 字節一面:HTTP長連接和TCP長連接有區別?
字節一面:HTTP長連接和TCP長連接有區別?
大家好,我是小林。
之前有位讀者私信我,他在字節面試時,被問到這兩個問題:
第一個問題:MySQL 的 NULL 值是怎么存放的?
第二個問題:HTTP 長連接和 TCP 長連接有什么區別?
第一個問題,主要是考核你是否清楚 MySQL 一條記錄是怎么存儲的,我在前幾天已經寫了一篇文章講解了,還沒看過的同學,可以去看這篇:字節一面:MySQL 的 NULL 值是怎么存放的?
第二問題,其實是在問 HTTP 的 Keep-Alive 和 TCP 的 Keepalive 有什么區別?
這是個好問題,應該有不少人都會搞混,因為這兩個東西看上去太像了,很容易誤以為是同一個東西。
如果認真讀過我網站上圖解網絡系列文章的同學,應該這個問題你們都會,因為我之前就寫過。
不過,應該也有不少同學,看過后忘記了,這次就帶大家重新復習一波。
事實上,這兩個完全是兩樣不同東西,實現的層面也不同:
HTTP 的 Keep-Alive,是由應用層(用戶態)實現的,稱為 HTTP 長連接;
TCP 的 Keepalive,是由TCP 層(內核態)實現的,稱為 TCP 保活機制;
接下來,分別說說它們。
HTTP 的 Keep-Alive
HTTP 協議采用的是「請求-應答」的模式,也就是客戶端發起了請求,服務端才會返回響應,一來一回這樣子。
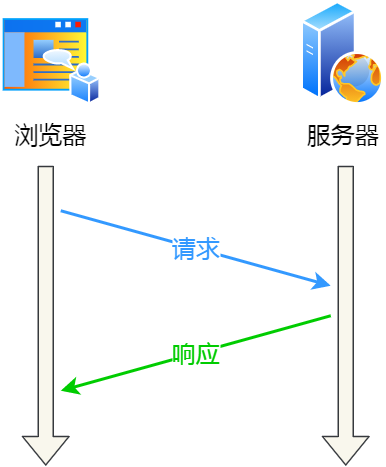
請求-應答
由于 HTTP 是基于 TCP 傳輸協議實現的,客戶端與服務端要進行 HTTP 通信前,需要先建立 TCP 連接,然后客戶端發送 HTTP 請求,服務端收到后就返回響應,至此「請求-應答」的模式就完成了,隨后就會釋放 TCP 連接。
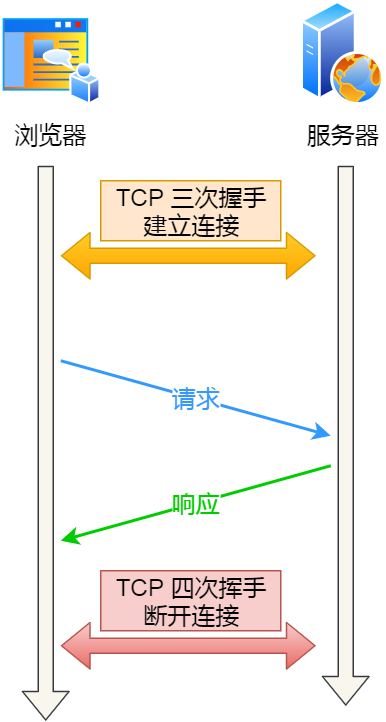
一個 HTTP 請求
如果每次請求都要經歷這樣的過程:建立 TCP -> 請求資源 -> 響應資源 -> 釋放連接,那么此方式就是HTTP 短連接,如下圖:
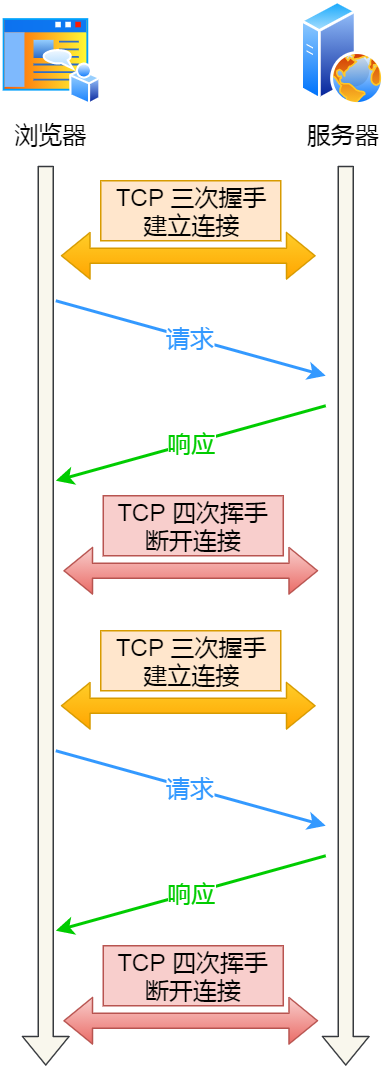
HTTP 短連接
這樣實在太累人了,一次連接只能請求一次資源。
能不能在第一個 HTTP 請求完后,先不斷開 TCP 連接,讓后續的 HTTP 請求繼續使用此連接?
當然可以,HTTP 的 Keep-Alive 就是實現了這個功能,可以使用同一個 TCP 連接來發送和接收多個 HTTP 請求/應答,避免了連接建立和釋放的開銷,這個方法稱為HTTP 長連接。
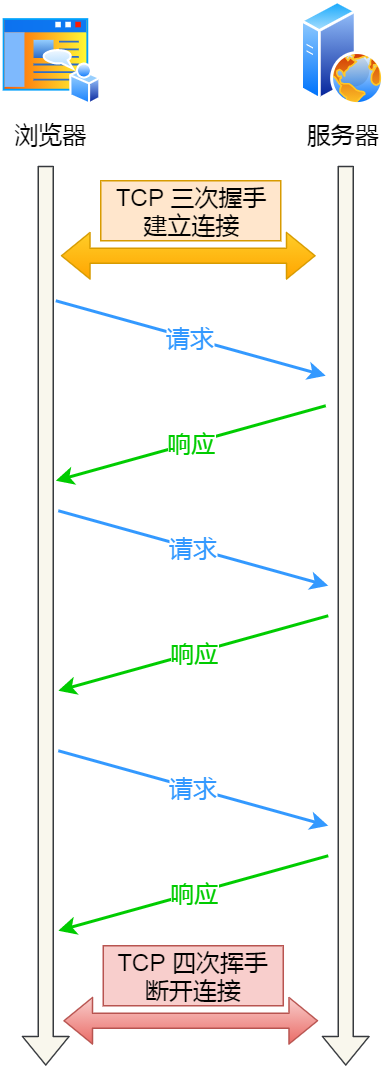
HTTP 長連接
HTTP 長連接的特點是,只要任意一端沒有明確提出斷開連接,則保持 TCP 連接狀態。
怎么才能使用 HTTP 的 Keep-Alive 功能?
在 HTTP 1.0 中默認是關閉的,如果瀏覽器要開啟 Keep-Alive,它必須在請求的包頭中添加:
Connection:Keep-Alive
然后當服務器收到請求,作出回應的時候,它也添加一個頭在響應中:
Connection:Keep-Alive
這樣做,連接就不會中斷,而是保持連接。當客戶端發送另一個請求時,它會使用同一個連接。這一直繼續到客戶端或服務器端提出斷開連接。
從 HTTP 1.1 開始, 就默認是開啟了 Keep-Alive,如果要關閉 Keep-Alive,需要在 HTTP 請求的包頭里添加:
Connection:close
現在大多數瀏覽器都默認是使用 HTTP/1.1,所以 Keep-Alive 都是默認打開的。一旦客戶端和服務端達成協議,那么長連接就建立好了。
HTTP 長連接不僅僅減少了 TCP 連接資源的開銷,而且這給HTTP 流水線技術提供了可實現的基礎。
所謂的 HTTP 流水線,是客戶端可以先一次性發送多個請求,而在發送過程中不需先等待服務器的回應,可以減少整體的響應時間。
舉例來說,客戶端需要請求兩個資源。以前的做法是,在同一個 TCP 連接里面,先發送 A 請求,然后等待服務器做出回應,收到后再發出 B 請求。HTTP 流水線機制則允許客戶端同時發出 A 請求和 B 請求。
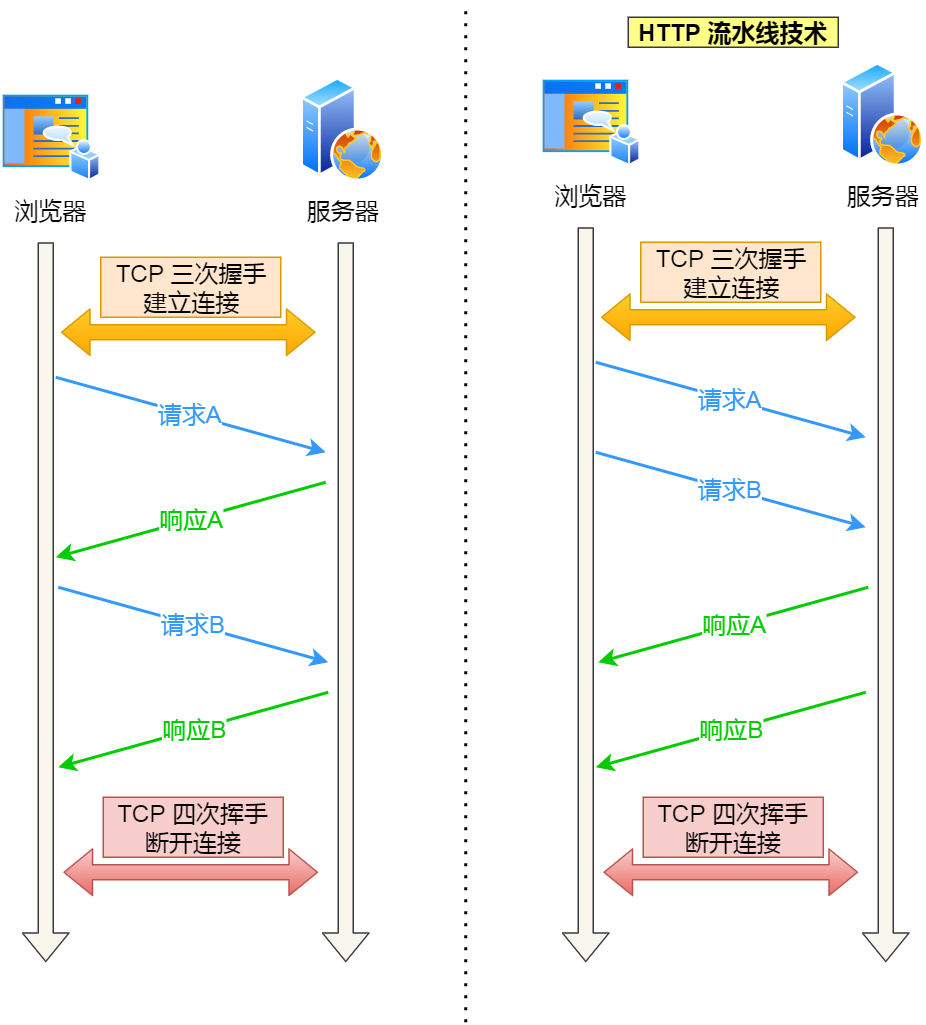
右邊為 HTTP 流水線機制
但是服務器還是按照順序響應,先回應 A 請求,完成后再回應 B 請求。
而且要等服務器響應完客戶端第一批發送的請求后,客戶端才能發出下一批的請求,也就說如果服務器響應的過程發生了阻塞,那么客戶端就無法發出下一批的請求,此時就造成了「隊頭阻塞」的問題。
可能有的同學會問,如果使用了 HTTP 長連接,如果客戶端完成一個 HTTP 請求后,就不再發起新的請求,此時這個 TCP 連接一直占用著不是挺浪費資源的嗎?
對沒錯,所以為了避免資源浪費的情況,web 服務軟件一般都會提供 keepalive_timeout 參數,用來指定 HTTP 長連接的超時時間。
比如設置了 HTTP 長連接的超時時間是 60 秒,web 服務軟件就會啟動一個定時器,如果客戶端在完后一個 HTTP 請求后,在 60 秒內都沒有再發起新的請求,定時器的時間一到,就會觸發回調函數來釋放該連接。
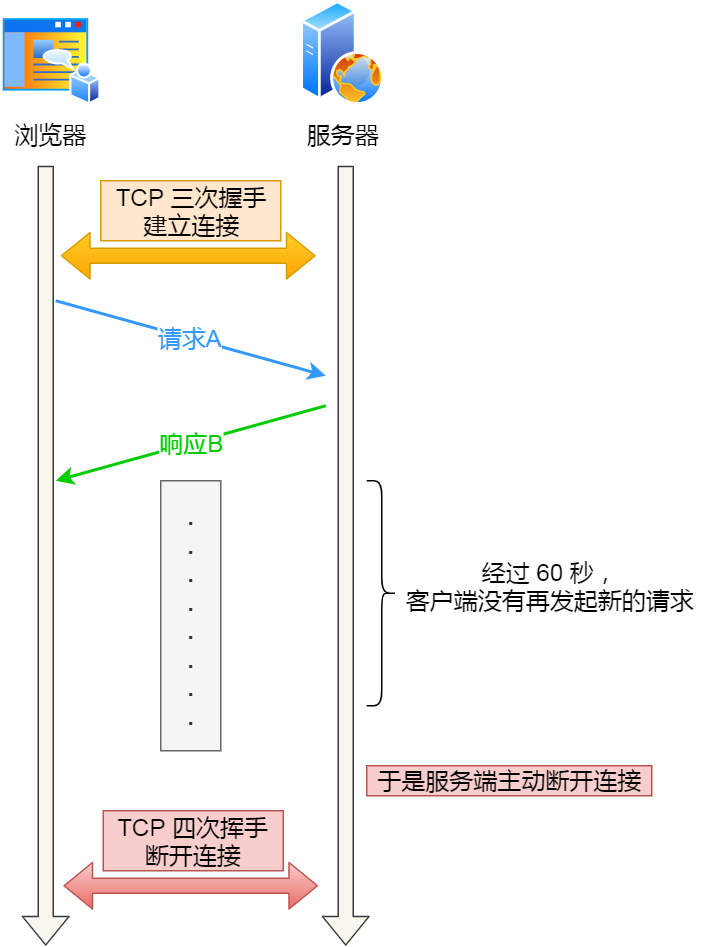
HTTP 長連接超時
TCP 的 Keepalive
TCP 的 Keepalive 這東西其實就是TCP 的保活機制,它的工作原理我之前的文章寫過,這里就直接貼下以前的內容。
如果兩端的 TCP 連接一直沒有數據交互,達到了觸發 TCP 保活機制的條件,那么內核里的 TCP 協議棧就會發送探測報文。
如果對端程序是正常工作的。當 TCP 保活的探測報文發送給對端, 對端會正常響應,這樣TCP 保活時間會被重置,等待下一個 TCP 保活時間的到來。
如果對端主機崩潰,或對端由于其他原因導致報文不可達。當 TCP 保活的探測報文發送給對端后,石沉大海,沒有響應,連續幾次,達到保活探測次數后,TCP 會報告該 TCP 連接已經死亡。
所以,TCP 保活機制可以在雙方沒有數據交互的情況,通過探測報文,來確定對方的 TCP 連接是否存活,這個工作是在內核完成的。
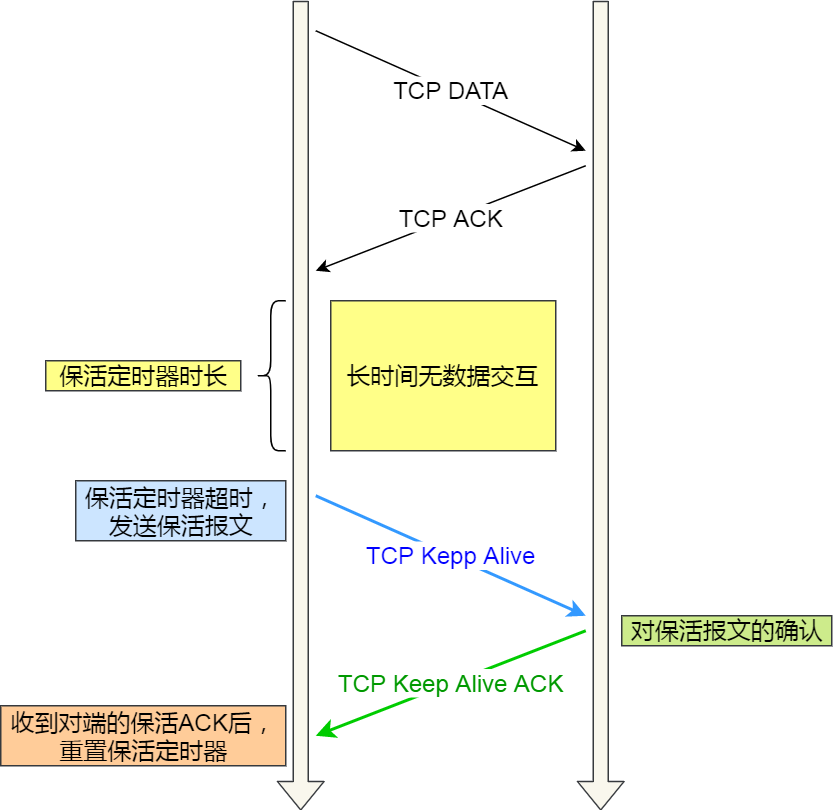
TCP 保活機制
注意,應用程序若想使用 TCP 保活機制需要通過 socket 接口設置 SO_KEEPALIVE 選項才能夠生效,如果沒有設置,那么就無法使用 TCP 保活機制。
總結
HTTP 的 Keep-Alive 也叫 HTTP 長連接,該功能是由「應用程序」實現的,可以使得用同一個 TCP 連接來發送和接收多個 HTTP 請求/應答,減少了 HTTP 短連接帶來的多次 TCP 連接建立和釋放的開銷。
TCP 的 Keepalive 也叫 TCP 保活機制,該功能是由「內核」實現的,當客戶端和服務端長達一定時間沒有進行數據交互時,內核為了確保該連接是否還有效,就會發送探測報文,來檢測對方是否還在線,然后來決定是否要關閉該連接。
歷史好文:
字節一面:TCP 三次握手,問的好細!
美團二面:TCP 四次揮手,可以變成三次嗎?
字節一面:服務端掛了,客戶端的 TCP 連接還在嗎?
字節一面:HTTPS 一定安全可靠嗎?
審核編輯 :李倩
-
HTTP
+關注
關注
0文章
504瀏覽量
31197 -
TCP
+關注
關注
8文章
1353瀏覽量
79055 -
MySQL
+關注
關注
1文章
804瀏覽量
26531
發布評論請先 登錄
相關推薦
測徑儀 測測長儀是如何應用在卷煙生產中的?

TCP協議是什么
網線不夠長可以接嗎
tcp和udp的區別和聯系
請問esp32之間的藍牙連接與esp32與手機的藍牙連接有什么區別?
mqtt協議和tcp協議區別
能不能說一說TCP和UDP的區別?
短時額定電流和長時額定電流的區別有哪些?
TCP和UDP協議有什么區別?如何通過網關實現TCP協議通信?

什么是Socket連接?Socket的工作原理 它與TCP連接有什么關系?
UDP與TCP的主要區別 UDP能否像TCP一樣實現可靠傳輸?
一臺服務器,最大支持的TCP連接數是多少?






 工商網監
工商網監
評論