") AI大模型開(kāi)源之困:壟斷、圍墻與算力之殤
AI大模型開(kāi)源之困:壟斷、圍墻與算力之殤
從新興技術(shù)轉(zhuǎn)變?yōu)?a href="http://www.1cnz.cn/tags/ai/" target="_blank">AI基礎(chǔ)設(shè)施,大模型開(kāi)源很重要,但也很難。
2020年6月,OpenAI發(fā)布GPT-3,其千億參數(shù)的規(guī)模和驚人的語(yǔ)言處理能力曾給國(guó)內(nèi)AI界帶來(lái)極大的震動(dòng)。但由于GPT-3未對(duì)國(guó)內(nèi)開(kāi)放,一批提供文本生成服務(wù)的商業(yè)公司在海外誕生時(shí),我們只能望洋興嘆。
今年8月,倫敦的開(kāi)源公司Stability AI發(fā)布文生圖模型Stable Diffusion,并免費(fèi)開(kāi)源了模型的權(quán)重和代碼,這迅速引發(fā)了AI作畫(huà)應(yīng)用在全球范圍內(nèi)的爆炸式增長(zhǎng)。
可以說(shuō),今年下半年的AIGC熱潮,開(kāi)源起到了直接的催化作用。
而當(dāng)大模型成為所有人都能參與的游戲時(shí),得益的并不僅僅是AIGC。
1 大模型開(kāi)源進(jìn)行時(shí)
四年前,一個(gè)名為BERT的語(yǔ)言模型問(wèn)世,以3億的參數(shù)量從此改變了AI模型的游戲規(guī)則。
今天,AI模型的體量已經(jīng)躍升至萬(wàn)億的規(guī)模,但大模型的“壟斷性”也隨之日益凸顯:
大公司、大算力、強(qiáng)算法、大模型,它們共同堆砌了一道普通開(kāi)發(fā)者和中小企業(yè)難以闖進(jìn)的圍墻。
技術(shù)壁壘,以及訓(xùn)練和使用大模型所需的計(jì)算資源和基礎(chǔ)設(shè)施,阻礙了我們從「煉」大模型走向「用」大模型的這條路。因此,開(kāi)源迫在眉睫。通過(guò)開(kāi)源讓更多人參與大模型的這場(chǎng)游戲,將大模型從一種新興的AI技術(shù)轉(zhuǎn)變?yōu)榉€(wěn)健的基礎(chǔ)設(shè)施,這正在成為許多大模型締造者的共識(shí)。
也是在這樣的共識(shí)下,前不久阿里巴巴達(dá)摩院在云棲大會(huì)上推出的中文模型開(kāi)源社區(qū)“魔搭”(ModelScope)在AI界引起了很大的關(guān)注,目前國(guó)內(nèi)的一些機(jī)構(gòu)已經(jīng)開(kāi)始在該社區(qū)上貢獻(xiàn)模型,或是建立自己的開(kāi)源模型體系。
國(guó)外的大模型開(kāi)源生態(tài)建設(shè)目前來(lái)看要領(lǐng)先于國(guó)內(nèi)。Stability AI是私營(yíng)公司出身但自帶開(kāi)源基因,有自己龐大的開(kāi)發(fā)者社區(qū),在開(kāi)源的同時(shí)還有穩(wěn)定的盈利模式。
今年7月發(fā)布的BLOOM有1760億參數(shù),是目前最大的開(kāi)源語(yǔ)言模型,它背后的BigScience更是完美契合了開(kāi)源精神,從頭到腳透露著與科技巨頭對(duì)弈的氣勢(shì)。BigScience由Huggingface帶頭發(fā)起的開(kāi)放式協(xié)作組織,并非正式成立的實(shí)體,BLOOM的誕生,是來(lái)自70多個(gè)國(guó)家的1000多名研究人員在超級(jí)計(jì)算機(jī)上訓(xùn)練了117天的結(jié)果。
另外,科技巨頭也并非沒(méi)有參與大模型的開(kāi)源。今年5月,Meta開(kāi)源了1750億參數(shù)的大模型OPT,除了允許OPT可被用于非商業(yè)用途外,還發(fā)布了其代碼以及記錄培訓(xùn)過(guò)程的100頁(yè)日志,可謂開(kāi)源得十分徹底。
研究團(tuán)隊(duì)在OPT的論文摘要里直截了當(dāng)?shù)刂赋觯缚紤]到計(jì)算成本,如果沒(méi)有大量資金,這些模型是很難復(fù)制的。對(duì)于少數(shù)可通過(guò)API獲得的模型,無(wú)法訪問(wèn)完整的模型權(quán)重,這致它們難以得到研究」。模型的全稱「Open Pre-trained Transformers」也表明了Meta的開(kāi)源態(tài)度。這可以說(shuō)是暗諷了一把由并不「Open」的OpenAI發(fā)布的GPT-3(僅提供API付費(fèi)服務(wù))、以及今年4月谷歌推出的5400億參數(shù)大模型PaLM(未開(kāi)源)。
在壟斷色彩一向濃厚的大廠中,Meta這番開(kāi)源的舉動(dòng)是一股清流。當(dāng)時(shí)斯坦福大學(xué)基礎(chǔ)模型研究中心的負(fù)責(zé)人Percy Liang評(píng)價(jià)道:「這是朝著開(kāi)辟研究新機(jī)遇邁出的令人興奮的一步,一般而言,我們可以認(rèn)為更強(qiáng)的開(kāi)放能夠使研究人員得以解決更深層次的問(wèn)題。」
2 大模型的想象力不應(yīng)止于AIGC
Percy Liang的這句話這也從學(xué)術(shù)層面回答了為何大模型一定要做開(kāi)源的問(wèn)題。
原創(chuàng)成果的誕生,需要開(kāi)源來(lái)提供土壤。
一個(gè)研發(fā)團(tuán)隊(duì)訓(xùn)練出一個(gè)大模型,如果止步于在頂級(jí)會(huì)議上發(fā)表一篇論文,那么其他研究人員得到的就只是論文中各種「秀肌肉」的數(shù)字,而看不到模型訓(xùn)練技術(shù)的更多細(xì)節(jié),只能花時(shí)間去復(fù)現(xiàn),還不一定能復(fù)現(xiàn)成功。可復(fù)現(xiàn)性是科學(xué)研究結(jié)果可靠、可信的一個(gè)保證,有了開(kāi)放的模型、代碼和數(shù)據(jù)集,科研人員便能更及時(shí)地跟上最前沿的研究,站在巨人的肩膀上去觸及一顆更高處的果實(shí),這可以省下許多時(shí)間成本、加快技術(shù)創(chuàng)新的速度。
國(guó)內(nèi)在大模型工作上的原創(chuàng)力不足,就主要體現(xiàn)為盲追模型尺寸、但在底層架構(gòu)上無(wú)甚創(chuàng)新,這是從事大模型研究的業(yè)內(nèi)專家的普遍共識(shí)。
清華大學(xué)計(jì)算機(jī)系的劉知遠(yuǎn)副教授向AI科技評(píng)論指出:國(guó)內(nèi)在大模型的架構(gòu)上有一些相對(duì)比較創(chuàng)新的工作,但基本上都還是以Transformer為基礎(chǔ),國(guó)內(nèi)還比較缺乏像Transformer這種奠基式架構(gòu),以及BERT、GPT-3這樣能夠引起領(lǐng)域大變革的模型。
IDEA研究院(粵港澳大灣區(qū)數(shù)字經(jīng)濟(jì)研究院 )的首席科學(xué)家張家興博士也告訴AI科技評(píng)論,從百億、千億到萬(wàn)億,我們突破了各種系統(tǒng)上、工程上的挑戰(zhàn)后,應(yīng)該要有新的模型結(jié)構(gòu)方面的思考,而不再是單純地把模型做大。
另一方面,大模型在技術(shù)上要取得進(jìn)步,還需有一套模型評(píng)估標(biāo)準(zhǔn),標(biāo)準(zhǔn)的產(chǎn)生則要求公開(kāi)和透明。最近的一些研究正在試圖對(duì)眾多大模型提出各種評(píng)估指標(biāo),但有一些優(yōu)秀的模型由于不可訪問(wèn)而被排除在外,如谷歌在其Pathways架構(gòu)下訓(xùn)練的大模型PaLM具備超強(qiáng)的語(yǔ)言理解能力,能輕松解釋笑話的笑點(diǎn),還有DeepMind的語(yǔ)言大模型Chinchilla,都沒(méi)有開(kāi)源。
但無(wú)論是從模型本身的出色能力還是從這些大廠的地位來(lái)看,它們都本不該缺席這樣的公平競(jìng)技場(chǎng)。
一個(gè)令人遺憾的事實(shí)是,Percy Liang最近與其同事合作的一項(xiàng)研究表明,與非開(kāi)源模型相比,目前的開(kāi)源模型在許多核心場(chǎng)景上的表現(xiàn)都存在一定的差距。如OPT-175B、BLOOM-176B以及來(lái)自清華大學(xué)的GLM-130B等開(kāi)源大模型,在各項(xiàng)任務(wù)上幾乎全面輸給了非開(kāi)源的大模型,后者包括OpenAI的InstructGPT、Microsoft/NVIDIA的TNLG-530B等等(如下圖)。
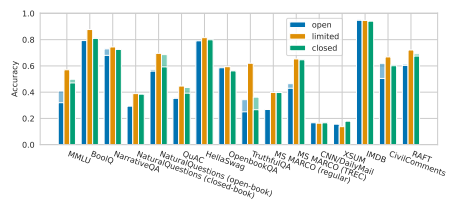
圖注:Percy Liang et al. Holistic Evaluation of Language Models
要消解這種尷尬局面,需要各個(gè)領(lǐng)頭羊們開(kāi)源開(kāi)放自家的優(yōu)質(zhì)大模型,這樣大模型領(lǐng)域的整體進(jìn)展才能更快地上一個(gè)臺(tái)階。
在大模型的產(chǎn)業(yè)落地方面,開(kāi)源更是一條必經(jīng)之路。
若以GPT-3的發(fā)布為起點(diǎn),大模型經(jīng)過(guò)兩年多的你追我趕,在研發(fā)技術(shù)上已經(jīng)較為成熟,但在全球范圍內(nèi),大模型的落地都還處于早期階段。國(guó)內(nèi)各個(gè)大廠所研發(fā)的大模型固然有內(nèi)部業(yè)務(wù)的落地場(chǎng)景,但整體上尚未有成熟的商業(yè)化模式。
在大模型落地正處蓄勢(shì)待發(fā)之時(shí),做好開(kāi)源能夠?yàn)閷?lái)大規(guī)模的落地生態(tài)打好基礎(chǔ)。
大模型的本質(zhì)決定了落地對(duì)開(kāi)源的需求。阿里巴巴達(dá)摩院副院長(zhǎng)周靖人告訴AI科技評(píng)論,「大模型是對(duì)人類知識(shí)體系的抽象與提煉,所以它能夠應(yīng)用的場(chǎng)景和產(chǎn)生的價(jià)值是巨大的。」而只有通過(guò)開(kāi)源,大模型的應(yīng)用潛力才能在眾多有創(chuàng)造力的開(kāi)發(fā)者那里得到最大限度的釋放。
這是封閉了大模型內(nèi)部技術(shù)細(xì)節(jié)的API模式所無(wú)法做到的。首先,這種模式的適用對(duì)象是低開(kāi)發(fā)能力的模型使用者,對(duì)他們而言,大模型落地的成敗相當(dāng)于完全掌握在研發(fā)機(jī)構(gòu)的手中。
以提供大模型API付費(fèi)服務(wù)的最大贏家OpenAI為例,據(jù)OpenAI的統(tǒng)計(jì),目前全世界已經(jīng)有300多個(gè)使用了GPT-3技術(shù)的應(yīng)用程序,但這個(gè)事實(shí)的前提是OpenAI的研發(fā)實(shí)力底氣足、GPT-3也足夠強(qiáng)大。如果模型本身性能不佳,那么這類開(kāi)發(fā)者也就束手無(wú)策了。
更關(guān)鍵的是,大模型通過(guò)開(kāi)放API所能提供的能力有限,難以承接復(fù)雜多樣的應(yīng)用需求。目前在市場(chǎng)上只是催生出一些具有創(chuàng)意的APP,但整體上還處于一種「玩具」的階段,遠(yuǎn)沒(méi)有達(dá)到大規(guī)模產(chǎn)業(yè)化的地步。
「產(chǎn)生的價(jià)值沒(méi)有那么大,成本又收不回來(lái),所以基于GPT-3 API的應(yīng)用場(chǎng)景非常受限,很多工業(yè)界的人其實(shí)并不認(rèn)可這種方式。」張家興說(shuō)道。的確,像國(guó)外的copy.ai、Jasper這些公司是選擇做AI輔助寫(xiě)作業(yè)務(wù),用戶市場(chǎng)相對(duì)更大,所以才能產(chǎn)生比較大的商業(yè)價(jià)值,而更多應(yīng)用還只是小打小鬧。
相比之下,開(kāi)源開(kāi)放做的是「授人以漁」。
在開(kāi)源模式下,企業(yè)憑借公開(kāi)的源代碼,在已有的基礎(chǔ)框架上進(jìn)行符合自己業(yè)務(wù)需求的訓(xùn)練、二次開(kāi)發(fā),這能夠發(fā)揮大模型的通用性優(yōu)勢(shì),釋放遠(yuǎn)超于現(xiàn)在的生產(chǎn)力,最終帶來(lái)大模型技術(shù)在產(chǎn)業(yè)中的真正落地。
作為目前大模型商業(yè)化落地最清晰可見(jiàn)的一條賽道,AIGC的這一波起飛已經(jīng)印證了大模型開(kāi)源模式的成功,然而在其他更多應(yīng)用場(chǎng)景上,大模型的開(kāi)源開(kāi)放仍屬少數(shù),國(guó)內(nèi)外皆是如此。西湖大學(xué)深度學(xué)習(xí)實(shí)驗(yàn)室的負(fù)責(zé)人藍(lán)振忠曾向AI科技評(píng)論表示,目前大模型的成果雖然有很多,但開(kāi)源極少,普通研究者的訪問(wèn)有限,這一點(diǎn)很令人惋惜。
貢獻(xiàn)、參與、協(xié)作,以這些關(guān)鍵詞為核心的開(kāi)源,能夠匯聚大量懷抱熱情的開(kāi)發(fā)者,共同打造一個(gè)可能具有變革意義的大模型項(xiàng)目,讓大模型更快地從實(shí)驗(yàn)室走向產(chǎn)業(yè)。
3 不可承受之重:算力
大模型開(kāi)源的重要性是共識(shí),但通往開(kāi)源的路上還有一個(gè)巨大的攔路虎:算力。
這也正是當(dāng)前大模型落地所面臨的最大挑戰(zhàn)。即便Meta開(kāi)源了OPT,但到目前為止它似乎還沒(méi)有在應(yīng)用市場(chǎng)上泛起大的漣漪,究其根本,算力成本仍然是小型開(kāi)發(fā)者的不可承受之重,先不說(shuō)對(duì)大模型做微調(diào)、二次開(kāi)發(fā),僅僅是做推理都很困難。
正因如此,在對(duì)拼參數(shù)的反思潮下,不少研發(fā)機(jī)構(gòu)轉(zhuǎn)向了做輕量模型的思路,將模型的參數(shù)控制在幾億至幾十億之間。瀾舟科技推出的「孟子」模型、IDEA研究院開(kāi)源的「封神榜」系列模型,都是國(guó)內(nèi)走這條路線的代表。他們將超大模型的各種能力拆分到參數(shù)相對(duì)更小的模型上,已經(jīng)在一些單項(xiàng)任務(wù)上證明了自身超越千億模型的能力。
但毫無(wú)疑問(wèn),大模型的路必然不會(huì)就此停下,多位業(yè)內(nèi)專家都向AI科技評(píng)論表示,大模型的參數(shù)依然有上升空間,肯定還要有人去繼續(xù)探索更大規(guī)模的模型。所以我們不得不直面大模型開(kāi)源后的窘境,那么,有哪些解決辦法?
我們首先從算力本身的角度來(lái)考慮。未來(lái)大規(guī)模計(jì)算機(jī)群、算力中心的建設(shè)肯定是一個(gè)趨勢(shì),畢竟端上的計(jì)算資源終歸難以滿足需求。但如今摩爾定律已經(jīng)趨緩,業(yè)界也不乏摩爾定律將要走向終結(jié)的論調(diào),如果單純地寄希望于算力的提升,是遠(yuǎn)水解不了近渴。
「現(xiàn)在一張卡可以跑(就推理而言)一個(gè)十億模型,按目前算力的增長(zhǎng)速度,等到一張卡可以跑一個(gè)千億模型也就是算力要得到百倍提升,可能需要十年。」張家興解釋。
大模型的落地等不了這么久。
另一個(gè)方向是在訓(xùn)練技術(shù)上做文章,加快大模型推理速度、降低算力成本、減少能耗,以此來(lái)提高大模型的易用性。
比如Meta的OPT(對(duì)標(biāo)GPT-3)只需要16塊英偉達(dá)v100 GPU就可以訓(xùn)練和部署完整模型的代碼庫(kù),這個(gè)數(shù)字是GPT-3的七分之一。最近,清華大學(xué)與智譜AI聯(lián)合開(kāi)源的雙語(yǔ)大模型GLM-130B,通過(guò)快速推理方法,已經(jīng)將模型壓縮到可以在一臺(tái)A100(40G*8)或V100(32G*8)服務(wù)器上進(jìn)行單機(jī)推理。
在這個(gè)方向上努力當(dāng)然是很有意義的,大廠們不愿意開(kāi)源大模型一個(gè)不言自明的原因,就是高昂的訓(xùn)練成本。此前有專家估計(jì),GPT-3的訓(xùn)練使用了上萬(wàn)塊英偉達(dá)v100 GPU,總成本高達(dá)2760萬(wàn)美元,個(gè)人如果要訓(xùn)練出一個(gè)PaLM也要花費(fèi)900至1700萬(wàn)美元。大模型的訓(xùn)練成本若能降下來(lái),自然也就能提高他們的開(kāi)源意愿。
但歸根結(jié)底,這只能從工程上對(duì)算力資源的約束起到緩解作用,而并非終極方案。盡管目前許多千億級(jí)、萬(wàn)億級(jí)的大模型已經(jīng)開(kāi)始宣傳自己的「低能耗」優(yōu)勢(shì),但算力的圍墻仍然太高。
最終,我們還是要回到大模型自身尋找突破點(diǎn),一個(gè)十分被看好的方向便是稀疏動(dòng)態(tài)大模型。
稀疏大模型的特點(diǎn)是容量非常大,但只有用于給定任務(wù)、樣本或標(biāo)記的某些部分被激活。也就是說(shuō),這種稀疏動(dòng)態(tài)結(jié)構(gòu)能夠讓大模型在參數(shù)量上再躍升幾個(gè)層級(jí),同時(shí)又不必付出巨大的計(jì)算代價(jià),一舉兩得。這與GPT-3這樣的稠密大模型相比有著極大的優(yōu)勢(shì),后者需要激活整個(gè)神經(jīng)網(wǎng)絡(luò)才能完成即使是最簡(jiǎn)單的任務(wù),資源浪費(fèi)巨大。
谷歌是稀疏動(dòng)態(tài)結(jié)構(gòu)的先行者,他們于2017年首次提出了MoE(Sparsely-Gated Mixture-of-Experts Layer,稀疏門(mén)控的專家混合層),去年推出的1.6萬(wàn)億參數(shù)大模型Switch Transformers就融合了MoE風(fēng)格的架構(gòu),訓(xùn)練效率與他們之前的稠密模型T5-Base Transformer相比提升了7倍。
而今年的PaLM所基于的Pathways統(tǒng)一架構(gòu),更是稀疏動(dòng)態(tài)結(jié)構(gòu)的典范:模型能夠動(dòng)態(tài)地學(xué)習(xí)網(wǎng)絡(luò)中的特定部分擅長(zhǎng)何種任務(wù),我們根據(jù)需要調(diào)用經(jīng)過(guò)網(wǎng)絡(luò)的小路徑即可,而無(wú)需激活整個(gè)神經(jīng)網(wǎng)絡(luò)才能完成一項(xiàng)任務(wù)。
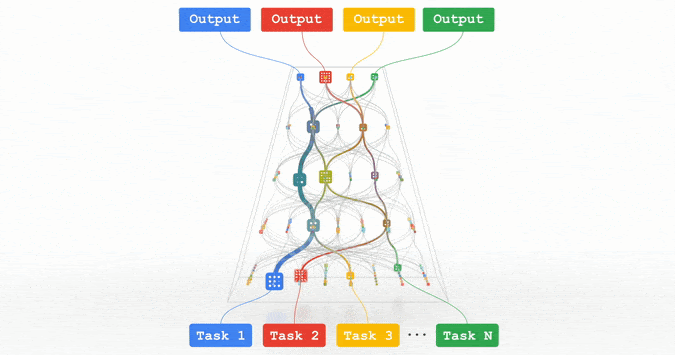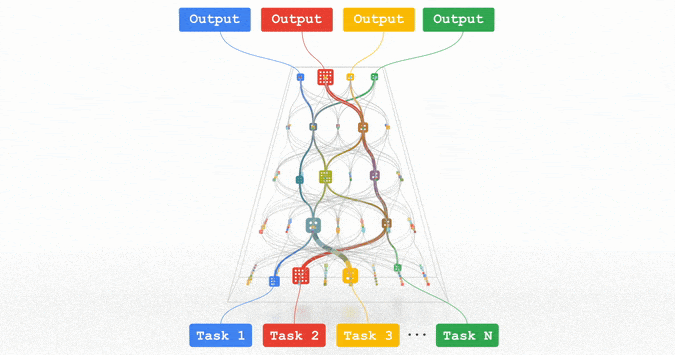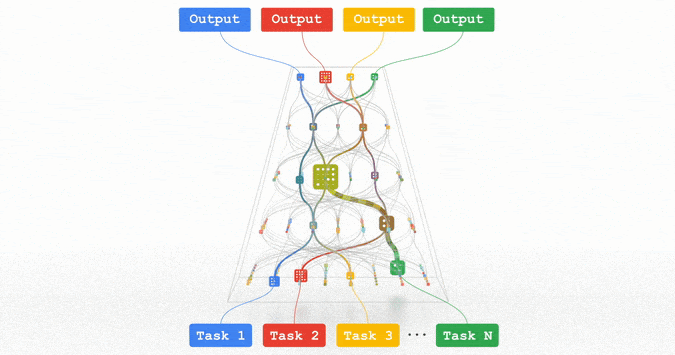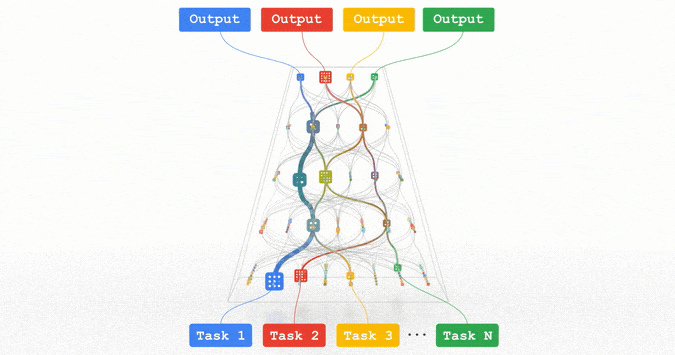
圖注:Pathways架構(gòu)
這本質(zhì)上與人腦的運(yùn)作方式類似,人腦中有百億個(gè)神經(jīng)元,但在執(zhí)行特定任務(wù)中只激活特定功能的神經(jīng)元,否則巨大的能耗是人難以承受的。
大、通用,且高效,這種大模型路線無(wú)疑具有很強(qiáng)的吸引力。
「以后有了稀疏動(dòng)態(tài)的加持,計(jì)算代價(jià)就不會(huì)那么大,但是模型參數(shù)一定會(huì)越來(lái)越大,稀疏動(dòng)態(tài)結(jié)構(gòu)或許會(huì)為大模型打開(kāi)一個(gè)新天地,再往十萬(wàn)億、百萬(wàn)億走也沒(méi)問(wèn)題。」張家興相信,稀疏動(dòng)態(tài)結(jié)構(gòu)將是解決大模型尺寸與算力代價(jià)之間矛盾的最終途徑。但他也補(bǔ)充說(shuō),在當(dāng)下這種模型結(jié)構(gòu)還未普及的情況下,再盲目將模型繼續(xù)做大確實(shí)意義不大。
目前國(guó)內(nèi)在這個(gè)方向上的嘗試還比較少,且不如谷歌做得更徹底。大模型結(jié)構(gòu)上的探索創(chuàng)新與開(kāi)源相互促進(jìn),我們需要更多開(kāi)源來(lái)激發(fā)大模型技術(shù)的變革。
阻礙大模型開(kāi)源的,除了大模型的算力成本導(dǎo)致的低可用性,還有安全問(wèn)題。
對(duì)于大模型尤其是生成大模型開(kāi)源后帶來(lái)的濫用風(fēng)險(xiǎn),國(guó)外擔(dān)憂的聲音似乎更多,爭(zhēng)議也不少,這成了許多機(jī)構(gòu)選擇不開(kāi)源大模型的憑據(jù),但或許也是他們拒絕慷慨的一個(gè)借口。
OpenAI已經(jīng)因此招致了許多批評(píng)。他們?cè)?019年發(fā)布GPT-2時(shí)就聲稱,模型的文本生成能力過(guò)于強(qiáng)大,可能會(huì)帶來(lái)倫理方面的危害,因而不適合開(kāi)源。一年后公開(kāi)GPT-3時(shí)也僅僅提供了API試用,目前GPT-3的開(kāi)源版本實(shí)際上是由開(kāi)源社區(qū)自行復(fù)現(xiàn)的。
事實(shí)上,對(duì)大模型的訪問(wèn)限制反而會(huì)不利于大模型提高穩(wěn)健性、減少偏見(jiàn)和毒性。Meta AI的負(fù)責(zé)人Joelle Pineau在談到開(kāi)源OPT的決定時(shí),曾誠(chéng)懇地表示,單靠自家團(tuán)隊(duì)解決不了全部問(wèn)題,比如文本生成過(guò)程中可能產(chǎn)生的倫理偏見(jiàn)和惡意詞句。他們認(rèn)為,如果做足功課,就可以在負(fù)責(zé)任的情況下讓大模型變得可以公開(kāi)訪問(wèn)。
在防范濫用風(fēng)險(xiǎn)的同時(shí)保持開(kāi)放獲取和足夠的透明度,這并非易事。作為打開(kāi)了「潘多拉魔盒」的人,Stability AI享受了主動(dòng)開(kāi)源帶來(lái)的好名聲,但最近也遭遇了開(kāi)源帶來(lái)的反噬,在版權(quán)歸屬等方面引起了爭(zhēng)議。
開(kāi)源背后的「自由與安全」這一古老的辯證命題由來(lái)已久,或許并沒(méi)有一個(gè)絕對(duì)正確的答案,但是在大模型開(kāi)始走向落地的當(dāng)下,一個(gè)清楚的事實(shí)是:大模型開(kāi)源,我們做得還遠(yuǎn)遠(yuǎn)不夠。
兩年多過(guò)去,我們已經(jīng)擁有了自己的萬(wàn)億級(jí)別大模型,在接下來(lái)大模型從「讀萬(wàn)卷書(shū)」到「行萬(wàn)里路」的轉(zhuǎn)變過(guò)程中,開(kāi)源是一個(gè)必然的選擇。
最近,GPT-4正呼之欲出,所有人都對(duì)它能力上的飛躍抱著極大的期待,但我們不知道,未來(lái)它能給多少人釋放多大的生產(chǎn)力?
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
31155瀏覽量
269493 -
模型
+關(guān)注
關(guān)注
1文章
3268瀏覽量
48927 -
大模型
+關(guān)注
關(guān)注
2文章
2491瀏覽量
2871
原文標(biāo)題:AI 大模型開(kāi)源之困:壟斷、圍墻與算力之殤
文章出處:【微信號(hào):信息與電子工程前沿FITEE,微信公眾號(hào):信息與電子工程前沿FITEE】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
浪潮信息與智源研究院攜手共建大模型多元算力生態(tài)
企業(yè)AI算力租賃模式的好處
開(kāi)源AI模型庫(kù)是干嘛的
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
企業(yè)AI算力租賃是什么
AI時(shí)代算力的重要性及現(xiàn)狀:平衡發(fā)展與優(yōu)化配置的挑戰(zhàn)
中國(guó)智能汽車騰飛,為什么異構(gòu)算力是第一生產(chǎn)力?

淺析三大算力之異同

大模型時(shí)代的算力需求
科華數(shù)據(jù)攜手希姆計(jì)算,推動(dòng)國(guó)產(chǎn)RISC-V開(kāi)源AI算力快速發(fā)展

科華數(shù)據(jù)攜手希姆計(jì)算,推動(dòng)國(guó)產(chǎn)RISC-V開(kāi)源AI算力快速發(fā)展

摩爾線程張建中:以國(guó)產(chǎn)算力助力數(shù)智世界,滿足大模型算力需求
數(shù)據(jù)語(yǔ)料庫(kù)、算法框架和算力芯片在AI大模型中的作用和影響
智能算力規(guī)模超通用算力,大模型對(duì)智能算力提出高要求
立足算力,聚焦AI!順網(wǎng)科技全面走進(jìn)AI智算時(shí)代






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論