

沿著從大規(guī)模圖文多模態(tài)預訓練遷移適配到視頻多模態(tài)任務的思路,我們提出了模型LiteVL,它利用圖文預訓練模型BLIP來初始化參數,可以直接在下游任務上微調而不需要進行額外的昂貴的視頻文本預訓練。并且為了增強圖像語言模型中缺乏的時間建模,我們提出在BLIP的Image encoder中增加具有動態(tài)時間縮放(dynamic temporal scaling)的時間注意力模塊。除了模型方面的這一適配之外,我們還提出了一種非參數池化text-dependent pooling,以自適應地重新加權以文本為條件的細粒度視頻嵌入。我們選取了兩個具有代表性的下游任務,即文本-視頻檢索和視頻問答,來驗證所提出方法的有效性。實驗結果表明,所提出的LiteVL在沒有任何視頻文本預訓練的情況下,甚至明顯優(yōu)于以前的視頻文本預訓練模型。
1. Motivation
近期許多Video-language modeling的工作往往基于大規(guī)模video-text數據集 (WebVid2M,CC-3M,HowTo100M) 上進行預訓練,然后在下游任務的數據集上微調,而預訓練的成本往往十分昂貴。另一方面,學習細粒度的visual-language對齊往往需要利用離線的目標檢測器 (e.g., ActBERT) 來捕捉物體信息,但卻受限于檢測器有限的類別數量 (e.g., 在MSCOCO數據集上訓練的目標檢測器只能檢測出不到100個類別) 和昂貴的計算開銷。而且沒有充分利用來自文本數據的監(jiān)督信息。此外,以往的稀疏幀采樣的video-text模型是利用image encoder在大規(guī)模圖文對上預訓練的,它忽略了視頻理解所需要的時序信息建模 (e.g., CLIPBERT)。最近,在單一視頻模態(tài)領域的研究上,基于預訓練的圖像編碼器ViT初始化而來的TimeSformer在許多下游的視頻任務上性能表現很好,它相比ViT僅僅插入了額外的一層用ViT的注意力層初始化來的時間注意力層。
2. Solution
我們提出了一種簡單且高效的視頻語言模型LiteVL,它是從近期的預訓練圖像語言模型BLIP初始化而來的,并且分別從模型層面和特征層面做了時域信息增強。
對于模型層面,我們提出用一組具有可學習scaling factor的時間注意層明確插入原始image backbone中,可以針對每個下游任務進行訓練調整(Dynamic Temporal Scaling):
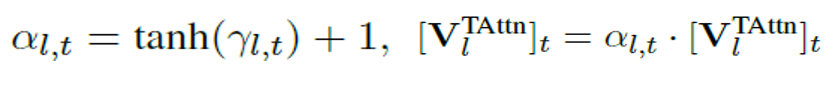
對于特征層面,我們設計了一種無參的特征池化方法(Text-dependent Pooling),以學習基于文本描述的細粒度時間-空間視頻特征:
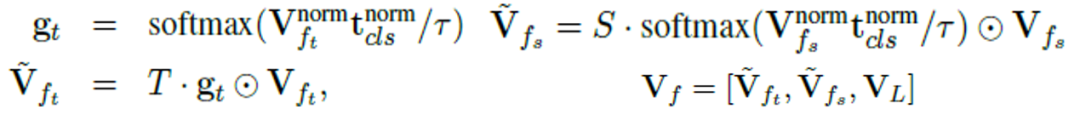
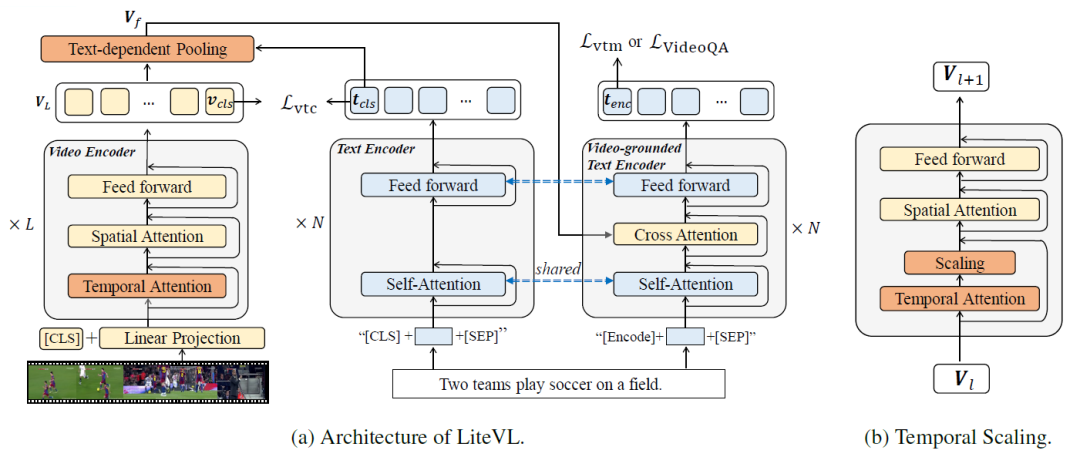
模型框架和動態(tài)時序scaling
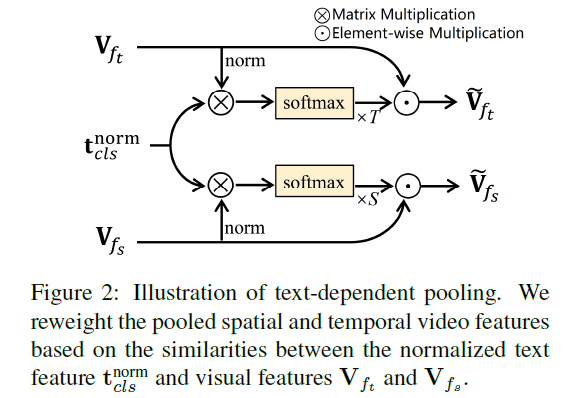
Text-dependent Pooling
3. Experiments
在三個視頻文本檢索數據集上和BLIP的性能比較:
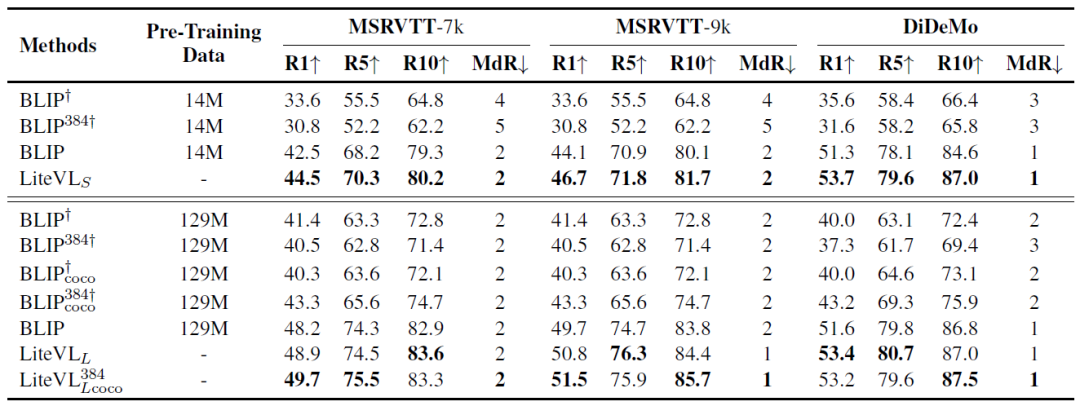
我們提出的LiteVL由于在模型和特征方面的顯式時間建模,最終性能優(yōu)于原始BLIP。
關于Dynamic Temporal Scaling和Text-dependent Pooling的消融實驗
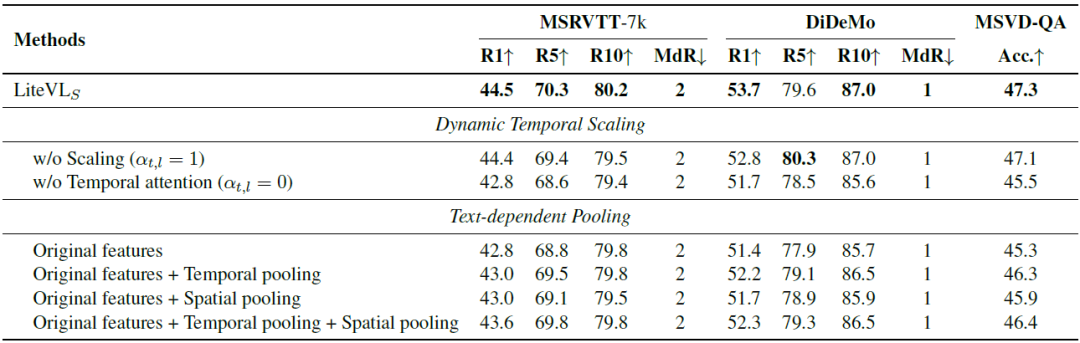
通過提出的輕巧的動態(tài)時間縮放自適應地根據每個特定任務調整框架級別的重要性,使性能得到進一步提高。此外,與僅使用原始特征相比,使用其他空間或時間池化后的特征會更好。
逐層的平均temporal scaling可視化分析
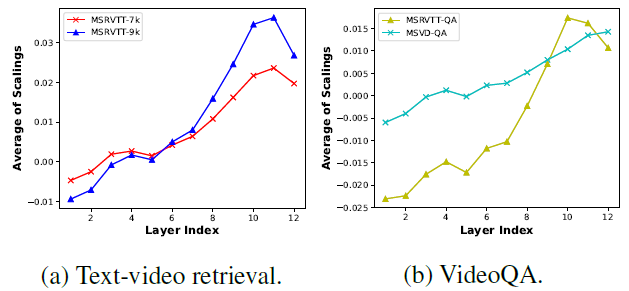
折線圖的變化趨勢顯示了video encoder的淺層更多地集中在理解每個幀的空間內容上,并更少注意不同幀之間的時間依賴性。當層的深度增加時,每個幀的空間特征變得更加全局,并且該模型逐漸尋求學習它們之間的時間依賴性。
Grad-CAM可視化分析

上圖展示了Grad-CAM可視化,提出的LiteVL有效地捕捉了不同幀之間的細微差異。這也表明我們提出的text-dependent pooling為video-grounded text encoder提供了豐富的信息。
4. Conslusion
我們提出了LiteVL,這是一種視頻語言模型,它無需大量的視頻語言預訓練或目標檢測器。LiteVL從預先訓練的圖像語言模型BLIP中繼承了空間視覺信息和文本信息之間已經學習的對齊。然后,我們提出了具有動態(tài)時間縮放的額外時間注意力塊,以學習視頻幀中的時間動態(tài)。我們還引入了一種無參的text-denpendent pooling,該方法基于文本描述來對不同幀或者空間位置進行加權,從而實現了細粒度的視頻語言對齊。實驗結果表明,我們的LiteVL優(yōu)于利用了視頻文本預訓練的最先進方法。
審核編輯:郭婷
-
檢測器
+關注
關注
1文章
882瀏覽量
48242 -
數據集
+關注
關注
4文章
1220瀏覽量
25183
原文標題:EMNLP 2022 | LiteVL:具有增強時空建模的高效視頻-語言學習
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
?VLM(視覺語言模型)?詳細解析

大語言模型的解碼策略與關鍵優(yōu)化總結






 工商網監(jiān)
工商網監(jiān)

評論