 用于NAT的選擇性知識蒸餾框架
用于NAT的選擇性知識蒸餾框架
01
研究動機
在本文中,我們研究了一種能夠高效推理的機器翻譯模型NAT (Non-Autoregressive Transformer)[1]。相較于傳統的Transformer,NAT能夠在解碼階段并行預測,從而大幅提升模型的推理速度。此外,NAT可以使得模型在訓練和測試階段從相同的分布進行預測,從而有效避免了順序解碼模型中經常出現的exposure bias問題。在WMT21 news translation shared task for German→English translation中,已經有NAT模型在翻譯質量上超過了許多順序解碼的模型。
盡管NAT在擁有許多潛在的優勢,目前的工作中這類模型仍然在很大程度上依賴于句子級別的知識蒸餾(sequence-level knowledge distillation, KD)[2]。由于需要并行預測所有token,NAT對單詞間依賴關系的建模能力較弱。這個特點使得在真實數據集上,NAT很容易受到multi-modality問題的影響:訓練數據中一個輸入可能對應多個不同的輸出。在這樣的背景下,Gu提出訓練一個AT (Autoregressive Transformer)[3]模型作為老師,將它的輸出作為NAT的學習對象。這種KD方式可以幫助NAT繞過multi-modality問題,從而大幅提升NAT的翻譯表現。
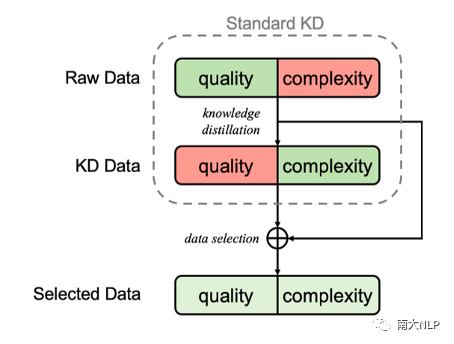
圖1:Selective KD的流程示意圖
KD在幫助NAT提升表現的同時,也會帶來一些負面影響,例如模型在低頻詞上的準確率較低[4]、AT teacher的錯誤會傳播到NAT上等。此外,如果NAT僅能在AT teacher的輸出上學習,這類模型的翻譯質量將很難有更進一步的突破。我們的研究希望能夠在避免multi-modality的情況下,讓NAT能夠從真實的數據分布中學到知識蒸餾的過程中缺失的信息,從而提升NAT的表現。
為達到這樣的目的,我們提出了selective KD:在KD數據上訓練一個NAT作為評估模型,并通過它來選擇需要蒸餾的句子。通過這種方式,我們可以讓模型接觸到翻譯質量更高的真實數據,同時避免了嚴重的multi-modality情況。受課程學習的影響,我們也在訓練過程中動態調整蒸餾數據的比例。“用評估模型有選擇地蒸餾數據”和“動態調節蒸餾數據的比例”共同構成了我們的Selective KD訓練框架。
02
解決方案
2.1評估模型
我們首先將數據蒸餾產生的結果劃分為四種不同的情況:
較輕的modality change:某些單詞可能被替換為同義詞,句式和語義并沒有發生顯著的變化
較輕的錯誤:在保持原有句式和語義的情況下,發生了一些小錯誤,例如單詞重復
嚴重的modality change:語義不變的情況下,句子的表達方式發生了顯著的變化
嚴重的錯誤:翻譯的質量很糟糕
對于情況1,我們可以容忍較輕的modality change,這種情況下真實數據和蒸餾數據都可以被視作正確的學習目標,同時引入真實數據不會大幅增加數據集的復雜程度。情況2中,用真實數據替換蒸餾數據可以得到更高的翻譯質量,找出屬于這種情況的樣本是我們方法的主要目標。情況3中,由于引入真實數據會惡化multi-modality問題,我們希望蒸餾這部分數據。情況4很少發生,我們認為這種情況下該訓練樣本對NAT可能太過困難,引入真實數據帶來的提升很有限。總的來說,我們希望能找到情況1、2對應的訓練樣本,在訓練過程中將它們的原始數據作為學習對象。

圖2:4種不同的情況對應的案例
為了篩選情況1、2中的數據,我們在蒸餾數據上訓練一個NAT作為評估模型,通過比較評估模型的輸出和真實數據計算一個score,判斷一個真實翻譯是否適合被直接用于訓練。若對于某個樣本評估模型的輸出和真實數據較為接近,則score較高,我們可以認為蒸餾數據僅有微小的錯誤或modality change,從而認為它屬于情況1、2,無需蒸餾。反之,可以認為蒸餾數據發生了較大的變化,因此屬于情況3、4,或是這個樣本在蒸餾后不發生太大變化的情況下對NAT而言仍過于困難。經過篩選,我們僅蒸餾那些不適合用于訓練的真實數據。
2.2動態調整蒸餾比例:由困難到容易
我們在訓練過程中會調整蒸餾數據的比例。一般來說,剛開始訓練時絕大多數訓練樣本為真實數據,訓練的尾聲則會蒸餾整個訓練集。具體實現中,我們通過動態調節score的閾值來調整蒸餾的比例。

圖3:selective KD在第k次update的算法示意
03
實驗
我們在WMT14 EN-DE和WMT16 EN-RO上開展了實驗,包括了兩種代表性的NAT架構:CMLM [5]和GLAT+CTC [6],以及一種inference-efficient的AT架構:DeepShallow [7](6層編碼器,1層解碼器)。
3.1翻譯質量與推理速度
我們通過BLEU score [8]和一種learned metric COMET [9]來衡量模型的翻譯質量,并通過和標準Transformer比較來衡量推理速度。可以發現,相比于常規的知識蒸餾,Selective KD可以在不同數據集、不同架構以及不同metric上穩定取得翻譯質量的提升,同時保持模型自身在推理速度上的優勢。我們方法在inference-efficient AT上也有明顯的效果,這進一步說明了selective KD具有廣泛的價值。
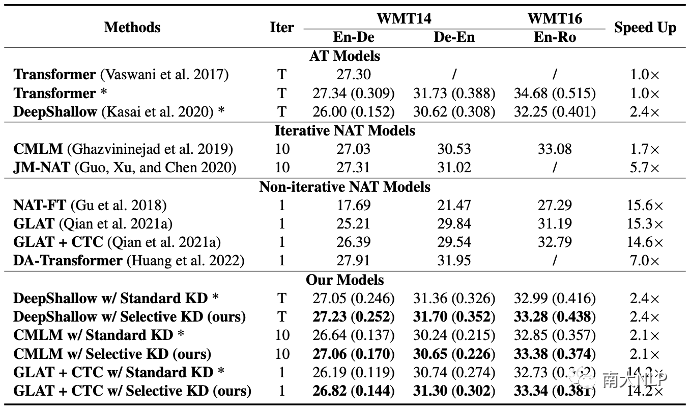
圖4:翻譯質量與推理速度。翻譯質量括號外為BLEU,括號內為COMET
3.2調節quality和complexity
真實數據的翻譯質量往往是優于蒸餾數據的,通過調節蒸餾數據的比例,Selective KD可以調節訓練集的quality。與此同時,我們希望知道這個方法是否可以靈活調節訓練集的complexity。為了更好地觀察這一點,文章中用了兩個metric來衡量數據的復雜程度:Translatioin Uncertainty [10]和Alignment Shift。Translation Uncertainty反映了源句單詞對應翻譯結果的多樣性,Alignment Shift反映了句式的變化程度。
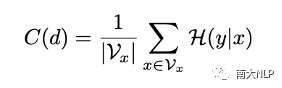
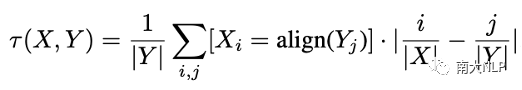
圖5:Translation Uncertainty(左)和Alignment Shift(右)的計算方式
如圖6所示,我們的方法可以有效控制數據的complexity。我們保留的真實數據(綠色折線)在兩個指標上都遠遠低于被蒸餾的真實數據(紅色折線)。在增加真實數據的比例同時,整個數據集complexity的提升是緩慢而平滑的。
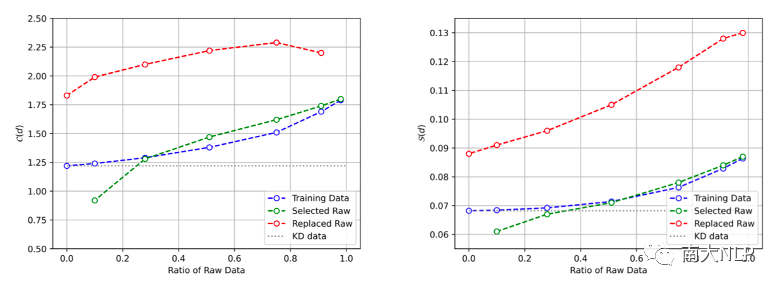
圖6:數據的Translation Uncertainty(左)和Alignment Shift(右)
3.3蒸餾數據占比的影響
如圖7所示,我們在不同蒸餾比例的數據上進行了實驗。可以發現,通過selective KD僅蒸餾5%的數據就可以提升2.4 BLEU。在蒸餾數據比例為80%時,模型的表現甚至超過了完全蒸餾的數據,根據[10],一種可能的解釋是這種比例下數據的complexity更適合我們實驗中采用的GLAT+CTC架構。另外,動態調節真實數據的比例(藍色虛線)可以進一步提升模型的表現。
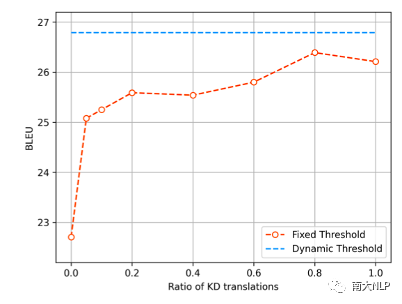
圖7:在不同蒸餾比例下模型的表現
04
總結
在這篇文章中,我們提出了選擇性知識蒸餾,從而使得NAT模型可以從真實的數據分布中學到知識蒸餾過程中缺失的部分信息。具體來說,我們采用一個NAT作為評估模型來判斷哪些句子需要蒸餾,并動態提高蒸餾數據的比例。我們用實驗結果證明了該方法可以有效提升NAT在機器翻譯任務上的表現。
審核編輯 :李倩
-
NAT
+關注
關注
0文章
148瀏覽量
16365 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14987 -
數據集
+關注
關注
4文章
1212瀏覽量
24964
原文標題:AAAI'23 | 用于NAT的選擇性知識蒸餾框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大連理工提出基于Wasserstein距離(WD)的知識蒸餾方法
奔騰NAT造型獲國家知識產權局“中國外觀設計銀獎”
SiGe與Si選擇性刻蝕技術
選擇性沉積技術介紹
基于介電電泳的選擇性液滴萃取微流體裝置用于單細胞分析
Nat server技術原理和配置過程
過電流保護的選擇性是靠什么來實現的

NAT技術及其應用





 工商網監
工商網監
評論