卡集群,到目前復(fù)用數(shù)據(jù)中心網(wǎng)絡(luò)的大規(guī)模 FPGA 云,三個思想指導(dǎo)我們的路線:
硬件和軟件不是相互取代的關(guān)系,而是合作的關(guān)系;
必須具備靈活性,即用軟件定義的能力;
必須具備可擴放性(scalability)。
三、FPGA 在云計算中的角色
FPGA 在云規(guī)模的網(wǎng)絡(luò)互連系統(tǒng)中應(yīng)當(dāng)充當(dāng)怎樣的角色?
如何高效、可擴放地對 FPGA + CPU 的異構(gòu)系統(tǒng)進行編程?
我對 FPGA 業(yè)界主要的遺憾是,F(xiàn)PGA 在數(shù)據(jù)中心的主流用法,從除微軟外的互聯(lián)網(wǎng)巨頭,到兩大 FPGA 廠商,再到學(xué)術(shù)界,大多是把 FPGA 當(dāng)作跟 GPU 一樣的計算密集型任務(wù)的加速卡。然而 FPGA 真的很適合做 GPU 的事情嗎?
前面講過,FPGA 和 GPU 最大的區(qū)別在于體系結(jié)構(gòu),F(xiàn)PGA 更適合做需要低延遲的流式處理,GPU 更適合做大批量同構(gòu)數(shù)據(jù)的處理。
由于很多人打算把 FPGA 當(dāng)作計算加速卡來用,兩大 FPGA 廠商推出的高層次編程模型也是基于 OpenCL,模仿 GPU 基于共享內(nèi)存的批處理模式。CPU 要交給 FPGA 做一件事,需要先放進 FPGA 板上的 DRAM,然后告訴 FPGA 開始執(zhí)行,F(xiàn)PGA 把執(zhí)行結(jié)果放回 DRAM,再通知 CPU 去取回。
CPU 和 FPGA 之間本來可以通過 PCIe 高效通信,為什么要到板上的 DRAM 繞一圈?也許是工程實現(xiàn)的問題,我們發(fā)現(xiàn)通過 OpenCL 寫 DRAM、啟動 kernel、讀 DRAM 一個來回,需要 1.8 毫秒。而通過 PCIe DMA 來通信,卻只要 1~2 微秒。
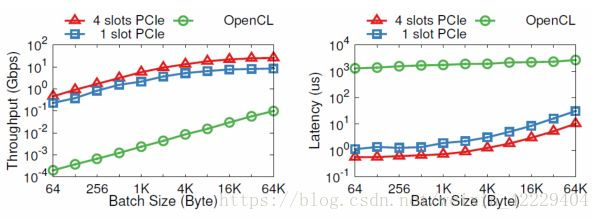
PCIe I/O channel 與 OpenCL 的性能比較。縱坐標(biāo)為對數(shù)坐標(biāo)。來源:[5]
OpenCL 里面多個 kernel 之間的通信就更夸張了,默認(rèn)的方式也是通過共享內(nèi)存。
本文開篇就講,F(xiàn)PGA 比 CPU 和 GPU 能效高,體系結(jié)構(gòu)上的根本優(yōu)勢是無指令、無需共享內(nèi)存。使用共享內(nèi)存在多個 kernel 之間通信,在順序通信(FIFO)的情況下是毫無必要的。況且 FPGA 上的 DRAM 一般比 GPU 上的 DRAM 慢很多。
因此我們提出了 ClickNP 網(wǎng)絡(luò)編程框架 [5],使用管道(channel)而非共享內(nèi)存來在執(zhí)行單元(element/kernel)間、執(zhí)行單元和主機軟件間進行通信。
需要共享內(nèi)存的應(yīng)用,也可以在管道的基礎(chǔ)上實現(xiàn),畢竟 CSP(Communicating Sequential Process)和共享內(nèi)存理論上是等價的嘛。ClickNP 目前還是在 OpenCL 基礎(chǔ)上的一個框架,受到 C 語言描述硬件的局限性(當(dāng)然 HLS 比 Verilog 的開發(fā)效率確實高多了)。理想的硬件描述語言,大概不會是 C 語言吧。
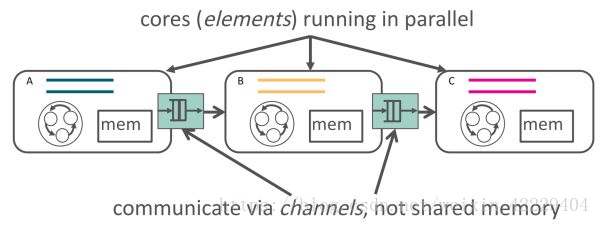
ClickNP 使用 channel 在 elements 間通信,來源:[5]
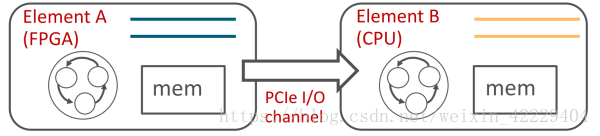
ClickNP 使用 channel 在 FPGA 和 CPU 間通信,來源:[5]
低延遲的流式處理,需要最多的地方就是通信。
然而 CPU 由于并行性的限制和操作系統(tǒng)的調(diào)度,做通信效率不高,延遲也不穩(wěn)定。
此外,通信就必然涉及到調(diào)度和仲裁,CPU 由于單核性能的局限和核間通信的低效,調(diào)度、仲裁性能受限,硬件則很適合做這種重復(fù)工作。因此我的博士研究把 FPGA 定義為通信的「大管家」,不管是服務(wù)器跟服務(wù)器之間的通信,虛擬機跟虛擬機之間的通信,進程跟進程之間的通信,CPU 跟存儲設(shè)備之間的通信,都可以用 FPGA 來加速。
成也蕭何,敗也蕭何。缺少指令同時是 FPGA 的優(yōu)勢和軟肋。
每做一點不同的事情,就要占用一定的 FPGA 邏輯資源。如果要做的事情復(fù)雜、重復(fù)性不強,就會占用大量的邏輯資源,其中的大部分處于閑置狀態(tài)。這時就不如用馮·諾依曼結(jié)構(gòu)的處理器。
數(shù)據(jù)中心里的很多任務(wù)有很強的局部性和重復(fù)性:一部分是虛擬化平臺需要做的網(wǎng)絡(luò)和存儲,這些都屬于通信;另一部分是客戶計算任務(wù)里的,比如機器學(xué)習(xí)、加密解密。
首先把 FPGA 用于它最擅長的通信,日后也許也會像 AWS 那樣把 FPGA 作為計算加速卡租給客戶。
不管通信還是機器學(xué)習(xí)、加密解密,算法都是很復(fù)雜的,如果試圖用 FPGA 完全取代 CPU,勢必會帶來 FPGA 邏輯資源極大的浪費,也會提高 FPGA 程序的開發(fā)成本。更實用的做法是FPGA 和 CPU 協(xié)同工作,局部性和重復(fù)性強的歸 FPGA,復(fù)雜的歸 CPU。
當(dāng)我們用 FPGA 加速了 Bing 搜索、深度學(xué)習(xí)等越來越多的服務(wù);當(dāng)網(wǎng)絡(luò)虛擬化、存儲虛擬化等基礎(chǔ)組件的數(shù)據(jù)平面被 FPGA 把持;當(dāng) FPGA 組成的「數(shù)據(jù)中心加速平面」成為網(wǎng)絡(luò)和服務(wù)器之間的天塹……似乎有種感覺,F(xiàn)PGA 將掌控全局,CPU 上的計算任務(wù)反而變得碎片化,受 FPGA 的驅(qū)使。以往我們是 CPU 為主,把重復(fù)的計算任務(wù)卸載(offload)到 FPGA 上;以后會不會變成 FPGA 為主,把復(fù)雜的計算任務(wù)卸載到 CPU 上呢?隨著 Xeon + FPGA 的問世,古老的 SoC 會不會在數(shù)據(jù)中心煥發(fā)新生?



掃描二維碼獲取
更多精彩

FPGA設(shè)計論壇


歡迎關(guān)注至芯科技
至芯官網(wǎng):www.zxopen.com
至芯科技技術(shù)論壇:www.fpgaw.com
至芯科技淘寶網(wǎng)址:
https://zxopen.taobao.com
至芯科技FPGA初級課程(B站):
https://space.bilibili.com/521850676
至芯科技FPGA在線課程(騰訊課堂):
https://zxopenbj.ke.qq.com/
至芯科技-FPGA 交流群(QQ):282124839
精彩推薦 至芯科技12年不忘初心、再度起航11月12日北京中心FPGA工程師就業(yè)班開課、線上線下多維教學(xué)、歡迎咨詢! FPGA基礎(chǔ)知識 都說FPGA高端,它到底能干啥?詳解六大應(yīng)用領(lǐng)域!掃碼加微信邀請您加入FPGA學(xué)習(xí)交流群

歡迎加入至芯科技FPGA微信學(xué)習(xí)交流群,這里有一群優(yōu)秀的FPGA工程師、學(xué)生、老師、這里FPGA技術(shù)交流學(xué)習(xí)氛圍濃厚、相互分享、相互幫助、叫上小伙伴一起加入吧!
點個在看你最好看
原文標(biāo)題:FPGA與CPU、GPU、ASIC的區(qū)別,F(xiàn)PGA在云計算中的應(yīng)用方案
文章出處:【微信公眾號:FPGA設(shè)計論壇】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
FPGA
+關(guān)注
關(guān)注
1646文章
22061瀏覽量
619311
原文標(biāo)題:FPGA與CPU、GPU、ASIC的區(qū)別,F(xiàn)PGA在云計算中的應(yīng)用方案
文章出處:【微信號:gh_9d70b445f494,微信公眾號:FPGA設(shè)計論壇】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
FPGA在機器學(xué)習(xí)中的具體應(yīng)用
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
fpga和cpu的區(qū)別 芯片是gpu還是CPU
異構(gòu)計算的概念、核心、優(yōu)勢、挑戰(zhàn)及考慮因素
FPGA+GPU+CPU國產(chǎn)化人工智能平臺

ASIC和GPU的原理和優(yōu)勢
FPGA 實時信號處理應(yīng)用 FPGA在圖像處理中的優(yōu)勢
FPGA與ASIC的區(qū)別 FPGA性能優(yōu)化技巧
ASIC集成電路與FPGA的區(qū)別
FPGA和ASIC在大模型推理加速中的應(yīng)用

FPGA與ASIC的優(yōu)缺點比較
FPGA在圖像處理領(lǐng)域的優(yōu)勢有哪些?
FPGA做深度學(xué)習(xí)能走多遠?
自動駕駛?cè)笾髁餍酒軜?gòu)分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論