 用于邊緣設備上機器學習的安全閃存
用于邊緣設備上機器學習的安全閃存
最初,具有所有“無限”功能的云計算似乎消除了對邊緣設備具有任何實質性智能的需求。然而,在過去幾年中,有一種趨勢是在邊緣設備中實施人工智能 (AI) 和機器學習 (ML),以解決數據傳輸延遲、隱私和更大的設備自主性等問題。這為在邊緣設備中構建嵌入式系統帶來了一定的內存要求。本文探討了適用于邊緣設備的某些 ML 方案,以及實現這些設備的非易失性存儲器要求。
為什么在邊緣設備上進行機器學習 (ML)
邊緣設備是生成 ML 數據的地方。物聯網、工業和消費領域的應用從自己的傳感器生成大量數據,并且需要能夠根據人機界面 (HMI) 的命令做出快速決策。傳感器融合技術使在邊緣設備上獲取數據變得更容易、更快、更準確。HMI使人機交互更加用戶友好和自適應。當然,在更接近其來源的 ML 計算引擎中處理數據是有意義的。邊緣計算永遠不會取代云計算;但是,不必將數據傳輸到云,可以更快地訓練機器,并且可以大大減少與云服務器的連接帶寬。
廣泛的物聯網應用可以從提供本地AI處理中受益。圖 1 顯示了 SensiML 的圖表,其中列出了邊緣設備上的 AI 處理示例。
當然,在邊緣設備上實施ML肯定會面臨挑戰。例如,邊緣設備可能依賴電池,因此能源預算有限。它們也可能具有有限的計算能力和/或內存空間。然而,現代MCU技術正在邊緣設備上實現這一目標。如圖2所示,從Barth Development所做的研究中,在過去的幾十年里,我們可以看到,雖然MCU功耗保持相對平穩,但晶體管的數量、時鐘速度、并行內核的數量都在上升。隨著越來越多的高性能、低功耗MCU問世,邊緣計算可以幫助構建智能且用戶友好的系統。
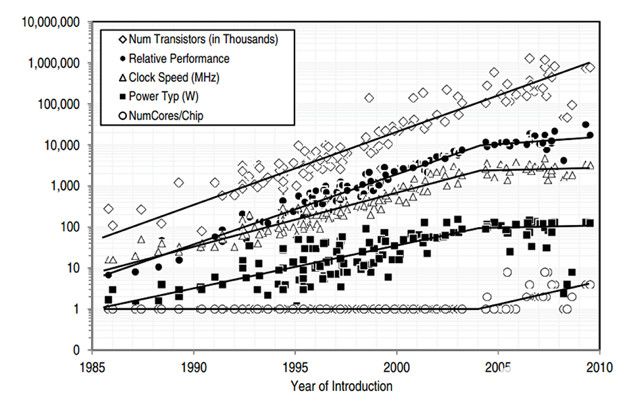
圖2:過去幾年的MCU研究(來源:Barth Development)
機器學習的不同方案
一般來說,ML可以分為兩大類:監督學習和無監督學習。監督學習是指使用“標記”的數據訓練機器,這意味著每個數據樣本都包含特征和答案。通過向機器提供這些標記數據,我們正在訓練它找到特征和答案之間的相關性。訓練后,當我們為機器提供一組新功能時,希望它能得出我們期望的正確答案。例如,可以訓練設備在其視頻源(即相機)捕獲的圖像中查找文本和數字。為了以非常簡化的方式描述該過程,通過給定可能包含也可能不包含文本和數字的圖像以及正確答案(即“標簽”)來訓練設備。訓練后,該設備可以在任何給定的新圖像中查找文本和數字。
另一方面,無監督學習是指向機器提供未“標記”的數據的方法,這意味著每組特征都沒有答案。無監督學習的目標是從所有這些數據中找到隱藏的信息,無論是對數據集進行聚類,還是找到它們之間的關聯。無監督學習的一個例子可能是在生產線末端執行質量控制,從所有其他產品中發現異常產品(即異常檢測)。設備沒有給出“標簽”答案以指示哪些產品異常。通過分析每個產品中的特征,該算法會自動從大多數好產品中識別不良產品,因為設備經過訓練以查看它們之間的差異。
在本文中,我們將嘗試更深入地介紹可以部署在邊緣設備中的監督學習算法。我們將使用一些簡單的數學公式來解釋兩種學習算法之間的差異。
如上所述,監督學習將標記的數據集饋送到正在訓練的設備中。假設每個數據集包含許多特征 x1, x2.。.xn.接下來,為每個特征分配一個系數 q,并記下函數。這稱為假設函數,hq(十):
hq(x) = q0+ 問1 x1 + 問2 x2+ 問3 x3 。.. + qn xn
訓練機器意味著一組適當的q(q0, q1, q2, 。.., qn) 的發現使得假設輸出 hq(x) 盡可能接近給定的答案(標簽)。訓練后,當一組新的特征 X (x1, x2, 。.., xn) 提出,假設函數將給出基于 q 的最優集的輸出。
查找 q 的一種方法是使用梯度下降的線性回歸。以下步驟是此方法的簡化說明:
1.選擇一組初始。..n.然后計算假設和給定答案 Y 之間的差異。這種差異通常稱為成本。
2.不斷向成本小的方向轉變。每次重新計算成本。重復此步驟,直到成本不再降低。
3.如果成本不再降低,我們已經達到了一個最佳集合,為我們提供了所有給定樣品的最低成本。
4.現在,如果給出一組新的X,這組可用于預測輸出。
梯度下降的名稱來自步驟 2 中更改 q 的方法。通過在梯度方向上更新q,該算法保證它將收斂到最佳值。圖 3 顯示了梯度下降的圖形表示,以得到最小成本函數 J(q0, q1)。
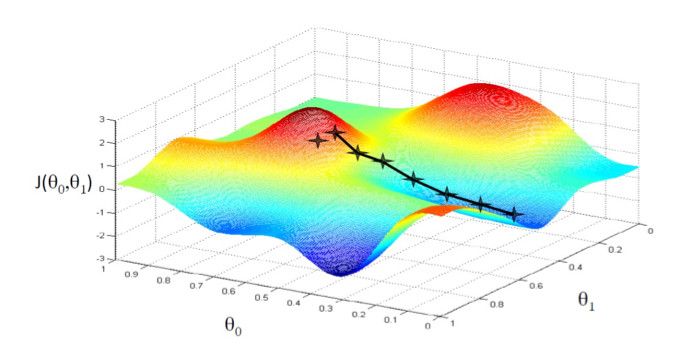
圖 3:梯度下降中的成本函數 J 與參數集 q 的關系
如果在步驟 2 中對所有給定的數據樣本進行成本計算,則該方法稱為批量梯度下降。每次更新 q 時,該算法都會計算所有訓練數據樣本的成本。這種計算方式為如何更改 q 提供了更好的方向。但是,如果給定的訓練數據樣本集很大,則計算所有樣本的成本需要大量的計算能力。此外,系統必須在訓練期間存儲所有數據樣本。
梯度下降的另一種方法是對數據樣本的子集執行步驟 2。這種方法稱為隨機梯度下降。該算法在每次迭代時根據較小的數據樣本集更改 q。此方法可能需要更多迭代才能達到最佳 q,但它節省了大量的計算能力和潛在的時間,因為它不需要計算整個數據樣本集的成本。
使用隨機梯度下降法,用于計算成本的最小樣本數為一個。如果 ML 算法在有新的數據樣本可用時細化 q,我們可以將此 ML 算法視為基于順序數據樣本的持續行為更新。當每個可用的數據樣本進來時,算法會計算新的 q。因此,系統會在每個步驟動態更新假設函數。這種方法也稱為在線梯度下降或在線機器學習。
批量梯度下降與在線機器學習
在批量梯度下降和在線機器學習之間,后者具有適用于邊緣設備的某些特征。
1.無限數據樣本
如前所述,邊緣設備通常配備傳感器或HMI,可以連續提供無窮無盡的數據樣本或人工反饋。因此,在線 ML 算法可以不斷從數據變化中學習并改進假設。
2.算力
邊緣設備通常具有有限的計算能力。對大量數據樣本運行批量梯度下降算法可能不切實際。但是,通過一次計算一個數據樣本,就像在在線機器學習中一樣,MCU 不必具有巨大的計算能力。
3.非易失性(NV)存儲器
批量梯度下降算法要求系統存儲整個訓練集,這些訓練集必須駐留在非易失性存儲中,而在線 ML 算法一次計算一個傳入的數據樣本。在線 ML 算法可能會丟棄數據或僅存儲一小部分樣本,以節省非易失性存儲。這特別適用于非易失性存儲器可能受限的邊緣設備。
4.適應性
想象一下,在線 ML 算法在邊緣設備上執行語音識別。通過新的數據樣本不斷訓練算法,系統可以動態適應特定的用戶和/或口音。
邊緣設備上 ML 的非易失性內存要求
除了MCU,非易失性存儲器是設計進行ML處理的邊緣設備的另一個重要因素。嵌入式閃存是一個顯而易見的選擇,如果MCU為應用軟件提供了足夠的電子閃存。然而,隨著MCU技術節點的不斷縮小,電子閃存變得越來越難以集成。簡而言之,應用軟件的增長超過了可用的電子閃存。在這種情況下,外部獨立NV閃存變得必要。考慮到不同類型NV閃存設備提供的可靠性、讀取吞吐量和就地執行功能,NOR閃存通常是邊緣系統設計人員的首選。
要為 ML 構建安全可靠的邊緣設備,需要考慮許多設計因素。以下是其中的一些,可幫助設計人員決定使用哪種NV存儲器(參見圖4)。
1.安全啟動
所有嵌入式系統都必須安全啟動。對于邊緣設備,安全啟動尤其重要,因為靠近人類訪問,因此存在潛在安全攻擊的風險。通常,對于使用存儲下載 (SnD) 代碼模型的設備,引導代碼存儲在非易失性存儲器中并下載到 RAM 中執行。如果非易失性存儲器不安全,黑客很容易替換或修改啟動代碼進行惡意操作。因此,將引導代碼存儲在安全的非易失性存儲器中并在引導期間建立信任根是邊緣設備非常重要的考慮因素。
2.抗攻擊性
鑒于邊緣設備的連接性,邊緣設備的攻擊面無疑是巨大的。即使使用安全啟動,黑客也可能試圖通過各種攻擊方法從設備中竊取智能機密或隱私信息,例如被動監控、主動重放攻擊、側信道攻擊等。使用能夠抵抗這些攻擊的非易失性存儲器可以大大降低系統暴露的風險。
3.重要AI參數的安全存儲
ML 算法需要參數的內存存儲,例如上面提到的參數集。這些參數是使用大量數據樣本集運行訓練的結果。黑客對AI算法本身可能不感興趣,但最終結果通常是。如果黑客可以從存儲中竊取最終結果,他們可以不經過任何培訓即可模仿AI系統。這些參數(例如參數集)直接影響 ML 方案和系統的智能。因此,它們應存儲在安全的存儲中,黑客不會無意或故意更改。提供這種安全存儲能力的非易失性存儲器將非常適合具有敏感信息要存儲的邊緣設備。
4.吞吐量快
盡管邊緣設備可能不需要強大的MCU來運行廣泛的ML算法,但它們可能仍需要快速訪問非易失性存儲器,以實現快速安全啟動和良好的計算性能。
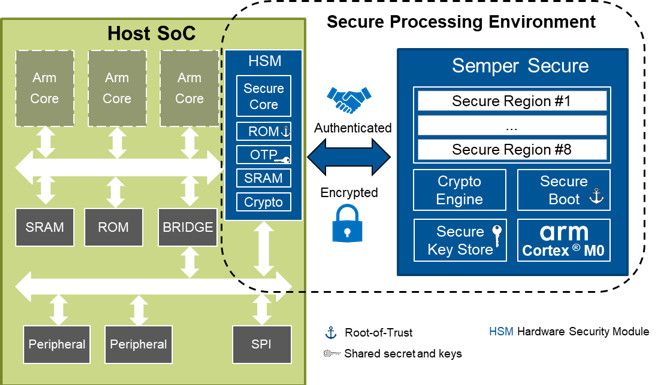
圖 4:使用機器學習的邊緣設備需要支持安全啟動、抵御惡意攻擊、安全存儲和快速吞吐量的非易失性存儲器,如此處所示的 CypressSemper 安全 NOR 閃存。
在邊緣設備中實現智能是一種行業趨勢,以便用戶數據的處理更接近其來源。許多 AI 應用程序可以部署在構建智能和用戶友好系統的邊緣設備上。機器學習算法之一,在線機器學習,不需要廣泛的計算能力,對變化具有很強的適應性,適用于邊緣設備。為了在邊緣設備上構建智能且安全的系統,用戶可以選擇提供信任根功能、安全存儲、快速吞吐量和抗惡意攻擊的非易失性存儲器。
審核編輯:郭婷
-
傳感器
+關注
關注
2550文章
51046瀏覽量
753119 -
物聯網
+關注
關注
2909文章
44578瀏覽量
372857 -
機器學習
+關注
關注
66文章
8408瀏覽量
132573
發布評論請先 登錄
相關推薦
在邊緣設備上設計和部署深度神經網絡的實用框架
AI模型部署邊緣設備的奇妙之旅:如何在邊緣端部署OpenCV
使用機器學習和NVIDIA Jetson邊緣AI和機器人平臺打造機器人導盲犬
邊緣計算與邊緣設備的關系

閃存的哪些扇區可用于用戶數據存儲?
邊緣AI網關,將具備更強大的計算和學習能力
MCX N系列微控制器適用于安全、智能的電機控制和機器學習應用
英飛凌收購Imagimob,擴大AI產品,提升邊緣設備機器學習能
AI邊緣盒子助力安全生產相關等場景

plc邊緣網關如何實現PLC設備數據處理?

人工智能和機器學習的頂級開發板有哪些?

英飛凌科技旗下Imagimob可視化Graph UX改變邊緣機器學習建模
邊緣計算盒子護航企業安全生產,邊緣設備提高安全生產監管效率






 工商網監
工商網監
評論