 采用阿里云倚天實例g8y對深度學習推理性能進行測試和比較
采用阿里云倚天實例g8y對深度學習推理性能進行測試和比較
簡介:本次實測涵蓋圖像分類識別、圖像目標檢測、自然語言處理以及搜索推薦等四種常見的深度學習推理場景
近幾年,深度學習在視覺、自然語言處理、搜索廣告推薦等工業界的各個領域廣泛落地。深度學習模型參數量的指數級上升、以及新的業務對復雜模型的需求,都要求云廠商的彈性計算能夠降低算力成本、提高計算效率,尤其是深度學習的推理,將會成為優化的重點。在此因素影響下,阿里云平頭哥團隊推出了全球首個5nm 制程的 ARM Server 芯片倚天710。該芯片基于 ARM Neoverse N2 架構,支持最新的 ARMv9 指令集,其中包括 i8mm,bf16等擴展指令集,能在科學/AI計算領域獲得性能優勢。
在本文中,我們聚焦于采用倚天710芯片的 ECS倚天實例g8y,對深度學習推理任務的性能進行了測試和比較。
本次分析,我們選擇了四種常見的深度學習推理場景,涵蓋圖像分類識別、圖像目標檢測、自然語言處理以及搜索推薦領域。所使用的代表性模型如下:
| Area | Task | Model |
| Vision | Image Classification | Resnet50-v1.5 and VGG19 |
| Vision | Object Detection | SSD-Resnet34 |
| Language | Natural Language Processing | BERT-Large |
| Recommendation | Click-Through Rate Prediction | DIN |
02 Platforms
實例類型
我們在阿里云兩種實例類型上進行測試,分別是ECS g8y(倚天710) 和 ECS g7(Ice Lake),實例均為 8-vCPU。
Deep Learning Framework
在所有平臺,我們使用 TensorFlow v2.10.0 和 PyTorch 1.12.1。
在 Arm 設備上,TensorFlow 支持兩種后端,我們使用 OneDNN 后端。OneDNN 是一個開源的跨平臺深度學習庫,并且能夠集成 Arm Compute Library(Arm設備的機器學習計算庫)。在 Arm 設備上使用該后端能夠取得更高的性能。
OneDNN 在 PyTorch 上的支持仍然是實驗版本,因此在 PyTorch 框架上使用默認的 OpenBLAS 后端。
BFloat16
BFloat16 (BF16) 是一種浮點數表示形式,其指數位與單精度浮點數(IEEE FP32)保持一致,但是小數位只有 7 位,因此 BF16 的表示范圍與 FP32 幾乎一致,但是精度較低。BF16 非常適合深度學習,因為通常精度下降并不會顯著降低模型的預測精度,但是16位的數據格式卻能夠節省空間、加速計算。
03 TensorFlow Performance Comparison
g8y 借助新的 BF16 指令,大幅提升了深度學習模型的推理性能,在多個場景下跑出了比 g7 更優秀的數據。此外,倚天 710 作為自研芯片,相比 g7 最大有 30% 的價格優勢。
下面四幅圖分別是 Resnet50,SSD,BERT 和 DIN 模型下的對比結果,其中,Resnet,SSD 和 BERT 都來自 MLPerf Inference Benchmark 項目,DIN 是 alibaba 提出的點擊率預測模型。藍色柱狀條是直接性能對比,橙色柱狀條是考慮了單位價格的性能對比,例如在 Resnet50 上,g8y 的性能是 g7 的 1.43倍,單位價格的性能是 g7 的 2.05 倍。
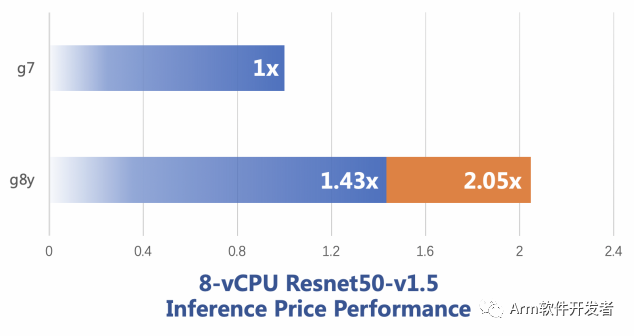
Figure 1: Resnet50 在 g8y 和 g7 上的推理性能對比圖
說明:此處設置 Batch Size = 32,測試圖像尺寸為 224 * 224
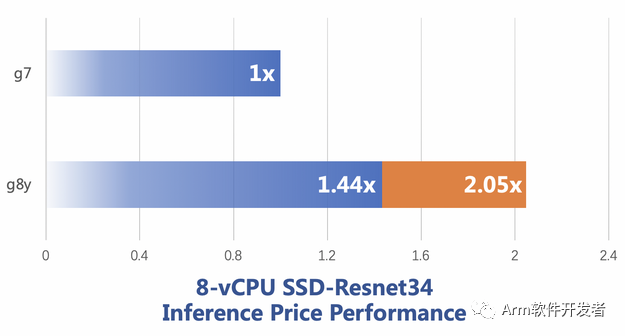
Figure 2: SSD 性能對比圖
說明:此處 Batch Size = 1,測試圖像尺寸為1200 * 1200
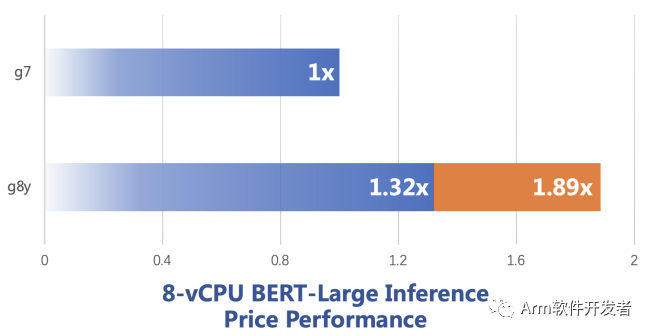
Figure 3: BERT 性能對比圖
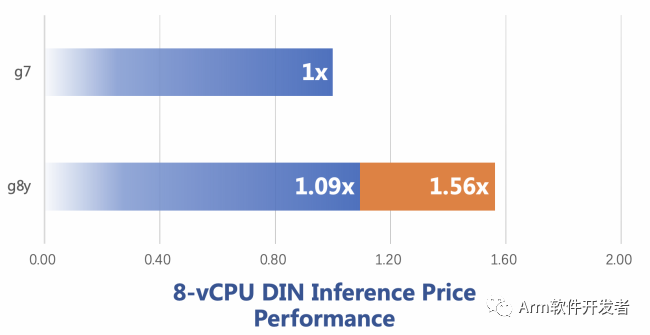
Figure 4: DIN 性能對比圖
04 PyTorch Performance Comparison
Arm 上的 OneDNN 后端的 PyTorch 版本仍然是實驗性質,因此本次實驗采用默認的 OpenBLAS 后端。OpenBLAS 是一個開源的線性代數庫,我們為其添加了針對 Arm Neoverse N2 的 BFloat16 矩陣乘法計算的優化實現。
OpenBLAS BFloat16 矩陣乘法優化
矩陣乘法和深度學習存在非常緊密的關系,例如深度學習中常見的 Fully Connected Layer,Convolutional Layer等,最終是被轉換成矩陣乘法實現的。因此,加速矩陣乘法最終能加速模型的計算。
OpenBLAS 是一個廣泛使用的計算庫,默認作為 Numpy,PyTorch 等庫的后端,我們在調研中發現該庫不支持倚天 710 的 bf16 指令擴展,在和社區交流后,我們決定利用倚天 710 支持的 BFMMLA 等向量指令實現支持 bf16 數據格式的矩陣乘法,實現后性能的到大幅提升,性能對比如圖 5 所示。該實現目前已經貢獻給開源社區,OpenBLAS 的最新版本 0.3.21 也已經合入。
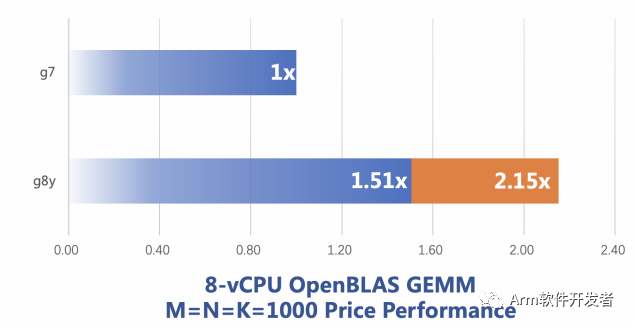
Figure5: OpenBLAS 矩陣乘法性能對比
說明:參與運算的矩陣的行數和列數均為 1000。
PyTorch CNN Performance
OpenBLAS 作為 PyTorch 的默認后端,在矩陣乘法上的優化可以體現在 PyTorch 實現的深度學習模型中,我們以卷積計算占比較高的模型 VGG19 為例,該模型推理時,所有的卷積算子會被轉換為矩陣乘法,并調用 OpenBLAS 完成計算。下圖是 VGG 19 的性能對比:
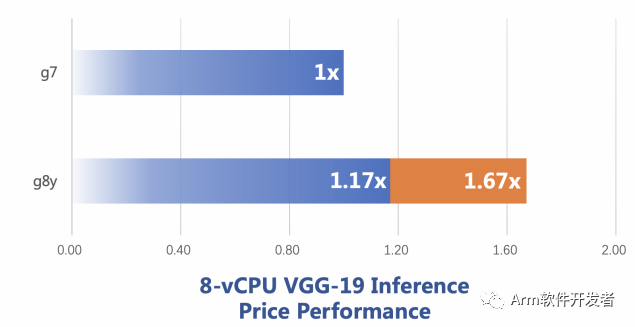
Figure 6: VGG19性能對比圖
05 結論
本文的分析顯示,在阿里云倚天實例g8y上,多個深度學習模型的推理性能高于同規格 g7,這主要得益于 Arm Neoverse N2 的新指令以及不斷更新的軟件支持(OneDNN、ACL 和 OpenBLAS)。在這個過程中,阿里云編譯器團隊貢獻了一部分軟件優化,后續我們將繼續關注該領域的軟硬件優化,提高 Arm 系列實例在 ML/AI 方面的競爭力。
審核編輯:郭婷
-
芯片
+關注
關注
456文章
50892瀏覽量
424341 -
ARM
+關注
關注
134文章
9104瀏覽量
367870 -
深度學習
+關注
關注
73文章
5504瀏覽量
121246
原文標題:性能最高提升50%,ECS倚天實例深度學習推理性能實測
文章出處:【微信號:Arm軟件開發者,微信公眾號:Arm軟件開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
云服務器 Flexus X 實例,鏡像切換與服務器壓力測試
華為云 X 實例 CPU 性能測試詳解與優化策略

使用 Memtester 對華為云 X 實例進行內存性能測試

華為云 Flexus X 實例 MySQL 性能加速評測及對比

Flexus X 實例 CPU、內存及磁盤性能實測與分析
基于哪吒開發板部署YOLOv8模型

開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能

TensorFlow與PyTorch深度學習框架的比較與選擇
學習筆記|如何移植NCNN

飛天技術沙龍回顧:業務創新新選擇,倚天Arm架構深入探討

阿里云倚天710服務器處理器速度超至強
UL Procyon AI 發布圖像生成基準測試,基于Stable Diffusion
阿里云第八代企業級實例g8i搭載第五代英特爾至強可擴展處理器

Torch TensorRT是一個優化PyTorch模型推理性能的工具






 工商網監
工商網監
評論