 介紹兩種高效的參數更新方式LoRA與BitFit
介紹兩種高效的參數更新方式LoRA與BitFit
1 簡介
NLP一個重要的范式包括在通用領域數據上的大規模預訓練和在特定任務或者領域上的微調。目前大規模語言模型在諸多任務上取得sota效果,Finetune全模型參數以適配下游任務雖然能取得不錯的效果,但是卻是一種低效的參數更新方式,歸因于模型的龐大模型參數量帶來的訓練成本,從而限制了在諸多下游任務的應用。
在這個章節我們介紹另外兩種高效的參數更新方式,LoRA與BitFit,一種通過在transformer結構中固定原本的模型參數同時引入可訓練的分解矩陣,另一種通過只更新模型中的bias參數,都能極大程度的減少下游任務需要訓練的參數數量,提高訓練速度并且取得不錯的效果。
2 LoRA
神經網絡包含很多全連接層,借助于矩陣乘法得以實現,很多全連接層的權重矩陣都是滿秩的。當針對特定任務訓練時,預訓練模型具有low intrinsic dimension,盡管隨機投影到較小的子空間,仍然可以有效的學習,可以理解為針對特定任務這些權重矩陣就不要求滿秩。
基于此,LoRA(Low-Rank Adaptaion)被提出,它的想法也很樸素直觀。在原始的PLM旁邊增加一個新的通路,通過前后兩個矩陣A,B相乘,第一個矩陣A負責降維,第二個矩陣B負責升維,中間層維度為r,從而來模擬所謂的intrinsic rank。在下游任務訓練時,固定模型的其他參數,只優化新增的兩個矩陣的權重參數,將PLM跟新增的通路兩部分的結果加起來作為最終的結果(兩邊通路的輸入跟輸出維度是一致的),即h=Wx+BAx。
通常第一個矩陣的A的權重參數會通過高斯函數得到,而第二個矩陣的B的參數則是零矩陣,這樣能保證訓練開始時新增的通路BA=0從而對mo xing 結果沒有影響。在推理時,將左右兩部分的結果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要將訓練完成的矩陣乘積BA跟原本的權重矩陣W加到一起作為新權重參數替換原本PLM的W即可,不會增加額外的計算資源。
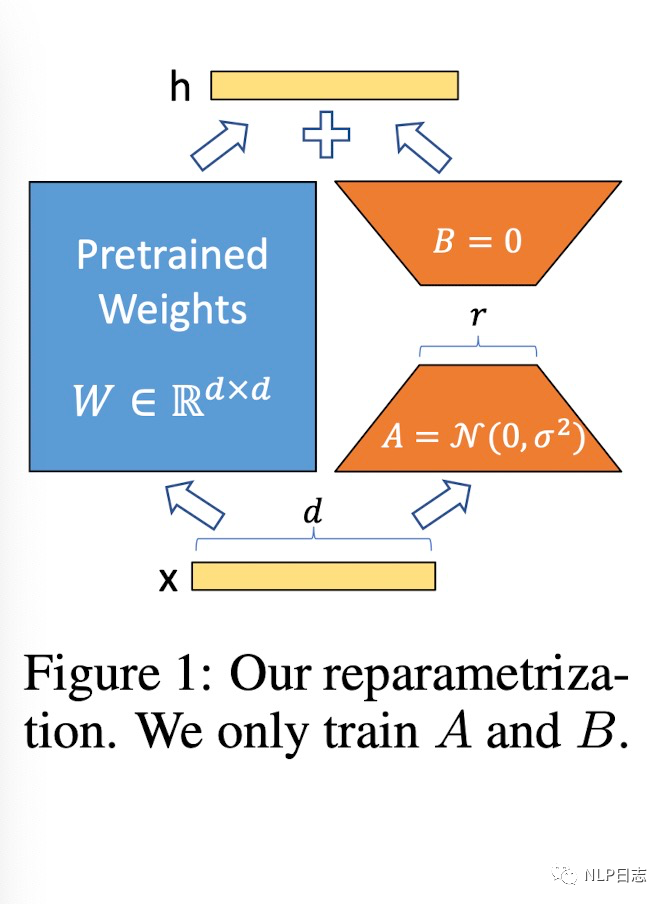
圖1:LoRA框架
一般情況下,r會遠小于模型原本的維度m,所以LoRA訓練的模型參數相比于模型原本的參數而言非常輕量,對于下游任務而言,原本的模型參數可以公攤到多個下游任務中去,每個下游任務只獨立維護自身的LoRA的矩陣BA參數,從而省下了大量內存跟存儲資源。同時,凍結語言模型原本的參數,只更新新增通路的少量參數也能節省大量計算資源跟IO成本,從而提升模型訓練速度。
通過實驗也發現,在眾多數據集上LoRA在只訓練極少量參數的前提下,達到了匹配訓練全部參數的finetune方式,是一種高效的參數更新方法。相比其他高效的參數訓練方式,類似Adapter, BitFit,LoRA在較少訓練參數時就能保證比較穩定的效果。而prefix等方式則會由于插入了更多token導致輸入的分布偏離預訓練數據分布,從而導致精度下降。
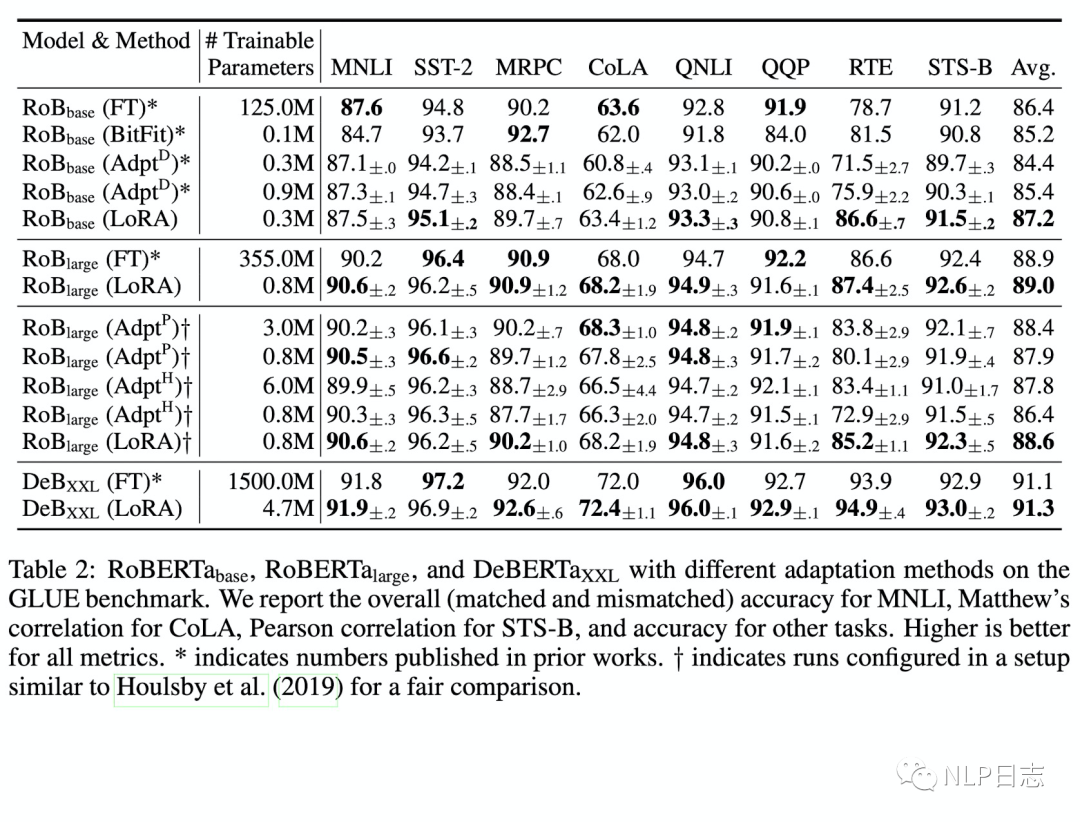
圖2:LoRA的效果
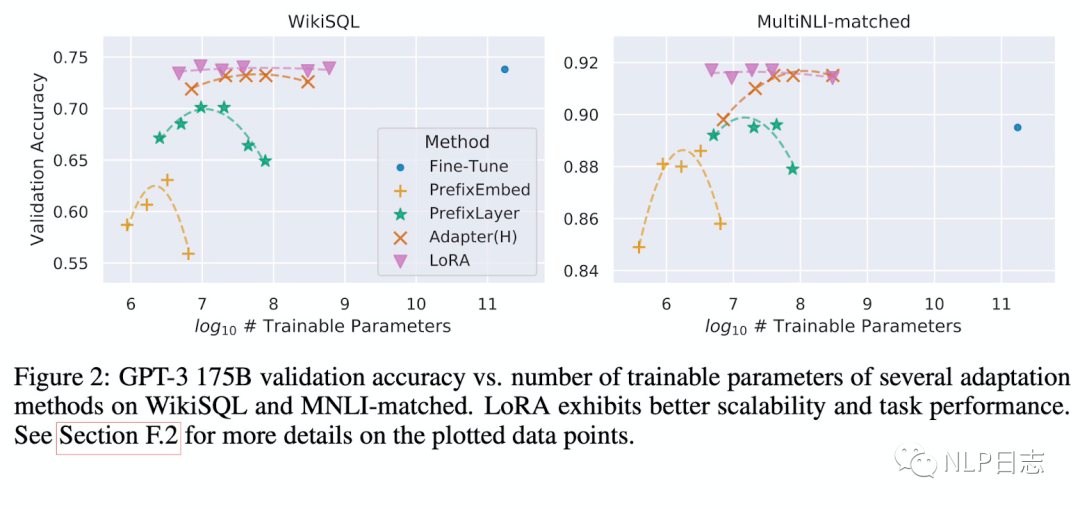
圖3:各種參數更新方法下模型效果跟可訓練參數量的關系
此外,Transformer的權重矩陣包括attention模塊里用于計算query, key, value的Wq,Wk,Wv以及多頭attention的Wo,以及MLP層的權重矩陣,LoRA只應用于attention模塊中的4種權重矩陣,而且通過消融實驗發現其中Wq,Wk兩者不可缺失。同時,保證權重矩陣的種類的數量比起增加隱藏層維度r更為重要,增加r并不一定能覆蓋更加有意義的子空間,這也顯示了低秩的中間矩陣A跟B對于LoRA已經足夠了。
3 BitFit
這是一種稀疏的finetune方法,它只在訓練時更新bias的參數(或者部分bias參數)。對于transformer模型而言,凍結大部分模型參數,只訓練更新bias參數跟特定任務的分類層參數。涉及到的bias參數有attention模塊中計算query,key,value跟合并多個attention結果的涉及到的bias,MLP層中的bias,Layernormalization層的bias參數。像Bert base跟Bert large這種模型里的bias參數占模型全部參數量的0.08%~0.09%。
通過實驗可以看出,Bitfit在只更新極少量參數下在多個數據集上都達到了不錯的效果,雖不及訓練全部參數的finetune,但是遠超固定全部模型參數的Frozen方式。同時,通過比起Bitfit訓練前后的參數對比,發現很多bias參數沒有太多變化,例如跟計算key所涉及到的bias參數。發現其中計算query與將特征維度從N放大到4N的FFN層的bias參數變化最為明顯,只更新這兩類bias參數也能達到不錯的效果,反之,固定其中任何一者,模型的效果都有較大損失。
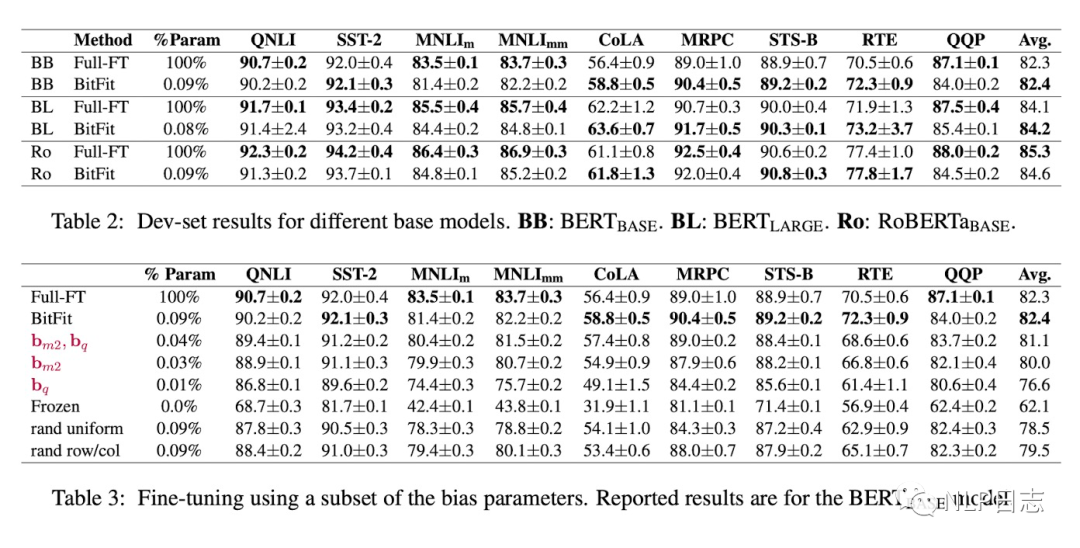
圖4:BitFit效果
4 總結
上述這兩種參數優化方法都是在Adapter之后提出的,相比adapter需要在原模型基礎上加入了額外模塊,雖然減少了訓練成本跟存儲資源,但在推理時卻也不可避免的增加了計算資源從而增加了耗時。但LoRA跟Biffit在推理時跟原語言模型結果保持一致,沒有額外的計算資源。
審核編輯:劉清
-
PLM
+關注
關注
2文章
121瀏覽量
20863 -
LoRa技術
+關注
關注
3文章
101瀏覽量
16328 -
nlp
+關注
關注
1文章
488瀏覽量
22033 -
MLP
+關注
關注
0文章
57瀏覽量
4241
原文標題:Parameter-efficient transfer learning系列之LoRA與BitFit
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
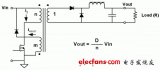
兩種高效能電源設計及拓撲分析
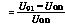





 工商網監
工商網監
評論