

香港中文大學(xué)(深圳)和清華大學(xué)聯(lián)合完成的后門防御工作被NeurIPS 2022接收為Spotlight論文。基于投毒的后門攻擊對由不可信來源數(shù)據(jù)所訓(xùn)練的模型構(gòu)成了嚴(yán)重威脅。給定一個(gè)后門模型,我們觀察到,相較于干凈樣本,毒性樣本的特征表示對數(shù)據(jù)變換更加敏感。這啟發(fā)我們設(shè)計(jì)了一個(gè)簡單的敏感性度量——“針對數(shù)據(jù)變換的特征一致性(FCT)”,并基于FCT設(shè)計(jì)了一個(gè)樣本區(qū)分模塊,用以區(qū)分不可信訓(xùn)練集中的毒性樣本和干凈樣本。此外,基于上述模塊,我們提出了兩種有效的后門防御方法,分別適用于不同的防御場景。第一種方法用于從頭訓(xùn)練出一個(gè)安全模型(in-training defense),涉及一個(gè)兩階段的安全訓(xùn)練模塊。第二種方法用于移除后門模型中的后門(post-training defense),包含一個(gè)交替遺忘毒性樣本和重新學(xué)習(xí)干凈樣本的后門移除模塊。在3個(gè)基準(zhǔn)數(shù)據(jù)集和8種后門攻擊上的實(shí)驗(yàn)結(jié)果表明了我們方法相較于SOTA防御方法的優(yōu)越性能。

論文標(biāo)題: Effective Backdoor Defense by Exploiting Sensitivity of Poisoned Samples
收錄會議: NeurIPS 2022 (Spotlight)
論文鏈接: https://openreview.net/pdf?id=AsH-Tx2U0Ug
代碼鏈接: https://github.com/SCLBD/Effective_backdoor_defense
1 問題背景
訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)(DNNs)往往需要大量的訓(xùn)練數(shù)據(jù),這些數(shù)據(jù)有時(shí)可能由不可信的第三方來源所提供。這些不可信的數(shù)據(jù)可能會對模型的訓(xùn)練帶來嚴(yán)重的安全威脅。典型的威脅之一就是基于投毒的后門攻擊,它可以通過投毒一小部分訓(xùn)練樣本(即:給這部分樣本的圖像加上指定的觸發(fā)器,并把它們的標(biāo)簽改為某個(gè)目標(biāo)類別),來向模型中注入后門(即:在訓(xùn)練過程中,模型能夠?qū)W到觸發(fā)器和目標(biāo)類別之間的映射)。一般地,一個(gè)后門模型可以很好地預(yù)測干凈樣本,并且能將任何帶有觸發(fā)器的毒性樣本預(yù)測為目標(biāo)類別。為了解決上述威脅,本文提出2個(gè)有效的后門防御方法,即使使用不可信來源的數(shù)據(jù)訓(xùn)練,我們?nèi)阅艿玫桨踩⒏蓛舻哪P汀?/p>
2 方法介紹
方法的總體框架如圖所示:
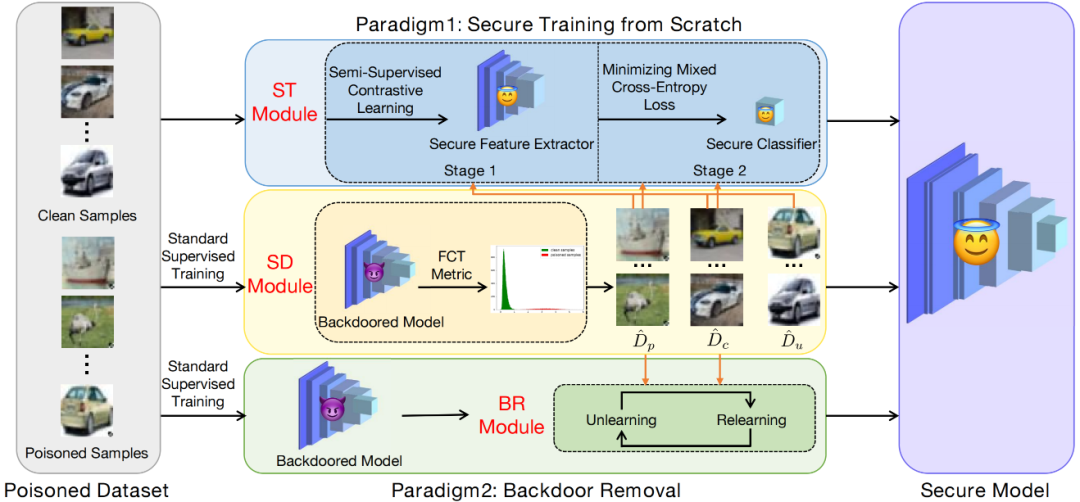
2.1 樣本區(qū)分模塊
我們觀察到,在后門模型的特征空間中,帶有觸發(fā)器的毒性樣本總是會匯聚到一起,如下圖的紅色實(shí)心點(diǎn)所示。這表示,即使毒性樣本包含著不同的物體,這些物體所代表的信息都被后門模型所忽略了。換句話說,毒性樣本的特征表示由觸發(fā)器所主導(dǎo),而不是物體。因此,我們猜測:這樣的主導(dǎo)作用來源于后門模型對觸發(fā)器的過擬合,這是因?yàn)樵诓煌亩拘詷颖局校|發(fā)器比物體具備更少多樣性。
為了驗(yàn)證這一猜測,我們嘗試對干凈和毒性樣本分別進(jìn)行相同的數(shù)據(jù)變換,如旋轉(zhuǎn)。我們觀察到,毒性樣本的特征表示不再匯聚到一起,而是移動到各自的ground-truth類別中,如下圖的紅+所示。這表示,觸發(fā)器的主導(dǎo)作用消失了,我們也證實(shí)了上述的猜測。此外,我們發(fā)現(xiàn),雖然干凈樣本的特征表示也受到數(shù)據(jù)變換的影響,但是相較于毒性樣本,這些影響小得多。這些觀察給了我們啟發(fā):我們可以利用特征表示對數(shù)據(jù)變換的敏感性來區(qū)分干凈和毒性樣本。
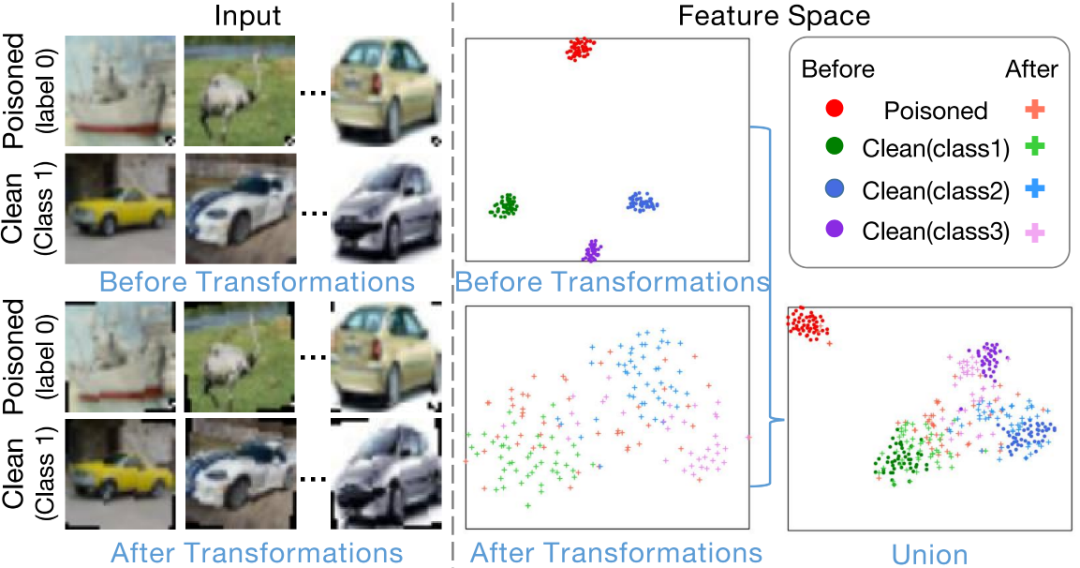
接下來,我們設(shè)計(jì)了一個(gè)度量——針對圖像變換的特征一致性(FCT),來描述這種敏感性。
如下圖所示,我們發(fā)現(xiàn),依據(jù)這個(gè)度量,干凈與毒性樣本的分布具有顯著差異。其中,左圖/右圖對應(yīng)被BadNets attack/Blend attack攻擊后的數(shù)據(jù)集。
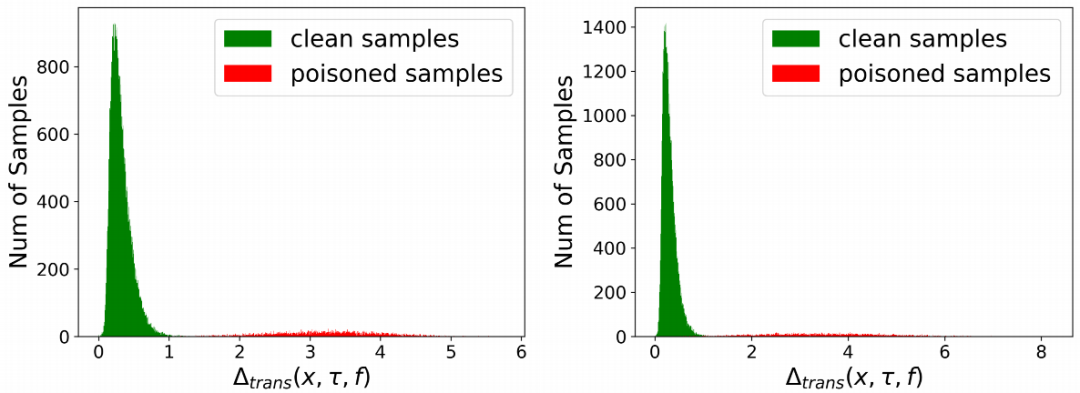
因此,基于FCT,我們可以建立一個(gè)樣本區(qū)分模塊(Sample-distinguishment module)。基本規(guī)則是選取FCT最大的一部分作為毒性樣本,F(xiàn)CT最小的一部分作為干凈樣本。
2.2 安全訓(xùn)練模塊
結(jié)合樣本區(qū)分模塊,我們設(shè)計(jì)了一個(gè)兩階段的安全訓(xùn)練模塊two-stage secure training (ST) module,這2個(gè)模塊共同組成防御方法D-ST,它適用于in-training defense的防御場景,即:給定一個(gè)毒性數(shù)據(jù)集,此方法可以從頭訓(xùn)練出一個(gè)安全的(準(zhǔn)確率高且不包含后門)的模型,且在整個(gè)訓(xùn)練過程中模型都不會被注入后門。
2.2.1 階段一:用半監(jiān)督對比學(xué)習(xí)(SS-CTL)來學(xué)習(xí)特征提取器
現(xiàn)有防御方法DBD使用對比學(xué)習(xí)(CTL)來學(xué)習(xí)特征提取器,在這一過程中,干凈樣本的標(biāo)簽所包含的有價(jià)值信息會流失。另一方面,研究表明,相較于CTL,有監(jiān)督對比學(xué)習(xí)(S-CTL)可以學(xué)到表現(xiàn)更好的特征提取器。因此,考慮到樣本區(qū)分模塊可以鑒別干凈樣本,我們提出半監(jiān)督對比學(xué)習(xí)(SS-CTL)來學(xué)習(xí)一個(gè)不包含后門的安全的特征提取器。SS-CTL的損失函數(shù)如下:
對于每個(gè)毒性樣本和不確定樣本,SS-CTL將促使它的2個(gè)數(shù)據(jù)增強(qiáng)版本靠近;對于每個(gè)干凈樣本,SS-CTL將促使所有同類干凈樣本的數(shù)據(jù)增強(qiáng)版本靠近。
2.2.1 階段二:用混合交叉熵?fù)p失來學(xué)習(xí)分類器
給定訓(xùn)練好的安全特征提取器,我們設(shè)計(jì)了一個(gè)混合交叉熵函數(shù)來學(xué)習(xí)分類器,表示如下:
它能夠從干凈樣本學(xué)習(xí)到正確映射的同時(shí),防止后門注入分類器。
2.3 后門移除模塊
結(jié)合樣本區(qū)分模塊,我們設(shè)計(jì)了一個(gè)后門移除模塊backdoor removal (BR) module,這2個(gè)模塊共同組成防御方法D-BR,它適用于post-training defense的防御場景,即給定一個(gè)毒性數(shù)據(jù)集,我們先使用標(biāo)準(zhǔn)監(jiān)督訓(xùn)練得到一個(gè)準(zhǔn)確率高且包含后門的模型,再利用此方法移除模型中的后門,從而得到一個(gè)安全的(準(zhǔn)確率高且不包含后門)模型。特別地,后門移除模塊本質(zhì)上是一個(gè)交替學(xué)習(xí)算法,包含了2個(gè)交替的步驟,分別是遺忘與重新學(xué)習(xí)。
2.3.1 遺忘
這一步旨在通過遺忘從毒性樣本中學(xué)到的知識來移除后門,損失函數(shù)如下:
2.3.3 重新學(xué)習(xí)
這一步旨在通過從干凈樣本中重新學(xué)習(xí)知識來維持模型的識別準(zhǔn)確率,損失函數(shù)如下:
3 實(shí)驗(yàn)結(jié)果
3.1 D-ST的有效性
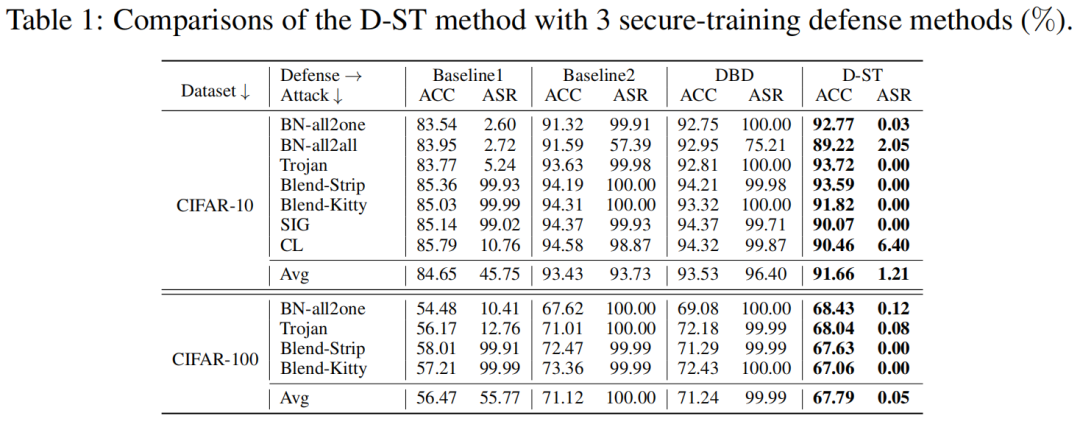
我們選取適用于安全訓(xùn)練防御范式的方法DBD來作為baseline。此外,我們設(shè)計(jì)2個(gè)baseline方法。Baseline1和baseline2分別用CTL和S-CTL來訓(xùn)練特征提取器,且都用標(biāo)準(zhǔn)交叉熵來訓(xùn)練分類器。表1表示我們的方法D-ST不僅能夠得到較高的ACC,還能將平均ASR抑制為1.21%(在CIFAR-10數(shù)據(jù)集上,在CIFAR-100上則是0.05%)。
3.2 D-BR的有效性
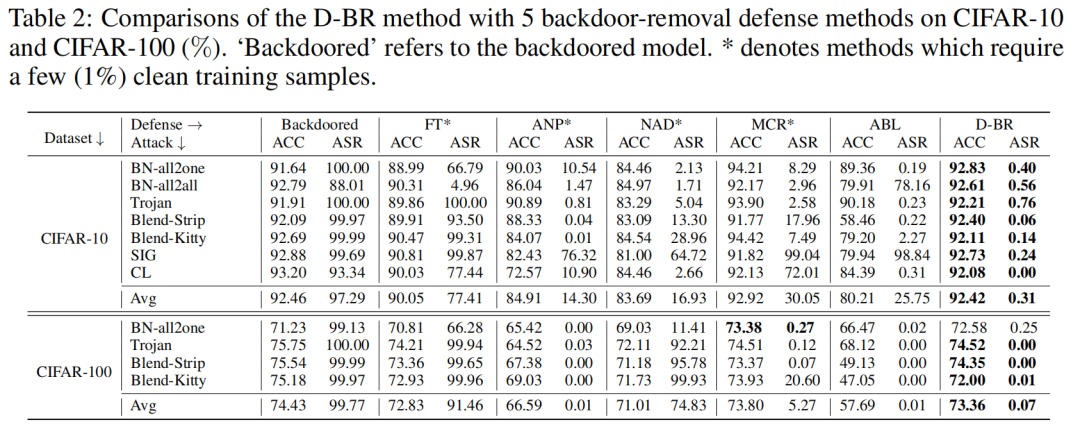
我們選取5個(gè)適用于后門移除防御范式的SOTA方法來作為baselines。表2表示我們的方法D-BR不僅能夠維持高ACC,還能將平均ASR由97.29%減小至0.31%(在CIFAR-10數(shù)據(jù)集上,在CIFAR-100上則是由99.77%減小至0.07%)。
3.3 其它實(shí)驗(yàn)
除了上述的主體實(shí)驗(yàn)以外,我們做了大量的實(shí)驗(yàn)來說明:(1)單個(gè)SD模塊的有效性,(2)單個(gè)BR模塊的有效性,(3)單個(gè)ST模塊的有效性,(4)在不同數(shù)據(jù)變換類型下方法的表現(xiàn),(5)在不同干凈/毒性樣本選擇比例下方法的表現(xiàn),(6)在不同投毒比例下方法的表現(xiàn),(7)在不同模型結(jié)構(gòu)及特征維度下方法的表現(xiàn)。更多的結(jié)果與分析請見原論文。
4 總結(jié)
在本文中,我們揭示了毒性樣本對數(shù)據(jù)變換的敏感性,并提出了一個(gè)敏感性度量(FCT)。此外,我們提出了樣本區(qū)分模塊(SD module),安全訓(xùn)練模塊(ST module)和后門移除模塊(BR module)3個(gè)模塊,它們構(gòu)成了2種適用于不同防御范式的后門防御方法(D-ST, D-BR)。大量的實(shí)驗(yàn)分別證明了每個(gè)模塊與整體方法的有效性。
審核編輯 :李倩
-
模塊
+關(guān)注
關(guān)注
7文章
2784瀏覽量
49734 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102923 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25297
原文標(biāo)題:NeurIPS 2022 | 一種基于毒性樣本敏感性的有效后門防御!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
兩種感應(yīng)電機(jī)磁鏈觀測器的參數(shù)敏感性研究
VirtualLab Fusion應(yīng)用:氧化硅膜層的可變角橢圓偏振光譜(VASE)分析
IGBT器件的防靜電注意事項(xiàng)
《電子技術(shù)基礎(chǔ)》(模電+數(shù)電)教材配套課件PPT
VirtualLab Fusion應(yīng)用:氧化硅膜層的可變角橢圓偏振光譜(VASE)分析
使用Phase Lab2024A計(jì)算合金抗裂敏感性
什么是濕度敏感等級 MSL (Moisture Sentivity levels)?

防御性編程:讓系統(tǒng)堅(jiān)不可摧
虹科干貨 溫度敏感性藥品的安全守護(hù)秘籍

點(diǎn)成干貨 溫度敏感性藥品不同儲運(yùn)容器的溫度監(jiān)測方法

溫度敏感性藥品不同儲運(yùn)容器的溫度監(jiān)測方法

點(diǎn)成干貨 溫度敏感性藥品的安全守護(hù)秘籍
無人機(jī)主動防御系統(tǒng)不起作用嗎
無人機(jī)主動防御系統(tǒng)有什么作用
振蕩器動態(tài)相位噪聲優(yōu)化的四步實(shí)操指南





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論