


背景
目前,日志異常檢測算法采用基于時(shí)間序列的方法檢測異常,具體為:日志結(jié)構(gòu)化 -> 日志模式識(shí)別 -> 時(shí)間序列轉(zhuǎn)換 -> 異常檢測。異常檢測算法根據(jù)日志指標(biāo)時(shí)序數(shù)據(jù)的周期性檢測出歷史新增、時(shí)段新增、時(shí)段突增、時(shí)段突降等多種異常。 然而,在實(shí)際中,日志指標(biāo)時(shí)序數(shù)據(jù)并不都具有周期性,或具有其他分布特征,因此僅根據(jù)周期性進(jìn)行異常檢測會(huì)導(dǎo)致誤報(bào)率高、準(zhǔn)確率低等問題。因此如果在日志異常檢測之前,首先對(duì)日志指標(biāo)時(shí)序數(shù)據(jù)進(jìn)行分類,不同類型數(shù)據(jù)采用不同方法檢測異常,可以有效提高準(zhǔn)確率,并降低誤報(bào)率。
日志指標(biāo)序列的類型
日志指標(biāo)序列分為時(shí)序數(shù)據(jù)與日志指標(biāo)數(shù)據(jù)兩大類:
時(shí)序數(shù)據(jù):包含平穩(wěn)型、周期型、趨勢(shì)型、階躍型。
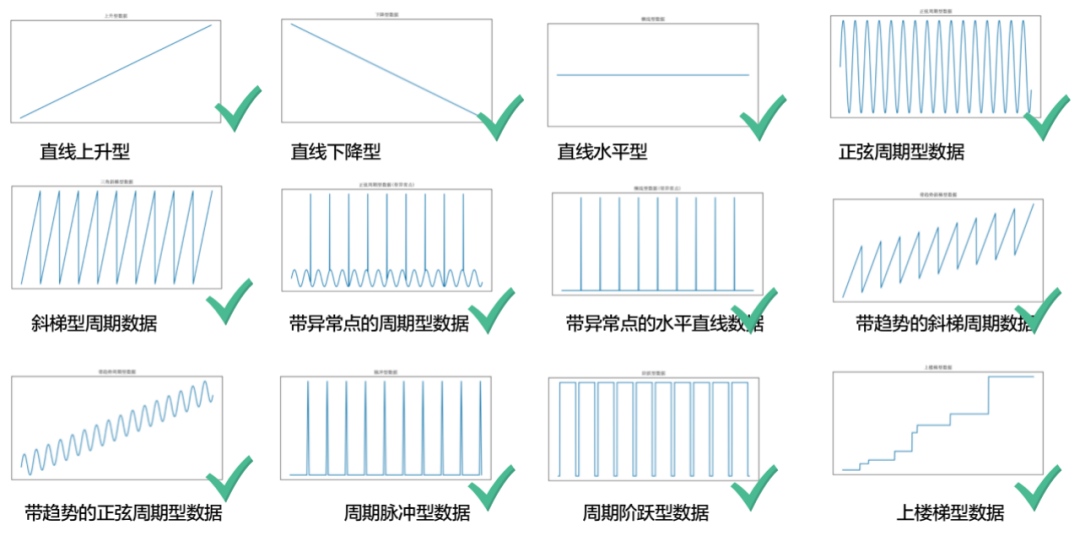
日志指標(biāo)數(shù)據(jù):包含周期型、非周期型。
時(shí)間序列分類算法
時(shí)間序列分類是一項(xiàng)在多個(gè)領(lǐng)域均有應(yīng)用的通用任務(wù),目標(biāo)是利用標(biāo)記好的訓(xùn)練數(shù)據(jù),確定一個(gè)時(shí)間序列屬于預(yù)先定義的哪一個(gè)類別。時(shí)間序列分類不同于常規(guī)分類問題,因?yàn)闀r(shí)序數(shù)據(jù)是具有順序?qū)傩缘男蛄小?時(shí)間序列分為傳統(tǒng)時(shí)間序列分類算法與基于深度學(xué)習(xí)的時(shí)間序列分類算法。傳統(tǒng)方法又根據(jù)算法采用的用于分類的特征類型不同,分為全局特征、局部特征、基于模型以及組合方法 4 大類。基于深度學(xué)習(xí)的時(shí)間序列算法分為生成式模型與判別式模型兩大類。本文主要對(duì)傳統(tǒng)時(shí)間序列分類算法進(jìn)行介紹。
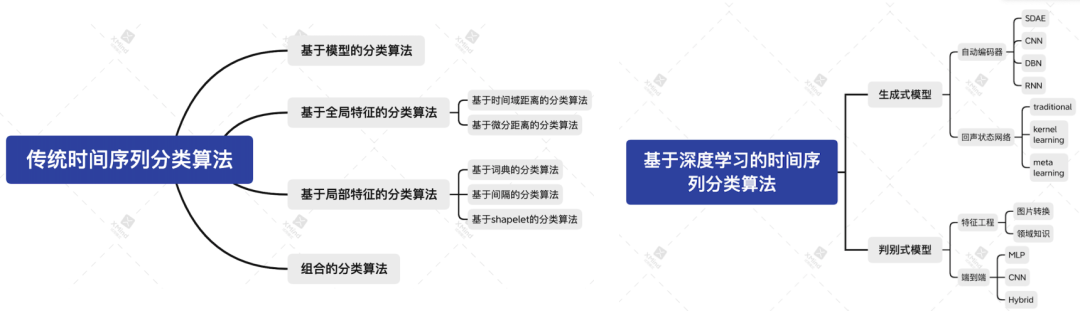
傳統(tǒng)時(shí)間序列分類算法
基于全局特征的分類算法
全局特征分類是將完整時(shí)間序列作為特征,計(jì)算時(shí)間序列間的相似性來進(jìn)行分類。分類方法有通過計(jì)算不同序列之間距離的遠(yuǎn)近來表達(dá)時(shí)間序列的相似性以及不同距離度量方法 + 1-NN(1 - 近鄰)。主要研究序列相似性的度量方法。
時(shí)間域距離
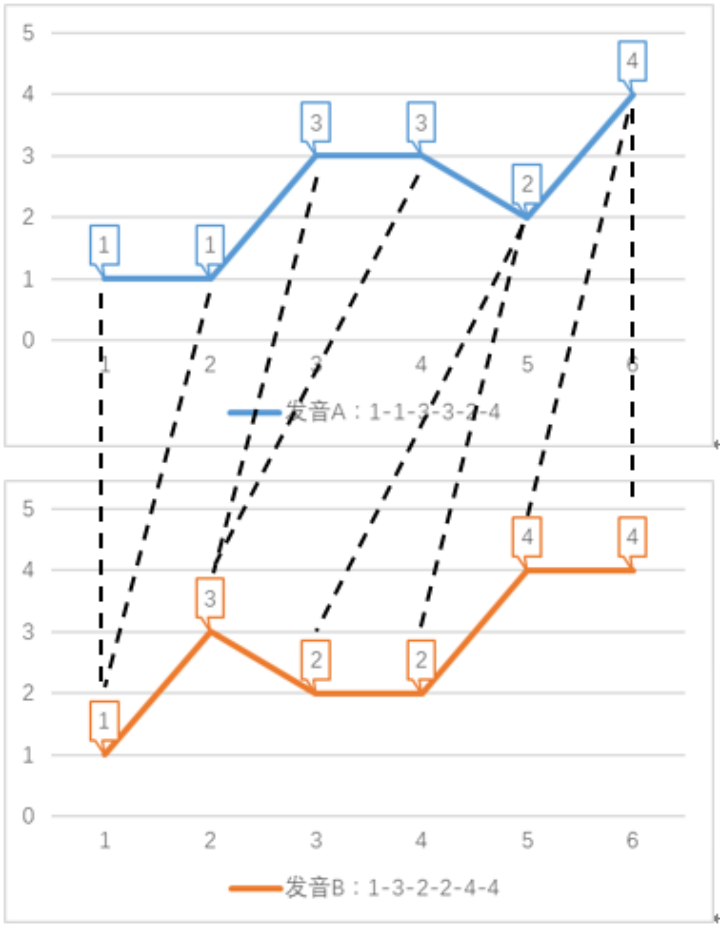
問題場景描述: 如下圖所示,問題場景是一個(gè)語音識(shí)別任務(wù)。該任務(wù)用數(shù)字表示音調(diào)高低,例如某個(gè)單詞發(fā)音的音調(diào)為 1-3-2-4。兩個(gè)人說同一單詞時(shí),因?yàn)橐艄?jié)的發(fā)音拖長,會(huì)形成不同的發(fā)音序列 前半部分拖長,發(fā)音:1-1-3-3-2-4 后半部分拖長,發(fā)音:1-3-2-2-4-4 在采用傳統(tǒng)歐式距離,即點(diǎn)對(duì)點(diǎn)的方式計(jì)算發(fā)音序列距離時(shí),距離之和如下:歐式距離 = |A (1)-B (1)| + |A (2)-B (2)| + |A (3)-B (3)| + |A (4)-B (4)| + |A (5)-B (5)| + |A (6)-B (6)| =6_x0001_
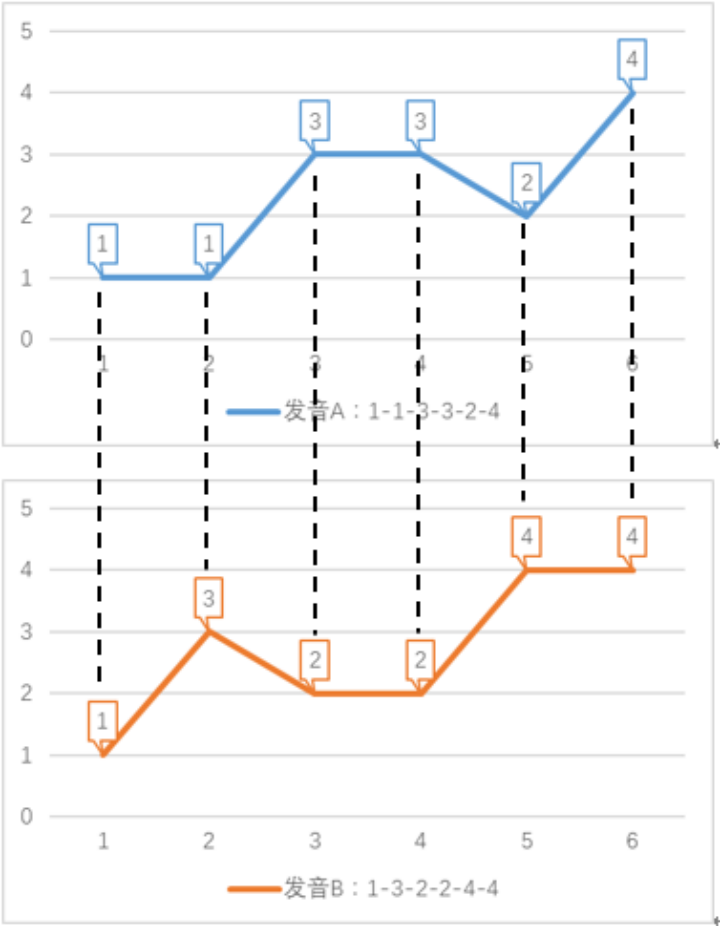
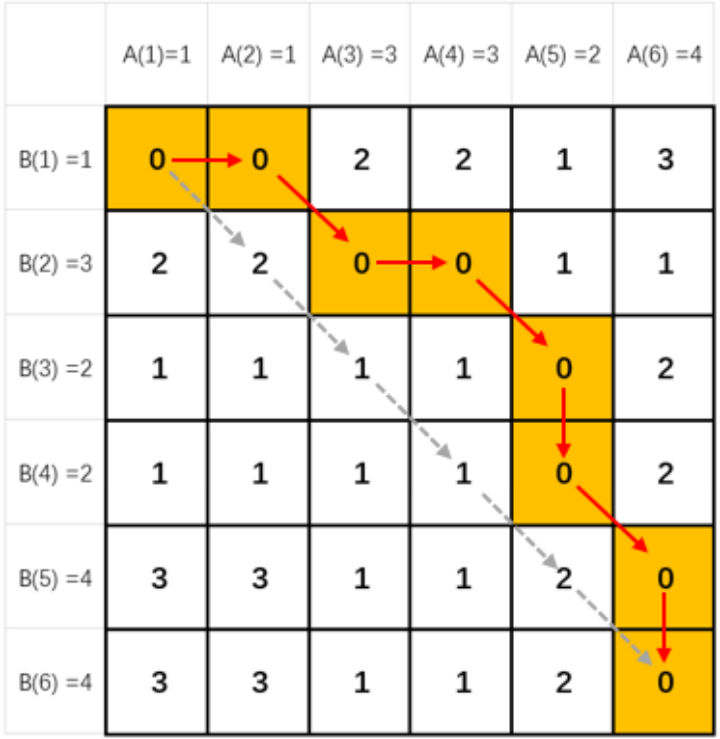
算法原理: 如果我們?cè)试S序列的點(diǎn)與另一序列的多個(gè)連續(xù)的點(diǎn)相對(duì)應(yīng)(即,將這個(gè)點(diǎn)所代表的音調(diào)的發(fā)音時(shí)間延長),然后再計(jì)算對(duì)應(yīng)點(diǎn)之間的距離之和,這就是 dtw 算法。dtw 算法允許序列某個(gè)時(shí)刻的點(diǎn)與另一序列多個(gè)連續(xù)時(shí)刻的點(diǎn)相對(duì)應(yīng),稱為時(shí)間規(guī)整(Time Warping)。如下圖所示,語音識(shí)別任務(wù)的 dtw 距離如下: dtw 距離 = |1-1| + |1-1| + |3-3| + |3-3| + |2-2| + |2-2| + |4-4| + |4-4| = 0 dtw 計(jì)算出的距離為 0,由此代表兩個(gè)單詞發(fā)音一致,與實(shí)際情況相符。
算法實(shí)現(xiàn): dtw 算法實(shí)現(xiàn)包括計(jì)算兩個(gè)序列各點(diǎn)之間距離構(gòu)成矩陣以及尋找一條從矩陣左上角到右下角的路徑,使得路徑上的元素和最小兩個(gè)主要步驟。距離矩陣如下圖所示,矩陣中每個(gè)元素的值為兩個(gè)序列對(duì)應(yīng)點(diǎn)之間的距離。DTW 算法將計(jì)算兩個(gè)序列之間的距離,轉(zhuǎn)化為尋找一條從距離矩陣。左上角到右下角的路徑,使得路徑上的元素和最小。實(shí)現(xiàn)要點(diǎn)如下:
轉(zhuǎn)化為動(dòng)態(tài)規(guī)劃的問題(DP);
由于尋找所有路徑太耗時(shí),需要添加路徑數(shù)量限制條件(可以等效為尋找矩陣橫縱坐標(biāo)的差的允許范圍,即 warping window)。
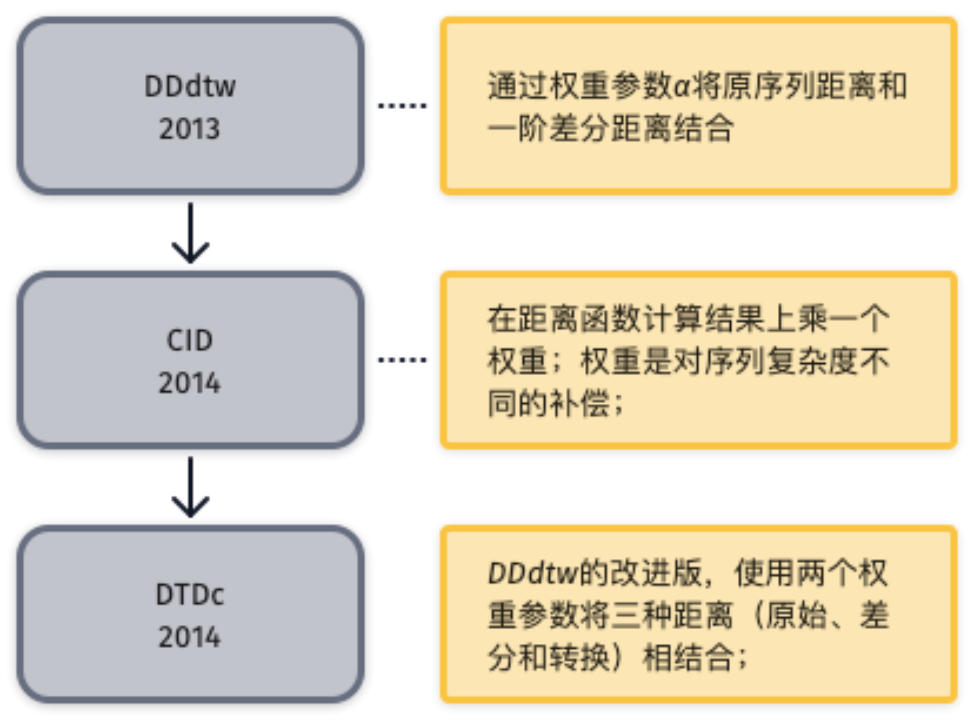
差分距離法
差分距離法是計(jì)算原始時(shí)間序列的一階微分,然后度量兩個(gè)時(shí)間序列的微分序列的距離,即微分距離。差分法將微分距離作為原始序列距離的補(bǔ)充,是最終距離計(jì)算函數(shù)的重要組成部分。 對(duì)于一個(gè)時(shí)間序列 t=(t1, t2, …,tm),其一階微分計(jì)算公式如(2-1)所示,二階微分計(jì)算公式如(2-2)所示,更高階的微分計(jì)算方式依次類推。差分距離法將位于時(shí)間域的原時(shí)間序列和位于差分域的一階差分序列相結(jié)合,提升分類效果。研究方向主要是如何將原序列和差分序列合理結(jié)合。
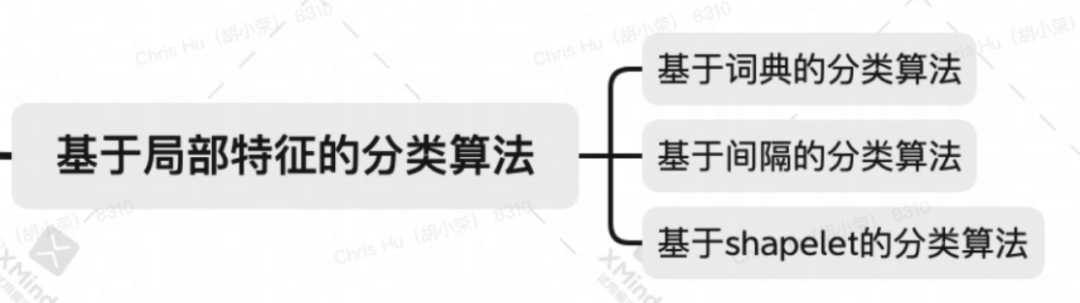
基于局部特征的分類算法
將單條時(shí)間序列中的一部分子序列作為特征,用于時(shí)間序列分類。主要有以下特點(diǎn):
關(guān)鍵在于尋找能夠區(qū)分不同類的局部特征;
由于子序列更短,因此構(gòu)建的分類器速度更快;
但由于需要尋找局部特征,需要一定的訓(xùn)練時(shí)間。
基于間隔(interval)的分類算法
基于間隔(interval)的分類算法分類方法是將時(shí)間序列劃分為幾個(gè)間隔,從每個(gè)間隔中提取特征。過程中需考慮以下關(guān)鍵問題:
需要找到最具有區(qū)分度特征的區(qū)間;
區(qū)間劃分方法很多,如果處理大量的候選區(qū)間;
如何在每個(gè)區(qū)間上合理提取特征。
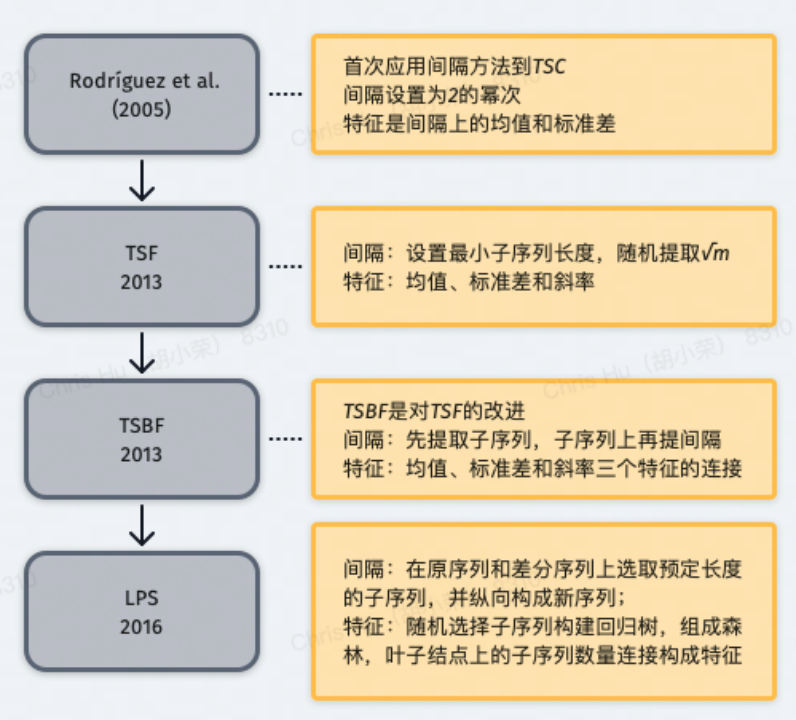
關(guān)鍵問題解決方法如下(TSF-Time Series Forest):
采用隨機(jī)森林的方法解決序列區(qū)間數(shù)量大的問題,采用統(tǒng)計(jì)值作為特征;
長度為 m 的序列,提取 sqrt (m) 個(gè)區(qū)間,每個(gè)區(qū)間上提取均值、標(biāo)準(zhǔn)差和斜率三個(gè)特征,共 3*sqrt (m) 個(gè)特征用于訓(xùn)練;
分類結(jié)果由集成的所有樹的多數(shù)投票決定;
基于 shapelets 的分類算法
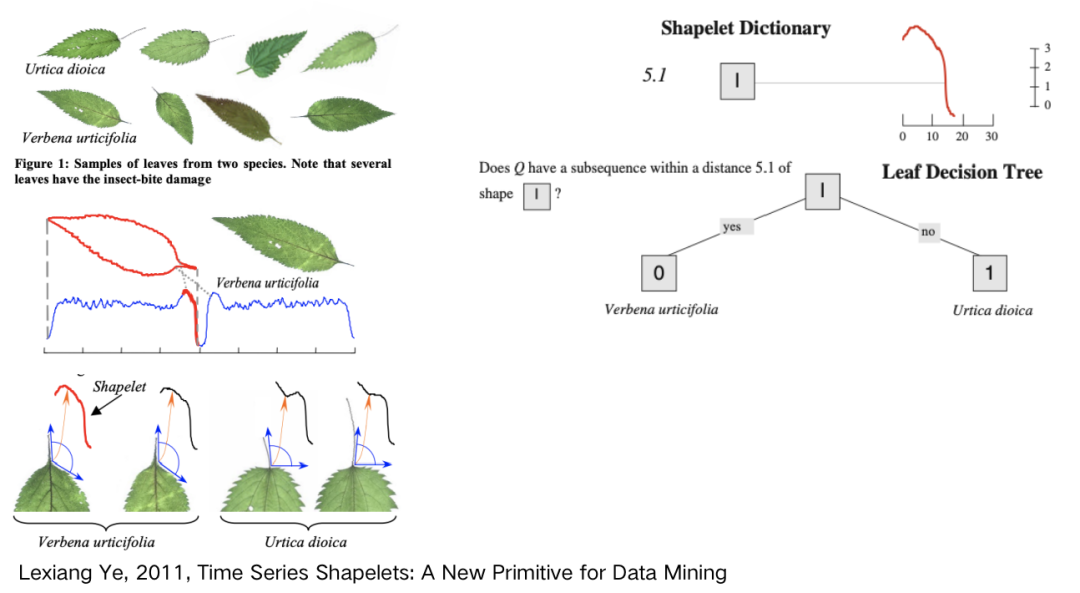
shapelet 分類算法通過在序列中查找最具辨別性的子序列用于分類,其中 shapelet 指一個(gè)與位置無關(guān)的最佳匹配子序列。該類算法適用于可以通過序列中的一種模式定義一個(gè)類,但是與模式的位置無關(guān)的分類問題。主要有以下兩個(gè)研究方向:
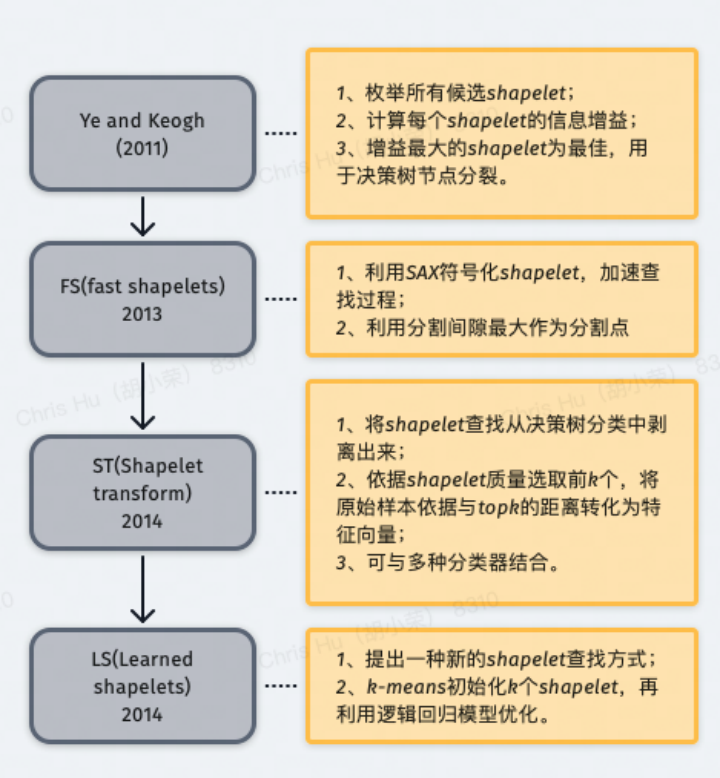
shapelet 尋找:枚舉所有可能的 shapelet,挑選最好的;
shapelet 用法:將 shapelet 用于決策樹的結(jié)點(diǎn)分裂準(zhǔn)則。
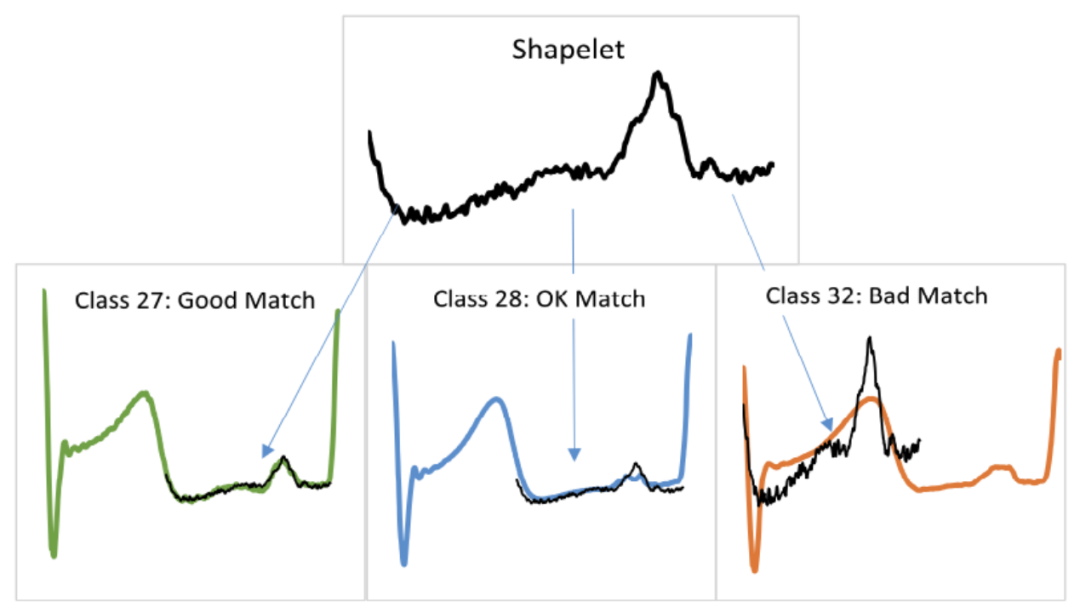
shapelet 分類算法通過在序列中查找最具辨別性的子序列用于分類,其中 shapelet 指一個(gè)與位置無關(guān)。
基于詞典的分類算法
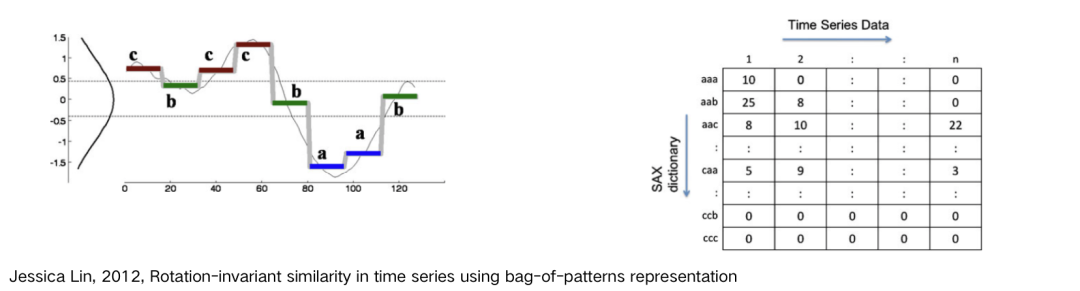
由于 shapelet 分類算法需要花費(fèi)大量時(shí)間搜索子序列,因此更適用于短序列。對(duì)于長序列,更適用于在高級(jí)結(jié)構(gòu)上衡量相似度。此外,shapelet 只使用一個(gè)最佳匹配進(jìn)行分類,無法解決區(qū)別在模式重復(fù)數(shù)量上的分類問題。因此,對(duì)于長序列中一種模式反復(fù)出現(xiàn)的時(shí)間序列,更適用于一種叫做 dict 詞典類的分類算法。 基于詞典的分類算法原理是以序列中的子序列的重復(fù)頻率作為特征進(jìn)行分類。首先對(duì)序列進(jìn)行降維和符號(hào)化表示,形成單詞序列,然后根據(jù)單詞序列中的單詞分布情況進(jìn)行分類。特點(diǎn)是通過給每個(gè)序列傳入一個(gè)長度為 w 的滑動(dòng)窗構(gòu)建單詞,每一個(gè)窗產(chǎn)生 l 個(gè)近似值,將每個(gè)值離散化,對(duì)應(yīng)到一個(gè)字母表中的符號(hào)。 BOP - Bag of Patterns 采用了類似 “bag of words” 的思路,將時(shí)間序列表示成一系列模式的向量。存在問題如下:
需要構(gòu)建 “模式詞匯表 -> SAX
時(shí)間序列沒有明顯分隔符進(jìn)行分割。- 滑動(dòng)窗口
操作步驟如下:
BOP 算法采用滑動(dòng)窗口在原始序列上取子序列;
再利用 SAX 方法將子序列轉(zhuǎn)化為單詞,并記錄每個(gè)單詞數(shù)量,所有的單詞匯總為詞匯表;
最后構(gòu)建 “單詞 - 句子” 向量矩陣,行是詞匯表,列是每個(gè)時(shí)間序列,點(diǎn)的值是詞匯在序列中的出現(xiàn)頻率。
_x0008_SAX (Symbolic Aggregate Approximation) 對(duì)序列進(jìn)行正則化,在橫軸方向,將時(shí)間序列等長劃分為 w 段,計(jì)算每一段的均值,并將 w 個(gè)系數(shù)聚集在一起,這個(gè)過程稱為分段聚集近似(Piecewise Aggregate Approximation,PAA)。 研究表明正則化的時(shí)間序列的子序列服從高斯分布,在縱軸方向,將均值從高斯分布等概率劃分為三塊區(qū)域,位于每個(gè)區(qū)域的系數(shù)分別用 a,b,c 表示,此時(shí)序列已轉(zhuǎn)化為字符串。
審核編輯:郭婷
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7257瀏覽量
91962 -
檢測算法
+關(guān)注
關(guān)注
0文章
122瀏覽量
25502
原文標(biāo)題:日志異常檢測準(zhǔn)確率低?一文掌握日志指標(biāo)序列分類
文章出處:【微信號(hào):OSC開源社區(qū),微信公眾號(hào):OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】全書概覽與時(shí)間序列概述
基于粒子群優(yōu)化算法的屬性異常檢測算法
多變量水質(zhì)參數(shù)時(shí)間異常事件檢測算法
密度偏倚抽樣的局部距離異常檢測算法
基于概率圖模型的時(shí)空異常事件檢測算法
基于角度方差的數(shù)據(jù)流異常檢測算法
機(jī)器學(xué)習(xí)算法概覽:異常檢測算法/常見算法/深度學(xué)習(xí)
基于時(shí)間卷積網(wǎng)絡(luò)的通用日志序列異常檢測框架

基于車輛軌跡特征的視頻異常事件檢測算法
一種多維時(shí)間序列汽車駕駛異常點(diǎn)檢測模型
基于離群點(diǎn)檢測算法的電力市場異常行為辨識(shí)
如何選擇異常檢測算法
智能電網(wǎng)時(shí)間序列異常檢測:a survey






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論