 50億海量數據如何高效存儲和分析? 華為云數據庫GaussDB (for Cassandra) 3個秘訣搞定
50億海量數據如何高效存儲和分析? 華為云數據庫GaussDB (for Cassandra) 3個秘訣搞定
50億海量數據如何高效存儲和分析?
華為云數據庫GaussDB (for Cassandra) 3個秘訣搞定
當下,信息社會正在從互聯網時代走向物聯網時代,信息交互變得更加龐雜、高效和智能。對于互聯網公司和IOT企業來說,既是機遇,也是挑戰。因為,企業不可避免的要面對數據量劇增帶來的一系列問題:如何高效存儲和擴容,如何在對原有業務改動最小的情況下做到智能化和實時分析。
針對挑戰,華為云GaussDB (for Cassandra)為客戶提供了強擴展、高存儲、高效導入/導出和實時分析等一系列能力,并成功服務了眾多互聯網公司和IOT企業,獲得了客戶的高度認可和支持。本文將以其中一個客戶業務的痛點問題舉例,聊聊高效存儲和實時分析的3個秘訣。
海量存儲,PB級無感擴展
該用戶在線下本地化部署使用數據庫或者使用其他的存儲為云盤的數據庫時,常常需要在容量達到閾值時,提前規劃和申購存儲資源,可能還需要連帶擴容不必要的計算資源。而使用GaussDB (for Cassandra)之后,便再無此煩惱。GaussDB (for Cassandra)采用存算分離架構,可單獨擴展存儲,高效擴容,業務無感,最高可擴展到PB級。
此外,客戶為了做大數據分析,將數據庫中的數據再寫入一份到HDFS中,供MapReduce和Spark分析,同時需要維護兩套資源,維護和資源成本成為了痛點。而客戶使用GaussDB (for Cassandra)之后,可以僅采用GaussDB (for Cassandra)即可完成數據庫存儲和對接大數據分析的功能,同時GaussDB (for Cassandra)提供了更為易用的CQL接口,讓用戶更加專注功能開發,而不是資源管理。
數據變更捕獲和實時分析
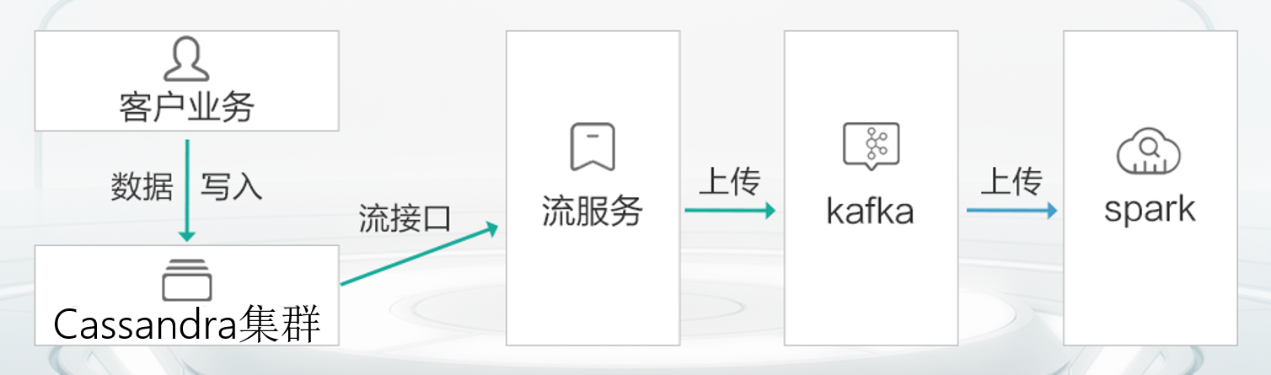
客戶的一個使用場景需要將爬蟲或用戶輸入的數據,進行在線分析和實時推薦業務,該業務中全量數據達到了50億條,但增量數據不足5億,分析對象主要是每日新增數據。在這個場景中,GaussDB (for Cassandra)為客戶提供了streaming服務+實時分析解決方案,在損失小部分讀寫性能的前提下,客戶端無需改造即可做到數據讀寫和實時分析并行,解決方案如下圖,該解決方案主要有以下幾個階段:
1.客戶業務用過開源驅動寫入數據到GaussDB (for Cassandra)
2.GaussDB (for Cassandra)對外提供streaming接口,該接口可獲取數據變更捕獲
3.客戶構建的流服務組件讀取streaming接口數據寫入到指定的Kafka隊列
4.Kafka隊列將streaming數據寫入到Spark或者Flink中
5.客戶在Spark中可對增量數據做分析,也可合并之后做全量分析
全量數據導出分析
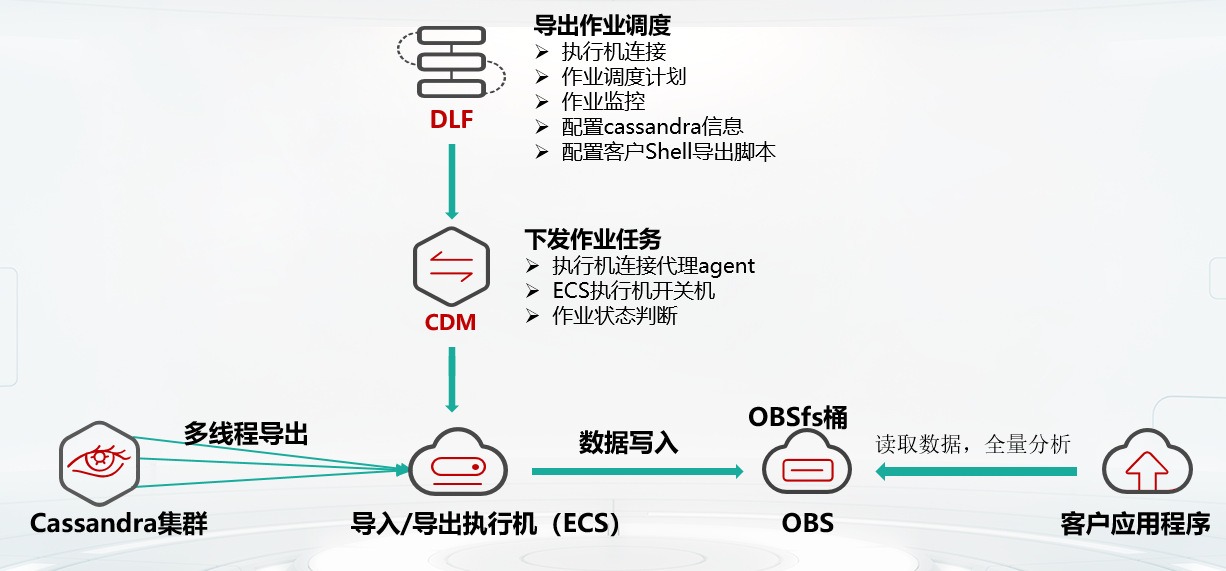
客戶的另一個業務需要周期性對全量數據進行分析和處理,但不想影響在線業務,希望在閑時處理。GaussDB (for Cassandra)提供了全量數據導出和分析解決方案,可在業務低峰期觸發任務進行數據導出和冷數據分析,數據導出速率是開源的10+倍,同時做到對業務讀寫基本無影響。如下為互聯網客戶每周定期導出數據分析用戶畫像的解決方案,該方案有以下幾個階段:
1.客戶根據需求配置ECS規格,并掛載obsfs并行文件系統
2.客戶在DLF上配置導出作業,包括ECS信息,導出參數和定時任務
3.CDM下發作業任務
4.ECS上的導出任務將GaussDB (for Cassandra)中的指定表指定條件的數據導出到obsfs
5.Spark從obsfs中讀取全量數據進行數據分析
通過這3個秘訣,華為云GaussDB (for Cassandra)完美解決了難擴展、高成本、變更不及時等問題,實現了海量數據的高效存儲和實時分析,為互聯網公司和IOT企業的數字化發展提供了更多可能。
審核編輯黃昊宇
-
華為云
+關注
關注
3文章
2445瀏覽量
17410
發布評論請先 登錄
相關推薦
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

有云服務器還需要租用數據庫嗎?
恒訊科技分析:云數據庫rds和redis區別是什么如何選擇?
恒訊科技分析:sql數據庫怎么用?
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例

華為云GaussDB數據庫基礎版發布:旗艦性能、價格下降超60%
華為云多模數據庫 GeminiDB 架構與應用實踐直播問答實錄
華為云原生多模數據庫 GeminiDB 架構與應用實踐

選擇 KV 數據庫最重要的是什么?
2024年,國產數據庫正醞釀新變局!





 工商網監
工商網監
評論