

今天,小編將繼續(xù)為大家?guī)鞱ullmax感知部總監(jiān)兼計算機視覺首席科學(xué)家成二康博士做客汽車之心·行家說欄目的內(nèi)容整理下篇,關(guān)于自動駕駛的數(shù)據(jù)閉環(huán)及混合數(shù)據(jù)增強的簡要介紹。Nullmax正通過將這些技術(shù)應(yīng)用到不同的量產(chǎn)項目中,推進自動駕駛系統(tǒng)的迭代升級。
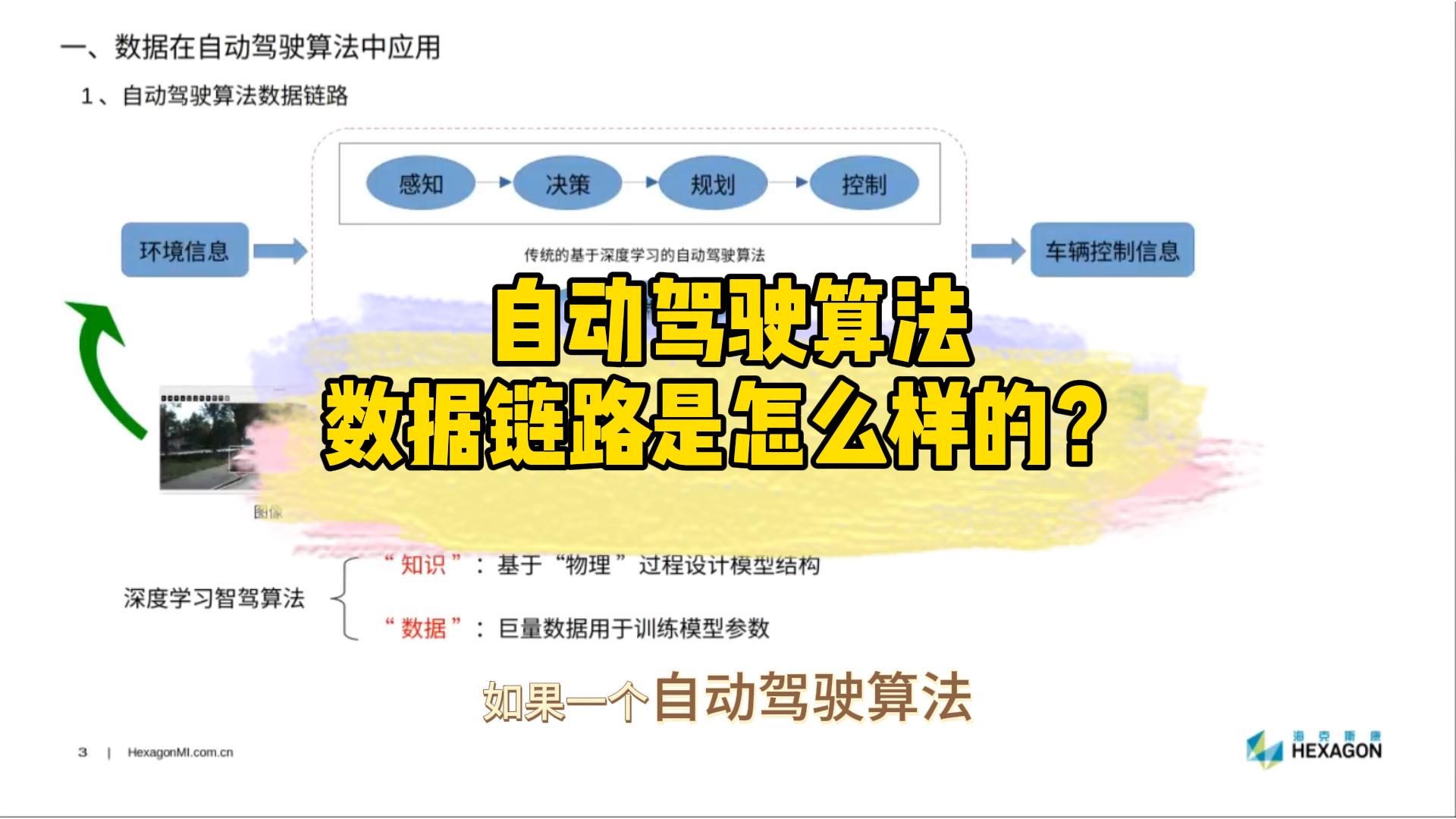
對于自動駕駛而言,數(shù)據(jù)具有至關(guān)重要的技術(shù)驅(qū)動作用,通過數(shù)據(jù)閉環(huán)高效收集、利用海量的真實數(shù)據(jù),是自動駕駛研發(fā)和落地的一項核心能力。與此同時,在無法充分獲得所需真實數(shù)據(jù)的情況下,大規(guī)模地生成虛擬樣本也是一種可行的方式。
對于自動駕駛來說,真實世界的駕駛環(huán)境變幻莫測,駕駛場景層出不窮,訓(xùn)練有素的軟件算法也會面臨長尾效應(yīng)帶來的一系列問題,遇到一些很少遇到但是很難應(yīng)對的極端場景。
因此,針對自動駕駛的長尾問題,Nullmax打造了高效的數(shù)據(jù)閉環(huán),支持行泊一體方案的大規(guī)模應(yīng)用,并且探索了大規(guī)模地生成虛擬樣本數(shù)據(jù),運用混合數(shù)據(jù)增強方法解決少見目標檢測方面的相關(guān)難題。
這樣的話,可以最大程度、最高效率地在真實場景中收集和利用困難樣本數(shù)據(jù),同時在真實場景數(shù)據(jù)難以滿足需求的情況,通過合成虛擬樣本來解決數(shù)據(jù)難題。
數(shù)據(jù)閉環(huán)
Nullmax的數(shù)據(jù)閉環(huán),名為MaxFlow自主成長系統(tǒng)。它包含了車端、云端兩大部分,車端源源不斷地獲取數(shù)據(jù),云端對數(shù)據(jù)進行分析,完成獲取、清洗、標注、訓(xùn)練以及模型驗證的整個閉環(huán)。
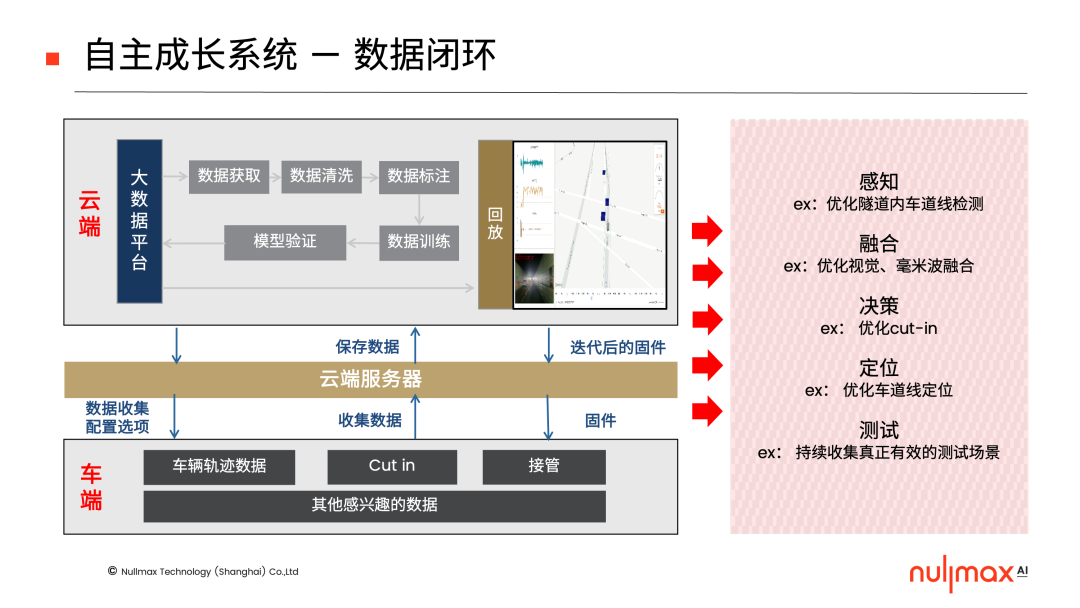
它可以為感知、融合、決策、定位、測試等環(huán)節(jié)提供全方位的幫助,實現(xiàn)持續(xù)不斷的迭代升級,驅(qū)動自動駕駛的整個系統(tǒng)自主成長。特別是在感知層面,尤其是視覺感知當(dāng)中,自主成長系統(tǒng)發(fā)揮了巨大作用。
數(shù)據(jù)閉環(huán)的數(shù)據(jù),主要源自兩個方面。一是以offline的方式,在收集全量數(shù)據(jù)后,通過data filter機制篩選出感興趣的數(shù)據(jù),然后送到云端參與訓(xùn)練等任務(wù)。二是以online的方式,在車端運用trigger機制,通過影子模式等方法,自主地收集一些感興趣的數(shù)據(jù),包括困難樣本。(點擊查看詳情)
影子模式,簡單來說就是通過對比人類司機和自動駕駛系統(tǒng)的駕駛差異,獲得一些數(shù)據(jù),提升自動駕駛系統(tǒng)的駕駛能力,從而逼近甚至是超越人類駕駛水平。對于感知層面來說,也是如此,比如AEB誤觸發(fā),那么就可以在誤觸發(fā)的時候,將視覺傳感器的數(shù)據(jù)進行回收,送到云端分析處理。這是一種相對被動的學(xué)習(xí)方式,此外系統(tǒng)也包含一些相對主動的學(xué)習(xí)方式,比如通過不確定性等進行樣本的篩選。

在線的trigger方面,包括有人機一致性、時序一致性、多傳感器一致性、多算法一致性、指定特殊場景等不同類型的設(shè)置。如果遇到變道失敗、傳感器之間結(jié)果不一致、算法結(jié)果不一致等等情況,那么就會觸發(fā)相應(yīng)數(shù)據(jù)的收集。
舉個例子,一個障礙物在時間維度而言,既不可能憑空消失,也不可能憑空出現(xiàn),這就是時序的一致性。如果一個行人在連續(xù)軌跡上消失了,那么就是典型的漏檢。
另外一個例子,就是同樣的一張圖片,用不同的算法進行一致性的校驗。比如freespace和障礙物相互校驗,可行駛區(qū)域當(dāng)中不應(yīng)存在障礙物,不然的話就是漏檢。
此外,運用多種算法校驗來篩選難樣本,也是非常重要的手段。比如行駛在路面的車輛,如果只檢測出車輪,但沒有檢測出車輛,那么極有可能這是一個比較難的樣本,比如涂裝車、挖掘機、平板車等等罕見的車輛。這種方法也可以用來篩選一些極近距離的大車,比如油罐車、拖車、掛車等等少見場景的數(shù)據(jù)。


同樣的,對于行人也可以通過頭部的檢測和身體的檢測,來校驗檢測結(jié)果,篩選困難案例。
混合數(shù)據(jù)增強
對于自動駕駛而言,除了通過數(shù)據(jù)閉環(huán)在真實場景中收集困難樣本之外,另外一種獲取數(shù)據(jù)樣本的方式,就是大規(guī)模的自動化生成虛擬樣本。
比如,在CVPR 2022上提出的合成數(shù)據(jù)集SHIFT,就是通過CARLA仿真幾乎零成本地生成真值數(shù)據(jù)。再比如Block-NeRF,利用3個月收集的數(shù)據(jù)重建舊金山市的場景,這是另外一種生成數(shù)據(jù)的方式,通過一些樣本的視角來生成其他視角的虛擬圖像。
此外,通過計算機圖形學(xué)和生成式模型相結(jié)合,也能夠以Neural Rendering的方式生成大量的虛擬數(shù)據(jù)。
在ICRA 2022上,Nullmax同樣也提出了一種生成虛擬樣本的方式,通過混合數(shù)據(jù)增強的方法,解決罕見目標檢測的難題。(點擊查看詳情)
因為對自動駕駛而言,即使專門去篩一些數(shù)據(jù),獲得的數(shù)據(jù)量仍可能還是很小。收集一些少見的樣本,比如錐形筒相關(guān)的場景,其實依然很難。
所以我們當(dāng)初的想法是,既然擁有大量沒有錐形筒的真實場景,那么能不能將錐形筒的mask(掩膜)貼到這些真實場景圖片上面,幾乎零成本地自動生成大量少見樣本呢?這就是我們想要通過混合數(shù)據(jù)增強來實現(xiàn)的目標。
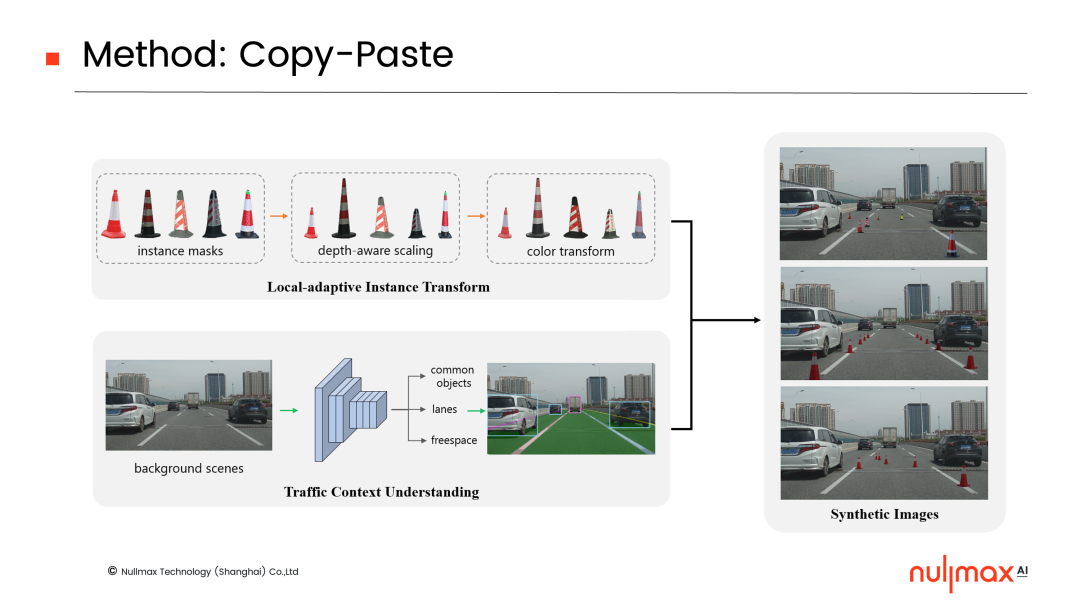
這當(dāng)中有兩個非常關(guān)鍵的問題,一個是錐形筒mask貼到什么位置,一個是怎么貼mask。因此,我們提出了一個多任務(wù)的深度學(xué)習(xí)網(wǎng)絡(luò),為交通場景提供相應(yīng)的約束,確保mask沿著車道線貼到freespace上,而不是車上。同時,還提出了一個局部自適應(yīng)的顏色變換,讓mask能夠自動適應(yīng)每張圖片本身的顏色分布。
實驗結(jié)果顯示,對錐形筒這類少見樣本來說,如果只有少量數(shù)據(jù),檢測效果其實比較一般。但是在結(jié)合我們的混合數(shù)據(jù)增強方法后,檢測效果可以大幅提升。
Nullmax已經(jīng)開源相應(yīng)的ROD(Rare Object Dataset)數(shù)據(jù)集,當(dāng)中包含1萬多張的數(shù)據(jù),分布在不同的道路、天氣和光照條件。如果大家感興趣,歡迎登陸網(wǎng)站下載 https://nullmax-vision.github.io/。
篇后語
為了更好地實現(xiàn)行泊一體,Nullmax開發(fā)了能夠自動化支持行車和泊車兩類任務(wù)的感知基礎(chǔ)架構(gòu),從而最大程度地復(fù)用軟件算法。這其中,就包括了數(shù)據(jù)、訓(xùn)練和部署。
基于這套架構(gòu),Nullmax能夠通過數(shù)據(jù)閉環(huán)收集的海量真實數(shù)據(jù),以及大規(guī)模生成的虛擬樣本,以非常高效、經(jīng)濟的方式提供提供豐富、充足的訓(xùn)練樣本,對算法進行真實和混合數(shù)據(jù)的混合訓(xùn)練,打造出一個滿足全場景自動駕駛需求的「超級大腦」。
后續(xù),我們將介紹這套強大的感知基礎(chǔ)架構(gòu),敬請關(guān)注!
審核編輯 :李倩
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7239瀏覽量
90989 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14193瀏覽量
169493 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
679
原文標題:Nullmax研習(xí)社 | 從數(shù)據(jù)閉環(huán)到混合數(shù)據(jù)增強,關(guān)于自動駕駛數(shù)據(jù)的那些事
文章出處:【微信號:Nullmax,微信公眾號:Nullmax紐勱】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
新能源車軟件單元測試深度解析:自動駕駛系統(tǒng)視角
東風(fēng)汽車推出端到端自動駕駛開源數(shù)據(jù)集

助力從真實駕駛到虛擬測試# 仿真# 測試# 場景# 合成數(shù)據(jù)# 汽車# 數(shù)據(jù)# 自動駕駛# 人工智能# 科技
技術(shù)分享 |多模態(tài)自動駕駛混合渲染HRMAD:將NeRF和3DGS進行感知驗證和端到端AD測試


自動駕駛開發(fā)需要海量數(shù)據(jù),但真實數(shù)據(jù)難以覆蓋所有復(fù)雜場景,如何解決?# 自動駕駛# 仿真# #汽車電子
從自動駕駛行業(yè),分析數(shù)據(jù)標注在人工智能的重要性
以自動駕駛角度解析數(shù)據(jù)標注對于人工智能的重要性
從《自動駕駛地圖數(shù)據(jù)規(guī)范》聊高精地圖在自動駕駛中的重要性
標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

連接視覺語言大模型與端到端自動駕駛

FPGA在自動駕駛領(lǐng)域有哪些優(yōu)勢?
FPGA在自動駕駛領(lǐng)域有哪些應(yīng)用?
VSP2272適合數(shù)碼相機的完整混合信號處理IC數(shù)據(jù)表






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論