 如何高效實現矩陣乘?CUDA初學者的角度入門
如何高效實現矩陣乘?CUDA初學者的角度入門
本文將從一個 cuda 初學者的角度來闡述如何優化一個形狀較大的正方形乘正方形的 FP32 矩陣乘。
矩陣乘作為目前神經網絡計算中占比最大的一個部分,其快慢會顯著影響神經網絡的訓練與推斷所消耗的時間。雖然現在市面上已經有非常多的矩陣乘的高效實現——如基于 cpu 的 mkl、基于 arm 設備的 ncnn 與 emll、基于 cuda 的 cublas ——掌握了矩陣乘優化的思路不僅能幫助你更好的理解編寫高性能代碼的一些基本原則,而且許多神經網絡加速領域進階的技巧如算子融合都是與矩陣乘交互從而達到更高的性能。
由于矩陣乘的性能優化與兩個矩陣的形狀有著非常密切的聯系,因此,為了降低本文的撰寫難度(以及輔助讀者更好的理解矩陣乘優化),本文將從一個 cuda 初學者的角度來闡述如何優化一個形狀較大的正方形乘正方形的 FP32 矩陣乘。同時本文按如下順序講解:
-
Goals:本文的目標是什么?
-
樸素 GEMM 與前置知識:簡單介紹一下我們的任務是什么,我們需要提前了解什么。
-
Thread 級優化:在 Thread 這個維度,我們能做什么優化?
-
Warp 級優化:在 Warp 這個維度,我們能做什么優化?
-
Block 級優化:在 Block 這個維度,我們能做什么優化?
-
Epilogue:尾聲。
Goals
首先明確一下本文的目標是:
? 實現一個比 cublas 更快的形狀較大的正方形乘正方形的 FP32 矩陣乘。
? 從理論角度與硬件規格能夠簡單的推導矩陣分塊與排布的方法。
? 可以大致清楚各個優化技術效果的階段性的 benchmark。
? 如何使用 Nsight Compute 等性能分析工具分析潛在的性能瓶頸。
本文不含:
? 使用 Tensor Core 加速矩陣乘。(這也是為什么這篇文章叫傳統 CUDA GEMM)
? 使用安培架構新提出的 async memcpy。
? CUDA 語法知識。
? 匯編。(主要是現在并沒有官方支持匯編的操作,目前的匯編器幾乎都是逆向的產物,不是很穩定。同時匯編帶來的好處如消除寄存器的 bank conflict nvcc 也在不斷的做相應的改進,因此就不介紹了)
開源地址:https://github.com/AyakaGEMM/Hands-on-GEMM
同時本文在相當程度上參考了李少俠的 GEMM 優化指南(寫得非常!非常!非常!不錯),本文的優勢在于補了階段性代碼和在某些少俠一筆帶過的地方做了一些擴展。
Performance
為了讓大家更有動力閱讀下去,這里先放出來性能效果!
測試平臺
? 系統:Arch Linux
? 驅動:520.56.06
?CUDA:11.8
?GPU:Nvidia RTX 2080
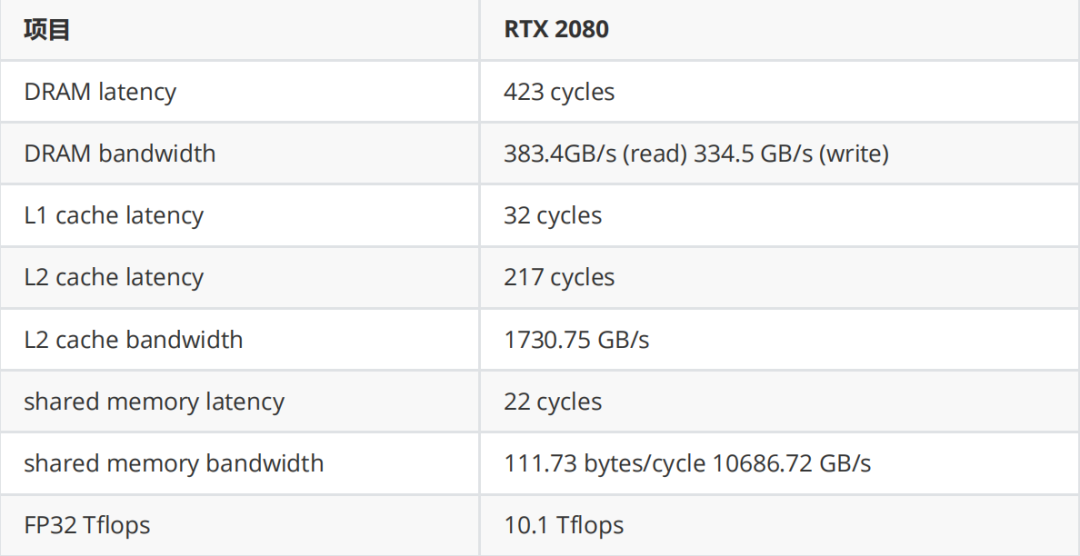
測試結果
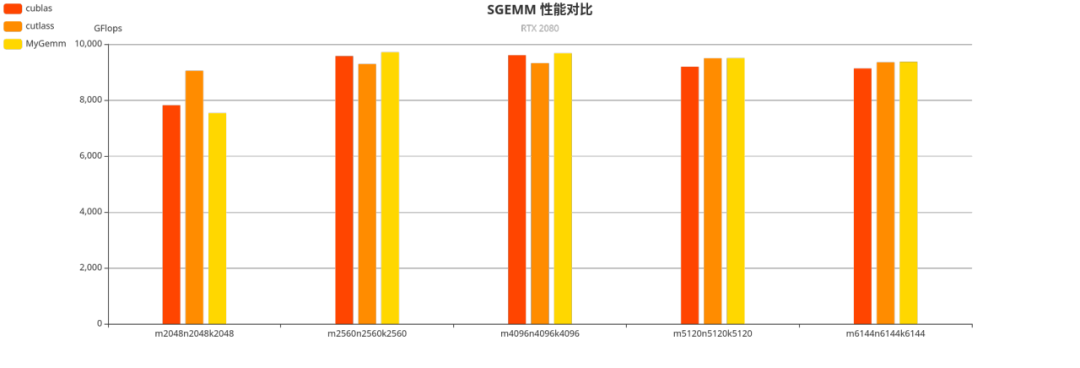
我們也可以注意到,在較大形狀上手寫的矩陣乘有著與 cublas 相近,甚至更優的性能。
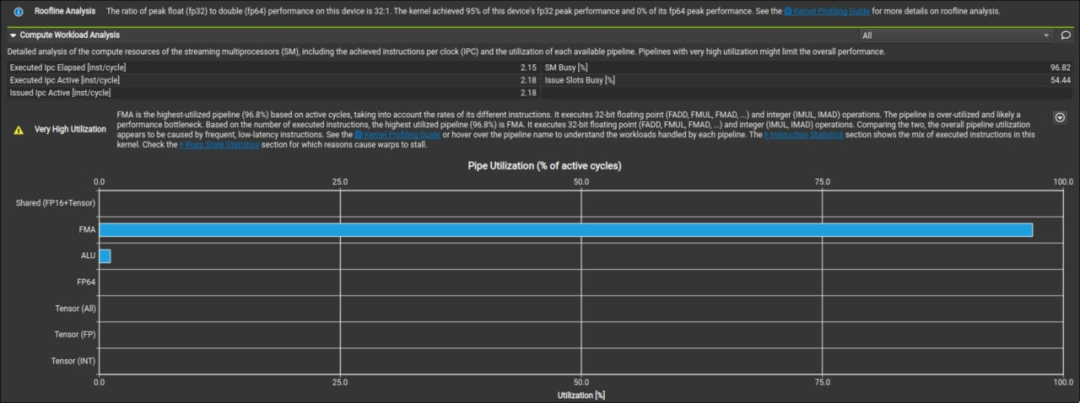
從這張圖我們可以看出,手寫的矩陣乘能夠達到硬件 95% 的峰值性能,效果還是很不錯的。
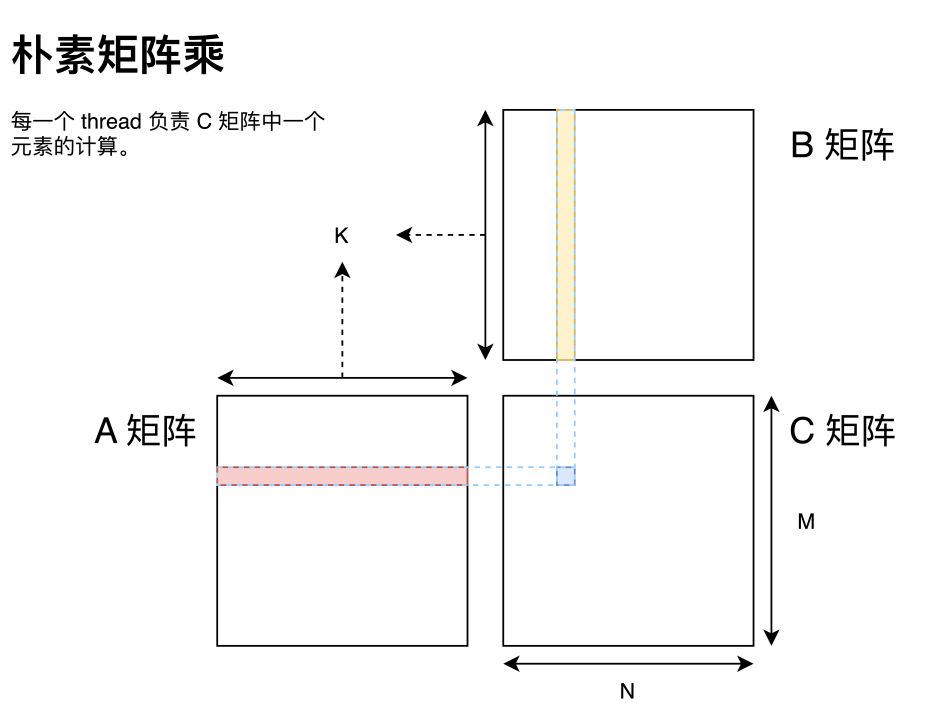
樸素 GEMM 與前置知識
首先寫一個樸素矩陣乘。
#數組 A:M 行 K 列的行主序矩陣
#數組 B:K 行 N 列的行主序矩陣
#數組 C:M 行 N 列的行主序矩陣
# alpha:一個標量
# beta:一個標量
#計算方法:
# c=alpha*A*B+beta*C;
__global__ void matrixMul(const float *A, const float *B, float *C,
intM,intN,intK,floatalpha,floatbeta)
{
inttx=blockIdx.x*blockDim.x+threadIdx.x;
intty=blockIdx.y*blockDim.y+threadIdx.y;
intbaseX=blockIdx.x*blockDim.x;
intbaseY=blockIdx.y*blockDim.y;
floatc=0;
if(tx
{
for(inti=0;i
{
c+=A[tx*K+i]*B[i*N+ty];
}
C[tx*N+ty]=beta*C[tx*N+ty]+alpha*c;//wemultiplyalphaheretoreducethealphacalnum.
}
}
這里 GPU 矩陣乘與 CPU 矩陣乘最大的區別就在于 GPU 可以為目標矩陣 C 中每一個元素分配一個 thread 進行計算。這也是可以切實的感知到 GPU 多線程編程的一點。但這個矩陣乘的樸素實現會非常慢,而分析性能瓶頸中最常見的兩個指標即是帶寬和延遲。這里借用 Nvidia 在 GTC 2018 上的分享來做說明。

這里以一個自動扶梯作為例子來講解。
-
帶寬:指這個自動扶梯每秒能夠運送多少個人,以這張圖為例子,這個扶梯每秒能運 0.5 個人,這就是這個自動扶梯的帶寬。
-
延遲:指一個人踏上這個扶梯直到他被運到頂所需要的時間。同樣以這張圖為例,這個扶梯需要 40s 的延遲。
那么回到指令上來,每一個指令都有對應的延遲和帶寬,而以樸素矩陣乘為例,每一個乘法運算需要讀兩次內存和一次 FFMA,假如沒有其他額外的優化(如循環展開與指令重排),相當于是兩個級聯的自動扶梯,一個負責運送數據,一個負責做數學運算。假設數據運送扶梯的帶寬與延遲與圖中一致而不考慮 FFMA 的帶寬與延遲,那么一次 FFMA 需要等待 40s(扶梯延遲)+ (1/0.5)s(第一個數據到達后第二個數據到達的時間)才能拿到所需的數據,這與扶梯的帶寬 0.5s / 人的峰值性能相去甚遠。那么此時這個 kernel 就完全被延遲卡住了,而無法發揮出應有的性能。
而對于帶寬部分,這里我們引用李少俠的帶寬分析:
對于 FP32 數據,如上圖所示,一個 warp 一次做 32 次 FFMA,對應 64 OP,需讀取 A 矩陣 1 個元素和 B 矩陣 32 個元素,共 132byte。通過寄存器累加,且忽略 C 矩陣寫回開銷,那么計算訪存比為 64OP / 132byte = 0.48。雖然 dram 最小訪問單位為一個 memory transaction,但考慮到 L1 cache 的存在也不會影響實際的計算訪存比。
通過 repo 中提供的 l2cache_bandwidth.cu 可測得 Titan V L2 cache 帶寬約 1.9TB/s,那么最樂觀的結果即使 L2 cache 100% 命中,此方案的理論上限也只有 1.9T * 0.48 = 0.912 tflops,遠低于 14.9 tflops 的硬件算力。
由此我們可以看出,樸素的矩陣乘實現方法無論從延遲和帶寬上都無法滿足需要。
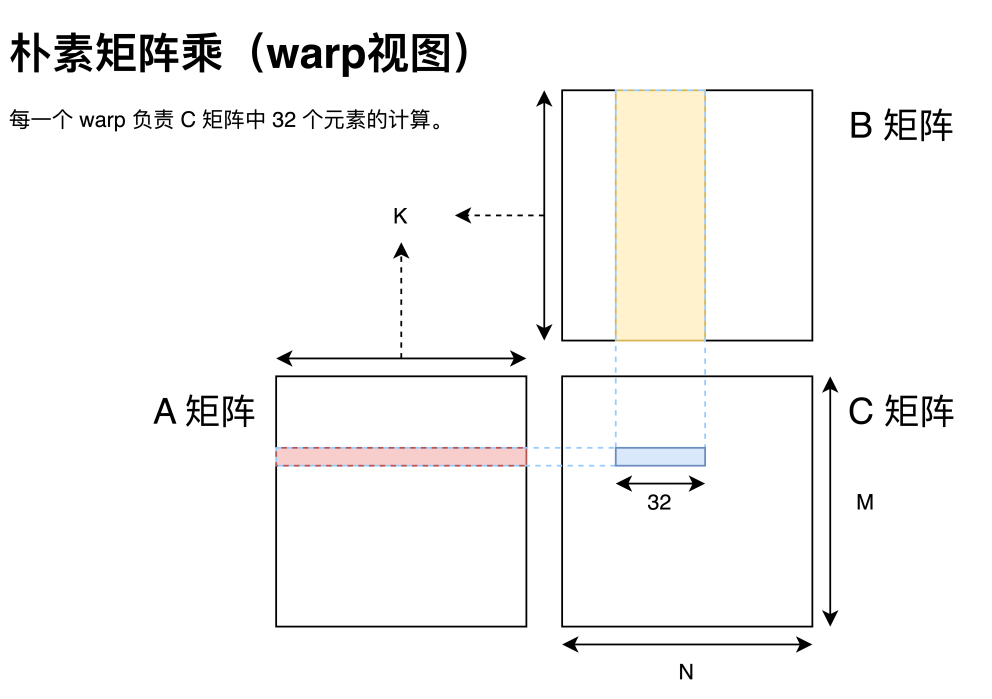
這里一個 warp(即 32 個線程)是指 GPU 調度線程的粒度,可以簡單的理解為同一個 warp 內的線程總是同時運行、同時休眠的。當然這種說法并不完全準確,畢竟還有 warp divergent 問題,感興趣的同學可以自行了解。但總之,思考 GPU 執行時總是從 warp 的角度思考是非常合理的。那么對于一個 warp 而言,我們可以根據李少俠的分析看出,就算我們假設延遲能夠被完全覆蓋,這種分配方案也并不能達到硬件的峰值性能。
這里我用自己的話總結一遍就是:在每個線程執行指令設計時,需要盡可能的覆蓋掉每個指令的延遲;在性能分析時,則從帶寬角度分析矩陣分塊是否合理。
而在于延遲部分還有一頓免費的午餐。在實際應用中,編譯器會自動的做一些優化,如循環展開與指令重排等。例如展開循環后可以將多個讀取 A 矩陣的元素和讀取 B 矩陣的元素排在一起,使得取數據的自動扶梯能夠一次多上幾個人,從而去覆蓋掉扶梯的延遲。而且 GPU 與 CPU 還有一個非常不同的地方在于,GPU 的線程切換代價非常低,因此可以在等待延遲的時候轉而去運行其他線程從而達到延遲覆蓋的目的。還是以扶梯為例子,GPU 上有很多個扶梯,在等待第一個人到達扶梯末尾時,GPU 可以轉到第二個扶梯送幾個人上扶梯。理想情況下,在 GPU 送完第 N 個扶梯的人時,第一個扶梯的人剛好達到扶梯頂部,那么這個運送的延遲就被覆蓋掉了。
Tiling
矩陣乘分塊是為了將一個大問題化解為小問題求解,這里 CPU 與 GPU 分塊的需求也不盡相同。CPU 是希望保持計算的局部性,可以充分利用 L1、L2 高速緩存來避免緩慢的內存訪問。而 GPU 在此基礎之上還需要將一個大問題合理拆分到不同的 thread 上,使得其能夠充分利用 GPU 上的硬件資源。下面我將從局部性和合理拆分兩個方面講解如何做矩陣分塊。
局部性原理
局部性原理,在我的理解中便是為了能夠盡可能的使用高速緩存器內的數據進行運算所提出的一個程序設計理念。由于高速緩存器往往十分昂貴(或者需要很高的功耗),因此空間都不大。由此我們需要盡可能的將一些重復訪存聚合起來,放到高速緩存器里面來加速數據訪問,或者在進行訪存的時候盡可能連續訪存來使用 cache 加速訪存。我們先還是讓每一個 thread 負責一個目標矩陣元素的計算。雖然這種分配方式十分樸素、十分直接,同時各個 thread 之間也沒有數據依賴關系,不需要做額外的同步之類的操作,但這種分配方式卻是十分訪存不友好的,因為每一個 thread 都是直接與內存做交互,而 GPU 的全局內存訪問帶寬完全不足以匹配上它的計算速度。
同時我們注意到處于同一行的 thread 總是會同樣的讀取 A 矩陣的同一行數據;同一列的 thread 總是會讀取 B 矩陣的同一列數據。那么一個非常自然的想法則是對于每一個 Block,我們將數據移動到這個 Block 共享的一塊高速存儲區 shared memory 上,從而減少與全局內存交互的次數。同時我們考慮到 shared memory 的容量有限,因此可以一次只取一部分 k,然后通過循環迭代的方式完成這個 Block 所負責的矩陣乘區域。
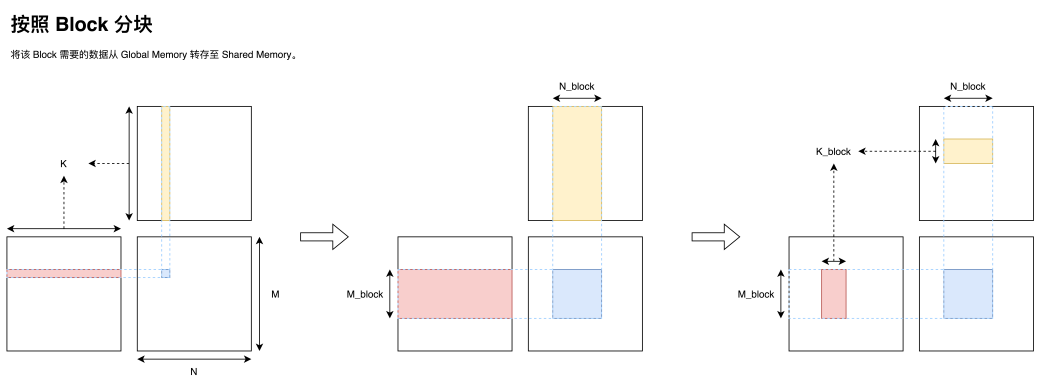
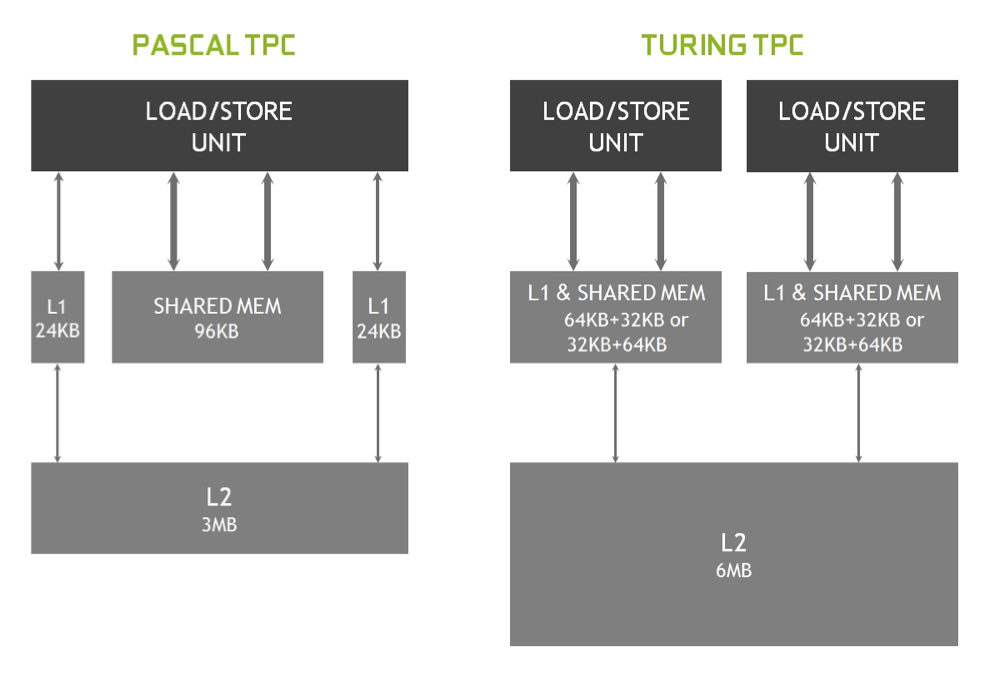
值得一提的事,shared memory 雖然叫做 memory,但他卻有著非常高的訪存速度與極低的延遲。實際上,shared memory 可以被看作是一塊可以顯式控制的 L1 cache。從圖靈架構開始,在硬件上 shared memory 與 GPU 上的 L1 cache 共享同一塊區域,同時 shared memory 與 Load/Store 單元交互也是直連的(沒有中間商賺差價)。
在將一個大型矩陣乘劃分為一個個由 Block 負責的小型矩陣乘之后,我們接下來還需要把一個 Block 負責的矩陣乘分配給 Block 內部的 warp;分配到 warp 之后我們還需要把一個 warp 負責的矩陣乘分配給 warp 內部的 thread。經過這么一步一步的劃分,我們便可以把一個巨大的矩陣乘任務高效的分配到各級速度不一的存儲器上,最終盡可能打滿硬件峰值性能,實現高效矩陣乘。有了前面劃分 Block 的經驗,我們也就可以依葫蘆畫瓢,實現大矩陣的拆分(Tiling),在此就不過多贅述了,最終整體流程圖如下。
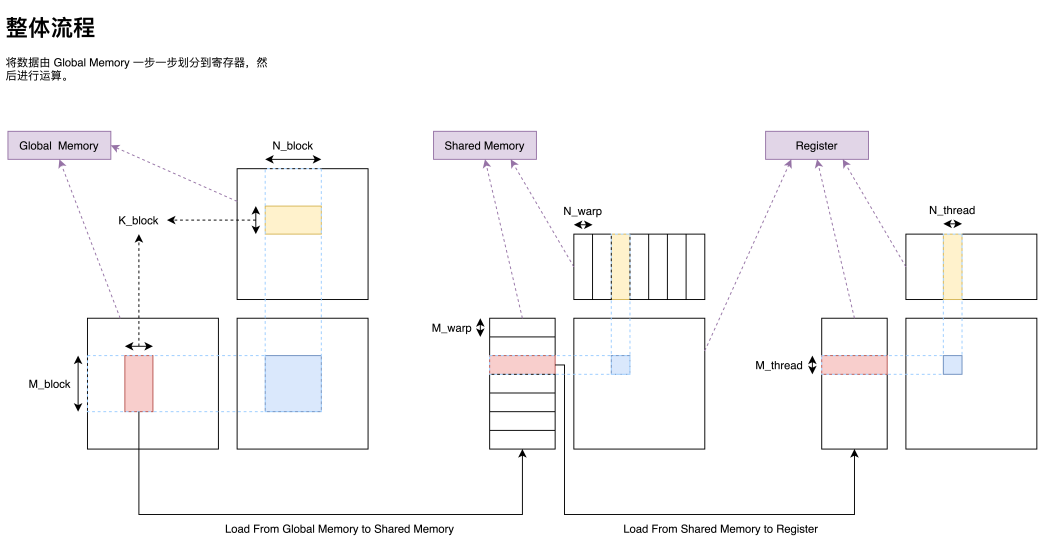
當然這只是一個較為粗糙的流程圖,例如每一個 thread 負責的分塊也并不是圖中所示的連續一塊矩陣乘,我們也將在后續一步一步完善細節,但這種分解的框架卻是一種非常經典的思路。
如何確定分塊大小?
在擁有分塊的基本理念之后,我們還有一個問題沒有解決。那便是每一個 Block 該負責多大的矩陣乘?每一個 thread 又應該負責多大的矩陣乘?為了讓文字變得清晰起來,我們定義每一個 Block 負責的矩陣大小為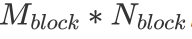 ,每次迭代
,每次迭代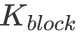 的 k 維數據,每一個 warp 負責的矩陣大小為
的 k 維數據,每一個 warp 負責的矩陣大小為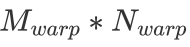 ,每一個 thread 負責的大小為
,每一個 thread 負責的大小為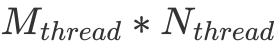 。其中這些符號都在上圖出現過,可以自行對照一下。
。其中這些符號都在上圖出現過,可以自行對照一下。
這里我們同樣引用李少俠的計算訪存分析:
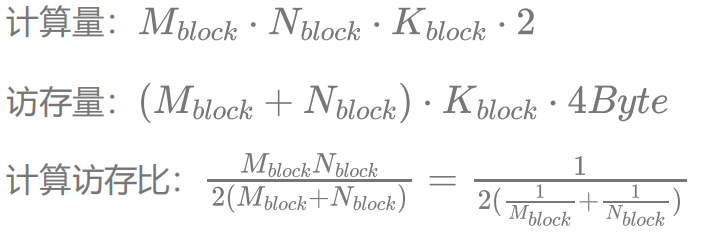
假設我們不考慮 shared memory 的訪存代價(因為可以做到覆蓋掉shared memory 的訪存延遲,而且其帶寬能夠滿足 FFMA 單元的計算速度),只考慮全局內存的訪問,可以看到選擇在K 上縮水(即不把整個 K 維度都放到 shared memory 里)還是比較合理的,因為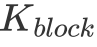 的大小其實并不影響計算訪存比。而對計算訪存比有決定性影響的是每一個 Block 計算的大小。如果取
的大小其實并不影響計算訪存比。而對計算訪存比有決定性影響的是每一個 Block 計算的大小。如果取 為 64,帶入 RTX 2080 的數據,可以得到 10.1 Tflops / 16 = 631.25 GB/s。即內存訪問帶寬達到 631.25 GB/s 就能避免內存訪問瓶頸了。同樣,我們取 L2 命中率為 20%(還是比較好達到的),加權內存訪問帶寬為:
為 64,帶入 RTX 2080 的數據,可以得到 10.1 Tflops / 16 = 631.25 GB/s。即內存訪問帶寬達到 631.25 GB/s 就能避免內存訪問瓶頸了。同樣,我們取 L2 命中率為 20%(還是比較好達到的),加權內存訪問帶寬為: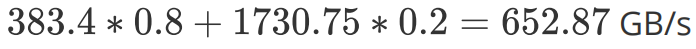 ,即可避免內存訪問瓶頸。
,即可避免內存訪問瓶頸。
那是否我們只要取分塊大小為 64x64 就萬事大吉了呢?也不盡然。我們前面只分析了帶寬,而在延遲無法被覆蓋的情況下,整個 kernel 性能也不會太好。而更大的分塊意味著每一個 thread 會計算更多的數據,可以使用一些手段實現更優的延遲覆蓋。這一點會在后面討論如何具體實現,大致思想也是局部性的原理,只不過這次是將數據從 shared memory 保存到寄存器,從而實現使用更高速的緩存計算的目的。
那是否我們取分塊越大越好呢?那也不一定。更大的分塊使用了更多的寄存器,從而使得同一個 SM 能夠同時承載的線程數變少,這里 Nvidia 將之稱為 Occupancy。如前文所述,當一個 warp 被卡住時,GPU 可以切換到另一個 warp 執行指令,Occupancy 越低,可供 GPU 切換的線程就越少。
而 Occupancy 也是和硬件強相關的。一個 GPU 由多個 SM 構成,每一個 SM 擁有有限的寄存器數量、 shared memory 和最大可調度線程數量。而 Occupancy 是指每個 SM 能夠同時調度的線程數量除以一個 SM 的最大可調度線程數量。關于 Occupancy 的計算我們可以通過在編譯時添加 --ptxas-options=-v 參數,使編譯器在編譯時輸出每個 kernel 所花費的寄存器數量和 shared memory,然后通過隨 cuda 提供的一個 excel 表格進行計算。(盡管這個 Excel 已經 deprecated 了,但他用起來確實挺方便的。)
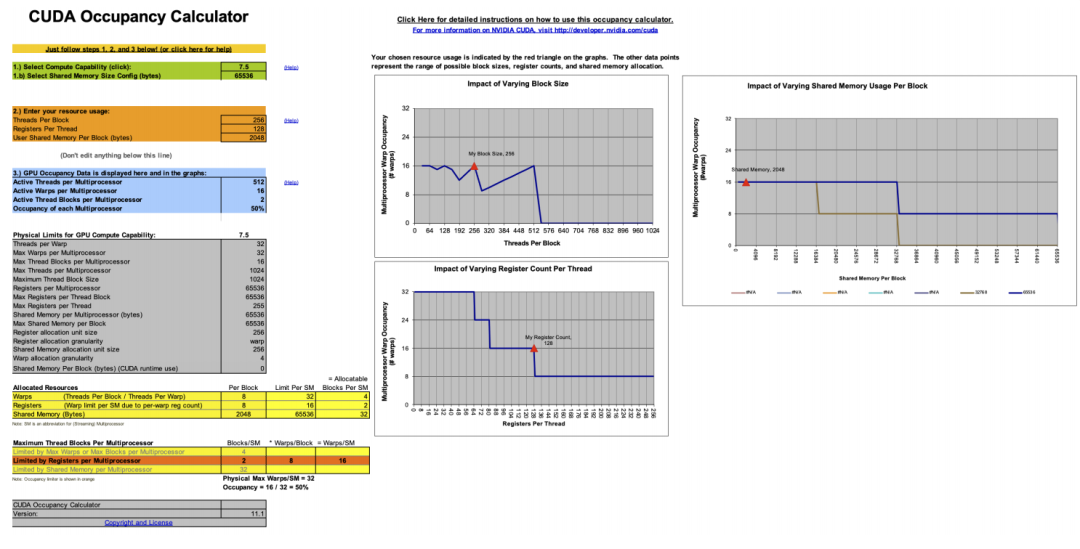
例如我們每個 thread 需要 128 個寄存器,2048 bytes 的 shared memory,那么由于 RTX 2080 每個 SM 只有 65536 個寄存器,因此每個 SM 最多只能同時跑 512 個 threads。又因為每個 SM 最多能夠承載 1024 個 threads,所以此時 Occupancy 為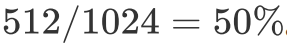 。
。
值得一提的是,雖然較高的 Occupancy 使得在一個線程卡住時,SM 能夠馬上切換到別的線程,通過將其他線程需要執行的指令填充到流水線中從而達到覆蓋延遲的目的,但這并不代表高性能。例如,如果每一個線程本身就能夠通過更多的寄存器占用從而達到延遲覆蓋的目的,自然也就不需要 SM 來做這件事了,反倒是如果無腦的去提高 Occupancy 使得一些 thread 內的延遲甚至都無法被 SM 通過切換執行線程的方式覆蓋,那屬實是得不償失了。
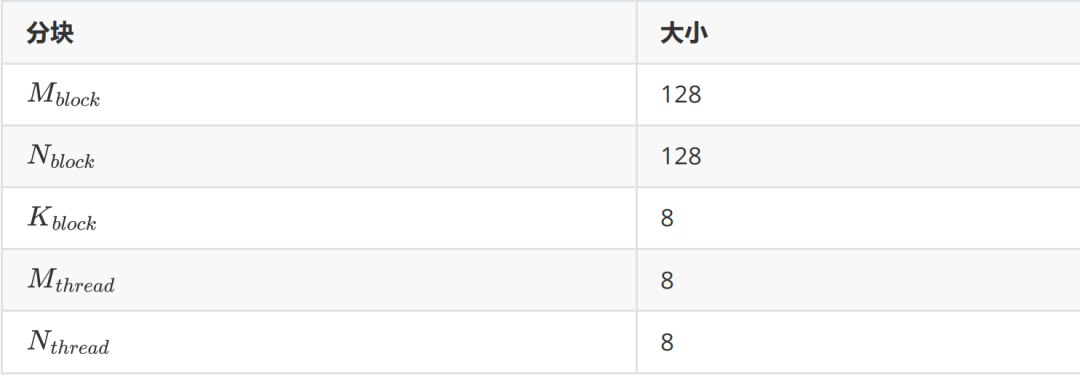
因此,我們能夠做的就是在有一定理論分析的情況下確定好一些矩陣的分塊大小的方案,然后要不就是經驗性的去選擇最終用哪個分塊,要不就是跑一個 profile 來直接得到最快的分塊。這里由于已經有非常多的先例證明了 128x128x8 是一個較優的選擇,因此本文則遵從這個分塊方案。那么,目前我們能夠確定的分塊如下表。
當然有些同學可能會問,既然最終還是需要用跑 profile 的方式來確定最優分塊,那理論分析還有什么意義呢?答案就是如果提前通過理論分析,那么就能夠在一定程度上縮小需要跑 profile 的分塊數量。用算法上的語言來講就是如果我們將需要搜索的所有分塊作為搜索空間,那么理論分析便是搜索算法中的 A* 算法,你掌握了越多的理論分析知識那么這個搜索過程就會越高效。同時對 CUDA 底層越了解,在同一個分塊策略下,你更容易寫出能達到理論性能的 kernel。
Thread 級優化
對于一個 thread 能做的優化其實并不多,因為 GPU 是以一個 warp(即 32 個 thread)進行調度的,所以許多基于單線程的優化,如訪存優化,其實并不能直接套到 GPU 上。而為數不多值得一提的優化手段便是單個線程在計算時應該采用向量內積還是向量外積以及 double buffer。但實質上向量外積嚴格意義上也不能算作是一個優化,因為這一步編譯器就能在編譯階段幫忙做了。之所以提一句是還是為了給 double buffer 做鋪墊,即我們應該怎么預取數據。
首先我們取了 128x128 的分塊策略,一個 Block 有 256 個線程,那么每個線程需要負責一個 8x8 的矩陣乘運算。而一個線程完成一個小型矩陣乘有兩種實現方法。
向量內積
向量內積的實現方法如圖所示,即將 A 矩陣拆分為多個行向量、B 矩陣拆分為多個列向量,這些向量通過向量內積的方法求得最終答案。
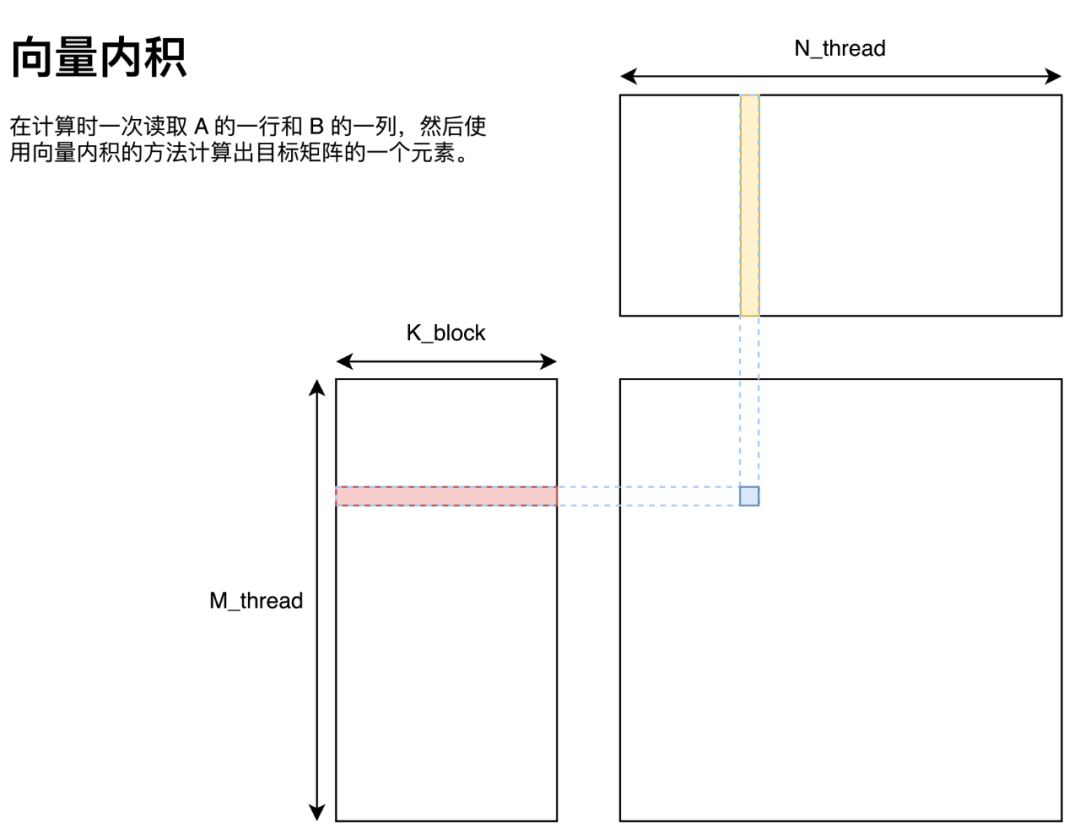
用代碼描述如下:
M=N=K=8;
floata[M*N];
floatb[N*K];
floatc[M*N];
foriinrange(M):
forjinrange(N):
forkinrange(K):
c[i*N+j]+=a[i*K+k]*b[k*N+j];
向量外積
向量外積的實現方法如圖所示,即將 A 矩陣拆分為多個列向量、B 矩陣拆分為多個行向量,這些向量通過向量外積的方法求得最終答案。
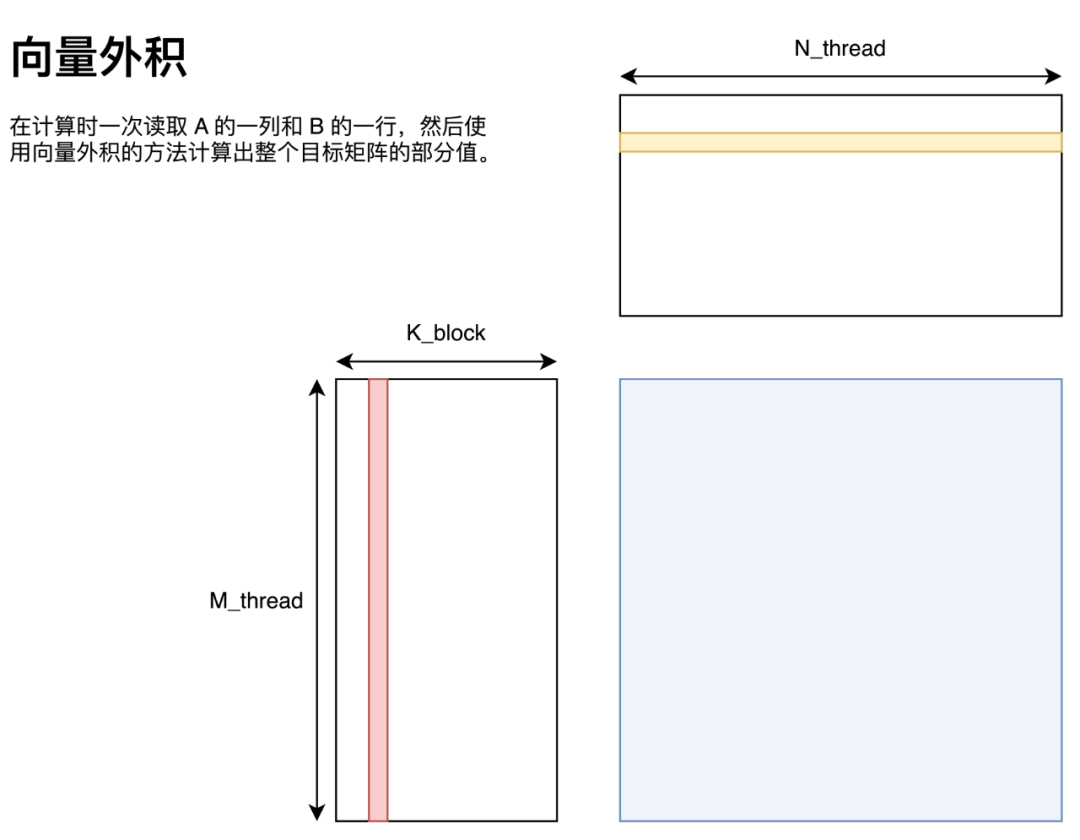
用代碼描述如下:
M=N=K=8;
floata[M*N];
floatb[N*K];
floatc[M*N];
forkinrange(K):
foriinrange(M):
forjinrange(N):
c[i*N+j]+=a[i*K+k]*b[k*N+j];
可以看到,向量內積和向量外積的區別在代碼上僅僅體現在循環方式上。
為何我們需要關心這個?
有做過 CPU 矩陣乘優化的同學可能知道,僅僅調整循環順序就已經能夠帶來顯著的性能差異了。有許多分析都是從局部性的角度進行分析的。即使用向量外積的方案可以利用到循環遍歷的局部性,將一些重復訪存使用寄存器緩存而避免無意義訪存。例如我們補充一下采用向量外積方案關于寄存器的細節。
floata[M*N];
floatb[N*K];
floatc[M*N];
forkinrange(K):
regB[0:N]=b[k*N:(k+1)*N]
foriinrange(M):
regA=a[i*K+k];
forjinrange(N):
c[i*N+j]+=regA*regB[j];
其中 regA 和 regB 均為寄存器。其中我們不難發現,對于每一次循環 j ,使用的都是完全相同的 A 矩陣里的元素,因此可以用一個寄存器來緩存該值;對于每一次循環 k,使用的都是完全相同的一行 B 矩陣中的值,因此我們可以用 N 個寄存器緩存該值。于是將原本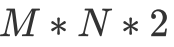 次訪存(底下兩層循環需要訪問一次 A 矩陣和一次 B 矩陣),通過使用
次訪存(底下兩層循環需要訪問一次 A 矩陣和一次 B 矩陣),通過使用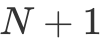 個寄存器緩存(B 使用 N 個,A 使用一個),優化為 N+M 次訪存。同時我們也注意到, M 和 N 越大的情況下,提升效果越發顯著,這也是為什么我們希望每一個線程負責的分塊大一點比較好。但同時 M 和 N 越大,每一個線程多使用的寄存器就越多,而在 GPU 的語境下,更高的寄存器占用意味著更低的 Occupancy。因此當 M 和 N 大到 shared memory 帶寬不是性能瓶頸即可。更詳細的分析可以看李少俠的分析。
個寄存器緩存(B 使用 N 個,A 使用一個),優化為 N+M 次訪存。同時我們也注意到, M 和 N 越大的情況下,提升效果越發顯著,這也是為什么我們希望每一個線程負責的分塊大一點比較好。但同時 M 和 N 越大,每一個線程多使用的寄存器就越多,而在 GPU 的語境下,更高的寄存器占用意味著更低的 Occupancy。因此當 M 和 N 大到 shared memory 帶寬不是性能瓶頸即可。更詳細的分析可以看李少俠的分析。
而我則從循環展開的角度解釋一下為什么我們需要了解這個優化方案,同時解釋一下為什么該優化方案在 GPU 上并不如 CPU 上那么有效。從循環展開的角度來看,第二種循環體構造與第一種循環最大的區別就在于它能在不展開 k 的情況下通過展開 m 和 n 處的循環就能自動的識別到重復訪存,并使用相應的寄存器來避免重復訪存。例如我們假定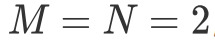 ,那么展開 m 和 n 處循環的結果如下。
,那么展開 m 和 n 處循環的結果如下。
M=N=2;
floata[M*N];
floatb[N*K];
floatc[M*N];
forkinrange(K):
c[0*N+0]+=a[0*K+k]*b[k*N+0]
c[0*N+1]+=a[0*K+k]*b[k*N+1]
c[1*N+0]+=a[1*K+k]*b[k*N+0]
c[1*N+1]+=a[1*K+k]*b[k*N+1]
只要是稍微現代一點的編譯器,都能一眼看出這四條指令的 8 次訪存,有 4 次是可以合并的。同時現代一點的編譯器也能在一定程度上根據生成的匯編交叉排列計算和訪存達到延遲覆蓋的目的。而向量內積的方案需要把整個 k 維度展開才能看到這些潛在的訪存合并機會。在 CPU 矩陣乘的語境下,一般計算 kernel 的 都比較大(好幾百),而
都比較大(好幾百),而 都很小(一般取 6x16,根據架構來做具體確定),寄存器數量又非常少,因此基本上無法在 K 維上將循環完全展開并做優化。因為展開一個超長的循環不僅會帶來額外的寄存器占用、優化難度,還會帶來更多的匯編指令,使得最終的二進制文件臃腫不堪。但在 GPU 上,情況卻恰恰相反。對于已知循環次數的小循環,即便你沒有指定 #pragma unroll,nvcc 也會自動的展開這些循環。而對于一個 thread 所負責的小型矩陣乘,這三層循環的值均為 8,符合 nvcc 自動展開循環的條件。而在展開完成后,nvcc 會對所有的訪存以及計算指令重排得到一個不錯的匯編指令排列。
都很小(一般取 6x16,根據架構來做具體確定),寄存器數量又非常少,因此基本上無法在 K 維上將循環完全展開并做優化。因為展開一個超長的循環不僅會帶來額外的寄存器占用、優化難度,還會帶來更多的匯編指令,使得最終的二進制文件臃腫不堪。但在 GPU 上,情況卻恰恰相反。對于已知循環次數的小循環,即便你沒有指定 #pragma unroll,nvcc 也會自動的展開這些循環。而對于一個 thread 所負責的小型矩陣乘,這三層循環的值均為 8,符合 nvcc 自動展開循環的條件。而在展開完成后,nvcc 會對所有的訪存以及計算指令重排得到一個不錯的匯編指令排列。
那么這就引出了下一個問題,我們為何還需要關心他究竟是向量內積還是向量外積?
答案就是 double buffer。如果我們能夠提前知道一個循環需要什么數據,我們就能提前預取該循環第一次所需的數據,同時在該循環進行運算的時候預取下一次計算所需的數據。而顯然這在向量內積的情況下是無法做到的。同時由于 double buffer 需要額外的寄存器保存從 global memory 轉移到 shared memory 的數據,所以當一開始循環展開使用的寄存器過多時,盡管后續能優化到較少的寄存器,但編譯器依然無法正確的在限定寄存器數量下實現 double buffer。這一點在優化 sgemm 的時候并不是那么重要(因為多使用一點寄存器也就從每個 SM 跑兩個 block 變為一個 block),但是在優化 int8 矩陣乘時需要額外的關注(因為本身它就只能在一個 SM 上跑一個 block,如果實現不得當將會完全失去 double buffer)。
那么此時樸素的利用到向量外積和 shared memory 的代碼:https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/shared_mem_gemm.cu
Double Buffer
由于 GPU 沒有 prefetch 這種指令,同時我們又有 shared memory 這種可編程的 L1 cache,因此需要手動實現 prefetch 功能,而在 GPU 語境下一般被稱作 double buffer。double buffer 的好處自不必多說,即它可以實現數據讀取與計算在時間上重疊,利用 FFMA 單元與 Load/Store 單元可以并行執行指令的特點,達到覆蓋延遲的目的。而盡管 GPU 可以在一個 warp 有延遲的情況下,通過切換去運行另一個 warp 達到延遲覆蓋到目的,但由于可供 warp 調度器能切換到線程數量的限制,過于長的延遲并不能通過這種方式覆蓋掉。這里引用一下李少俠更詳細的分析:
若每 SM 有 4 個調度器,若每個調度器只有 4 個可調度 warp,當指令平均間隔超過 4 cycle 后就無法靠 warp 調度掩蓋延遲了。考慮到 GEMM 中涉及 smem 讀寫的過程需要同步 thread block,進一步限制了 warp 調度空間,所以很難靠 warp 并行掩蓋延遲。
而本文最終實現的 kernel occupancy 只有 50%,即每個 SM 只能調度 512 個 threads(16 warps),加上圖靈架構每 SM 有 4 個 warp 調度器,最終結果與李少俠分析的一致。因此 double buffer 從指令角度提供的延遲覆蓋方法最終還是會有效的。
但值得一提的是,在你自己動手實踐時,盡可能的考慮在其他優化已經加無可加的情況下再加入這個優化。這是由于這個優化會大幅修改數據讀取部分的代碼,而且還會產生重復代碼,不利于代碼維護。同時在我自己的實踐中發現,如果在一開始 kernel 寫的比較垃圾,加了 double buffer 也沒有什么卵用,還會讓后續的優化不太好加上去。當然,這只是我的個人建議,如果你想實際看看 double buffer 的效果也可以一開始就加上去。
首先我們看一下每個 thread 的運行流程。

那么能實現 double buffer 的機會有兩個地方:Global Memory to Shared Memory 與 Shared Memory to Register。即在每一次 FFMA 開始之前我們讀取 Global Memory 的數據到寄存器中,在 FFMA 之后將該寄存器中的值寫到 shared memory 中。由于在讀取數據后 load from shared memory 以及 FFMA 兩個流程中我們并不依賴于該寄存器中的數據,因此可以覆蓋 Global Memory 的讀取延遲。而同時在計算每一次 FFMA 之前,我們可以用寄存器提前取下一次 FFMA 需要的數據,也就能做到覆蓋 shared memory 的延遲。
大概就是這樣!我們在每一次運算之前提前將第一次循環所需的數據移動到寄存器中,這樣我們就可以實現數據運算和數據存取指令級并行的功能了。
Warp 級優化
在做了不少鋪墊之后,接下來的優化終于是可以帶來一些看得見的性能提升的了。首先回顧我們之前的代碼,可以看到每個 thread 負責的部分完全沒有考慮到它們之間可能的協作關系,即同一個 warp 內的 thread 此時在同一塊硬件上同時執行——它們共享同一個 register file,這表明它們可以通過寄存器快速共享數據(即 shared memory 的 broadcast 機制);它們會同時訪存,這表明如何安排每一個 warp 內的 thread 訪存是至關重要的。
Warp Tiling
已知我們指定一個 Block 計算 128x128 的矩陣,一個 Block 有 8 個 warp,一個 warp 有 32 個 thread,每個 thread 需要負責 8x8 的小型矩陣乘,那么我們沿用李少俠的定義:
一個 warp 由個線程組成,可以是?
,我們把這些線程對應的 thread tile 拼在一起的區域稱為 warp tile,尺寸為
,如下圖所示。
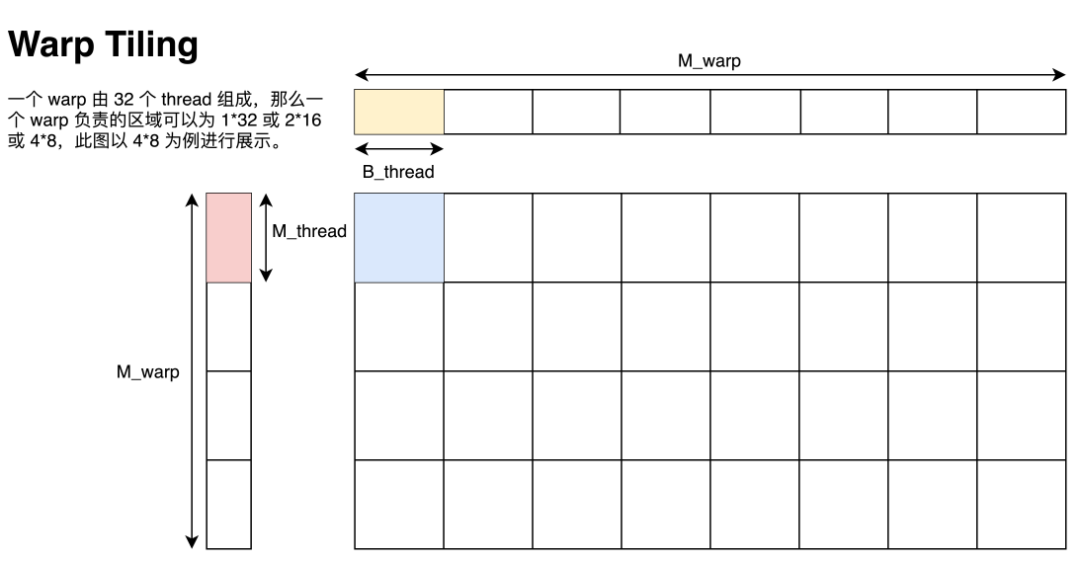
這里的圖給的是 的排列方式。由于同一個 warp 在訪問 shared memory 時有 broadcast 機制(即同一個 warp 在訪問同一個內存地址內的值時只會實質發生一次數據讀取),因此這一個 warp 計算時只會實際讀取
的排列方式。由于同一個 warp 在訪問 shared memory 時有 broadcast 機制(即同一個 warp 在訪問同一個內存地址內的值時只會實質發生一次數據讀取),因此這一個 warp 計算時只會實際讀取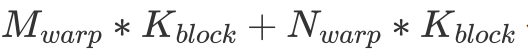 個 float。與之相對的,這個 warp 會進行
個 float。與之相對的,這個 warp 會進行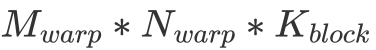 次 FFMA。不難看出,在
次 FFMA。不難看出,在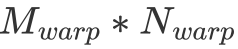 固定為 32 的情況下,
固定為 32 的情況下,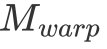 與
與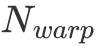 越相近,計算訪存比就越大,因此取
越相近,計算訪存比就越大,因此取 最為合適。
最為合適。
而在確定了 warp tiling 后,如何讀取和存儲數據的細節還需要細扣,接下來我將會按照 GPU 的硬件特性講解讀寫數據的細節。但這一部分的大致思路基本已經介紹完畢了,動手能力強的同學現在就可以自己試試如何寫一個高效矩陣乘了!
向量化訪存
向量化訪存即是一條指令同時請求多個 float 數據,目前 CUDA 最高支持 128 bit 的向量化訪存,即一條指令請求 4 個 float 數據。向量化訪問主要的好處在于可以用更少的指令讀取更多的數據。由于在訪問全局內存時是以 32 Byte 為粒度進行訪問的,因此如果同一個 warp 內的 thread 請求了一段連續內存的數據,每一個 thread 都請求兩次 4 Byte 的數據(小于 GPU 全局訪存的最小單位),那么 GPU 會在硬件處將 64 次數據請求按照 32 Byte 進行合并,最終形成 8 次 32 Byte 內存訪問。
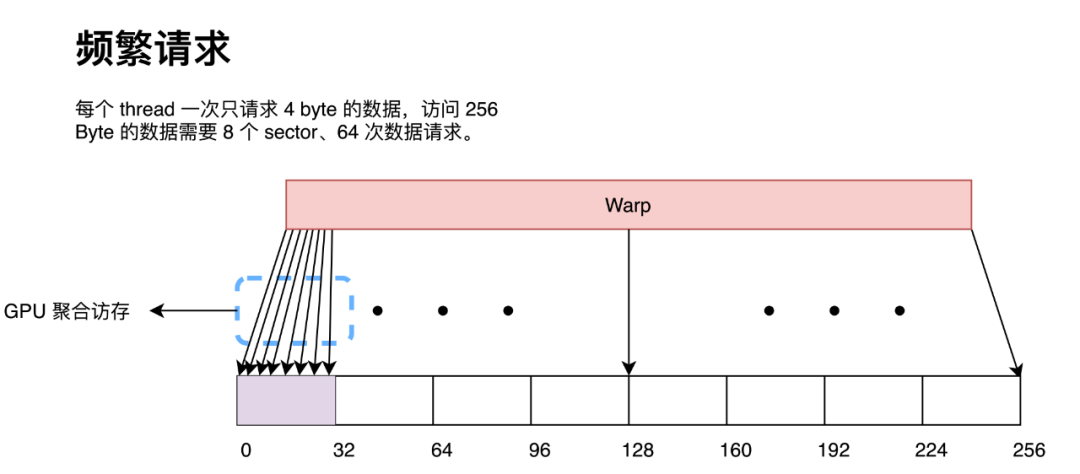
而如果每一個 thread 請求 8 Byte 數據,那么 GPU 會在硬件處同樣將 32 次數據請求按照 32 Byte 進行合并,最終形成也形成 8 次 32 Byte 內存訪問。
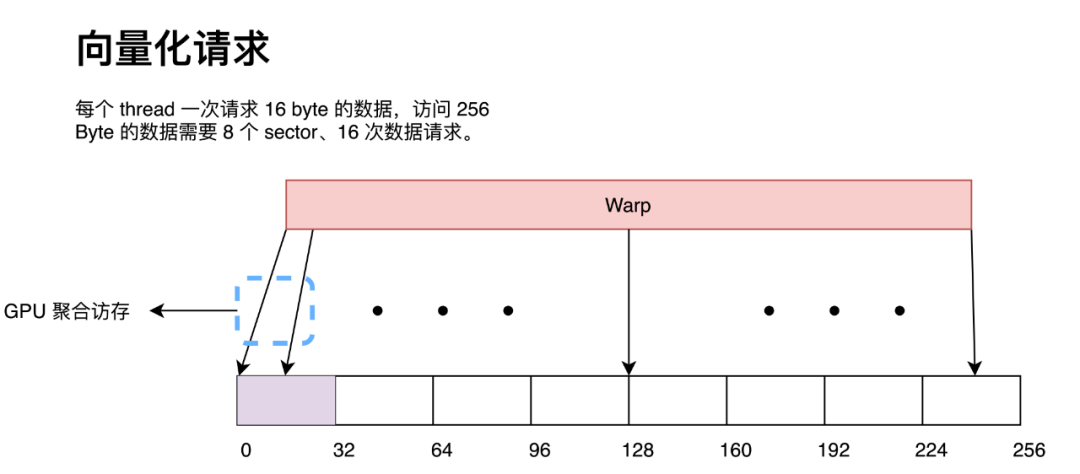
那么我們可以看出,對于訪問同一數據量的數據,請求的指令越多,GPU 的聚合訪問的壓力就會越大。在極端情況下,盡管帶寬足夠,但大量的訪存請求會塞滿訪問隊列導致 stall。這在 Nsight Compute 中顯示為 MIO Throttle 和 LG Throttle,即對應 shared memory 和 global memory。因此采用向量化訪存能在一定程度上緩解 GPU 硬件層面的聚合訪存壓力(因為我們顯式的用指令告訴 GPU 某些數據請求不需要聚合,直接用一個 sector 來處理就好了)。
但使用向量化訪存——即用 float4 讀寫數據——也不是完美的。它的一個嚴重缺陷在于使用 float4 訪存要求請求的數據地址要按照 float4 對齊,因此當 M、N、K 不為 4 的倍數時將會報 missaligned address 錯誤(因為第二行開始就不能按照 float4 對齊了)。
這么干對輸入矩陣形狀有一定要求,寫出來的矩陣乘沒有特別好的通用性。同時 sgemm 受聚合訪存的影響也并不是那么大,因此在實操中往往并不會選擇使用 float4 讀寫全局內存,而只會使用 float4 讀寫 shared memory。但由于我一開始學 CUDA 的時候對這一塊理解也不深,然后發現許多人(李少俠除外)都很暴力的直接用 float4 讀寫全局內存,于是我也用了 float4 讀寫全局內存。
而我們這里對比李少俠的 kernel profile 和我們最終的成品發現,在 global memory 讀取處是否使用向量化讀取其實并不會對性能有多少影響。可以看到最終 profile 出來的 Stall LG Throttle 和 Stall MIO Throttle 占比都不高。
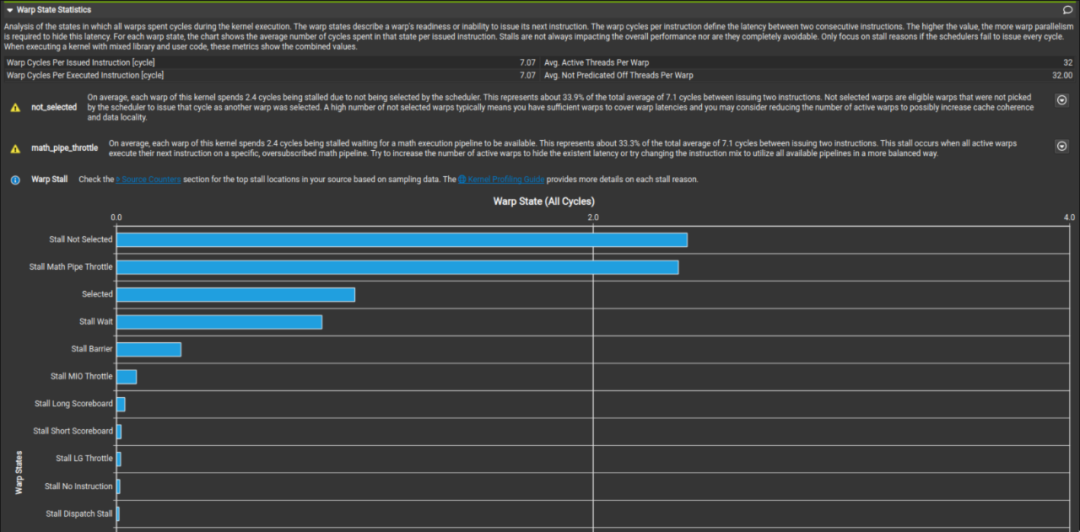
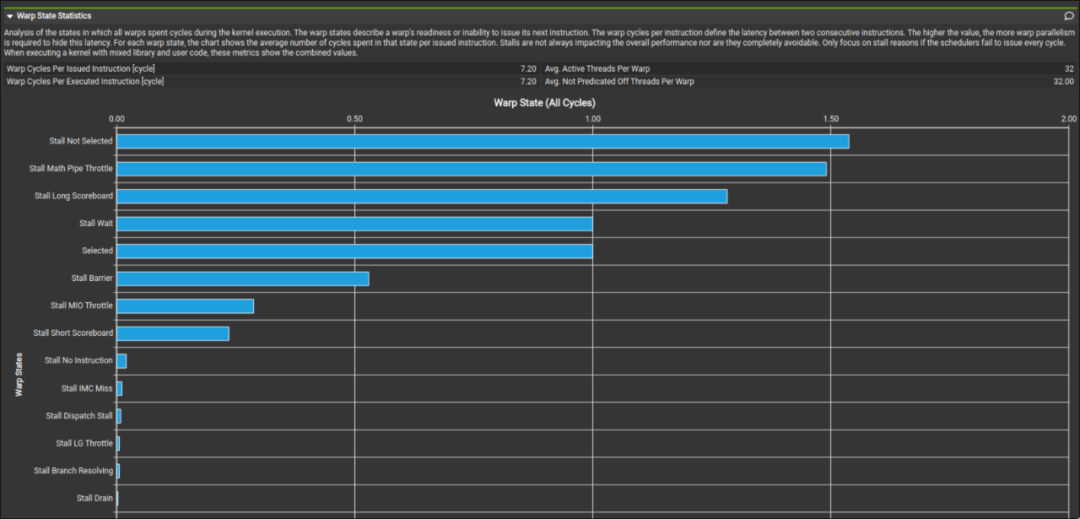
上圖為李少俠的 kernel 下圖為我最終寫的 kernel。這兩個 kernel 在數據讀取方面的區別就是李少俠是以 4B 為單位訪存的,而我是以 16B 為單位做訪存的。這進一步印證了 sgemm 其實并不是非常關心讀取 global memory 時是以怎樣的粒度讀取的。而向量化訪存對于 shared memory 的影響就留給讀者自行驗證了。同時值得注意的是,在把數據讀取方式從向量化訪存修改為一個一個訪存時需要注意 bank conflict 的問題。因為一個 warp 在執行 128-bit load 和 32-bit load 時的調度并不相同(這點會在后面提到)。
還有一個值得注意的是在 Global Memory 訪存時,并不能直接將原先的向量化存取代碼直接改成一個一個的讀取。因為這樣訪存從原來一個 warp 并行訪問一段連續的內存變成一個 warp 分成四次訪問不連續的內存。雖然有 L2 cache 來平滑這種不規則的訪存,但最終會帶來 10% 左右的性能下降。代碼如下:
//OriginalCode
preA=*reinterpret_cast<constfloat4*>(baseA+i+rowA*K+colA);
//ModifiedCode
preA.x=baseA[rowA*K+i+colA];
preA.y=baseA[rowA*K+i+colA+1];
preA.z=baseA[rowA*K+i+colA+2];
preA.w = baseA[rowA * K + i + colA + 3];
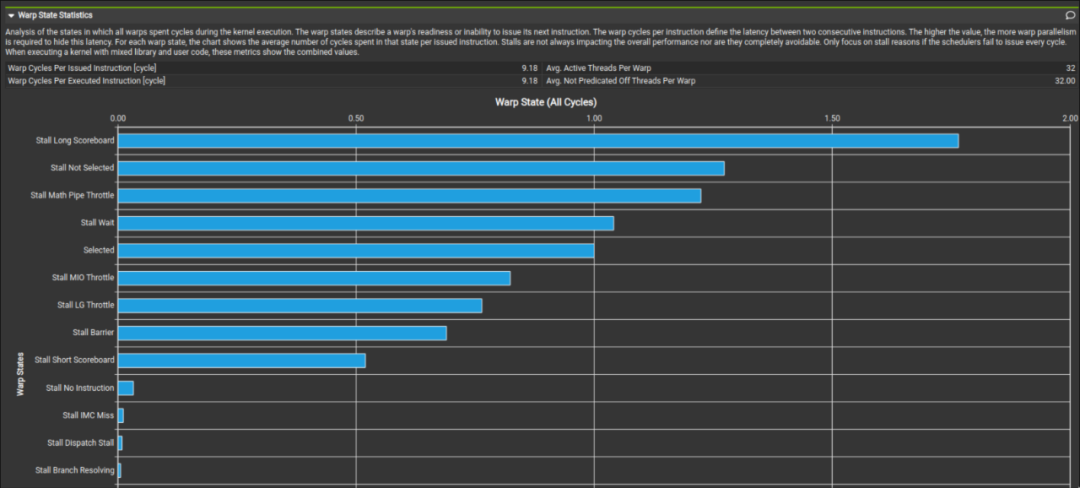
可以看到這種簡單的更改其實并不可取,更優的寫法是每一條指令都是在 warp 視圖下的連續訪存。
Global Memory
前面提到 GPU 訪存時以 32 Byte 為粒度進行訪問的,那么一個 32 Byte 訪問被稱為一個 sector。那么值得注意的就是在搬運數據時,盡可能的讓同一個 warp 搬運同一行的數據來避免使用額外的 sector(本文采用現代的行主序來存儲矩陣)。
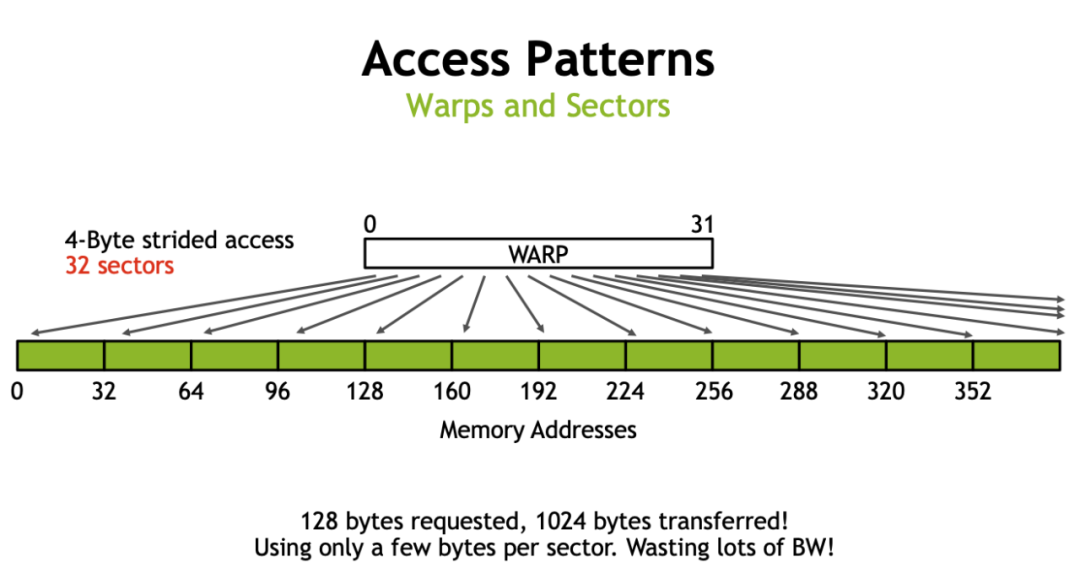
這里借用一下 Nvidia 的圖。如果同一個 warp 內的 thread 都訪問每一行的開頭,那么如果一行超過 8 個 float,那么每一個 thread 都需要一個 sector 去請求它們需要的數據,這就造成了 sector 浪費。而實際中每一行的元素往往都會大于 8 個 float,因此會有非常大的性能損失。下圖為一個 warp 在拷貝時,每個 thread 之間間隔的大小,單位為 float。可以看到在間隔為 2 時就已經有一半的性能損失了,這很不好。
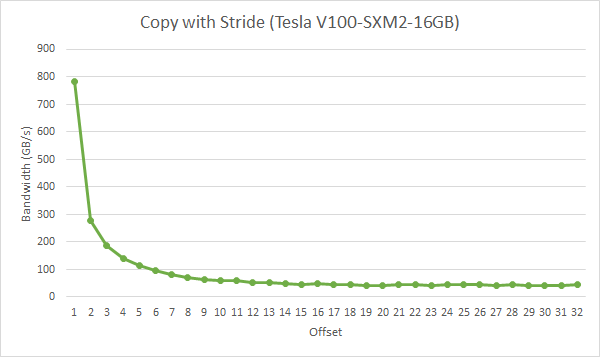
因此我們采用下圖所示的訪問方式。即盡可能的讓一個 warp 中的 thread 連續的讀取 Global Memory 中的元素。
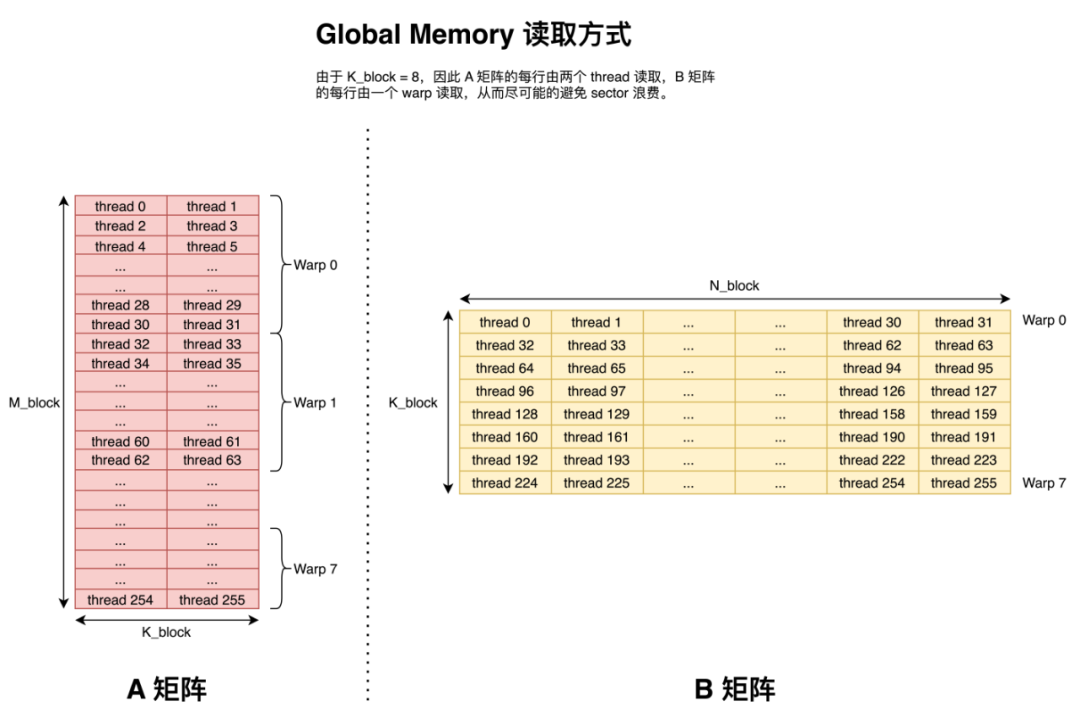
Shared Memory
前文已經講過,shared memory 在圖靈架構之后可以完全被看作是 L1 cache。而在此基礎之上,shared memory 的訪問粒度是 32 bit 也就是 4 Byte,剛好是一個 float 數據的大小。而后 shared memory 按照 4 Byte 連續的劃分為一個個 bank。對于 bank 可以簡單的理解為雙通道內存中通道的概念,即在不同的 bank 中的數據可以并行訪問,同一個 bank 內不同地址的數據只能串行訪問。在 Compute Capability 5.x 及之后的卡上,shared memory 具有 32 個 bank,剛好是一個 warp 中線程的數量。而如果同一個 warp 中不同 thread 均只訪問 4 Byte 數據且希望同時訪問同一個 bank 的數據將會有兩種結果。(對于每一個 thread 訪問更多數據的行為將在后面提到)
1. 兩個或多個 thread 訪問的剛好是同一個地址內的數據,那么此時將會觸發 broadcast 機制,即實際只讀取一次數據,而后廣播到這些 thread 中。
2. 兩個或多個 thread 訪問的是同一個 bank 內的數據,那么此時這些 thread 的訪問將會被強制安排為串行執行。這種訪問情況被稱為 bank conflict。
這里給出 cuda programming guide 的兩張圖來直觀的體現 broadcast 和 bank conflict。
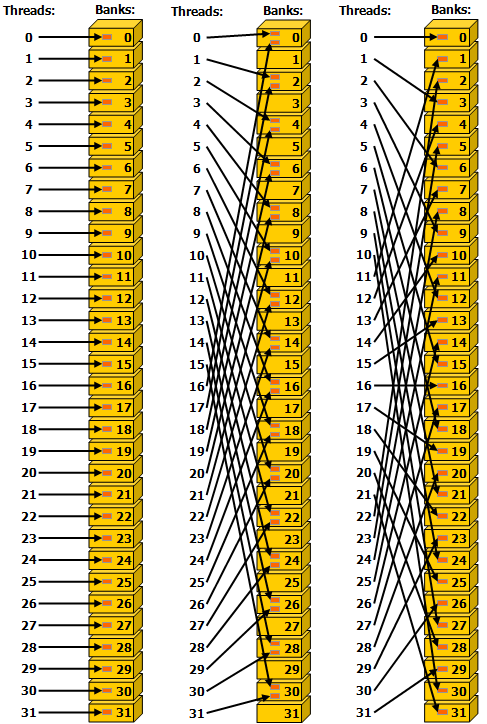
這張圖表示同一個 warp 中的 thread 按不間隔、隔一個、隔兩個 bank 對 shared memory 訪問。中間的訪問每兩個 thread 都會發生一次 bank conflict,而其他兩種訪問都不會發生 bank conflict。值得注意的一點是這張圖最右側的圖的訪問方式剛好可以達到每一個 thread 都訪問了不同的 bank 的效果。
同時考慮到 shared memory 是按照 bank 來訪問的,且與 Load/Store 單元直連,并沒有中間商賺差價,所以對于 shared memory 的訪存并不講究連續訪存,而只需要考慮是否有 bank conflict 就足夠了。因此理論上最左和最右兩列圖的訪問性能是一樣的,這與訪問全局內存有一點區別。同理,每一個 warp 連續的多次訪存也并不要求連續訪存,而在拷貝數據到 shared memory 時對 A 矩陣做矩陣轉置的目的是為了向量化訪存,而不是為了連續訪存。
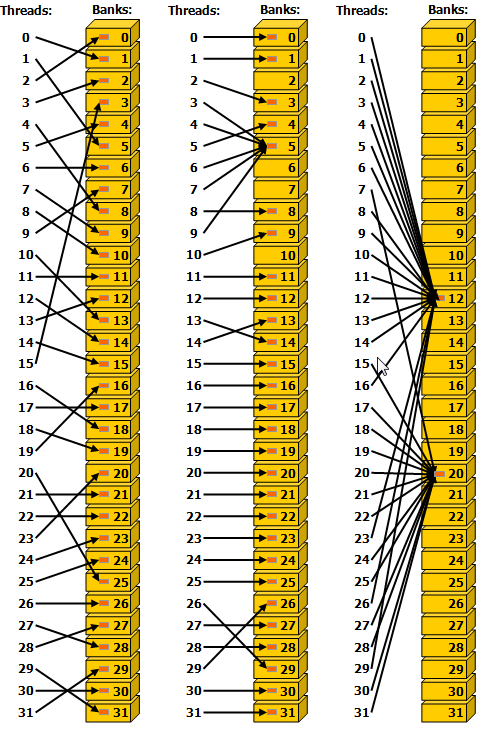
這張圖則展示了 broadcast 機制,沒啥好說的。
128-bit conflict-free store
而前文中提到,我們使用 float4 來做數據傳輸來緩解 GPU 聚合訪問的壓力,使得每一個指令都更加高效。而又因為前文所述,每個線程需要使用向量外積的方法計算矩陣乘,因此我們需要在 A 矩陣轉存到 shared memory 時做一次轉置。
但細心的同學可能注意到,如果就這么平鋪直敘的做轉置那么將會發生非常嚴重的 bank conflict,因為一個 warp 內的奇數 thread 和偶數 thread 使用同一個 bank。那么此時解決 bank conflict 的方法有兩種,第一種便是將 shared memory 的 k 維度縮小,然后直接把奇數 thread 所取的數據直接并到 M 維上,就不會有 bank conflict 的問題了。這種方法通過 index 變換,直接就能避免 bank conflict,非常巧妙,而我當時沒有想到,就沒有用這種方法。值得注意的是,盡管圖是按行隔開的,但那只是為了表示數據是如何在一個 thread 里保存的,實際寫到 shared memory 中是以一個 float 為單位,按列主序存儲到 shared memory 中。
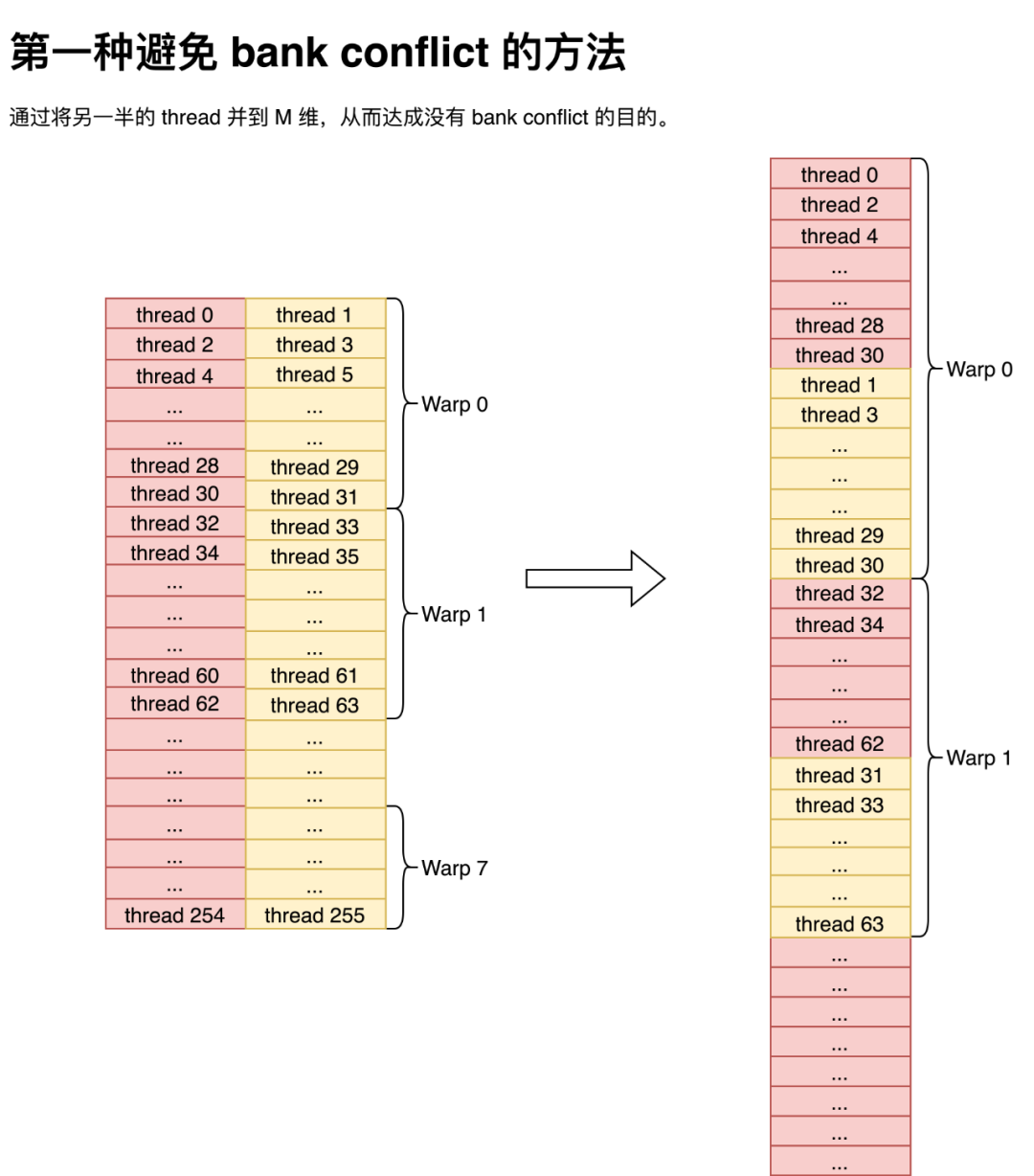
而第二種方法就非常簡單粗暴了,直接往 lda 上加 4,然后就不會有 bank conflict 了。當然這種方法的弊端也是有的,那就是會造成一部分 shared memory 的浪費。但對 sgemm 來說倒也還好, shared memory 的占用也不是導致 Occupancy 降低的原因,所以我就用了這個方法。
128-bit conflict-free load
而我們把數據存儲到 shared memory 之后,下一步便是考慮如何在沒有 bank conflict 的情況下將數據讀取出來。在本文中,我們取 為 8,在采用向量化存取時,直接按照 Warp Tiling 采用樸素的存取方法就能在沒有 bank conflict 的情況下把數據讀出來了。
為 8,在采用向量化存取時,直接按照 Warp Tiling 采用樸素的存取方法就能在沒有 bank conflict 的情況下把數據讀出來了。
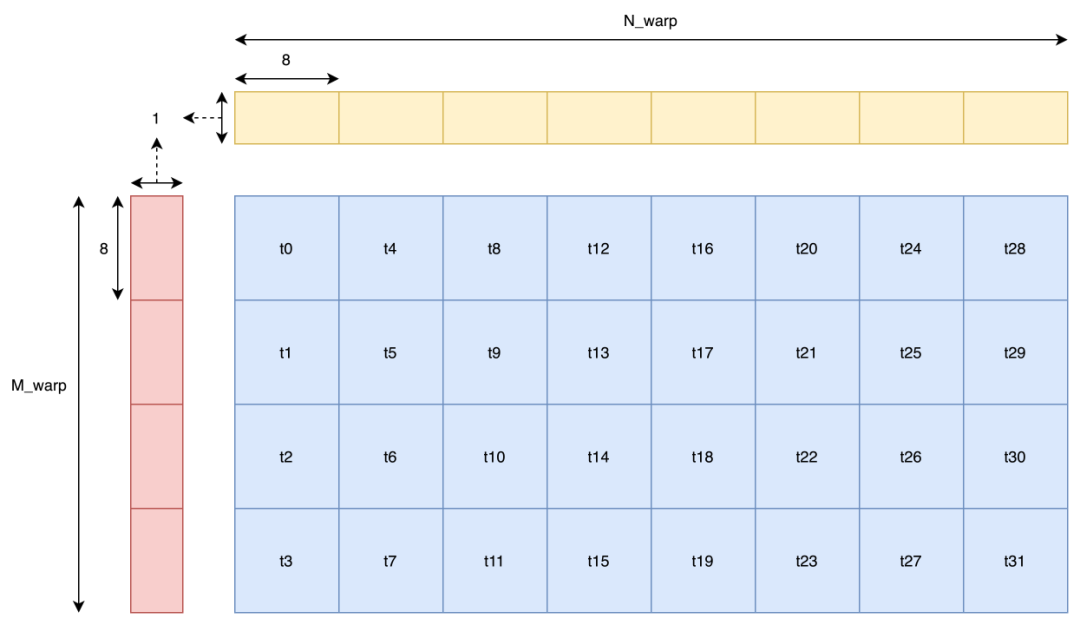
當然有的同學可能會問:既然訪存是按照一個 warp 為單位進行的,而圖中明顯讀取 B 矩陣時,t16 會和 t0 發生 bank conflict,那為什么又說不會有 bank conflict 呢?那么答案就是在做 128-bit 訪存時,warp 并不是同時讀取數據的。這里還是借用 Nvidia 在 GTC 2018 上的分享來做說明。

當 warp 中每個 thread 只讀取 4B 或更小數據時,warp 才是同時讀取的。而本文中采用 128-bit 也就是 16B 讀取,那么一個 warp 會分成 4 次操作讀取,每次操作只有 1/4 warp 工作。那么只要同一次操作內的 thread 沒有發生 bank conflict,那么就沒有 bank conflict。而上圖中 t0-t7 同時操作,它們之間并沒有 bank conflict,后面的 thread 依此類推,那么也就不會有 bank conflict。那么樸素的 warp tiling 實現代碼在這:https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/warp_tile_gemm.cu
而李少俠在代碼中采用了一種更高級的排布方式,即 z 字排布。與之相對應的,他將一個 thread 負責的小型矩陣乘拆分成四個更小的矩陣乘。同時這個拆分雖然是在地址上做的拆分,但在運算中依然可以看作是一個整體,即運算部分不用更改任何代碼而只需要在 index 上做一些變換即可。而他這么做的理由是為了更快的 broadcast。但說實話,我不是很理解,也沒搜到為什么這樣能有更快的 broadcast 性能。(而且我這么試了一下,發現確實是快了,這實在是太神奇了,歡迎大家提供一些看法。)
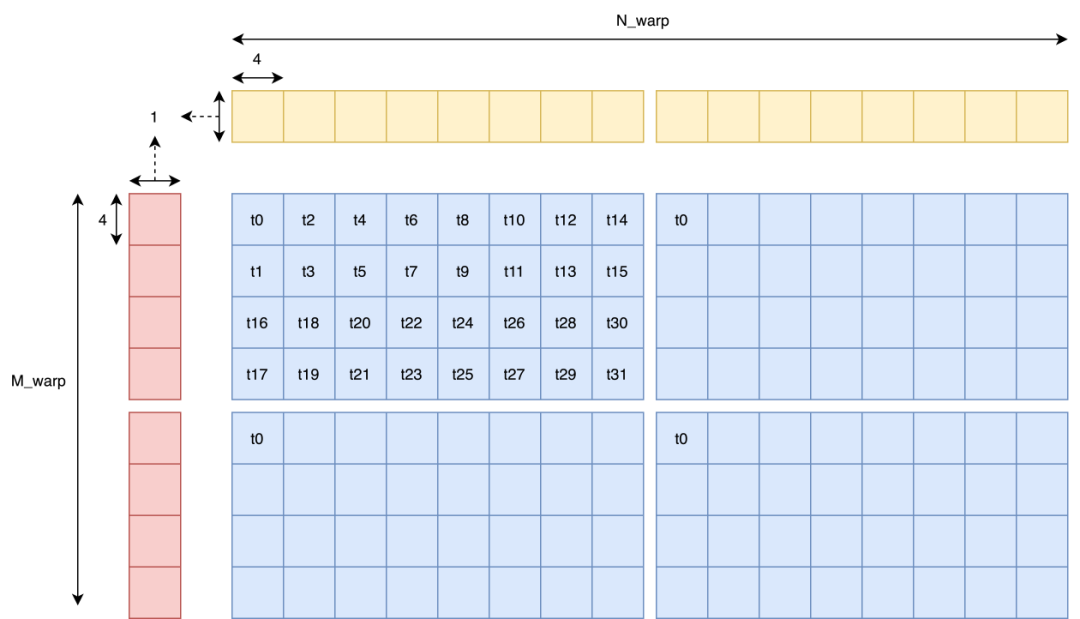
這里我們跑一個 profile 發現,確實是沒有 bank conflict 的,挺好。代碼在這:
https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/z_thread_map_gemm.cu

Block 級優化
Block 在 GPU 上基本等同于不同的 kernel 在 GPU 上運行了,所以它們之間的聯系并不是特別強烈。而它們之間的相互關系在 GEMM 語境下基本就只有 wave 和 L2 cache(一個 wave 里的 Block 共享這一塊 cache)了,良好的 Block Tiling 能提升相當可觀的 L2 cache 命中率。
但這一部分屬于 sgemm 并不是特別關心的部分,因為本身 FFMA 單元算的就不是很快,所以 Block Tiling 隨便搞搞就能夠滿足 FFMA 單元的帶寬和延遲需求了。因此,這一節的內容主要是為了有些有用到 tensor core 的同學提一個需要注意的性能提升點,其次就是有些同學可能會發現自己寫的 kernel 可能會比本文中的示例慢一點(大約 10% 左右),因此在此提一下在 sgemm 中應該怎么隨便搞搞 Block Tiling。
Wave & L2 cache Hit Rate
首先明確一下 wave 的概念,即一個 GPU 上能夠同時運行的 Block 數量。關于 GPU 是如何決定一個 wave 由哪些 Block 組成的我并沒有找到非常明確的文檔說明,但我一拍腦袋想,說不定就是樸素的按順序決定的,即 index 處于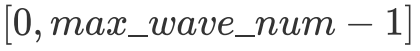 范圍內的 Block 處在第一個 wave 中,后面的 Block 依此類推。后面試了試好像的確是這樣劃分的。
范圍內的 Block 處在第一個 wave 中,后面的 Block 依此類推。后面試了試好像的確是這樣劃分的。
在明確了 wave 的概念后,我們便可以對 L2 cache 命中率做一個簡單的分析了。我們指定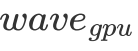 代表一個 wave 同時運行的 Block 數量,假設一個 wave 剛好能計算 C 矩陣的整數行,那么我們不難發現對于一個 wave 而言,它需要從 Global Memory 中讀取
代表一個 wave 同時運行的 Block 數量,假設一個 wave 剛好能計算 C 矩陣的整數行,那么我們不難發現對于一個 wave 而言,它需要從 Global Memory 中讀取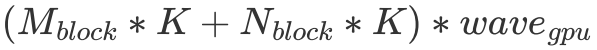 個 float。但由于有 L2 cache 的存在,假設一個 wave 讀取的數據全能被 L2 cache 裝下,那么實際只讀取了
個 float。但由于有 L2 cache 的存在,假設一個 wave 讀取的數據全能被 L2 cache 裝下,那么實際只讀取了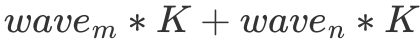 的數據。最終 L2 cache 的命中率為:
的數據。最終 L2 cache 的命中率為:
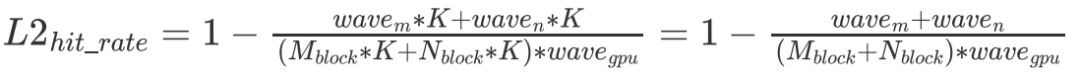
即 差距越大,L2 cache 的命中就越低。那么如果想要去優化 L2 cache 命中,一個比較直接的想法就是盡可能把一個 wave 的 Block 變成方的。但就算不搞,sgemm 也不在乎,因為其實對性能來講并沒有什么區別,所以就沒搞。
差距越大,L2 cache 的命中就越低。那么如果想要去優化 L2 cache 命中,一個比較直接的想法就是盡可能把一個 wave 的 Block 變成方的。但就算不搞,sgemm 也不在乎,因為其實對性能來講并沒有什么區別,所以就沒搞。
SGEMM Block Tiling
而在 sgemm 的語境下,假設最壞的情況即一個 wave 都不能覆蓋目標矩陣 C 的一行,且 RTX 2080 有 46 個 SM,一個 SM 能跑兩個 Block,此時
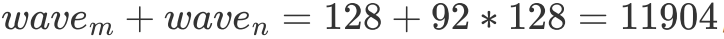
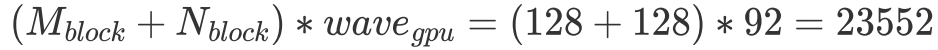 ,
,
帶入上式可得,此時 L2 cache 命中率大概是 49.4%。這里我們并沒有考慮訪問 C 矩陣的影響,在實踐中會把 L2 cache 的命中率拉低一點。但即便是如此,前文我們分析過只要 L2 cache 命中達到 20%,在帶寬上就不會造成性能瓶頸了。因此發現,就算我們采用樸素的 Block Tiling,Global Memory 訪問也不會成為訪存瓶頸。
但事實真的是這樣嗎?
細心的同學可能會發現,上圖所采用的 tiling 方式并不是直覺上的用 blockIdx.x 表示 Block 在 M 維上的位置,而是用 blockIdx.y 表示 Block 在 M 上的位置。而我們簡單調換一下代碼中 blockIdx.x 與 blockIdx.y 的順序,瞬間就有了 10% 左右的性能差距。目前網上并沒有針對這個現象的分析(因為幾乎所有人都是用的 col major 的 data layout,而且李少俠直接就在代碼里使用了更優的 tiling 方式,所以沒有人遇到這個問題),因此我這里提出一點個人的猜想,如果猜的不對還請指正。
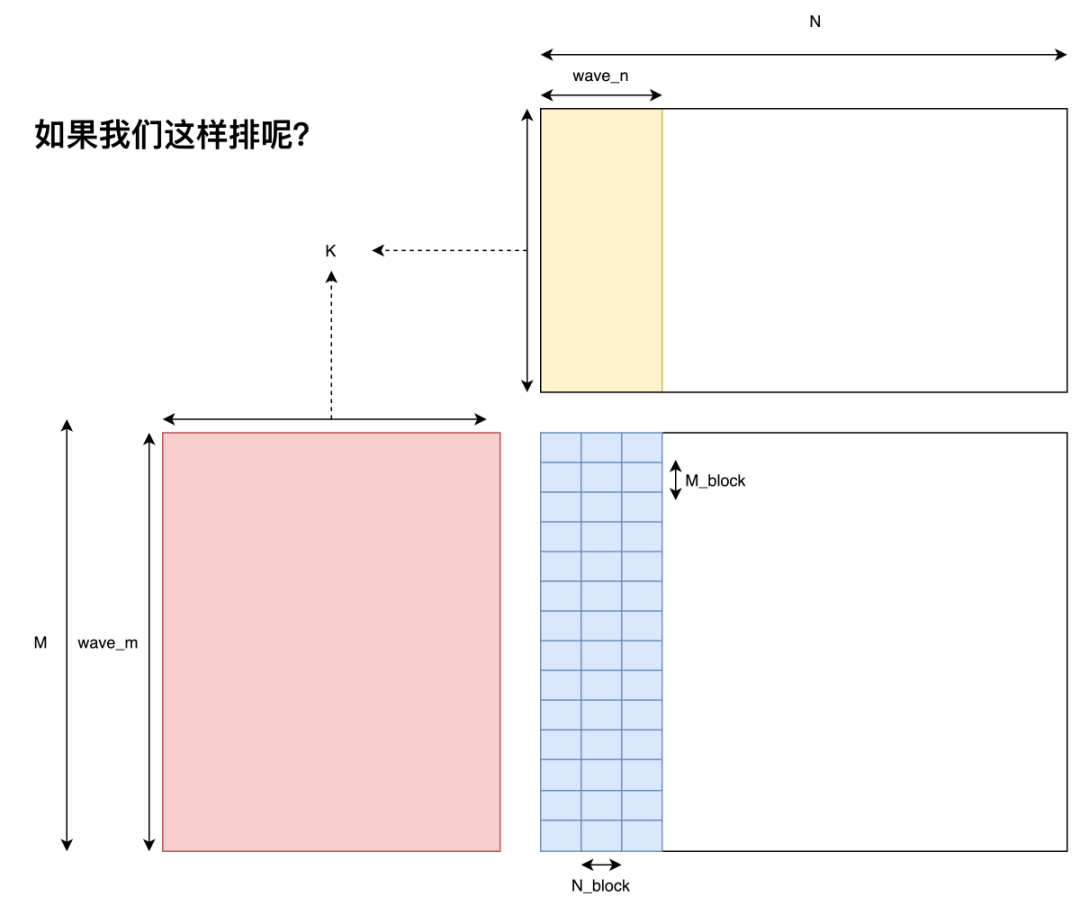
L2 cache
首先我們看一下這兩種 tiling 方式的區別在哪。最為直觀的區別就是當 N 或 M 足夠大時,采用上圖中的 tiling 方式的 wave 形狀是橫著的,而另一種 tiling 方式的 wave 形狀是豎著的,而這種豎著的形狀看起來就不是 cache 友好的訪存方式。
為什么這么說呢?因為我采用的是行主序的方式存儲的矩陣,因此如果一個 wave 的形狀是扁平的,那么每個 Block 在每一次循環遍歷 B 矩陣時只會有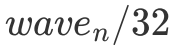 次 cache miss。這是由于 L2 cache 的 cache line 大小為 128 bytes,因此當數據從 Global Memory 中移動到 L2 cache 后,許多 Block 就能直接從 L2 cache 中讀取數據了。然而如果一個 wave 的形狀是狹長的。那么每個 Block 在第一次訪問 A 矩陣的每一行時都會有 cache miss 的情況出現,即產生
次 cache miss。這是由于 L2 cache 的 cache line 大小為 128 bytes,因此當數據從 Global Memory 中移動到 L2 cache 后,許多 Block 就能直接從 L2 cache 中讀取數據了。然而如果一個 wave 的形狀是狹長的。那么每個 Block 在第一次訪問 A 矩陣的每一行時都會有 cache miss 的情況出現,即產生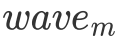 次 cache miss,而后 31 次的遍歷都不會有 cache miss。雖然兩種 tiling 方式最終 cache miss 的次數是一樣的,但這種短時間爆發的 cache miss 所帶來的延遲是非常難被各種優化手段覆蓋的,因為這種延遲不僅短時間內有很多次,同時每一次的延遲都很長,所以會造成性能損失。因此以后高性能代碼的開發中,也要注意合理的把 cache miss 分配到 kernel 運行的各個階段。
次 cache miss,而后 31 次的遍歷都不會有 cache miss。雖然兩種 tiling 方式最終 cache miss 的次數是一樣的,但這種短時間爆發的 cache miss 所帶來的延遲是非常難被各種優化手段覆蓋的,因為這種延遲不僅短時間內有很多次,同時每一次的延遲都很長,所以會造成性能損失。因此以后高性能代碼的開發中,也要注意合理的把 cache miss 分配到 kernel 運行的各個階段。
Bank Conflict
在查看兩種 Tiling 方式的 profile 我發現,采用橫著 Tiling 方式的 kernel bank conflict 更低一些。


等等,既然我們之前已經處理過 bank conflict 了,那么為什么這里還會有 bank conflict 呢?這個現象其實我也不是很清楚。但目前已知的是,在沒有加 double buffer 情況下是沒有 bank conflict 的,但加了 double buffer 之后或多或少會出現一些 bank conflict。那么至于為什么橫著 Tiling 方式的 bank conflict 更低,我就更不知道了,因此這里還請各位 dalao 賜教。
最終版本的代碼在這:https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/double_buffer_yhs_refine_gemm.cu
Epilogue
回顧本文,也基本達成了文章開頭所立的各種 flag。當然現在還是有很多問題沒有解決的,如 split K、長尾問題、分塊細調等等,這些權當是一些未來展望了。近期也在嘗試寫一下 int8 tensor core 的矩陣乘,在較小形狀上(M、N、K<=2048)能有比 cublas 更高的性能,但在更大形狀上就只有 80% 左右了(這還是 L2 cache 命中率為 90% 的結果,可能還有啥別的沒做好),所以就沒有寫 int8 tensor core 的部分。不過好歹是寫完了!
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100838 -
矩陣
+關注
關注
0文章
423瀏覽量
34564 -
代碼
+關注
關注
30文章
4791瀏覽量
68685
原文標題:如何高效實現矩陣乘?萬文長字帶你從CUDA初學者的角度入門
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
XD08M3232紅外感應單片機開發板適合初學者嗎?
我用的是multisim14.0,因為是初學者,仿真電路的時候找不到合適的模型,應該怎么辦?
手把手教你!STM32單片機入門指南:從初級到中級工程師的學習路線
適合初學者的嵌入式項目有哪些?
初學者必看:破解PCB設計常見錯誤!


如何用STM8S001J3設計一個手擺控制LED燈的程序?
解碼矩陣技術賦能電力監控,實現高效能源管理
初學者請問各位大佬
KVM矩陣系統助力企業構建高效、安全的IT基礎設施
盤點那些硬件+項目學習套件:STM32MP157 Linux開發板及入門常見問題解答
深入淺出理解PagedAttention CUDA實現

詳解微電子器件的宏原型





 工商網監
工商網監
評論