 Arm NEON編程技術上手指南
Arm NEON編程技術上手指南
1 簡介
本文旨在介紹Arm NEON技術,希望NEON初學者在閱讀本文后能很快上手開始NEON編程。
2 NEON概覽
本節介紹NEON技術及一些背景知識。
2.1 什么是NEON?
NEON是指適用于Arm Cortex-A系列處理器的一種高級SIMD(單指令多數據)擴展指令集。NEON 技術可加速多媒體和信號處理算法(如視頻編碼/解碼、2D/3D 圖形、游戲、音頻和語音處理、圖像處理技術、電話和聲音合成)。
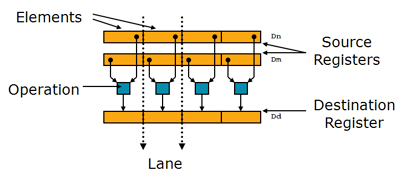
NEON 指令可執行并行數據處理:
寄存器被視為同一數據類型的元素的矢量
數據類型可為:8 /16 /32/64 位整數,單精度(Arm 32位平臺),單精度浮點/雙精度浮點(Arm 64位平臺)
指令在所有通道中執行同一操作
 ?
?
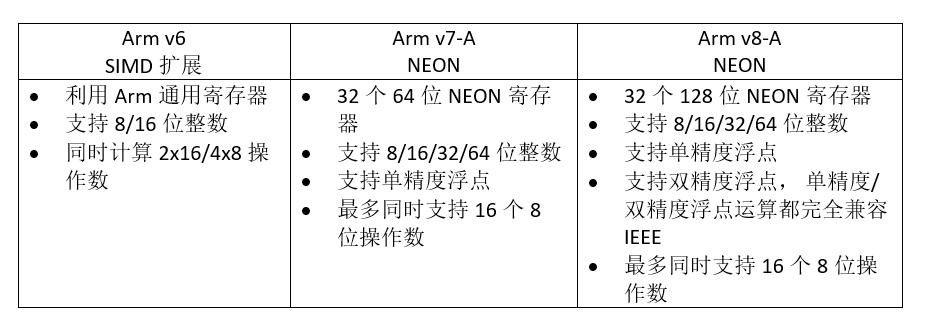
2.2 Arm 高級SIMD發展歷史
 ?
?
2.3 為什么要用NEON
NEON提供:
支持整數和浮點操作,以確保適合從編解碼器、高性能計算到 3D 圖形等廣泛應用領域。
與 Arm處理器緊密結合,提供指令流和內存的統一視圖,編程比外部硬件加速器更簡單。
3 Arm v8架構簡介
Arm v8-A是一個非常重要的架構變化,它支持64位執行模式 “AArch64” ,并且帶來了全新的64位指令集 “A64” 。同時,為了兼容Arm v7-A (32位架構)指令集,也引入了 “AArch32” 的概念。大部分Arm v7-A代碼可以運行在Arm v8-A AArch32執行模式下。
本節會對Arm v8-A 架構NEON相關的特點做出一些介紹。此外,本節也會略微介紹在NEON編程時經常使用的CPU通用目的寄存器和CPU指令,但是重點依然是NEON技術。
3.1 寄存器
Arm v8-A AArch64有31個64位通用目的寄存器,每一個通用寄存器具有64位(X0-X30)或是32位模式(W0-W30)。其寄存器視圖如下: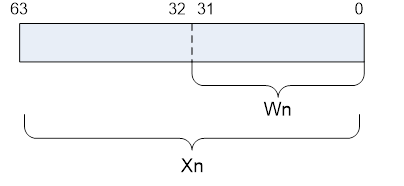
Arm v8-A AArch64有32個128位寄存器,也能當作32位Sn寄存器或是64位Dn寄存器使用。其寄存器視圖如下: ?
?
3.2 指令集
Arm v8-A AArch32指令集是由A32(Arm指令,32 位固定長度指令集)和T32(Thumb指令集,16 位固定長度指令集;Thumb2指令集, 16/32位長度指令集)指令集組成。它是Arm v7 Cortex-A指令集的超集,因此Arm v8-A AArch32能后向兼容Arm v7-A以便運行早期軟件。同時,為了維持與A64指令集的一致性,AArch32指令集又新增了NEON除法,加密指令擴展。
與AArch32指令集相比,AArch64指令集A64(32位固定長度)發生了很大變化,比如,它們具有完全不同的指令格式。但是在功能上來說,AArch64指令集基本上實現了AArch32指令集的全部功能,另外添加了NEON雙精度浮點的支持。
3.3 NEON指令格式
現在大部分已經是Arm v8平臺,因此本節只介紹AArch64 NEON指令格式。通用描述如下:
{
這里:
P:將向量按對操作,例如ADDP
V:跨所有的數據通道操作,例如FMAXV
2:在寬指令/窄指令中操作數據的高位部分。例如ADDHN2,SADDL2。
ADDHN2:兩個128位矢量相加,得到64位矢量結果,并將結果存到NEON寄存器的高64位部分。
SADDL2:兩個NEON寄存器的高64位部分相加,得到128-位結果。
下面列出具體的NEON指令例子:
UADDLP V0.8H, V0.16B
FADD V0.4S, V0.4S, V0.4S
更多內容請參考 Armasm_user_guide.pdf(http://infocenter.arm.com/help/topic/com.Arm.doc.dui0801g/DUI0801G_Armasm_user_guide.pdf)
13~15章介紹A32和T32指令。
16~20章介紹A64指令,其中第20章專門介紹NEON指令。
4 NEON編程基礎
上面幾章已經介紹了NEON的概念,硬件資源和指令集。現在我們可以開始使用NEON開始加速我們的應用了。使用NEON 技術通常有下列四種方式:
調用NEON優化過的庫函數
使用編譯器自動矢量化選項
使用NEON intrinsics指令
手寫NEON匯編
4.1 調用庫函數
用戶只需要在程序中直接調用NEON優化過的庫函數就可以了,簡單易用。目前你有下列庫可以選擇:
Arm Compute library
一系列經過Arm CPU和GPU優化過的底層函數庫。用于圖像處理、機器學習和計算機視覺。更多信息: https://developer.Arm.com/technologies/compute-library
Ne10開源庫
由Arm主導開發的,目前提供了比較通用的數學函數,部分圖像處理函數,以及FFT函數。http://projectne10.github.io/Ne10/
4.2 自動矢量化
在GCC編譯器選項中有自動矢量化編譯選項可以幫助現有的代碼編譯生成NEON代碼。GNU GCC提供一系列的選項,有的能提升性能,有的能降低生成可執行文件的代碼大小。
對于每一行代碼,有很多種匯編指令可以選擇。編譯器在寄存器、堆棧空間、代碼大小、編譯時間、便于調試、指令執行時間等許多選項中必須有所取舍,這樣才能生成最優的映像文件。
4.3 NEON intrinsics
NEON intrinsics可以視作在NEON指令上面封裝了一層接口。當用戶在C程序中調用NEON intrinsics接口時,編譯器會自動生成相關的NEON指令。
NEON intrinsics可以跨Arm v7-A/v8-A運行。只要編程一次,就可以借助編譯器生成相應的NEON代碼。
如果用戶在代碼中使用了Arm v8-A AArch64特有的NEON指令,只要如下例所示,用宏定義(__aarch64__)將這部分代碼分隔即可。
下面是NEON intrinsics的一個例程。
//下面是浮點數組的加法,假設count為4的整數倍 #includevoidadd_float_c(float*dst,float*src1,float*src2,intcount) { inti; for(i=0;i 通過查看反匯編,在Arm v7-A下,可以看到vld1/vadd/vst1 NEON指令。在Arm v8-A下可以看到ldr/fadd/str NEON指令。
4.4 NEON匯編
NEON手寫匯編主要有兩種方式:
獨立匯編文件
內嵌匯編
4.4.1 獨立匯編文件
獨立匯編文件可以用“.S”作為文件后綴,也可以用“.s”作為文件后綴。區別在于.S文件會經過C/C++預處理器處理,這樣我們可以利用宏定義等C語言特性。
手寫NEON匯編文件時,我們需要注意寄存器的保存。對于Arm v7/v8我們需要保存下列寄存器:?
下面是Arm v7-A/v8-A NEON 匯編的一個例程。
//在頭文件中定義 voidadd_float_neon2(float*dst,float*src1,float*src2,intcount);下面是手寫匯編代碼,保存到.S文件中//Armv7-A/Armv8-AAArch32版本 .text .syntaxunified .align4 .globaladd_float_neon2 .typeadd_float_neon2,%function .thumb .thumb_func add_float_neon2: .L_loop: vld1.32{q0},[r1]! vld1.32{q1},[r2]! vadd.f32q0,q0,q1 subsr3,r3,#4 vst1.32{q0},[r0]! bgt.L_loop bxlr//Armv8-AAArch64版本 .text .align4 .globaladd_float_neon2 .typeadd_float_neon2,%function add_float_neon2: .L_loop: ld1{v0.4s},[x1],#16 ld1{v1.4s},[x2],#16 faddv0.4s,v0.4s,v1.4s subsx3,x3,#4 st1{v0.4s},[x0],#16 bgt.L_loop ret更多代碼請參考: https://github.com/projectNe10/Ne10/tree/master/modules/dsp
4.4.2 內嵌匯編
顧名思義,內嵌匯編是和C代碼緊密結合在一起的一種方式。我們可以直接把匯編代碼內嵌在C/C++代碼中,我們可以在需要NEON的地方即時添加。
優點:
過程調用規則簡單,不需要自己手動保存寄存器。
可以使用 C/C++ 變量和函數,因此它能非常容易地整合到 C/C++ 代碼
缺點:
內嵌匯編有一套復雜的語法規則
NEON代碼內嵌在C/C++代碼中,不易于移植到其他平臺
例程:
//Armv7-A/Armv8-AAArch32 voidadd_float_neon3(float*dst,float*src1,float*src2,intcount) { asmvolatile( "1: " "vld1.32{q0},[%[src1]]! " "vld1.32{q1},[%[src2]]! " "vadd.f32q0,q0,q1 " "subs%[count],%[count],#4 " "vst1.32{q0},[%[dst]]! " "bgt1b " :[dst]"+r"(dst) :[src1]"r"(src1),[src2]"r"(src2),[count]"r"(count) :"memory","q0","q1" ); }//Armv8-AAArch64 voidadd_float_neon3(float*dst,float*src1,float*src2,intcount) { asmvolatile( "1: " "ld1{v0.4s},[%[src1]],#16 " "ld1{v1.4s},[%[src2]],#16 " "faddv0.4s,v0.4s,v1.4s " "subs%[count],%[count],#4 " "st1{v0.4s},[%[dst]],#16 " "bgt1b " :[dst]"+r"(dst) :[src1]"r"(src1),[src2]"r"(src2),[count]"r"(count) :"memory","v0","v1" ); }更多例程請參考libyuv
4.5 NEON intrinsics和NEON匯編
NEON intrinsics和NEON手寫匯編是最常使用的NEON優化方式。
下面就這兩種方式的優缺點做一些簡單對比。
NEON 匯編 NEON intrinsic 性能 對于指定平臺,匯編總是呈現最好性能。 現在的編譯器已經能得到媲美手工匯編的性能。 可移植性 Arm v7-A/v8-A平臺 具有不同的匯編格式。即使在Arm v8-A平臺,匯編程序可能也需要針對Cortex A53/A57微架構做出不同調整,才能呈現最好性能。 選擇合適的編譯器選項,一次編程即可以很容易實現跨平臺并針對該平臺微架構調整性能,例如Arm v7-A Cortex A9/A7/A15和Arm v8-A Cortex A53/A57。 可維護性 相比C語言,較難編程,可讀性較差 跟C語言類似,比較容易編程與維護
這只是簡單的優缺點對比,當應用NEON的情景比較復雜時,會有更多的特殊情況出現,在另一篇文章“Arm NEON 優化”中,我會對這個問題進行進一步分析。
有了以上基礎,選擇一種NEON實現方式,現在可以開始NEON編程之旅了!
審核編輯:劉清
-
ARM
+關注
關注
134文章
9089瀏覽量
367425 -
SIMD
+關注
關注
0文章
33瀏覽量
10289 -
NEON技術
+關注
關注
1文章
9瀏覽量
6079
原文標題:技術分享|Arm NEON編程快速上手指南
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用Arm Compiler 6自動矢量化功能為Neon編譯
ModelSim快速上手指南
RT-Thread文檔_RT-Thread 潘多拉 STM32L475 上手指南






 工商網監
工商網監
評論