 傳統CV和深度學習方法的比較
傳統CV和深度學習方法的比較
摘要:
深度學習推動了數字圖像處理領域的極限。但是,這并不是說傳統計算機視覺技術已經過時了。本文將分析每種方法的優缺點。本文的目的是促進有關是否應保留經典計算機視覺技術知識的討論。本文還將探討如何將計算機視覺的兩個方面結合起來。評論了幾種最近的混合方法論,這些方法論證明了改善計算機視覺性能和解決不適合深度學習的問題的能力。例如,將傳統的計算機視覺技術與深度學習相結合在新興領域(例如全景視覺和3D視覺)中很流行,而對于這些領域,深度學習模型尚未完全優化。
1. 介紹
深度學習被使用在數字圖像處理中,解決困難問題,比如圖像著色,分類,分割和檢測。CNN使用大量數據和大量的計算資源來實現預測的性能,一些被認為無法解決的問題實現了超過人類的精度的解決方案。
是不是深度學習就可以解決所有問題呢?是不是它就比傳統計算機視覺方法好呢?但是深度學習無法解決所有的問題,在一些問題上,具備全部特征的傳統技術仍是更好的方案。此外,深度學習可以和傳統算法結合,以克服深度學習帶來的計算力,時間,特點,輸入的質量等方面的挑戰。
這篇論文會提供對比在DL統治計算機視覺之前的傳統方法和深度學習的比較。這篇論文會總結傳統算法,一些可以作為DL有力的補集,去完成DL不能解決的問題。這篇論文然后會總結一些最近的結合DL和CV的研究,如3D感知,或者說3D點云物體定位,物體檢測,語義分割等。最后,使得3D深度學習獲得在2D上一樣成功的可能發展方向將會被討論。
2. DL和傳統計算機視覺的比較
2.1 什么是深度學習?
要獲得對DL的深刻理解,我們需要去考慮描述分析和預測分析。
描述分析:涉及到定義了一個可理解的數學模型,模型描述了我們希望觀察到的現象。模型包括了對過程收集數據,形成對模式(pattern)的假設,通過比較描述模型的結果和真實的結果驗證假設。但是總是有風險,因為對某些復雜的,隱藏或者非直覺性的理解不到位,科學家和工程師會忽略了某些變量,使其沒有包含進模型中。
預測分析:包括發現一些規則,這些規則支持一種現象,形成一個預測模型可以最小化真實結果和預測結果之間的誤差,當考慮到所有可能的影響因素時。
2.2 深度學習的優勢
DL的快速發展和設備能力(包括計算能力,內存容量,功率消耗,圖像傳感器分辨率和光學)的提高使得基于視覺的應用快速傳播。和傳統CV比較,DL有更好的精度,并且需要更少的專家分析和調參,同時可以利用如今容易獲得的大量的視頻數據。同時,DL有很好的靈活性,因為CNN模型和框架可以使用新的自定義數據重新訓練,相比較于更局限領域的傳統的圖像處理技術。
在DL出現前,傳統的CV方法時通過特征提取,比如目標檢測時,通過對圖像的特征描述向量檢索,如果很大一部分特征時重復的,則一副圖像就分類含有一種特殊的物體。傳統CV的難點在于必須選擇哪一種特征時最重要的在每張圖片中。這很大程度上依賴于工程師的判斷和長時間的調試的誤差處理,來決定哪一個特征可以區分不同類型的物體。同時,特征的定義也需要工程師調參得到。
DL引入了端對端(end-to-end)學習,即機器只是獲得了已經被標記上物體類型的圖像數據集。因此,DL模型再給定數據上被訓練,其中神經網絡得以找到背后的模式,自動找到最具有描述性和明顯的特征。傳統的提取手動特征的專業知識已經被通過迭代在DL架構的知識和專業性代替。如下圖所示。
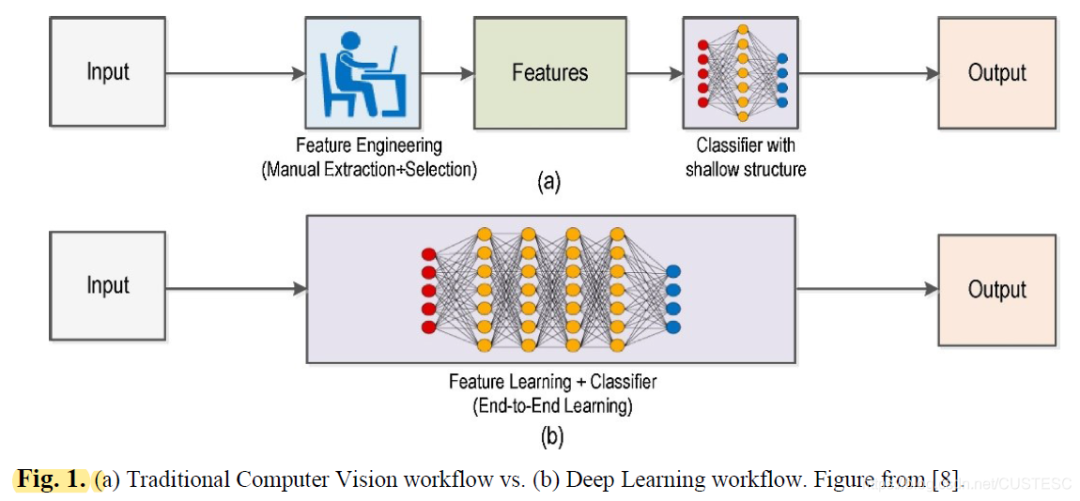
CNN使用核,也叫做濾波器,在整幅圖中檢測特征。CNN空間上在一個給定圖片上卷積這個核,去確認要檢測的特征是否存在。卷積操作通過計算濾波器和給定濾波器覆蓋區域的點積實現。
為了促進權重的學習,卷積層輸出相加添加一個偏置項,然后輸入到一個非線性激活函數,如Sigmoid,TanH,ReLU。基于數據和不同的分類任務,激活函數選擇有所不同。
為了加速訓練過程和減少內存消耗,卷積層后面經常添加池化層來去除輸入特征的多余(Redundancy)。如圖2,一般來說,深層神經網絡也許會有多對卷積層和池化層。最后,一個全連接層展開之前層體積,為一個特征向量,然后輸出層計算得分(置信度或者可能性。)。輸出結果一個回歸函數,比如softMax,其映射所有值到一個向量,其總和為1。
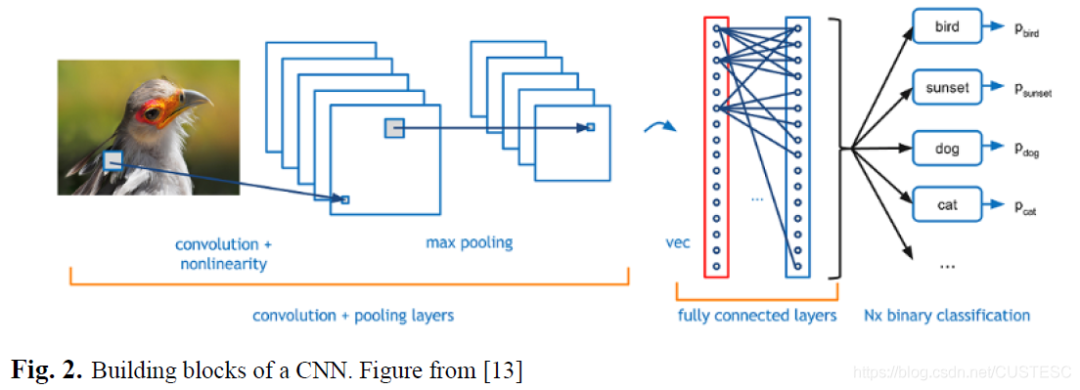
但是DL仍然是一個CV的工具。最常見的neural networkCNN中的卷積,就是在圖像處理技術中廣泛使用的技術。
2.3 傳統機器學習的優勢
傳統的機器學習分類算法使用特征描述子,再結合SVM,KNN等機器學習分類算法解決CV問題。
DL有時候矯枉過正,傳統算法可以解決一個問題以更簡單,更少的代碼。傳統的算法很簡單,只是顏色閾值或者像素技術,但是他們可以非常通用,在各種圖像上表現相同。可以對比的是,DL學習到的特征只能基于訓練集,不能再除訓練集以外的圖像中表現很好。所以,SIFT等算法經常用在圖像拼接和3D網格重建中。還有例子,比如分別兩個不同顏色的物體,DL需要構造訓練集,然而簡單的顏色閾值就可以實現。一些問題可以通過簡單和更快的技術,而不是DL。
如果一個DNN在訓練集以外表現很差?如果訓練集很小,機器可能會過擬合訓練數據,不能通用化這個任務。在這種情況時,DL模型被批評為黑匣子。傳統CV有著完全的透明性,可以判斷算法是否在訓練環境外。工程師具備對于問題的見解,可以轉換算法,如果失敗,可以調整參數在更大的圖片集中表現出更好的參數。
如今,傳統算法可以被使用,當問題被簡化到可以布置到低消耗的控制器或者通過加強特征限制問題對于DL的使用。之后我們會討論一些傳統的技術,如何使用來提高網絡訓練。最后,還有很多問題在CV中:機器人技術 ,增強現實,自動全景拼接,虛擬現實,3D建模,運動估計,視頻穩像,運動捕捉,視頻處理,場景理解,這些問題無法使用DL輕松的解決,但是可以從傳統CV中獲得幫助。
3.傳統計算機視覺的挑戰。
3.1 混合手動調整方法和DL獲得更好的表現
這里在傳統CV和基于學習的方法之間有清晰的權衡。傳統計算機視覺是完善的,透明的,對于表現和功率效率優化過的,盡管DL以大數量計算資源的代價提供更好的精度和通用性。
混合方法結合傳統CV和深度學習方法,提供了兩種方法的優點。這種結合在需要快速處理的高性能系統中很實用。
機器學習和深度網絡的融合已經變得非常流行,因為這樣可以產生更好的模型。混合視覺處理實施可以引入性能優點,可以實現在多累積操作中130X-1000X倍的減少,大約10X的幀率的提高,想比較于單純的DL。進一步的說,這種混合系統只需要一般的內存容量,只需要更低的CPU資源。
3.2 克服DL的挑戰
DL也存在挑戰。最新的DL方法可以實現更好的精度,但是這種提升需要以百萬次更多的數學操作和對于處理能力的要求增加。
使用DL的視覺處理結果也依靠于圖像分辨率。在物體分類實現足夠的性能,需要一個高分辨率的圖像和視頻,也導致了需要處理的數據增加。圖像分辨率對于遠處物體檢測和分類的一些應用非常重要。使用sift或者光流的幀減少技術(frame reduction),可以首先識別感興趣區域,減少訓練需要的處理時間和數據量。
DL需要大數據。當大的數據集或者高的計算能力不可獲得時,傳統的方法可以參與進來。訓練DNN需要很長的時間。需要很多次迭代,不同的參數獲得的誤差完全不一樣。最常見的技術,用于減小訓練時間的是遷移學習。傳統的CV技術,比如離散傅里葉變換,證明可以用來使用加速卷積。
但是領域特殊更簡單的任務一般不需要太多數據。在預處理過程中,傳統CV方法用來增加訓練樣本。預處理步驟中可以變換數據,使得關系或者模式,在訓練模型前能夠更簡單的描述。數據增強是一種常見的預處理任務,用于當訓練數據很少的時候,包括實現隨機旋轉,位移,剪切,用來增加訓練集。
3.3 利用邊緣計算
如果在邊緣運行算法和神經網絡推理,與基于云的方法比較,可以較少延遲,成本,云儲存和處理需求及帶寬需求。通過避免在網絡上傳輸敏感或者可識別的數據,邊緣計算同樣可以滿足私密和安全要求。
混合或者組合的方法,涉及傳統CV和DL利用了邊緣的異構計算能力。一種異構的計算架構,由CPU組合和微控制器核心處理器組成。DSP,fpga和AI加速設備可以分配不同的工作負載,實現最有效率的計算引擎。測試效果顯示,擋在DSP和CPU上面執行DL推理時,對象檢測的延遲減小了10倍。
多種混合CV方法已經證明了在邊緣應用的優勢。比如,臉部表情識別有一種新的特征損失,它添加了人工特征到訓練的過程中,這是嘗試去減小人工特征和學習得到特征之間的差別。使用混合的方法同樣顯示了其利用來自其它傳感器數據的能力的優勢。
3.4 不適合DL的問題
機器人,增強現實,自動全景拼接,虛擬現實,3D建模,運動抑制,視頻穩定,運動捕捉,視頻處理和場景理解,這些領域不能直接使用DL的方法,但是需要結合傳統技術來解決。
DL方法在解決閉環(close end)問題時表現優秀,這些問題中潛在的信號可以被映射到一個限制的類別中,同時有足夠的可以獲得的數據,訓練集和測試集的數量十分相似。但是當偏離以上假設時,就會導致問題,所以明確哪些問題是DL不擅長解決十分重要的。DL必須要得到其它技術的支持。
其中一個問題時DL算法學習視覺關系時局限的能力。比如識別一幅圖像中的多個物體是否時同樣或者不同的。一些文獻證明了包括注意力和感知組是實現這種抽象視覺推理的關鍵計算組成。
同樣的,ML模型很難處理具有先驗的模型,意味著不是所有都可以從學習中獲得,所以一些先驗比如植入到模型中。比如3D視覺具有強的先驗才能有效,比如基于圖像的3D建模要求光滑性,輪廓和照明信息。
3.5 3D視覺
3D視覺系統已經變得更容易接觸,因為3D卷積神經網絡的極大發展。這個新出現的領域稱為幾何深度數學(Multiple Deep Learning),應用方向包括:視頻分類,計算圖形學,視覺和機器人技術。
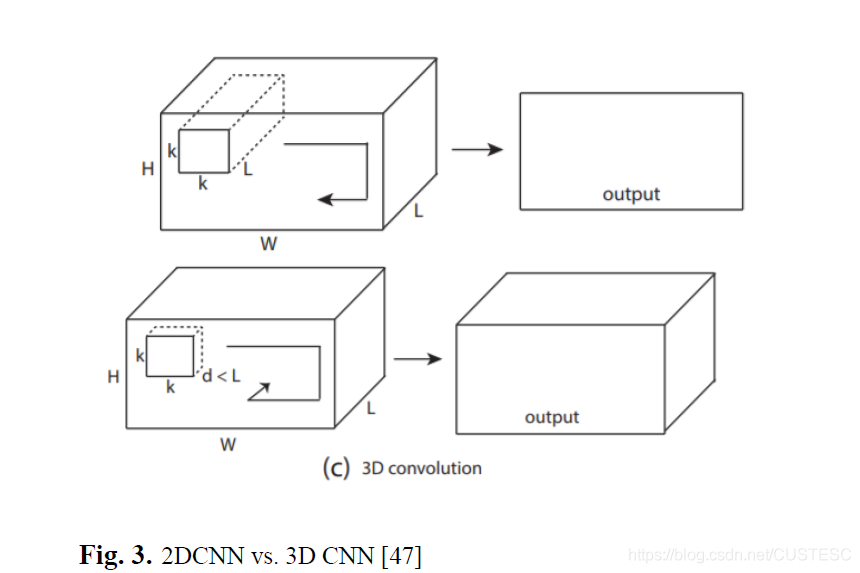
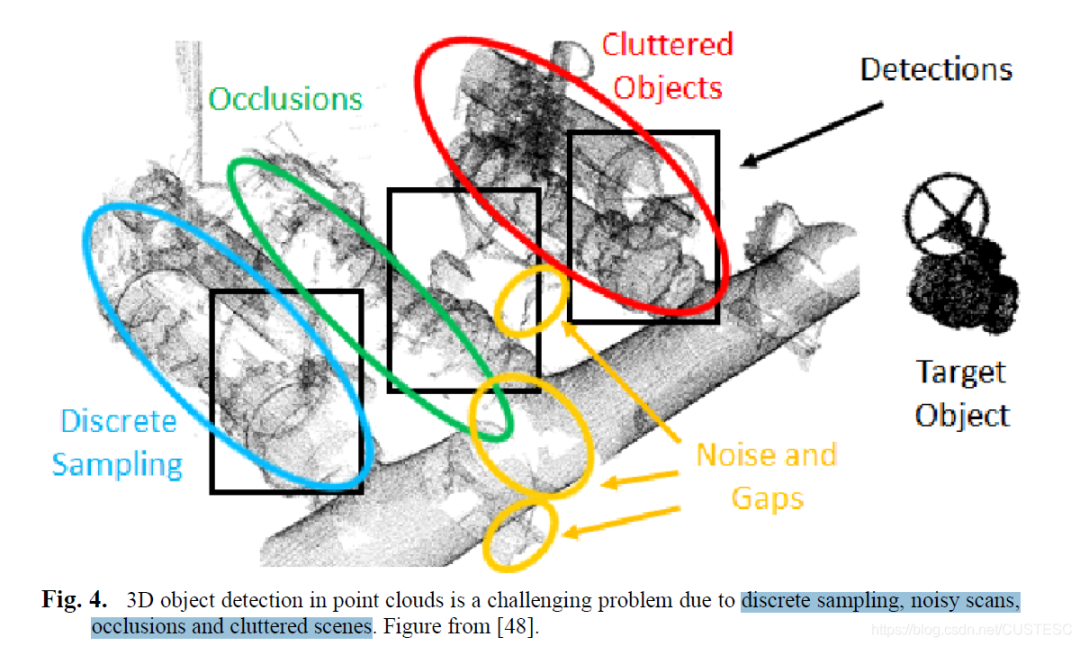
輸入的尺寸在內存上而言比傳統RGB圖像大得多,kernel卷積計算在3D空間中進行。因此,在分辨率上計算復雜度立方增長。3D CV難度在于引入了更多維度,帶來了更多不確定性,比如離散采樣,噪聲掃描,遮擋和混亂的場景。
基于FFT的方法可以優化3D CNN可以減少計算量,但是以增加的內存需要為代價。WMFA(Winograd Minimal Filtering Algortihm)實現了兩倍的加速,相比較于cuDNN,并且沒有增加內存。
幾何深度學習處理深度學習技術的到3D數據的擴展。3D數據可以分為歐幾里得和非歐幾里得。
3D歐幾里得有底層的網格結構,這允許全局參數化和像2D一樣有常見的坐標系統。這使得2D深度學習樣式可以同樣使用在3D數據中,所以歐幾里得更適合分析簡單的網格物體,如椅子,平面。
3D非歐幾里得數據沒有網格化結構,其中沒有全局參數化。因此,擴展經典DL技術對于這種表示,是一種挑戰的任務,僅僅最近被PointNet實現。
連續的形狀信息,這種有用的信息總是在轉換到體素表示時損失掉。
3.6 SLAM
視覺SLAM是SLAM的一個子集,其中視覺系統替代雷達作為組成場景地標定位。視覺SLAM具有攝影測量的優勢,豐富視覺數據,低成本,輕便和低能源消耗,沒有后處理中相關的繁重的計算工作。視覺SLAM包括環境感知,數據匹配,運動估計,場景更新和新地標定位。
建立一個視覺物體如何在不同的條件下出現,如3D旋轉,尺度變換,光照變化,從那些代表的變換,會使用較強形式的遷移學習去實現零擊或一擊(zero-shot one-shot)學習。特征提取和數據表示方法對于減少ML訓練樣本是有用的。
一種兩步方法常常使用在基于圖像的定位中,場景識別后做姿態估計。場景識別一般是計算每一幅圖像的全局描述子,然后聚類局部描述子,使用bag of words的方法。然后每一幅的圖像全局描述子,在詞袋中搜索,最匹配的全局描述子提供了一個查詢圖像的大致的定位在參考地圖中。在姿態估計中,查詢圖像精確的姿態通過一些算法,比如PnP和幾何驗證算法,實現更精確的計算。
基于圖像的場景識別很大程度上依賴于提取圖像特征描述子的能力。不幸的是,對于LiDAR掃描中,沒有一個類似SIFT算法提取局部描述子。
另外一個方法,從RGBD數據中構建了多模態特征,而不是深度處理。對于深度處理部分,他們采用了有名的基于表面向量的colouration方法,因為這種方法已經被證明是有效和魯棒的。另外一個方法是利用傳統技術,如Force Histogram Decomposition,一種基于圖的等級描述子,可以使得在結構子部分的空間關鍵和形狀信息被特征化。
3.7 360度相機
360相機(也稱為全向或球形或全景相機)是一種在水平面中具有360度視場,或者具有(大約)覆蓋整個球體的視野的相機。全向攝像機在需要大視野覆蓋的機器人等應用中很重要。360攝像機可以代替多臺單眼攝像機,并消除盲點,這顯然對全向無人地面飛行器(UGV)和無人飛行器(UAV)有利。由于球形攝像機的成像特性,每個圖像都可以捕獲場景的360°全景圖,從而消除了對可用轉向選擇的限制。球形圖像的主要挑戰之一是由于超廣角魚眼鏡頭造成的鏡筒變形,這使傳統的人類視覺啟發方法(例如車道檢測和軌跡跟蹤)的實現變得復雜。通常需要額外的預處理步驟,例如事先校準。
全景拼接是另外一個開放的研究問題。實時拼接方法使用一組可變形的網格和最終圖像,并使用魯棒的像素著色器組合輸入。另一種方法將幾何推理(線和消失點)提供的準確性與DL技術(邊緣和法線貼圖)實現的更高水平的數據抽象和模式識別相結合,以提取結構并生成室內場景的布局假設。在稀疏結構的場景中,基于特征的圖像對齊方法通常會因缺少獨特的圖像特征而失敗。相反,可以應用直接圖像對準方法,例如基于相位相關的方法。
3.8 數據集標記和加強
有很多對于CV和DL的結合的爭論,最后總結到結論是我們需要重新評估我們從基于規則和數據驅動的方法。傳統CV中,我們知道操作的意義,但是DL導致我們需要的只是更多的數據。這也許是進步,也可能是退步。
最基礎的問題是,目前的研究中,對于特殊的應用中的先進的算法或者模型,沒有更多足夠的數據。將自定義的數據集和DL模型結合在一起回事未來需要研究論文的主題。所以許多研究者的輸出不僅包括DL算法,也包括數據集或者收集數據的方法。數據標記會是DL工作流程的瓶頸,因為這需要大量的人工標記。主要是在語義分割應用中,每個像素都需要精確的標記。這里也有很多有用的工具用于半自動化這種過程。
最簡單和最常用的方法來克服限制的數據集,減小模型的過擬合是通過人工擴大數據集,方法是使用保持標記的轉換(label-preserving transformations)。比如使用裁剪,尺度變換,旋轉圖像來人工生成數據。數據增強過程需要非常少的計算并且可以在DL訓練流水線內實現,從而不需要將轉換后的圖像存儲在磁盤上。用于數據集擴充的傳統算法方法包括主成分分析(PCA),添加噪聲,在特征空間中的樣本之間進行內插或外推以及根據分割注釋對對象周圍的視覺環境進行建模。
結論
只知道CV的DL方法,會很大程度上限制CV工程師的解決方案類型。學習DL之前的CV技術,可以提供一些直覺方面的認識和掌握一些有用的工具。
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
45977 -
機器學習
+關注
關注
66文章
8406瀏覽量
132566 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:傳統CV和深度學習方法的比較
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何用OpenCV的相機捕捉視頻進行人臉檢測--基于米爾NXP i.MX93開發板
NPU在深度學習中的應用

AI大模型與深度學習的關系
基于Python的深度學習人臉識別方法
深度學習中的時間序列分類方法
基于AI深度學習的缺陷檢測系統
深度學習與nlp的區別在哪
深度學習的基本原理與核心算法
TensorFlow與PyTorch深度學習框架的比較與選擇
深度學習的模型優化與調試方法
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論