 關于ByteHouse你想知道的一切分享
關于ByteHouse你想知道的一切分享
ByteHouse 的前世今生
字節跳動最早是在 2017 年底開始使用 ClickHouse 的,用于支撐增長分析的業務場景。對于字節跳動而言,增長分析的重要性不言而喻。這是一項十分考驗運營團隊能力的工作,如何衡量不同運營方法的有效性,應該對哪些數據指標進行考量,如何對指標的波動進行更深層次的原因分析,這些需要重點關注。這其中涉及大量數據分析,對于數據分析平臺的實時性也有著非常高的要求。在比對、試用過多款 OLAP 分析產品后,字節跳動最終選擇了 ClickHouse,并且整體方案的可行性在實際業務應用中得到了很好的驗證。
在取得了不錯的業務效果之后,采用 ClickHouse 的方案快速推廣,從支持增長分析的單一場景,很快擴展到 BI 分析、AB 測試、模型預估等多個場景。同時,研發團隊也持續不斷打磨和改進 ClickHouse 能力,比如增強數據接入功能、提升 SQL-based 指標計算的執行效率,包括 UDF 增強、SQL 語法增強等,很快使 ClickHouse 成為字節內部最主流的分析平臺。
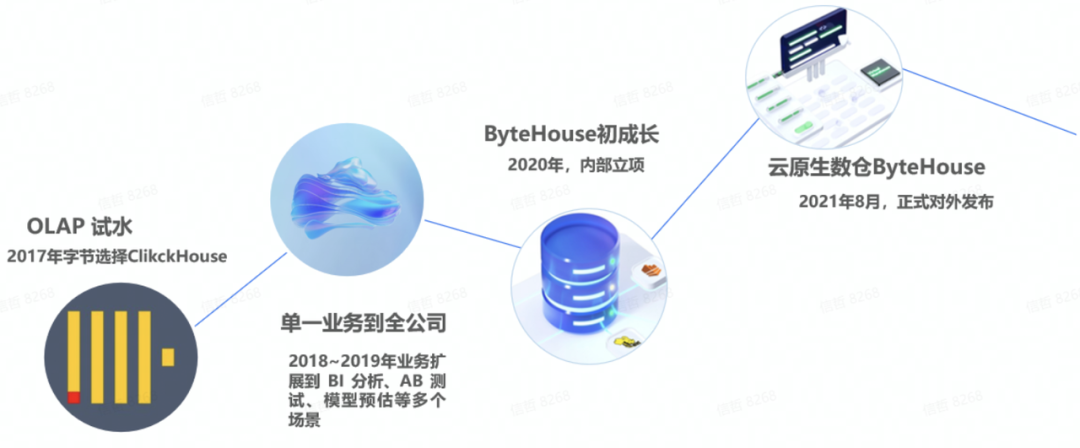
在產品的不斷打磨中,2020 年字節跳動火山引擎正式立項,把基于 ClickHouse 做了很多增強和自研的 ByteHouse 作為 ToB 的核心產品之一加快產品化步伐,以期讓更多的用戶在分析領域獲得更快、更好的業務體驗。在 2021 年 8 月份,ByteHouse 正式對外發布并提供服務。
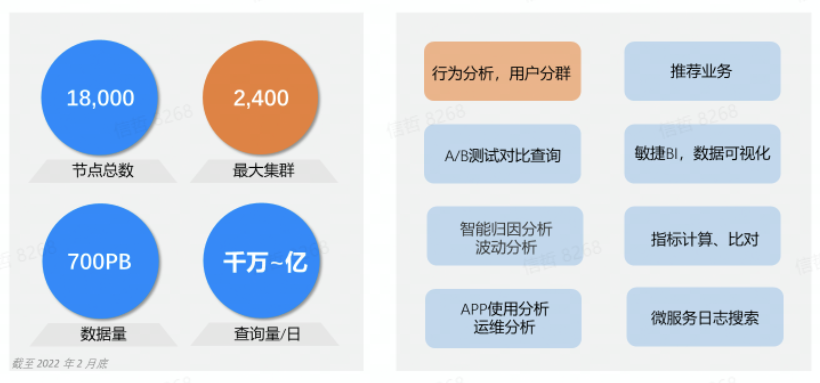
至 2022 年 6 月底,字節跳動內部的 ByteHouse 節點總數已經超過18000個,管理總數據量超過 700PB,每天上億次的分析查詢跑在ByteHouse上,有離線的、有實時的。其中支撐抖音、頭條的行為分析平臺其集群規模已經達到2400個節點。截止當前,字節內部 80% 的分析型應用都跑在ByteHouse平臺上。
字節跳動最初為什么選擇 ClickHouse
字節跳動曾做過各類分析型產品做過調研,如 Kylin、Druid、SparkSQL 等。那究竟為什么最后字節跳動選擇了 ClickHouse,并進一步投入力量研發出 ByteHouse 使之成為字節跳動內部核心的數據分析平臺呢?這里以兩個具體的字節跳動業務案例來展開一些細節:
推薦系統實時指標
公司內部 A/B 實驗平臺已經提供了 T+1 的離線實驗指標,而推薦系統需要更快地觀察算法模型、或者某個功能的上線效果,因此需要一份能夠實時反饋的數據作為補充,而且還要求:
? 能同時查詢聚合指標和明細數據;
? 能支持多達幾百列的維度和指標,且場景靈活變化,會不斷增加;
? 可以高效地按 ID 過濾數據;
? 需要支持一些機器學習和統計相關的指標計算(比如 AUC)。
選型開始時,最需要解決的是“快”,所以選擇了 Kylin 作為主要分析引擎,其優點是能夠提供毫秒級別的查詢延時。但是 Kylin 存在維度爆炸導致預計算時間越來越長,數據可用時間沒有保證的問題。此外,新業務上線會產生新的指標和維度,Kylin 無法支持維度和指標在線更新。
后期改用 SparkSQL ,同樣存在不少問題,如查詢分析的延遲太長、資源使用率高、穩定性不夠好頻發OOM,以及無法支持跨更長時間周期的數據做分析等。
綜合考量,最后選擇了 ClickHouse:
? 能更快地觀察算法模型,沒有預計算所導致的高數據時延;
? 既適合聚合查詢,在配合跳數索引后,也能充分支持明細查詢;
? BitSet 的過濾 Bloom Filter 是比較好的解決方案。
同時,團隊也持續投入研發力量,不斷自研增強產品能力,比如通過異步構建索引使得整體寫入吞吐量能力提升 20%。通過對 Kafka 多消費線程的改造和增強,實現并行消費,使得寫入性能得到線性提升。此外,自研 HaKafka 引擎,提升了系統的 HA 高可用能力,即使出現節點故障也不用擔心數據有完整性問題。
廣告投放實時分析
通常運營人員需要查看廣告投放的實時效果,由于業務的特點,當天產生的數據往往會涉及到對歷史數據的刷新,技術上最初是基于 Druid 實現,但有些問題一直難以解決。例如,實時數據會涉及到歷史3個月的時間分區,Druid 會產生很多 segment,歷史數據重刷后需要額外時間去做合并的操作,無法保證數據的實時消費;另外,業務數據的維度非常多,數據粒度非常細,所以 Druid 的預聚合的意義不大,業務更多的需求是直接來消費明細數據。
最后團隊也選擇了 ClickHouse 技術路線,并持續做了改進和增強,如:
? 對 Buffer Engine 做了改進,解決了社區版本在 Buffer Engine 和 ReplicatedMergeTree 同時使用下查詢一致性的問題。
? 自研事務機制,確保每次插入數據的原子性,增強數據消費的穩定性,解決了社區版本由于缺少事務支持,在異常場景下,往往會出現丟失或者重復消費的情況。具體實現上是將 Offset 和 Parts 數據綁定在一起,每次消費時,會默認創建一個事務,由事務負責把 Part 數據和 Offset 一同寫入磁盤中,如果出現失敗,事務會一起回滾 Offset 和寫入的 Part 然后重新消費。
ByteHouse 具備哪些特點
隨著 ByteHouse 在字節跳動內部支撐的分析業務越來越多,ByteHouse 也成為了字節跳動內部分析平臺構建的事實標準。ByteHouse 在字節廣泛的應用中,不斷從業務角度出發不斷打磨產品,并從實際應用角度思考什么樣的數據分析產品才是更好用的。我們認為,一個優秀的數據分析產品應該具備以下特點:
能支撐更全面的分析場景
數據庫行業流傳著“沒有銀彈”的說法,大家認為沒有一個分析類產品能夠滿足所有場景。這固然是很有道理的,但是也不必走向另外一個極端,所有場景都要“一事一庫”。如果有一個通用性的數據分析產品,能夠支撐 80% 以上的常見場景,這能為企業減少大量的時間和精力,并且能更有信心的應對營業務帶來的數據分析挑戰。
ClickHouse 的一個問題就是適用的場景相對較窄,對于寬表模型的查詢和分析效率非常高,但涉及到多表關聯的分析場景卻表現不佳,甚至不支持此類業務場景。因而,ClickHouse的這種高性能的表現更多的是基于“本能”層面。ByteHouse 團隊以打造一款綜合且性能強大的分析平臺為目標,對ClickHouse 做了全方位的增強,推出了全自研的查詢優化器,從而讓性能表現從“本能”層面躍遷到“智能”層面,從而更好的應對各類分析場景。
對于一款關系型數據庫產品來說,優化器就是大腦,通過優化器對查詢語句進行改寫優化,基于代價尋找最優執行路徑、生成執行計劃,并且結合資源動態負載情況,讓整體性能的輸出更加穩健、也更加智能。從效果來看,在部分場景下,優化器使得性能提升達 10 倍以上;此外,在 TPC-DS 標準測試測試場景中,啟用優化器的收益也十分顯著,能夠完成全部 99 個測試場景,而且性能也提升數倍不等。
而應對傳統數倉負載中的復雜查詢場景,僅僅有查詢優化器的增強還不夠,ByteHouse 為此還做了大量的工作。如 Runtime Filter,能夠智能過濾掉分析中不相干數據,減少中間過程數據的網絡傳輸,提升整體分析效率,在星型和雪花型業務分析場景中有很好的效果。另外通過優化網絡技術,比如連接復用、RDMA、傳輸壓縮等技術,也極大提升了整體分析性能。此外還包括其他一系列的能力增強,比如細粒度資源管控、數據交換的優化等,能夠讓 ByteHouse 在復雜分析場景中游刃有余。
從收益效果上看,在字節內部部分業務場景中,多表關聯分析性能提升 26 倍,單表復雜查詢也提升 3 倍左右,在標準SSB測試場景中也表現不俗,為支撐更全面的分析場景的目標邁出重要一步。
數據分析能力能隨業務快速擴縮,極致彈性
在 node-base 架構下,存算一體的模式不夠靈活,難以滿足業務對彈性的需求,擴容的代價無論是時間成本和資源成本都很高。應對這些挑戰,ByteHouse 團隊花費極大精力從底層開始秉承 Cloud-Native 云原生的架構理念進行整體重構,讓資源可以伴隨業務的需求進行靈活的彈性伸縮,擴容的代價更低更可控。另外,業務上可以通過讀寫分離做更好的資源管控和分流,從而讓整體業務的 SLA 更有保障。下面介紹部分 ByteHouse 架構重構中的關鍵技術點。
首先是基于分布式 KV 構建元數據管理服務,元數據信息會持久化保存在狀態存儲池里面,為了降低對元數據庫的訪問壓力,對于訪問頻度高的元數據會進行緩存。元數據服務自身是無狀態的,可以水平擴展。
在高性能層面,除了前面介紹的全自研優化器之外,還通過智能的分布式多級緩存技術來彌補存算分離架構下遠程數據訪問時額外的網絡開銷和IO開銷帶來的性能損失。此外 virtule warehouse 計算資源實現了容器化部署,做到了無狀態化,從而可以快速、靈活的進行彈性伸縮,且不影響業務。
在存儲層面,實現了存儲服務化,對數據存儲層進行統一抽象,構造 VFS 虛擬存儲系統,能夠支持更多的存儲語義,包括 HDFS 塊存儲、對象存儲等,既解決了存儲在擴展性、讀寫吞吐瓶頸、一致性等問題,同時能大幅降低存儲成本。
強一致性的事務機制、MVCC 多版本并發控制、細粒度鎖等技術保障,也能讓 ByteHouse 更好地去滿足核心分析業務對一致性和并發能力的要求。
此外,在負載管理上,圍繞計算、內存、網絡帶寬這三項核心資源進行持續優化,同時也在不斷引入AI等新技術讓系統資源的動態調配更加智能和高效;細粒度、多級的資源隔離能力也能更好的匹配業務差異化的需求,讓整體系統運行更加穩定可靠。
穩定、高可用
以抖音集團內部建于2017年的行為分析平臺為例,僅頭條和抖音兩款應用每天會產生萬億條級別的事件記錄,且至少保存1年,分析的特征維度多達上千,既有聚合查詢也有明細查詢,其自助式查詢分析要求必須達到秒級響應。當前這個平臺運行在 2400 個節點的 ByteHouse 集群上。
對社區版 ClickHouse 或者其他大部分分析類產品來說,要達到這個規模是非常困難的,幾乎難以實現。ByteHouse 做了哪些能力增強來不斷突破規模上限、持續支持業務高速增長呢?這里我們先重點介紹兩方面的能力增強:
一、通過自研的 HaMergeTree 替代社區的 ReplicatedMergeTree,降低對 ZooKeeper 的請求次數,減少在 Zookeeper 上存儲的數據量,副本直接通過 log 日志來交換信息,不需要再從 Zookeeper 獲取,從而極大減輕 Zookeeper 的負載,讓其壓力與集群內數據量規模脫鉤。
二、通過元數據持久化的方案,提升故障恢復能力。社區版本的元數據常駐于內存中,這會導致重啟時間非常長,因而當故障發生后,恢復的時間也很長,動輒一到兩個小時,這個是業務不能接受的。ByteHouse 的做法是將元數據持久化到 RocksDB,啟動時直接從 RocksDB 加載元數據,內存中也僅僅存放必要的 Part 信息,這樣就減少元數據對內存的占用,在性能基本無損失的情況下,單機支持的part 不再受內存容量的限制,可以達到 100 萬以上;最重要的是極大縮短了集群的故障恢復時間,從1-2 小時直接縮短到 3 分鐘,大大提高了系統的高可用能力,為業務提供了堅實保障。
保證查詢效率前提下,更快、更準確的數據導入
在實時寫入場景中,社區版 ClickHouse 還是存在部分能力的缺失,比如數據分布按 shard 的分布策略很難保障均勻分布,會存在數據傾斜的情況,而且不支持由用戶指定唯一鍵的業務需求,也無法保證數據的有序消費, 單線程的消費模式導致吞吐量受限,另外在 HA 高可用上也存在能力缺失。ByteHouse 針對這些不足對 kafka engion 做了全面的增強。
首先是在分布式架構下,通過自研的 HaKafka 引擎為數據的實時注入提供了 HA 高可用保障,保障數據不丟失;支持唯一鍵;通過 memory table,提升了實時寫入的吞吐能力,同時延遲刷盤也大幅降低IOPS,節省 IO 資源。
在此基礎上 ByteHouse 再向前一步,演進到云原生架構,能力得到更大的提升,包括支持 exactly-once 消費語義,自動容錯,之前 node-base 架構模式的擴容難、代價高的問題也在云原生架構下迎刃而解,能夠做到按需的靈活彈性擴容和縮容。
此外,ByteHouse 自研了 UniqueMergeTree 表引擎,很好的平衡了寫和讀的性能。UniqueMergeTree 表引擎既支持行更新的模式,也支持部分列更新的模式,用戶可以根據業務要求開啟或關閉。在性能方面,與 ReplacingMergeTree 相比,UniqueMergeTree 的寫入性能只有輕微下降,但在查詢性能上取得了數量級的提升。進一步對比了 UniqueMergeTree 和普通 MergeTree 的查詢性能,發現兩者是非常接近的。
ByteHouse 的未來展望
我們將持續圍繞讓 ByteHouse 更快、更穩、更智能持續做技術迭代,包括更強的優化器,當前在原型測試中有 3 倍的性能提升;通過AI技術的引入讓系統更智能更高效,在原型測試中,基于 IMDB 的大規模數據集的性能表現上有20%的提升;此外更加智能的物化視圖技術以及 RDMA 技術預期都會在 23 年實現產品化落地。
面向未來,ByteHouse 的愿景是打造數據分析領域的“抖音”平臺,能夠為用戶帶來一體化的集成、分析體驗,降低用戶分析門檻,一站式提供分析所需的各種能力,并能通過安全可信的數據分享、模型分享幫助用戶便捷地實現交易和價值變現。
審核編輯 :李倩
-
SQL
+關注
關注
1文章
766瀏覽量
44165 -
數據分析
+關注
關注
2文章
1451瀏覽量
34071 -
字節跳動
+關注
關注
0文章
321瀏覽量
8945
原文標題:關于 ByteHouse 你想知道的一切,看這一篇就夠了
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADC128S102WGRQV想知道輸入阻抗具體有多大?
大研智造廠家面對面 關于激光焊錫機、錫球焊設備高頻問題QA,你想知道的都在這!

智能讀碼器Q&amp;A | 常見疑問解答,你想知道的都在這!

關于公路邊坡安全監測,你想知道的都在這里!
定華雷達儀表學堂:雷達液位計,還有什么是你想知道的呢?

關于定位系統技術你知道多少?
切分去核機物聯網監控管理系統解決方案
TLE9867使用定序器讀取模擬輸入數據,只想知道在讀取ADC1數據時,中斷方式和定序器方式有何不同?
求助,關于ADC和觸發器的基本問題求解

一幀CANFD報文由多少個位組成?
關于ESS和BMS,您需要了解的一切


高速PCB的銅箔選用指南—外層避坑設計






 工商網監
工商網監
評論