") NVIDIA 憑借生成式 AI 和通用智能體方面的研究獲得 NeurIPS 獎
NVIDIA 憑借生成式 AI 和通用智能體方面的研究獲得 NeurIPS 獎
在 NeurIPS 這一關注機器學習、計算機視覺等領域的業(yè)界知名會議上,NVIDIA Research 帶來了 60 多個項目,并展示了開創(chuàng)性成果
兩篇 NVIDIA Research 的論文憑借對 AI 和機器學習領域的貢獻而榮獲 2022 年 NeurIPS 獎。其中一篇研究的是基于擴散的生成式 AI 模型,另一篇則是關于如何訓練通用智能體。
本周在新奧爾良舉行的 NeurIPS 大會和下周的 NeurIPS 在線會議中,60 多場講座、學術海報會和研討會均有 NVIDIA 的論文作者參加。
針對圖像、文本或視頻等模態(tài)的合成數(shù)據(jù)生成(SDG)是貫穿 NVIDIA 論文的一大關鍵主題。其他主題還包括強化學習、數(shù)據(jù)采集和增強、氣候模型以及聯(lián)邦學習。
NVIDIA 學習和感知研究副總裁 Jan Kautz 表示:“AI 是一項極其重要的技術。從生成式 AI 到自主智能體,NVIDIA 在各個領域都取得了飛快的進展。在生成式 AI 領域,我們不僅在推動自身對基礎模型理論的理解,而且還在為更輕松地創(chuàng)建逼真的虛擬世界和模擬做出實際的貢獻。”
重構基于擴散的生成式模型的設計
基于擴散的模型已成為生成式 AI 領域的一項開創(chuàng)性技術。NVIDIA 研究人員憑借對擴散模型設計的分析獲得了優(yōu)秀主流論文獎(Outstanding Main Track Paper)。他們所提出的改進措施能夠顯著提高這些模型的效率和質量。
該論文將擴散模型的各個組成部分分解成模塊,幫助開發(fā)者明確可以調整的流程,進而提高整個模型的性能。研究人員表示,經(jīng)過他們修改的模型在 AI 生成圖像質量評估中獲得了創(chuàng)紀錄的高分。
在基于《我的世界》游戲的模擬套件
中訓練通用智能體
雖然研究人員長期以來一直在《星際爭霸》、《Dota》、《圍棋》等視頻游戲環(huán)境中訓練自主智能體,但這些智能體一般只擅長少數(shù)任務。因此,NVIDIA 研究人員開始轉向全球最熱門的游戲《我的世界》,開發(fā)了一個用于訓練通用智能體(一種能夠成功執(zhí)行各種開放式任務的智能體)的可擴展訓練框架。
這個名為 MineDojo 的框架使智能體能夠利用一個由 7000 多個維基百科網(wǎng)頁、數(shù)百萬個 Reddit 帖子和 30 萬小時游戲錄像所組成的大規(guī)模在線數(shù)據(jù)庫來學習《我的世界》的靈活玩法(如下圖所示)。該項目獲得了 NeurIPS 委員會頒發(fā)的優(yōu)秀數(shù)據(jù)集和基準論文獎。
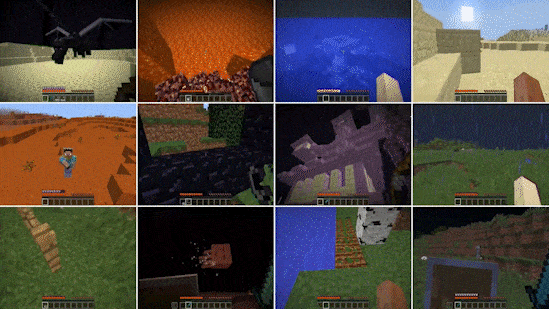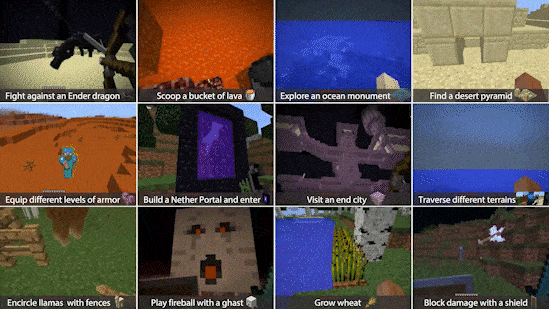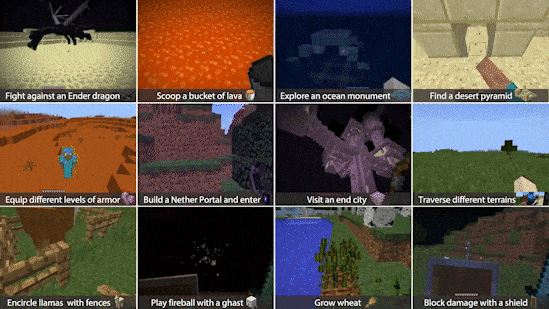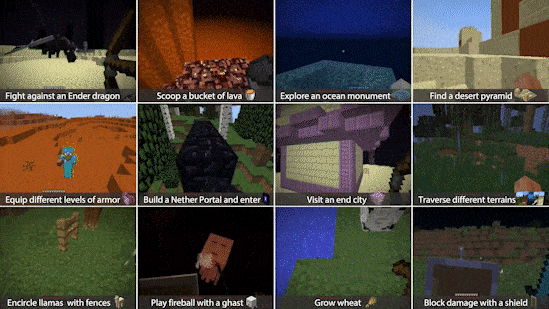
作為概念驗證,MineDojo 的研究人員創(chuàng)建了一個名為 MineCLIP 的大型基礎模型。該模型學會了將 YouTube 上的《我的世界》游戲視頻與視頻字幕(包含玩家敘述屏幕上的動作)相關聯(lián)。通過 MineCLIP,該團隊訓練出了一個能夠在沒有人類干預的情況下執(zhí)行《我的世界》中若干任務的強化學習智能體。
創(chuàng)建構建虛擬世界的復雜 3D 幾何體
本屆 NeurIPS 上還展示了 GET3D。這個生成式 AI 模型可根據(jù)其所訓練的建筑物、汽車、動物等 2D 圖像類別,即時合成 3D 幾何體。AI 生成的物體具有高保真的紋理和復雜的幾何細節(jié),并且以常用圖形軟件應用中所使用的三角網(wǎng)格格式創(chuàng)建,這使得用戶可以十分輕松地將這些幾何體導入 3D 渲染器和游戲引擎,以進行后續(xù)編輯。

GET3D 即 Generate Explicit Textured 3D 的縮寫,正如其名,它具備生成具有顯示紋理的3D 網(wǎng)格的能力。該模型是在 NVIDIA A100 Tensor Core GPU 上使用從不同相機角度拍攝的約 100 萬張 3D 幾何體的 2D 圖像訓練而成。該模型在單顆 NVIDIA GPU 上運行推理時,每秒可生成約 20 個物體。
AI 生成的物體可用于構建為游戲、機器人、建筑、社交媒體等行業(yè)設計的數(shù)字空間,比如建筑物、戶外空間或整座城市的 3D 表達。
通過對材質和光照的控制,改進可逆渲染流程
在 6 月于新奧爾良舉行的最近一次 CVPR 會議上,NVIDIA Research 發(fā)布了 3D MoMa。這種可逆渲染方法使開發(fā)者能夠創(chuàng)建由 3D 網(wǎng)格模型、覆蓋在模型上的材質以及光照這三個不同部分所組成的 3D 物體。
此后,該團隊在分離 3D 物體中的材質和光照方面取得了重大進展,這反過來又提高了 AI 生成幾何體的可編輯能力,創(chuàng)造者們能夠輕松地對在場景中移動的物體替換材質或者調整光照。
這項研究工作依靠的著色模型采用 NVIDIA RTX GPU 加速光線追蹤技術,更為逼真。該成果正在 NeurIPS 大會上以海報形式展示。
提高語言模型生成文本的事實準確性
另一篇被 NeurIPS 收錄的論文研究的是預訓練語言模型的一項重大難題——AI 生成文本的事實準確性。
由于 AI 只是通過關聯(lián)單詞來預測句子接下來的內容,因此為生成開放式文本而訓練的語言模型往往會產(chǎn)生包含非事實信息的文本。在這篇論文中,NVIDIA 研究人員提出了能夠突破這一局限性的技術,這也是為現(xiàn)實世界應用部署此類模型的必要前提。
研究人員建立了首個能夠衡量生成開放式文本語言模型事實準確性的自動化基準,并發(fā)現(xiàn)擁有數(shù)十億參數(shù)的大型語言模型比小型語言模型的事實準確性更高。該研究團隊提出了一項新的技術——事實性強化訓練,以及一種新穎的采樣算法,通過兩者的結合,助力訓練語言模型生成準確的文本,并且將事實性錯誤率從 33% 降低到 15% 左右。
目前,NVIDIA 在全球共有 300 多名研究人員,團隊專注的課題領域涵蓋 AI、計算機圖形學、計算機視覺、自動駕駛汽車和機器人技術等。
原文標題:NVIDIA 憑借生成式 AI 和通用智能體方面的研究獲得 NeurIPS 獎
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3771瀏覽量
90997
原文標題:NVIDIA 憑借生成式 AI 和通用智能體方面的研究獲得 NeurIPS 獎
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NVIDIA推出全新生成式AI模型Fugatto
NVIDIA助力Amdocs打造生成式AI智能體
使用全新NVIDIA AI Blueprint開發(fā)視覺AI智能體
NVIDIA AI助力SAP生成式AI助手Joule加速發(fā)展
NVIDIA在加速計算和生成式AI領域的創(chuàng)新
全新NVIDIA NIM微服務將生成式AI引入數(shù)字環(huán)境
NVIDIA攜手Meta推出AI服務,為企業(yè)提供生成式AI服務
HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
NVIDIA宣布全面推出 NVIDIA ACE 生成式 AI 微服務
Nullmax旗下智能駕駛方案MaxDrive憑借全面的行泊一體優(yōu)勢獲獎

NVIDIA在加速識因智能AI大模型落地應用方面的重要作用介紹
NVIDIA生成式AI研究實現(xiàn)在1秒內生成3D形狀

NVIDIA生成式AI開啟藥物研發(fā)與設計的新紀元

生成式AI通過NVIDIA Isaac平臺提高機器人的智能化水平






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論