 理解Vitis HLS默認行為
理解Vitis HLS默認行為
相比于VivadoHLS,Vitis HLS更加智能化,這體現在Vitis HLS可以自動探測C/C++代碼中可并行執行地部分而無需人工干預添加pragma。另一方面VitisHLS也會根據用戶添加的pragma來判斷是否需要額外配置其他pragma以使用戶pragma生效。為便于說明,我們來看一個簡單的案例。
如下圖所示代碼,函數array_mult用于計算兩個一維數組對應元素差的平方。數組長度為N,故通過N次for循環可完成此操作(這里N為8)。
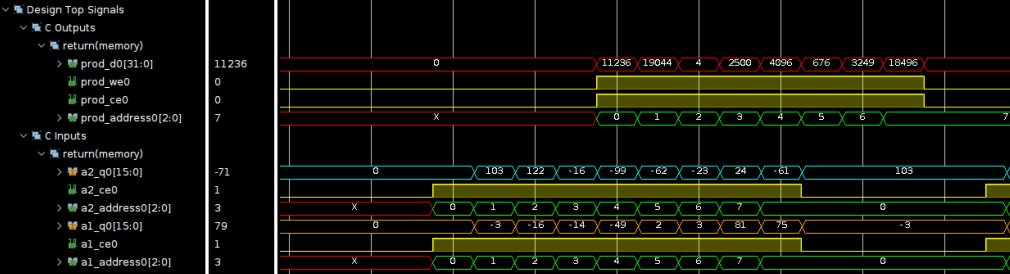
如果我們不添加任何pragma,從C綜合后的報告來看,工具會自動對for循環添加PIPELINE,如下圖所示。同時,工具會將數組映射為單端口RAM(因為數組是頂層函數的形參,故只生成單端口RAM需要的端口信號),這樣匹配了DSP48的接口需求(兩個輸入數據一個輸出數據)。從C/RTLCosim的波形可以看到輸入/輸出數據流關系。

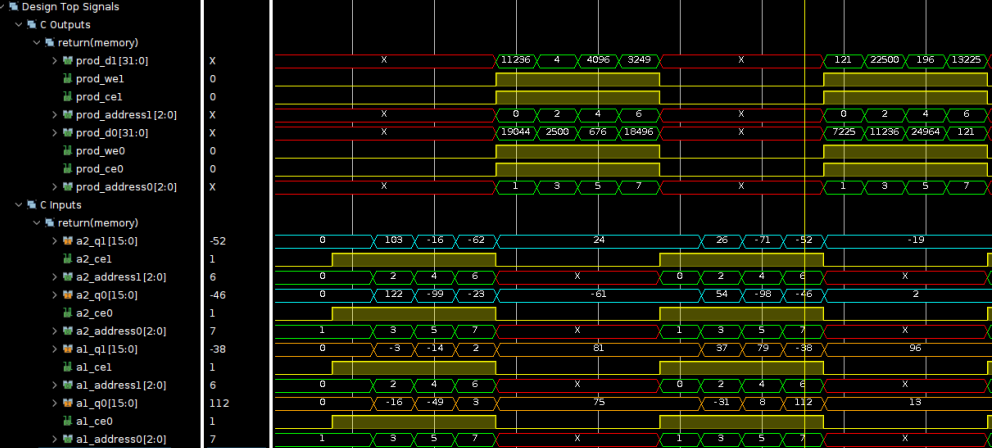
如果我們對for循環施加UNROLL,理論上分析可知工具應將for循環展開(復制8份),這樣會消耗8個DSP48,如下圖所示。這就需要能同時有16個數據提供給這8個DSP48,但此時工具只是將數組映射為雙端口RAM。這顯然造成了數據通路的不匹配。這其實造成了DSP48的浪費。這里,因為數組是頂層函數,故工具并沒有對其施加ARRAY_PARTITION,但如果是子函數的形參,工具就會自動對數組施加ARRAY_PARTITION,以確保數據通路的匹配。

因此,我們換個思路,既然工具至多會將數組映射為雙端口RAM,那么我們就將for循環復制兩份,從而實現數據通路的匹配。這可通過UNROLL的選項factor設置為2。從C綜合報告來看,消耗了2個DSP48,同時工具對for循環自動設置了PIPELINE。

當然,我們也可以對整個函數施加PIPELINE,這樣工具會將for循環自動UNROLL,但這同樣會造成DSP48的浪費,因為工具不會對頂層函數的形參數組自動進行ARRAY_PARTITION。于是,我們考慮手工添加ARRAY_PARTITION,同時對函數添加PIPELINE,從而使得數據通路完美匹配。

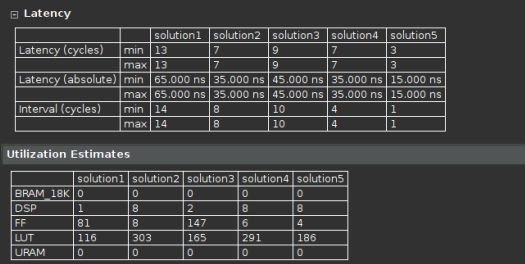
我們對這些Solution進行對比,如下圖所示。solution1消耗資源最少,但Latency最大;solution5消耗資源最多,但Latency最小。
solution1:僅對for循環施加pipeline。
solution2:僅對for循環施加UNROLL。
solution3:僅對for循環施加UNROLL并將factor設置為2。
solution4:僅對函數施加PIPELINE。
solution5:對函數施加PIPELINE,對輸入/輸出數組施加ARRAY_PARTITION(Complete)。
審核編輯:湯梓紅
-
函數
+關注
關注
3文章
4327瀏覽量
62569 -
C++
+關注
關注
22文章
2108瀏覽量
73618 -
HLS
+關注
關注
1文章
129瀏覽量
24097 -
Vitis
+關注
關注
0文章
146瀏覽量
7421
原文標題:理解Vitis HLS默認行為
文章出處:【微信號:Lauren_FPGA,微信公眾號:FPGA技術驛站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA高層次綜合HLS之Vitis HLS知識庫簡析
使用Vitis HLS創建屬于自己的IP相關資料分享
Vivado HLS和Vitis HLS 兩者之間有什么區別
Vitis初探—1.將設計從SDSoC/Vivado HLS遷移到Vitis上的教程
Vitis初探—1.將設計從SDSoC/Vivado HLS遷移到Vitis上
基于Vitis HLS的加速圖像處理
Vitis HLS工具簡介及設計流程
Vitis HLS如何添加HLS導出的.xo文件
Vitis HLS前端現已全面開源
Vitis HLS知識庫總結
HLS最全知識庫
AMD全新Vitis HLS資源現已推出
如何在Vitis HLS GUI中使用庫函數?






 工商網監
工商網監
評論