") 從統(tǒng)一視角看各類高效finetune方法實(shí)現(xiàn)最優(yōu)tuning框架設(shè)計(jì)
從統(tǒng)一視角看各類高效finetune方法實(shí)現(xiàn)最優(yōu)tuning框架設(shè)計(jì)
隨著預(yù)訓(xùn)練模型參數(shù)量越來越大,遷移學(xué)習(xí)的成本越來越高,parameter-efficient tuning成為一個(gè)熱點(diǎn)研究方向。在以前我們在下游任務(wù)使用預(yù)訓(xùn)練大模型,一般需要finetune模型的所有參數(shù)。隨著parameter-efficient tuning技術(shù)的發(fā)展,一些注入adaptor、prefix tuning、LoRA等成本更低的finetune方法被提出。那么各種各樣的parameter-efficient tuning方法之間是否存在某些潛在的關(guān)系呢?ICLR 2022就有一篇相關(guān)的研究,從統(tǒng)一的視角理解現(xiàn)有的各類parameter-efficient tuning方法,并提出了一套遷移框架,可以實(shí)現(xiàn)更接近全量參數(shù)finetune效果的部分參數(shù)finetune。
1各類tuning方法回顧
比較經(jīng)典的高效finetune方法主要包括adaptor、prefix-tuning、LoRA這三類,這里進(jìn)行一個(gè)簡單的回顧。
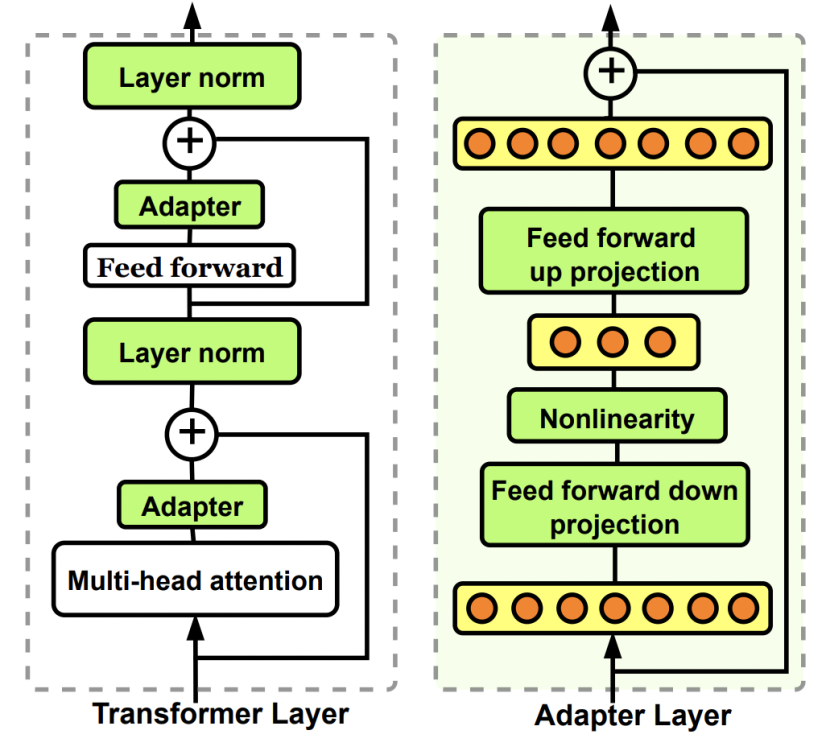
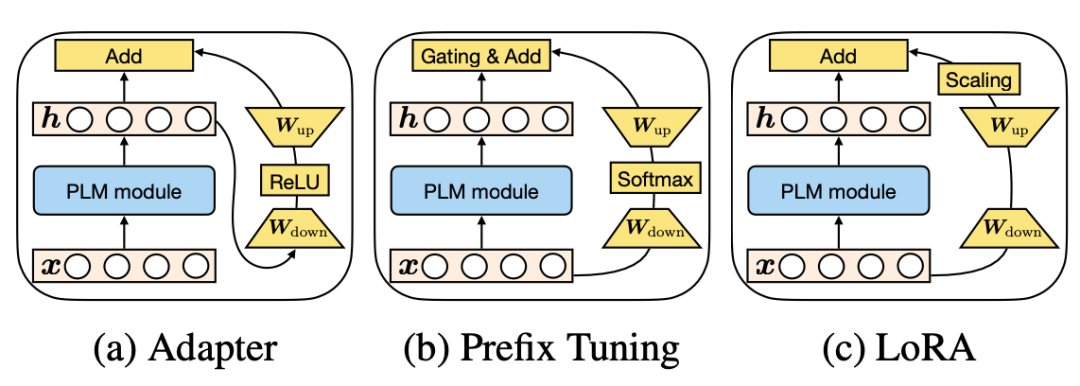
Adaptor核心是在原Bert中增加參數(shù)量更小的子網(wǎng)絡(luò),finetune時(shí)固定其他參數(shù)不變,只更新這個(gè)子網(wǎng)絡(luò)的參數(shù)。Adaptor是最早的一類高效finetune方法的代表,在Parameter-Efficient Transfer Learning for NLP(ICML 2019)這篇文章中被提出。在原來的Bert模型的每層中間加入兩個(gè)adapter。Adapter通過全連接對原輸入進(jìn)行降維進(jìn)一步縮小參數(shù)量,經(jīng)過內(nèi)部的NN后再將維度還原,形成一種bottleneck的結(jié)構(gòu)。在finetune過程中,原預(yù)訓(xùn)練Bert模型的參數(shù)freeze住不更新,只更新adapter的參數(shù),大大減少了finetune階段需要更新和保存的參數(shù)量。
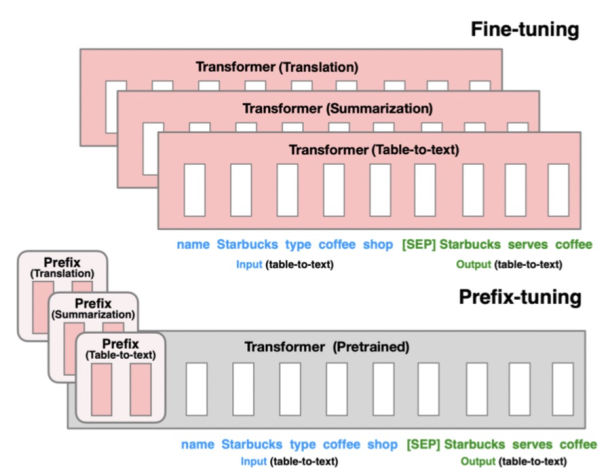
Prefix-tuning的核心是為每個(gè)下游任務(wù)增加一個(gè)prefix embedding,只finetune這些embedding,其他參數(shù)freeze。Prefix-tuning對應(yīng)的論文是Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021),這類方法的思想來源于prefix prompt,prefix embedding相當(dāng)于一個(gè)上下文信息,對模型最終產(chǎn)出的結(jié)果造成影響,進(jìn)而只finetune這個(gè)embedding實(shí)現(xiàn)下游任務(wù)的遷移。
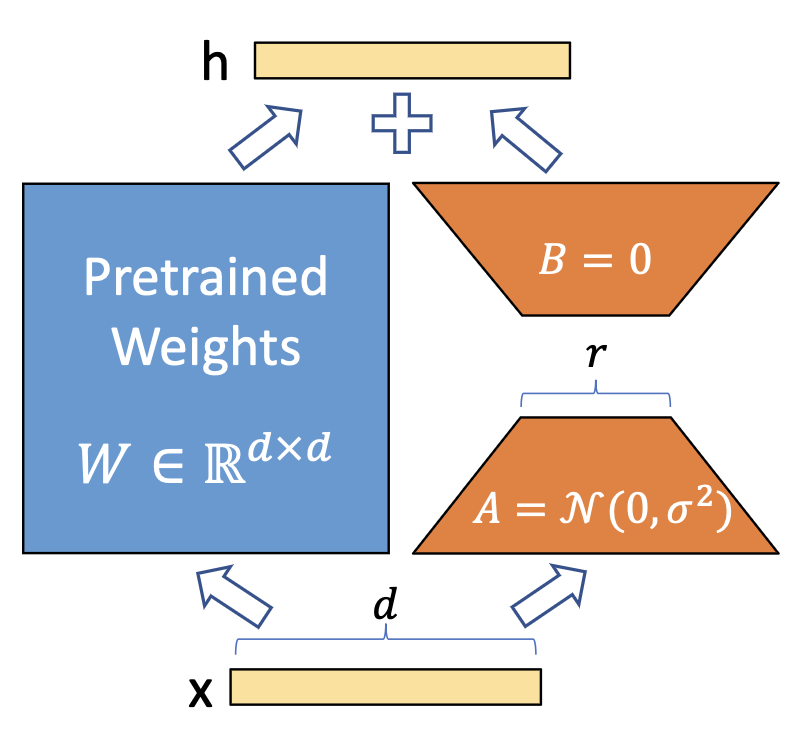
LoRA的核心是通過引入?yún)?shù)量遠(yuǎn)小于原模型的可分解的兩小矩陣建立一個(gè)旁路,通過finetune這個(gè)旁路來影響預(yù)訓(xùn)練模型。LoRA于LoRA: Low-rank adaptation of large language models(2021)論文中被提出,利用低秩矩陣替代原來全量參數(shù)的訓(xùn)練,提升finetune效率。
2統(tǒng)一視角看高效finetune方法
ICLR 2022的這篇文章從統(tǒng)一的視角來看各類不同的parameter-efficient tuning方法。首先對于prefix tuning,Transformer的每個(gè)head的結(jié)果可以進(jìn)行如下的公式推導(dǎo)變換:

其中,第一行的P就是prefix embedding,C對應(yīng)著key和value的序列向量,x代表query。經(jīng)過中間的變換后,可以發(fā)現(xiàn)prefix tuning的attention計(jì)算可以分為兩個(gè)部分的加權(quán)求和,第一部分是原始的attention,第二部分是和key或value無關(guān)的一項(xiàng),只用query和prefix embedding進(jìn)行self-attention的計(jì)算。而權(quán)重則是根據(jù)prefix embedding的attention權(quán)重。通過上述公式,我們可以從另一個(gè)視角來看prefix-tuning:即在原始attention的輸出結(jié)果上,對位相加一個(gè)由prefix embedding得到的attention值,實(shí)現(xiàn)對原始attention score的修正。
我們再來看Adaptor和LoRA兩種tuning方式的數(shù)學(xué)表示。Adaptor和LoRA方法可以分別表示為如下公式:
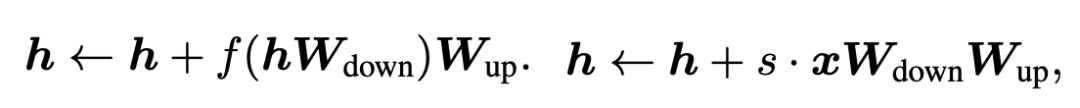
我們把prefix embedding也可以轉(zhuǎn)換成相同的表達(dá)形式:
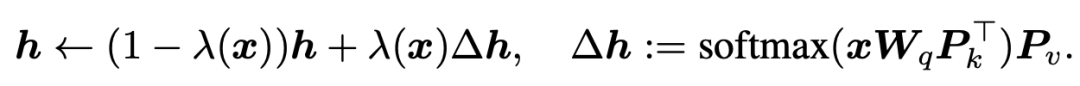
可以發(fā)現(xiàn)這些finetune方法都具有相似的表達(dá)形式。并且,prefix-tuning中prefix embedding的數(shù)量其實(shí)和Adapter中降維的維度具有相似的功能。三種方法在這個(gè)視角下的對比如下圖所示:
3統(tǒng)一的高效finetune框架
既然上述幾類方法表達(dá)形式相似,并且主要學(xué)的都是如何修改原來attention的輸出結(jié)果,那么我們可以建立一個(gè)統(tǒng)一的框架,涵蓋上述各類finetune方法。這個(gè)框架的核心是如何生成修改原始attention score的向量。為了生成這個(gè)向量,需要考慮以下4個(gè)核心模塊:
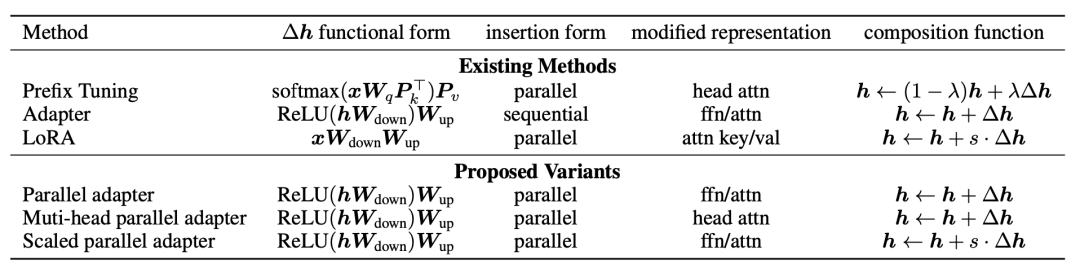
Functional Form:用什么樣的函數(shù)生成,上述方法基本都是全連接降維+激活函數(shù)+全連接升維的形式,當(dāng)然也可以設(shè)計(jì)更復(fù)雜的函數(shù)形式;
Modified Representation:對哪個(gè)位置的信息進(jìn)行直接修改;
Insertion Form:向量引入的形式,Adapter采用的是串聯(lián)的方式,根據(jù)上一層的隱狀態(tài)生成向量;而prefix tuning和LoRA采用并聯(lián)的方式,直接根據(jù)輸入序列生成向量;
Composition Function:向量的使用方式,利用adapter中采用簡單的對位相加的形式。
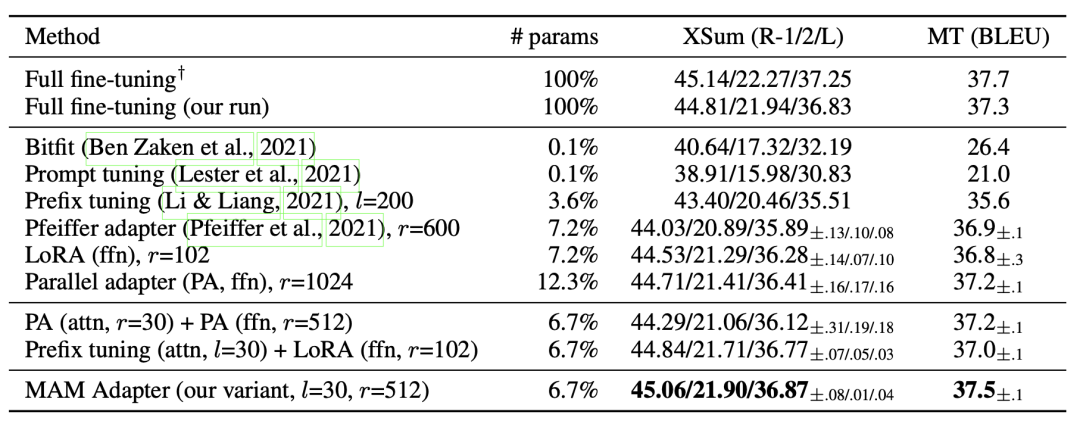
Adapter、Prefix-tuning、LoRA等方法按照 上面4個(gè)維度拆分,各自的實(shí)現(xiàn)形式如下表:
接下來,文中基于上述4個(gè)模塊設(shè)計(jì)了一些新的方法:
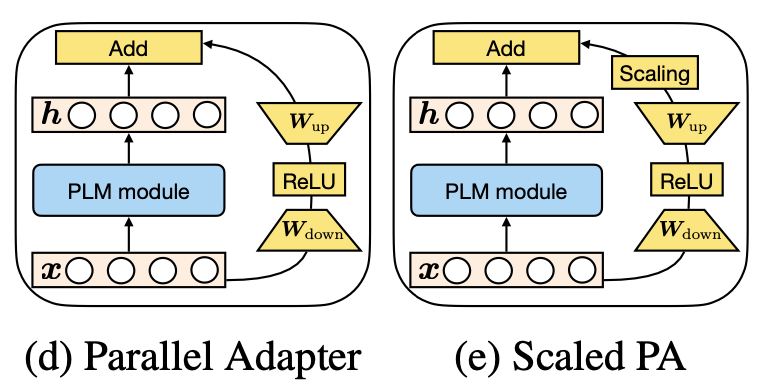
Parallel Adapter:將Adapter的串聯(lián)形式修改為并聯(lián)形式;
Multi-head Parallel Adapter:在Parallel Adapter基礎(chǔ)上修改了Modified Representation,使用旁路向量修改attention輸出結(jié)果;
Scaled Parallel Adapter:將LoRA的scaling引入進(jìn)來。
4實(shí)驗(yàn)結(jié)果
本文由于站在了更高的視角,看到了parameter-efficient tuning的統(tǒng)一形式,因此可以實(shí)現(xiàn)更加靈活的建模方式,基于這個(gè)框架尋找最節(jié)省參數(shù)量、最能達(dá)到更好效果的結(jié)構(gòu)。從下圖可以看出,本文提出的方法實(shí)現(xiàn)接接近全量參數(shù)finetune的效果,參數(shù)量也比Adapter、LoRA等方法有所減少。
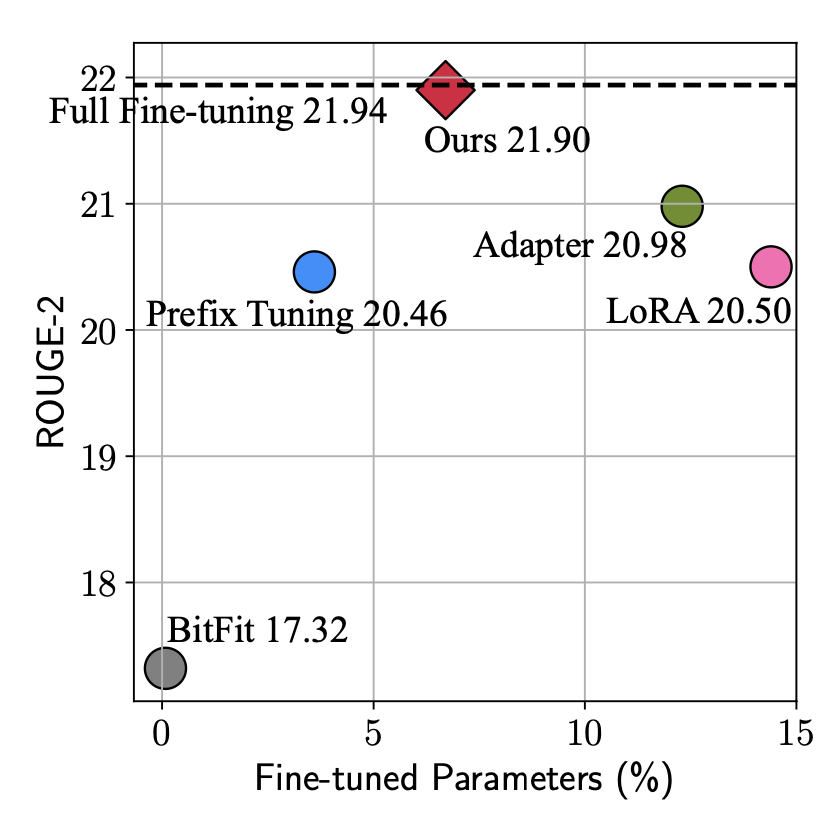
文中通過大量的實(shí)驗(yàn)對比各個(gè)模塊采用什么樣的形式能帶來最好的效果-效率的這種,并最終提出最優(yōu)的模型MAM-Adapter。核心的實(shí)驗(yàn)發(fā)現(xiàn)包括:并聯(lián)的方式比串聯(lián)的好;對FFN輸出結(jié)果的修改比對Attention輸出結(jié)果修改要好等。
5總結(jié)
本文從統(tǒng)一視角看parameter-efficient tuning,實(shí)現(xiàn)了更高視角的最優(yōu)tuning框架設(shè)計(jì)。這也啟發(fā)我們尋找同類問題不同建模方式背后原理的統(tǒng)一性,能夠跳出一種模型結(jié)構(gòu)去看各類建模方式的相似性,實(shí)現(xiàn)更高視角下對問題的理解。
審核編輯:郭婷
-
LoRa
+關(guān)注
關(guān)注
349文章
1689瀏覽量
231914
原文標(biāo)題:從統(tǒng)一視角看各類高效finetune方法
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
HarmonyOS NEXT應(yīng)用元服務(wù)開發(fā)Intents Kit(意圖框架服務(wù))習(xí)慣推薦方案概述
從特斯拉看智能駕駛未來發(fā)展
一種簡單高效配置FPGA的方法
從藍(lán)牙協(xié)議棧視角探索信道探測

使用PPC3軟件,進(jìn)入Tuning and Audio Processing模塊后,喇叭就不發(fā)聲了怎么解決?
一般高壓架設(shè)線路用的什么線
統(tǒng)一多云管理平臺怎么用?
ESP32-S3-KROVO2如何在ADF框架下實(shí)現(xiàn)wifi連接?
視覺新紀(jì)元:解碼LED顯示屏的視角、可視角、最佳視角的最終奧秘

鴻蒙Ability Kit(程序框架服務(wù))【應(yīng)用啟動框架AppStartup】
訊維融合通信系統(tǒng):如何助力企業(yè)實(shí)現(xiàn)高效溝通?
一種高效的KV緩存壓縮框架--GEAR

自制測試框架(設(shè)置界面密碼1)
【鴻蒙】NAPI 框架生成工具實(shí)現(xiàn)流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論