 一種將信息直接編碼到預訓練的語言模型中的結構
一種將信息直接編碼到預訓練的語言模型中的結構
邊界信息的挖掘,對于NER的任務是非常重要的,這種類似于分詞的功能,能夠很好的挖掘到詞語,并且把一個句子拆分成多個詞語的構成。
以目前世界杯火的例子來說:“葡萄牙有望得到冠軍”,可以按照邊界信息,分割成為以下的組成,接著有了這種邊界信息,我們可以用來做很多的上游任務。
在之前的工業技術分享中,NER的上一步就是由分割任務來做的。
NLP基礎任務的極限在哪里?一文告訴你工業界是如何做NER的
下面我們進行本次論文的分享:
Unsupervised Boundary-Aware Language Model Pretraining for ChineseSequence Labeling | EMNLP2022
在這項工作中,提出了無監督的計算邊界,并提出了一種將信息直接編碼到預訓練的語言模型中的結構,從而產生了邊界感知BERT(BABERT)。船長在此處辯證的分析一下,無監督有什么好處,有什么壞處?
好處:
可以節省大量的人力,本模型可以直接用于中文的邊界信息計算任務中。
壞處:
有監督的結果一般都比無監督的結果要好,從結果的角度來看,肯定是受限的。
實際上這里最好是利用半監督學習,使用到之前標注的詞庫信息,在進而進行無監督的訓練,這點才是值得肯定的地方。
模型結構
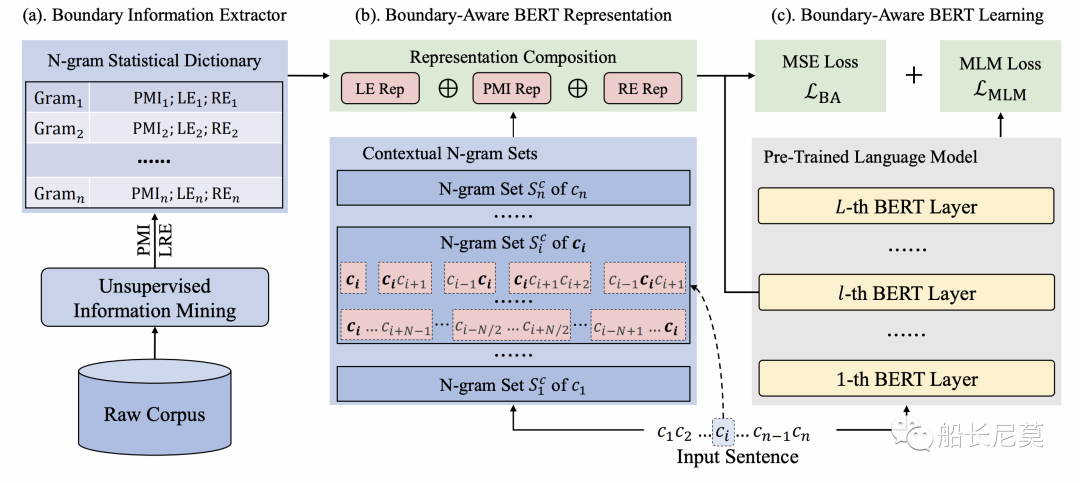
圖1:邊界感知預訓練語言模型的總體架構。總共由三部分組成:(a) 邊界信息提取器;(b)邊界感知表示;(c) 邊界感知BERT學習。
邊界信息提取器
其實為什么第一個部分是邊界信息提取器呢?因為我們的模型需要先猜一個結果,然后再判斷他是否“正確”,再進行迭代來不斷地進行學習。那么具體如何提取邊界信息,本文分成了兩個步驟。
從原始語料庫中收集所有N-grams,以建立一個詞典,在其中我們統計每個詞的頻率,并過濾掉低頻項,去除掉噪聲詞語。
考慮到詞頻不足以表示漢語上下文中的靈活邊界關系,本文進一步計算了兩個無監督指標,這兩個指標可以捕獲語料庫中的大部分邊界信息。在下文中,我們將詳細描述這兩個指標。
公式預警,讀者覺得復雜可以直接調到邊界信息感知的BERT學習
點交互信息 PMI
給定一個N-gram,將其分成兩個子字符串,并計算它們之間的互信息(MI)作為候選。然后,我們枚舉所有子字符串對,并選擇最小MI作為總PMI,以估計緊密性。設g={c1…cm}是由m個字符組成的N-gram,使用以下公式計算PMI:
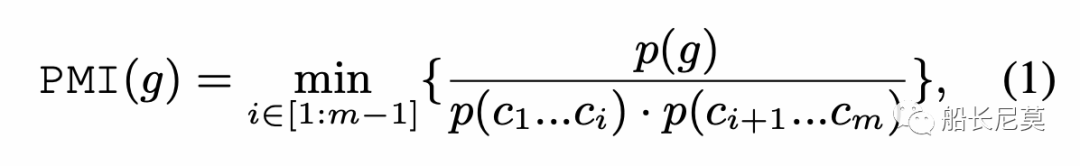
p()代表了文章中出現的概率。當m等于1的時候PMI這時也是最大的,即為1。除去這種情況后,如果PMI指數很高,也就意味著總字符串和子字符串有著同時出現的概率,例如總字符串“貝克漢姆”和子字符串“貝克”+“漢姆”,這時就讓N-Gram “貝克”和“漢姆”更像是兩個實體。
左右交叉熵
給定一個N-gram g,我們首先收集到左邊的鄰接字符集合Sl,之后我們用g和Sl的條件概率來計算左交叉熵:
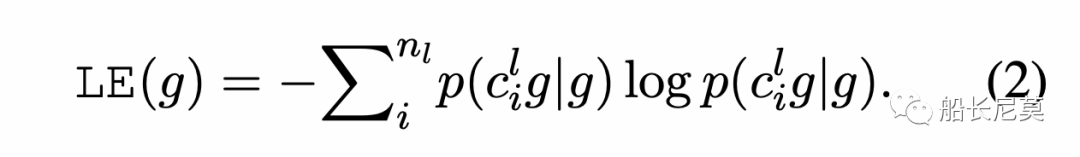
右交叉熵是同理的:
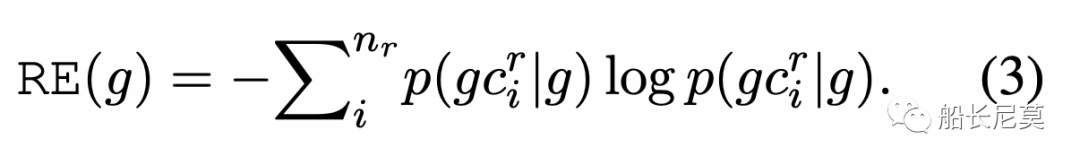
直觀地說,左右交叉熵(LRE)代表了N-gram中相鄰字符的數量。對于較低的LRE“漢姆”,表示它更可能是短語或實體的一部分。相反,具有更高LRE(例如,“貝克漢姆”),說明和上下文的交互很多,那么它很可能是單獨的一個實體,這點是毋庸置疑的,越高說明當前的詞語是單個實體的概率更大。作者使用的指標能夠感知到什么是上下文,什么是實體,從而更好的做好邊界計算的邏輯。
最后,我們利用PMI和LRE來測量中文上下文中的靈活邊界關系,然后用上面的無監督統計指標更新每個N-gram。
邊界信息表示
邊界信息計算的核心就是上下文和實體之間的差別,針對于字符Ci,我們抽取出和Ci相關的N-Gram來代表Ci的上下文。設計一種組合方法,通過使用特定的條件和規則來集成S中N個詞的統計特征,旨在避免統計信息的稀疏性和上下文獨立性限制。
具體地,我們將信息合成方法分為PMI和熵表示。首先,我們連接了所有和字符Ci相關的N-Gram,去形成PMI的表達:

a=1+2+··+N是包含ci的N-Gram的數量。注意,在PMI表示中,每個N的位置是固定的。我們嚴格遵循N-gram長度的順序和ci在N-gram中的位置來連接它們對應的PMI,確保位置和上下文信息可以被編碼到交叉熵信息中:
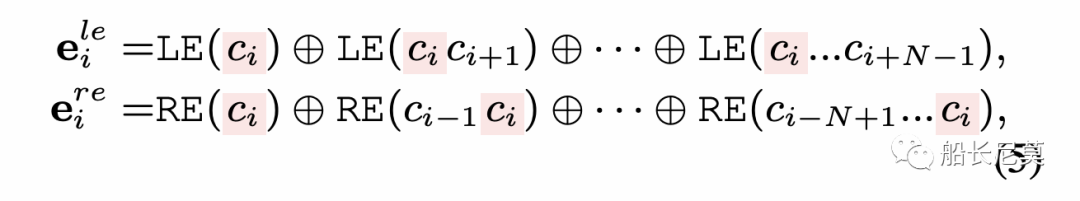
從而也就有了公式5,就是左右交叉熵。那么最終,我們就有了邊界信息的表示,通過PMI和左右交叉熵的整合可以得到:
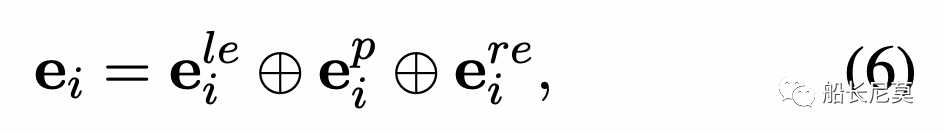
公式6很有意思,作者在文中提到,三個表達方式的順序是很特殊的,左邊的交叉熵放在了最左面,而右邊的交叉熵放在了最右邊,中間的是用來計算當前是否是實體的概率。那么我們可以這么理解這個公式,ei代表了 前文+實體+后文,也就是一種清晰的解決方案。
這個地方關于公式的地方讀者可以自行跳過,下面我們來舉一個具體的例子幫助理解,詳見圖2:
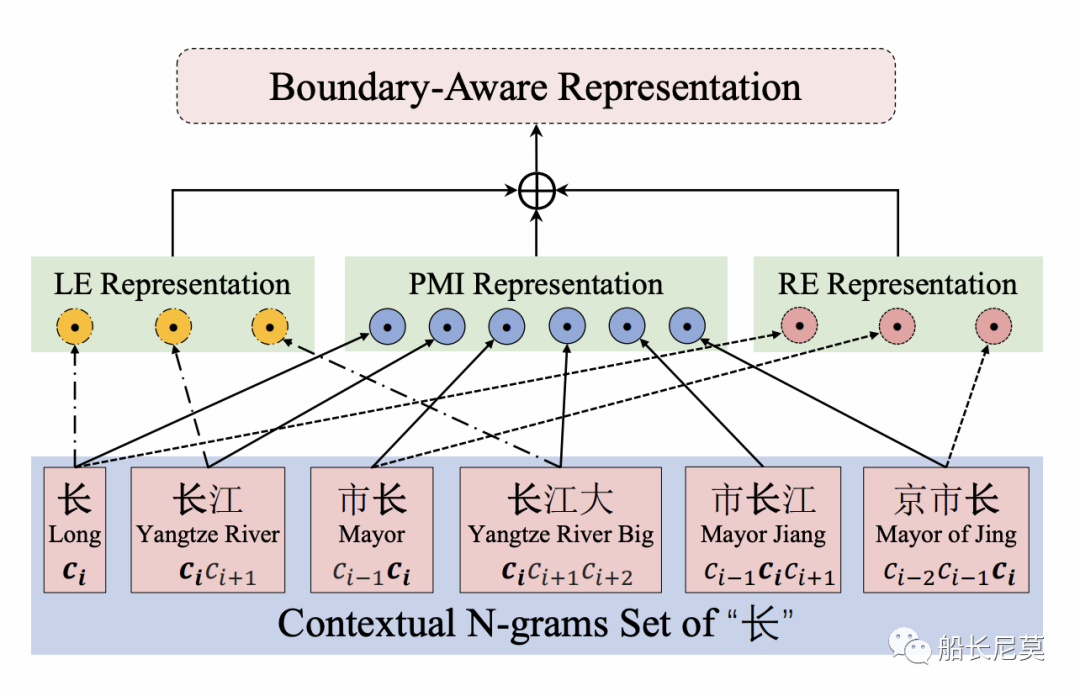
圖2:字符邊界感知表示的“長”在文本中“南京市長江大橋”
圖2顯示了邊界感知表示的示例。首先整句話呢,會按照N-Gram (N=3)來進行拆分,所以我們有了下面的字符串序列,接著,我們三個公式開始計算各自的數值,LE包含了三個詞,而PMI包含了所有詞,RE包含了三個詞,最終會把三個計算的數值并在一起作為邊界信息感知的表達方式。
邊界信息感知的BERT學習
邊界信息感知的BERT是BERT預訓練模型中的一種,在這節中,我們主要描述了如何把邊界信息引入到BERT的訓練中。
邊界信息感知的目標訓練
那么如何讓BERT擁有這種信息的感知呢?實際上用MSE來規范BERT的hidden states,讓這個和公式6中的ei來不斷地接近。詳細公式如公式7所示,其中h代表了BERT中某一層的隱狀態,W是可學習參數矩陣。
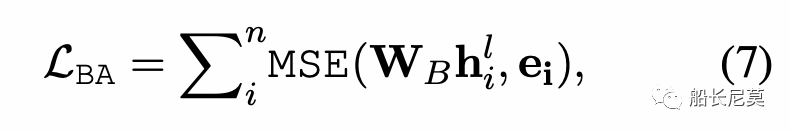
不過話說回來,船長平日做實驗的時候,很少有發現MSE loss針對這種回歸有效的,因為兩個向量本身就在不同的向量空間,如何讓他們兩個接近呢?其實很難。
最終BERT的預訓練損失函數,由兩部分組成,也即公式7+完形填空任務。完形填空任務類似于把某一個單詞挖空,然后讓BERT去預測這個單詞,這種方式能夠加強BERT對于上下文的感知能力。
序列標注任務的微調
微調的方法是很簡單粗暴的,對于序列標注的任務,只需要序列標注的信號,輸入文本,模型的輸出層加上CRF進行預測。因為本模型和BERT的結構幾乎一樣,所以在使用起來可以完全按照BERT+CRF的框架來走。
如何引入詞語?
回到了我們做NER的初心,如何利用好詞語的信息,是增強NER的關鍵之一,那么本文的方式就是利用Adapter的方式來引入詞語的信息,他的方法和我之前分析過的論文是類似的,感興趣的讀者可以看看我之前發的文章。
如何把單詞插入到預訓練模型?達摩院研究告訴你答案
數據集
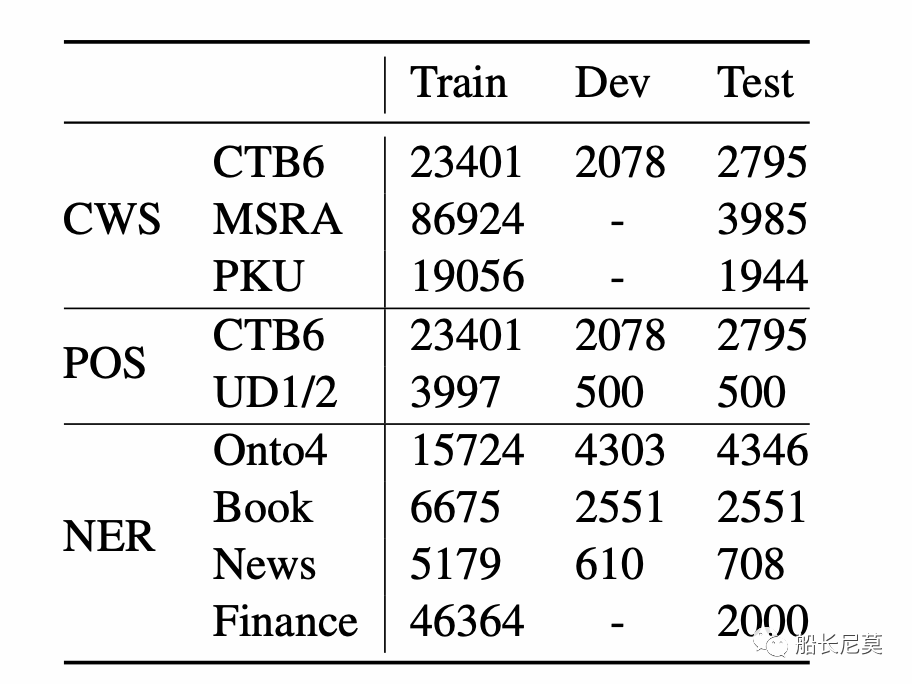
圖3:基準數據集的句子數統計。對于沒有測試部分的數據集,我們從相應的訓練集中隨機選擇10%的句子作為測試集。
本文的數據集有三種類型,分別是NER (Named Entity Recognition), POS (Part-Of-Speech Tagging),CWS (Chinese Word Segmentation)。
結果
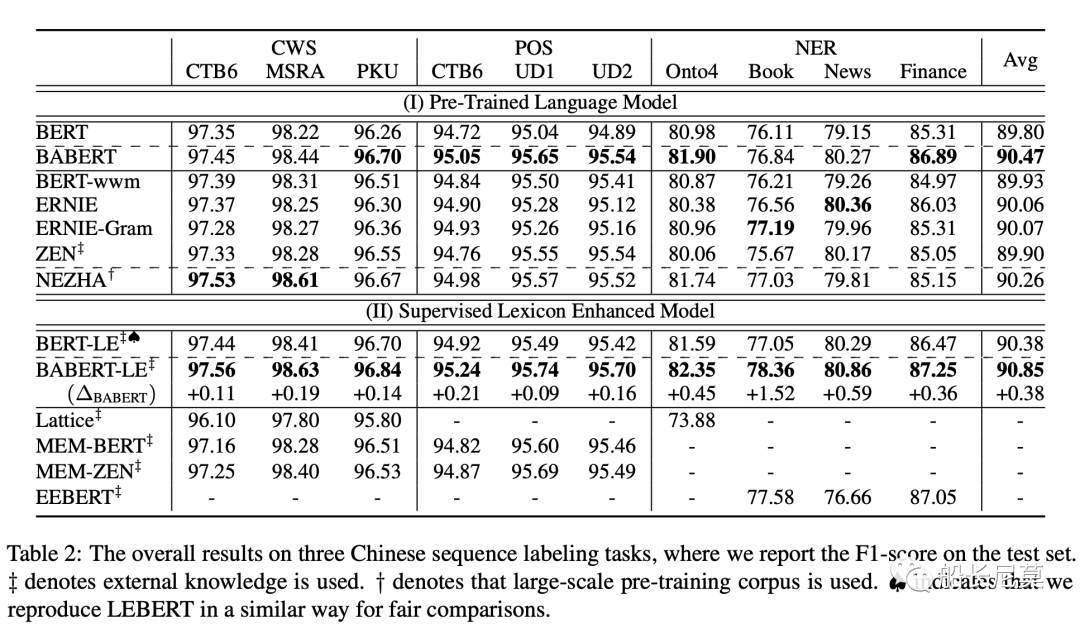
從結果的角度來講,提升是比較明顯的,相對于原始的BERT,很多數值都已經刷到了SOTA,確實是一篇很容易借鑒的工作。
寫在最后
在本文,提出了BABERT,一種用于中文序列標記的新的無監督邊界感知預訓練模型。在BABERT中,給定一個中文句子,使用無監督統計信息計算邊界感知表示以捕獲邊界信息,并在預訓練期間將這些信息直接注入BERT的參數學習。與之前的工作不同,BABERT開發了一種以無監督方式利用邊界信息的有效方法,從而減輕了基于監督詞典的方法的局限性。在三個不同任務的十個基準數據集上的實驗結果表明,方法非常有效,并且優于其他中文的預訓練模型。此外,與監督詞典擴展相結合可以在大多數任務上實現進一步的改進和最先進的結果。
接下來船長提幾個問題,讀者可以思考一下:
我想用這個模型,如何使用呢?
首先,先拿論文的框架訓練出BABERT,然后在自己的語料上訓練/微調,最終可以當做一個普通BERT來使用,我們可以做NER任務,也可以去做CWS任務。
這個模型好用嗎?
客觀的來說,這個模型有一些地方很難調參,比如說MSE Loss,還有MSE Loss中的隱狀態的層數,我們并不知道哪一層的結果最好。總不能每次實驗都去確定層數吧?這點很困難。除了上述的,其他的都比較好復現。
審核編輯:劉清
-
SCWS技術
+關注
關注
0文章
2瀏覽量
5822 -
PMI
+關注
關注
0文章
15瀏覽量
9254 -
NER
+關注
關注
0文章
7瀏覽量
6209
原文標題:如何將邊界信息融入到預訓練模型中?最新頂會告訴你答案
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
KerasHub統一、全面的預訓練模型庫

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習

預訓練模型的基本原理和應用
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
大語言模型推斷中的批處理效應






 工商網監
工商網監
評論