 圍繞深度學習的方法來講述激光雷達分割的問題
圍繞深度學習的方法來講述激光雷達分割的問題
簡介
激光雷達作為自動駕駛中最常用的傳感器之一,由于其深度感知特性優良,這也讓以激光SLAM為主的SLAM方法被廣泛應用。
但是我們發現在人員密集,車輛密集的場景經常會造成點云定位效果不佳,而這些情況傳統濾波方法是沒有辦法解決的。
本篇將主要圍繞著深度學習的方法來講述激光雷達分割的問題。
1. SLAM配準與建圖
無論哪種點云配準方式(點到點/點到特征/點到柵格/NDT),都是基于靜態假設的,理論上動態點一定會影響配準的精度,當然這一點用于建好地圖的定位也同樣適用。
當一幀中如果動態點比例過高的話,會造成軌跡精度下降,甚至不排除跑飛的可能。
在這個層面,只能通過實時的方式在配準之前或配準過程中,識別并干掉動態點。
如果我們認為動態物體對配準的干擾有限,不太影響軌跡精度,但我們還是無法忍受最終生成的地圖中充斥著大量動態物體的“鬼影”(如下圖所示)。
這會對后期基于地圖的定位、或者基于地圖的可行域規劃(路徑規劃)產生不利的影響。

1.1 傳統配準思路—-通過聚類+卡爾曼濾波預測過濾動態障礙物
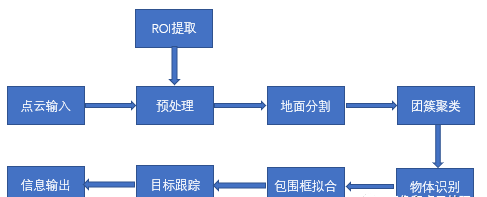
傳統方式比如在配準迭代過程中剔除距離過遠的點,物檢測流程一般如下:
考慮到車上有多個傳感器共同作業,需要對輸入的激光點云做時間同步和外參標定。
考慮到激光雷達的采樣噪聲和點云數據量大的問題,需要對點云做預處理,減少數據量,剔除噪聲點。
每幀點云數據中包含了大量的地面點,檢測的目的是獲取道路障礙物信息,需要進一步分割出地面上的點云。
地面上的障礙物點通常采用無監督的聚類算法形成多個團簇,每個團簇則表示一個障礙物。
針對團簇的物體識別可以根據任務需求而定,如果需要類別信息,可以采用特征提取+分類器的方式分類障礙物。
對每一塊團簇做包圍框擬合,計算障礙物屬性,比如中心點,質心點,長寬高等。
對每一個障礙物構建一個卡爾曼濾波器做跟蹤,平滑輸出,從而來判斷是否運動。
1.2 傳統配準思路—-適用submap來精配準
“RF-LIO: Removal-First Tightly-coupled Lidar Inertial dometry in High Dynamic Environments ”,這項工作就是傳統的匹配濾波的思路。
它建立在 LIO-SAM 的基礎上,先剔除是指所提出的RF-LIO首先去除沒有準確姿勢的運動物體,然后采用 scan-matching 。
當新的scan到達時,RF-LIO不會立即執行掃描匹配以獲得準確的位姿,因為它很容易受到動態環境的影響。
相反,我們使用緊耦合慣性測量單元 (IMU) 里程計來獲得粗略的初始狀態估計,然后 RF-LIO 可以利用自適應分辨率距離圖像初步去除環境中的運動點。
在初步去除運動點后,RF-LIO 使用 scan-matching 來獲得相對更準確的位姿。
在精配準迭代過程中,不斷基于初值和多分辨率深度圖檢測submap中的動態點并移除,最終實現基于“靜態submap”的精配準。
因此,即使在高動態環境中也可以獲得準確的姿勢。
實驗結果表明,在高動態環境下與 LOAM 和 LIO-SAM 相比,所提出的 RF-LIO 的絕對軌跡精度可以分別提高 90% 和 70%。
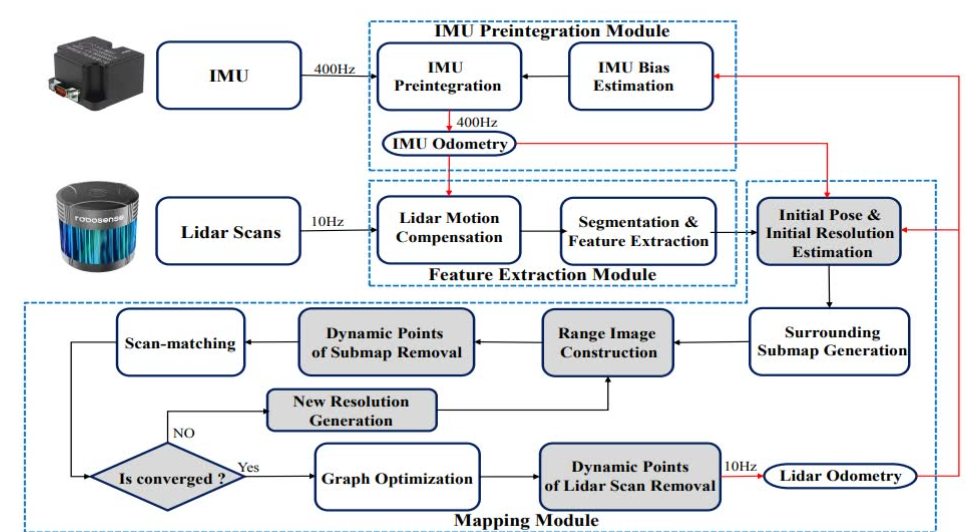
RF-LIO 的總體框架,它由三個主要模塊組成:IMU 預積分、特征提取和建圖。首先,IMU 預積分模塊用于推斷系統運動并生成 IMU 里程計。
然后,特征提取模塊補償點云的運動畸變。通過評估點的粗糙度來提取邊緣和平面特征。
建圖模塊是我們提出方法的關鍵模塊,要在沒有準確位姿的情況下先去除動態物體,
有幾個關鍵步驟:
初始位姿是通過 IMU 里程計獲得的。
然后使用 IMU 預積分和 scan-matching 之間的誤差來確定初始分辨率(即每個像素對應多少個 FOV 角度)。
RF-LIO 使用此初始分辨率從當前激光雷達掃描和相應的子圖分別構建距離圖像。
通過比較它們的能見度,去除子圖的大部分動態點。
RF-LIO 將激光雷達掃描與子圖進行匹配,并判斷 scan-matching 是否收斂。
如果是收斂的,經過圖優化后,用最終的高分辨率去除當前關鍵幀中剩余的動態點,否則,將生成新的分辨率,并重復步驟2、3、4。
1.3 現代配準思路—-通過深度學習實現動態物體識別
而當前更流行的方式則是基于deep-learning直接識別出動態物體并將點云去除。
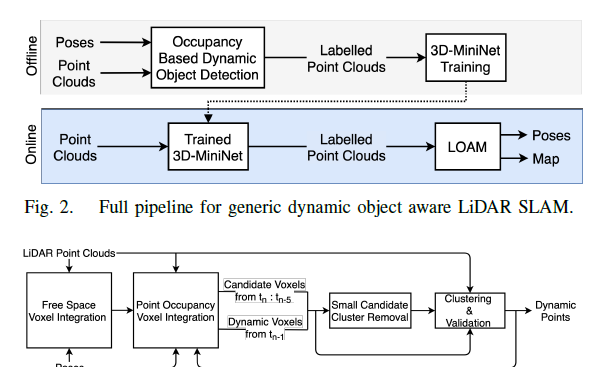
“Dynamic Object Aware LiDAR SLAM based on Automatic Generation of Training Data ”。
作者基于deep-learning(3D-MiniNet網絡)進行實時3D動態物體檢測,濾除動態物體后的點云被喂給LOAM,進行常規的激光SLAM。
文中提到為了克服動態障礙物的問題并支持機器人在現實世界場景中的部署,文章提出了一個用于動態對象感知激光雷達SLAM算法。
文中提出了一種新穎的端到端占用網格管道,可以自動標記各種各樣的任意動態對象。
從結果中,我們可以大致看出其可以有效地對動態障礙物完成分割。

2. 動態物體濾除
2.1 環境物體分類
環境中的所有物體依據“動態程度”的不同,分為四類:
高動態物體:實時移動的物體,如行人、車輛、跑動的寵物…
低動態物體:短暫停留的物體,如站在路邊短暫交談的人…
半靜態物體:在一個SLAM周期中不動,但是并非永遠不動的物體,如停車場的車輛、堆放的物料、臨時工棚、臨時圍墻、商場中臨時搭建的舞臺…
靜態物體:永遠不動的物體,如建筑物、馬路、路沿、交通信號燈桿…
除了靜態物體外的其它三類物體,都有不同程度上的動態屬性,應對策略也各不相同:
針對高動態物體:在線實時過濾
針對低動態物體:一次SLAM過程結束后,后處理方式過濾
針對半靜態物體:全生命周期建圖(life-longmapping, or long-term mapping)
2.2 實時點云過濾
實時動態點云過濾一定需要參考幀來比對出動態點,上面一節主要講述的就是動態點云濾除的操作,主要是分為傳統濾除方法以及深度學習濾除方法。
在深度學習方面基本思路就是先通過深度學習完成動態障礙物的分割,然后將分割好的點云數據放入SLAM當中。
這里主要闡述一個基于深度學習的三維激光雷達動態物體分割(LiDAR-MOS)方法,論文提出了一種利用深度學習和時空信息結合的方法實現了三維激光雷達動態物體分割,并用以提高激光雷達SLAM定位和建圖的精度。
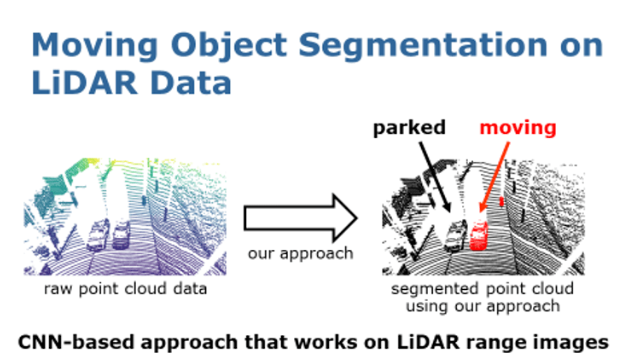
在這項工作中,我們的目標是對 LiDAR 數據進行動態物體分割 (LiDAR MOS)。
在這項工作中,與點云語義分割不同的是我們的任務不是要預測點云的語義類別,如車輛、道路、建筑物等,而是更專注于將場景分割成兩部分:
一部分是實際移動的物體,例如正在行駛的汽車、行人,另一部分是靜態物體,例如停放的汽車和靜態背景,例如道路和建筑物等。
我們提出了一種新的基于深度學習的方法,該方法利用 LIDAR 距離圖像(range image),運算速度非常快,能夠實現在線實時點云動態物體分割。
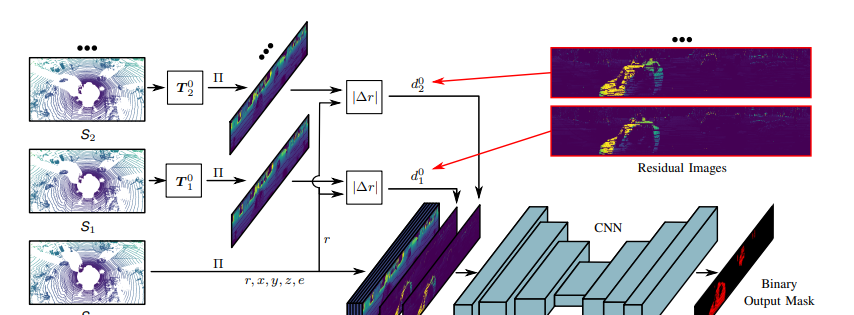
上面所展示的是該方法的概述圖。我們使用基于距離圖像的 LiDAR 表示方式和神經網絡來實現在線動態物體分割。
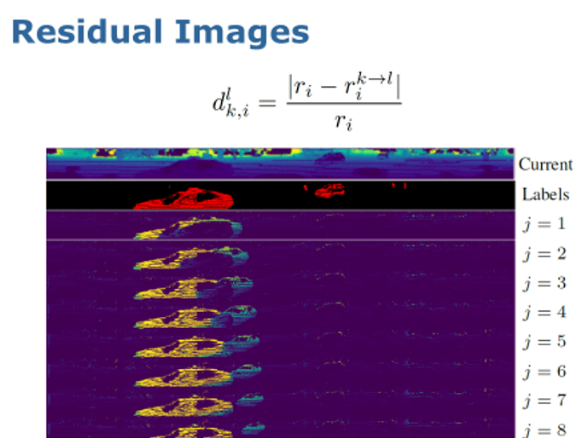
給定當前激光雷達觀測和過去的激光雷達數據,我們首先生成過去LiDAR數據和當前 LiDAR 觀測之間的“殘差圖像”(residual image),通過這種方式,我們可以得到時間上的序列信息。
生成殘差圖像后,我們將殘差圖與當前掃描連接到一起,一同用作神經網絡的輸入。
然后我們利用所提出的動態物體二分類標簽訓練神經網絡,該標簽僅包含移動和非移動的兩個類別。
最終,所提出的方法可以實現對激光雷達數據中動靜物體的檢測和分離。
2.3后處理點云過率
后處理方式由于不需要顧慮實時性,因此可以將整個SLAM周期內的所有幀作為參考信息,來識別動態點。
相比于實時方式,后處理方式更追求動態點云濾除的準確性和充分性。
以后處理方式為前提,常見的動態物體過濾方法可以分為典型的三類:segmentation-based, ray-casting based, 和 visibility-based


visibility-based其基本思路是,把一個queryscan投影為深度圖,然后在同一視點把queryscan附近的submap也投影為一個深度圖,比對兩個深度圖上同一位置的像素深度。
如果后者深度更淺,則該像素位置對應submap上的點為動態點(前方的點把后方的點遮擋了,則前方的點為動態點)。
Remove, then Revert: Static Point cloud Map Construction using Multiresolution Range Images
這篇文章以此為基本原理,做了諸多改進,并用更粗糙分辨率的深度圖對比來恢復被誤殺的靜態點。
本文為基于視點可見性(或基于深度圖)的方法提供了參考。

2.4life-long建圖
life-long mapping的核心問題,其實遠不止動態/半靜態物體過濾。
動態/半靜態物體過濾只是life-long過程中不同session之間地圖融合的一部分。
LT-mapper: A Modular Framework for LiDAR-based Lifelong Mapping提出一個long-term的點云建圖系統
其基本結構如下:
Multi-session SLAM優化
不同時間構建的點云地圖diff檢測
地圖更新和長期地圖管理
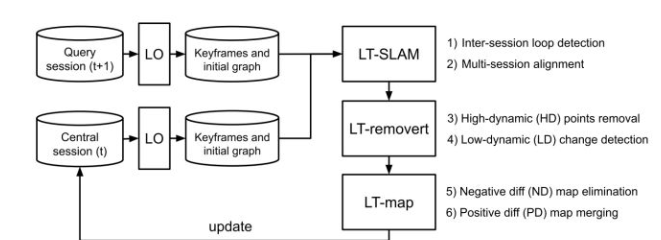
Multi-session SLAM:
每個session的點云地圖通過關鍵幀構建,對不同session的關鍵幀進行anchor node檢測,基于anchor幀構建的閉環因子實現Multi-session之間offset的修正。
在保證單個session pose最優的情況下,Multi-session之間的pose也是對齊的;
diff檢測:
首先會對新session的每一幀點云劃分動態點檢測,動態點會劃分為高動態(HD)和低動態 (LD) 兩種,高動態的點會在單次建圖完成后直接去除,低動態的點會根據kd-tree閾值區分。

地圖更新和長期地圖管理
構造兩種類型的靜態地圖:移除弱PD的meta map和保留弱PD的live map。metamap和livemap的示例如圖3所示。
在live map中,場景的最新表示將得到有效維護。在meta map中,non-volume-maximizing points被迭代刪除(紅色框),而其他永久結構保留。
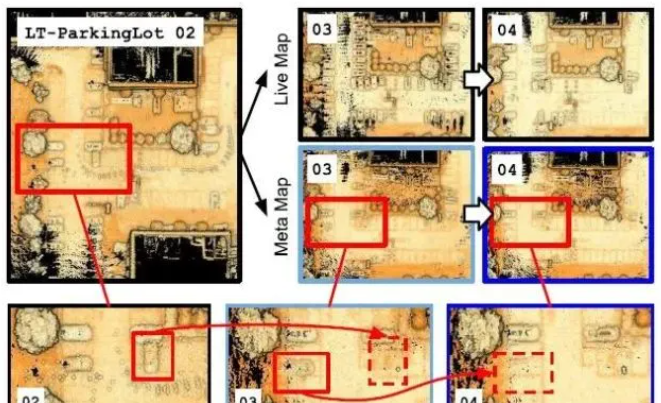
我們可以發現該life-long算法在第二部分也是對靜態和半靜態進行了濾波
3. 有所思考
目前眾多的開源方案中,基本上只要用了自己的數據集,就很少能達到論文展示的效果。
一種方法即使在理論上是完備的,實際中受限于雷達線束密集程度,軌跡誤差等因素,也不可能達到理想的效果。
目前但就過濾動態障礙物而言,個人還是提倡使用深度學習,因為傳統的PCL的RANSEC過濾方法難以滿足真實場景下的需求。
上文提到的實時處理/后處理/life-long處理這三種方法本質上基本一致,只是面對不同的需求設計了相似的方法,完全可以替換
可以嘗試多傳感器融合來規避這些問題,像激光、視覺、慣導里程等,因為通常環境變化不會對所有傳感器產生影響
也有人指出對于機器人來說SLAM的目的還是用來導航,導航只關心機器人對自身位置的感知,并不關心地圖是不是有誤差,所以可以使用位姿的拓撲圖來代替這類點云地圖。
審核編輯:劉清
-
SLAM
+關注
關注
23文章
426瀏覽量
31893 -
激光雷達
+關注
關注
968文章
4020瀏覽量
190228 -
NDT
+關注
關注
0文章
26瀏覽量
14961 -
自動駕駛
+關注
關注
784文章
13920瀏覽量
166794
原文標題:激光雷達動態障礙物濾除:調研與展望
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一則消息引爆激光雷達行業!特斯拉竟然在自研激光雷達?
全場景適用!TS Spectrum高速數字化儀在激光雷達系統中的應用

激光雷達會傷害眼睛嗎?

激光雷達的維護與故障排查技巧
如何提升激光雷達數據的精度
激光雷達技術的發展趨勢
TS高速數字化儀在激光雷達系統中的應用

LIDAR激光雷達逆向建模能用到revit當中嗎
光學雷達和激光雷達的區別是什么
一文看懂激光雷達

基于FPGA的激光雷達控制板

硅基片上激光雷達的測距原理

激光雷達的探測技術介紹 機載激光雷達發展歷程
激光雷達LIDAR基本工作原理






 工商網監
工商網監
評論