") 李昂:數(shù)據(jù)規(guī)模不是唯一標(biāo)準(zhǔn),數(shù)據(jù)純度更是重要考量
李昂:數(shù)據(jù)規(guī)模不是唯一標(biāo)準(zhǔn),數(shù)據(jù)純度更是重要考量
2022年11月29日,百度Apollo Day技術(shù)開放日活動(dòng)線上舉辦。百度自動(dòng)駕駛技術(shù)專家全景化展示Apollo技術(shù)實(shí)力及前沿技術(shù)理念。
隨著自動(dòng)駕駛的規(guī)模化落地,數(shù)據(jù)規(guī)模將出現(xiàn)爆發(fā)式增長。如何尋找更有價(jià)值的數(shù)據(jù),如何高效地利用數(shù)據(jù)提升駕駛能力,成為自動(dòng)駕駛持續(xù)學(xué)習(xí)和實(shí)現(xiàn)規(guī)模化的關(guān)鍵。百度自動(dòng)駕駛技術(shù)專家李昂提出了「高提純、高消化」的數(shù)據(jù)閉環(huán)設(shè)計(jì)理念,全面強(qiáng)化自動(dòng)駕駛的數(shù)據(jù)煉金術(shù)。據(jù)介紹,該方案的數(shù)據(jù)提純路徑利用車端小模型和云端大模型,實(shí)現(xiàn)高效率數(shù)據(jù)挖掘和自動(dòng)化標(biāo)注;數(shù)據(jù)消化架構(gòu)實(shí)現(xiàn)自動(dòng)化訓(xùn)練,具備聯(lián)合優(yōu)化和數(shù)據(jù)分布理解的能力,有效地利用高純度數(shù)據(jù)進(jìn)一步提升自動(dòng)駕駛系統(tǒng)的整體智能水平。
自動(dòng)駕駛是一個(gè)系統(tǒng)性工程,李昂本次關(guān)于數(shù)據(jù)閉環(huán)技術(shù)的分享,展現(xiàn)了百度在自動(dòng)駕駛方面進(jìn)行的是系統(tǒng)的技術(shù)創(chuàng)新:既關(guān)注常見的感知、決策、控制環(huán)節(jié),又在AI算法最關(guān)鍵的數(shù)據(jù)提純、標(biāo)注和模型訓(xùn)練環(huán)節(jié)進(jìn)行大膽創(chuàng)新,用新的技術(shù)思路和解題模式提升底層技術(shù)的支撐力,最終又反過來能促進(jìn)感知、決策等環(huán)節(jié)的發(fā)展。
清華大學(xué)交叉信息研究院助理教授
博士生導(dǎo)師趙行博士
以下為演講全文
大家好,我是李昂。我為大家?guī)戆俣華pollo對于自動(dòng)駕駛數(shù)據(jù)閉環(huán)的一些實(shí)踐與思考。
首先,自動(dòng)駕駛是一個(gè)持續(xù)學(xué)習(xí)的問題。無人車持續(xù)地在城市道路中行駛,會(huì)遇到各式各樣的新問題和很多意想不到的新場景。
根據(jù)這臺(tái)車端回傳的視頻可以發(fā)現(xiàn),其實(shí)在城市道路上遇到一群羊,排著隊(duì)橫穿馬路的情況,也不是完全沒有可能的。

而這些罕見的長尾場景,對于自動(dòng)駕駛來說是一個(gè)急需解決的問題,這也是自動(dòng)駕駛需要持續(xù)學(xué)習(xí)的一個(gè)重要原因。
當(dāng)無人車實(shí)現(xiàn)大規(guī)模的商業(yè)化落地,大量的無人車在道路上行駛,持續(xù)地去搜集海量的數(shù)據(jù)。
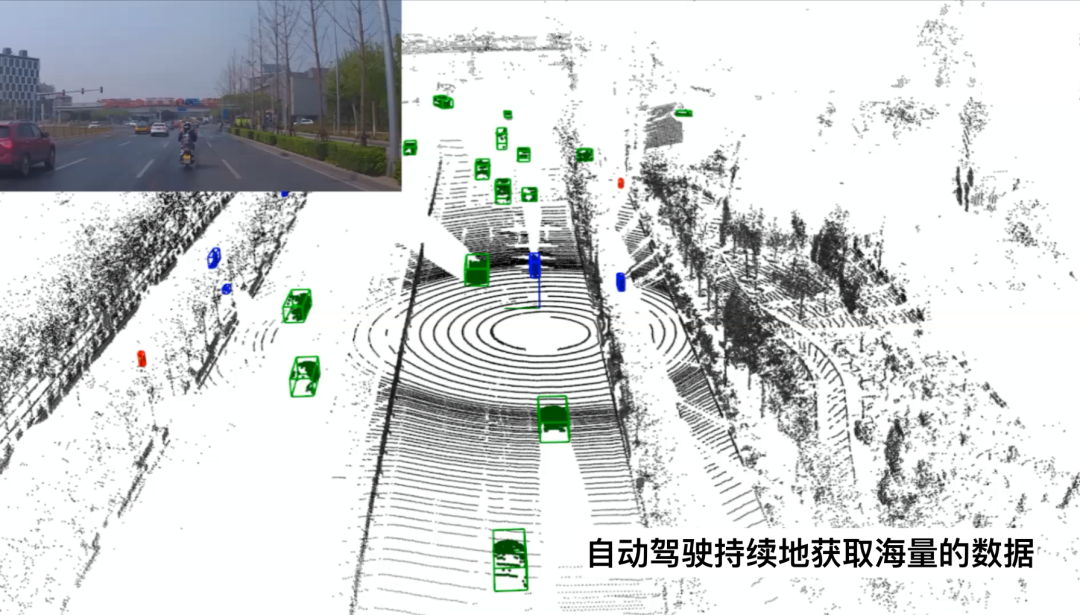
而對于我們的問題是,如何利用好這些大數(shù)據(jù),提升無人駕駛整體的安全性與舒適性,這就是數(shù)據(jù)閉環(huán)所需要考慮的一個(gè)核心問題。
百度認(rèn)為數(shù)據(jù)閉環(huán)是無人駕駛最終實(shí)現(xiàn)持續(xù)學(xué)習(xí)能力的重要基礎(chǔ)架構(gòu)。
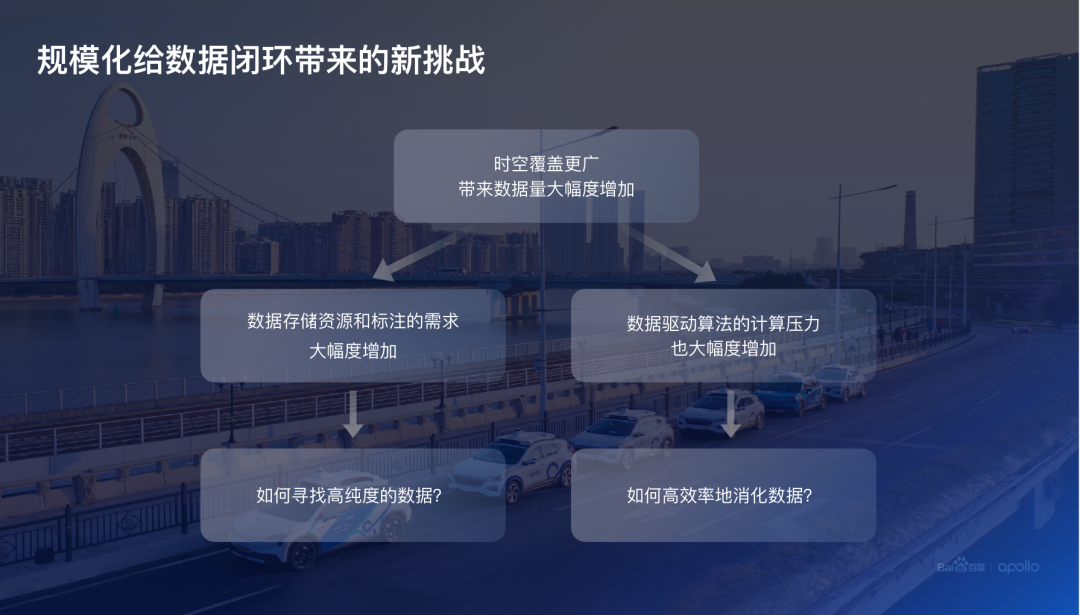
然而,大數(shù)據(jù)給自動(dòng)駕駛智能水平帶來巨大提升空間的同時(shí),大量的數(shù)據(jù)也給數(shù)據(jù)閉環(huán)建設(shè)帶來了全新挑戰(zhàn)。
一方面,大規(guī)模的數(shù)據(jù)帶來了數(shù)據(jù)存儲(chǔ)以及數(shù)據(jù)標(biāo)注的一個(gè)巨大壓力,全量落盤的模式不再是一個(gè)可以持續(xù)的方案。
另外一方面,數(shù)據(jù)閉環(huán)的目標(biāo)是利用數(shù)據(jù)提升無人駕駛整個(gè)的駕駛能力。在大規(guī)模數(shù)據(jù)的情況下,算法迭代所需要的計(jì)算量也隨之增加。我們將這兩個(gè)困難總結(jié)為兩個(gè)核心的問題:
首先,如何高效率地從海量的數(shù)據(jù)里找到高價(jià)值或者叫高純度的數(shù)據(jù)?
其次,如何利用好這些高純度的數(shù)據(jù),高效、高質(zhì)量地提升整體數(shù)據(jù)驅(qū)動(dòng)算法的整體智能水平?
我們從回答這兩個(gè)問題的角度出發(fā),設(shè)計(jì)了百度Apollo的數(shù)據(jù)閉環(huán)的整體設(shè)計(jì)思路。
首先,自動(dòng)駕駛系統(tǒng)是由車端和云端兩個(gè)部分組成的。而整個(gè)數(shù)據(jù)閉環(huán)是由數(shù)據(jù)提純以及數(shù)據(jù)消化這兩個(gè)部分構(gòu)成。
其中數(shù)據(jù)提純同時(shí)出現(xiàn)在車端和云端,它的目標(biāo)是找到高價(jià)值、高純度的數(shù)據(jù)。
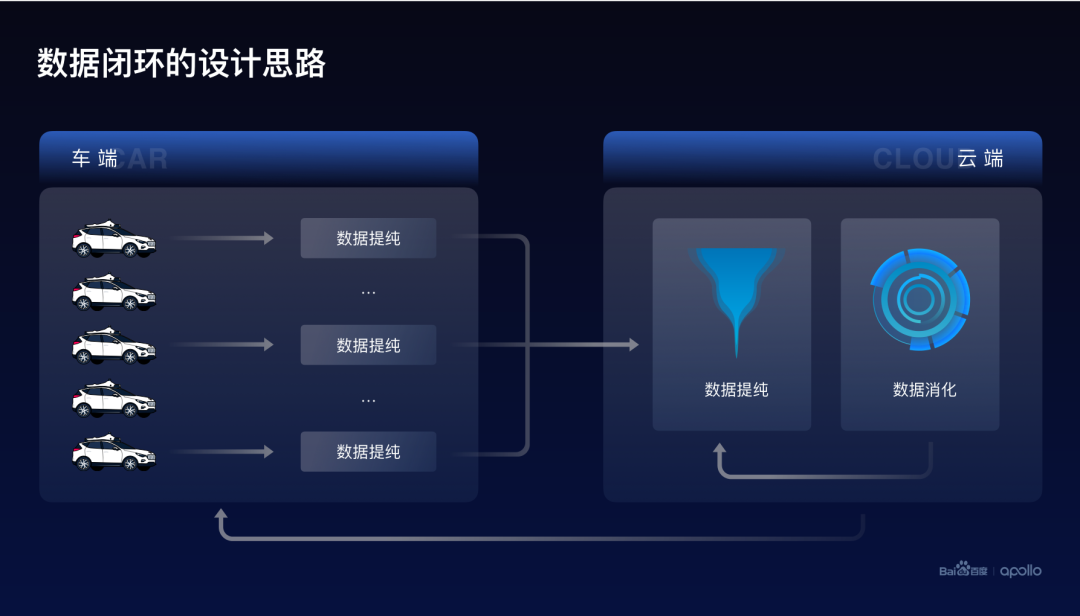
而數(shù)據(jù)消化部署在云端,它的目標(biāo)是利用高純度的數(shù)據(jù),提升自動(dòng)駕駛的整體的智能水平。
接下來,將從這兩個(gè)方面分別介紹百度關(guān)于數(shù)據(jù)閉環(huán)的高提純、高消化的設(shè)計(jì)思路。
首先,我們需要建設(shè)高效率數(shù)據(jù)提純的通路。

大規(guī)模的數(shù)據(jù)對于智能系統(tǒng)的幫助其實(shí)已經(jīng)是業(yè)界共識了,然而百度認(rèn)為數(shù)據(jù)的規(guī)模并不是唯一的標(biāo)準(zhǔn)。數(shù)據(jù)的純度也是一個(gè)重要的考量。這里定義數(shù)據(jù)的純度為,單位數(shù)據(jù)可以給整個(gè)智能系統(tǒng)提供的信息量。一個(gè)簡單的例子來看一看如何提高數(shù)據(jù)的純度。
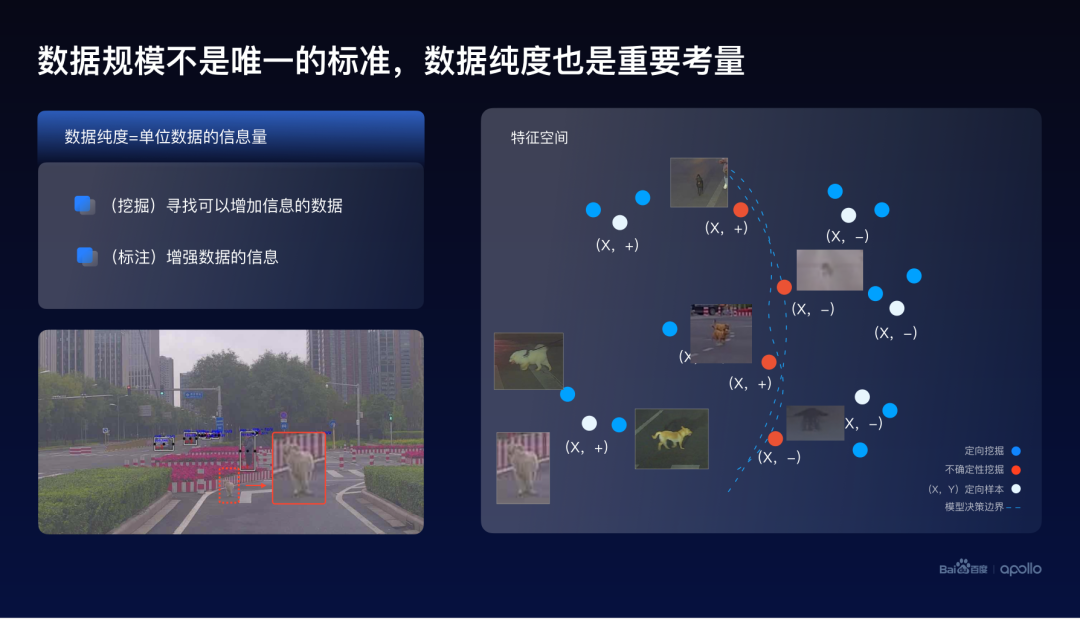
在左下角這個(gè)圖片中可以發(fā)現(xiàn),正前方有一只小狗,沒有被算法檢測到。我們稱這樣的數(shù)據(jù)為定向樣本。而在右邊的特征空間的表示中,用白色的圓圈來表示這樣的定向樣本。這里的正負(fù)號是這些樣本的標(biāo)注。
所以一個(gè)比較直接的想法就是嘗試去找與這只小狗類似的一個(gè)照片,而這些圖片大概率也會(huì)造成系統(tǒng)的漏檢。
這些圖片的搜索,可以通過比如最近鄰檢索的一些方式來實(shí)現(xiàn),在這個(gè)特征空間上我們用藍(lán)色的圓圈來表示。這種搜索類似樣本的一個(gè)數(shù)據(jù)挖掘的方式,把它叫做定向挖掘。
這里可以注意到,其實(shí)定向挖掘這個(gè)方法,并沒有使用到檢測模型的一些自身的信息。因而除了相似性,還可以從整個(gè)模型的角度來挖掘這個(gè)問題。
其實(shí)任何的模型都會(huì)有自己的決策邊界,在這張圖上使用虛線來表示。而出現(xiàn)在決策邊界上的數(shù)據(jù),往往是具有很大不確定性的。
因而,這些數(shù)據(jù)也會(huì)給模型帶來額外的信息。所以我們將找到這些數(shù)據(jù)的方式叫做不確定性挖掘。
可以注意到,在獲取這些不確定性數(shù)據(jù)的同時(shí),其實(shí)并沒有它們的標(biāo)簽。借助于人工或者自動(dòng)化標(biāo)注的一些方式,可以獲得這些標(biāo)簽。標(biāo)簽從某種程度上也可以認(rèn)為是數(shù)據(jù)的一種,并且可以帶來更多關(guān)于這些樣本的一些信息。當(dāng)獲得這些標(biāo)簽之后,就可以通過模型訓(xùn)練的方式,來改變模型的決策邊界。
所以簡單地總結(jié)一下,數(shù)據(jù)挖掘與標(biāo)注都是提高數(shù)據(jù)純度的一個(gè)重要手段。
根據(jù)這樣的思路,百度設(shè)計(jì)了自動(dòng)駕駛的數(shù)據(jù)提純通路。
從這張圖上可以看到,數(shù)據(jù)總是以數(shù)據(jù)流的形式不斷地進(jìn)入到這個(gè)系統(tǒng)里。而數(shù)據(jù)提純的一個(gè)核心組件是推理引擎,作用是對任意的一個(gè)給定的模型和一組數(shù)據(jù),給出這個(gè)模型在這組數(shù)據(jù)上的推理結(jié)果,這個(gè)結(jié)果可以包括數(shù)據(jù)的特征以及模型預(yù)測出的標(biāo)簽。

另外一個(gè)重要的組件是模型倉庫,這里包含了云端大模型、車端小模型,以及一些并沒有上車的一些候選小模型。
這里的大模型可以用來通過推理引擎獲取對應(yīng)數(shù)據(jù)的特征和標(biāo)簽。大模型的特征與向量檢索相結(jié)合,其實(shí)可以用作定向挖掘,大模型的標(biāo)簽可以用作自動(dòng)化標(biāo)注。
除了大模型以外,車上的小模型也可以用來做數(shù)據(jù)提純。小模型可以通過推理的方式獲取小模型的標(biāo)簽,注意,這里小模型的效果其實(shí)不如大模型,但由于小模型是實(shí)際在車上跑的模型,可以用這些標(biāo)簽來判斷哪些數(shù)據(jù)是目前的小模型無法準(zhǔn)確預(yù)測的數(shù)據(jù)。這也就是說這些數(shù)據(jù)其實(shí)是并沒有被模型消化的數(shù)據(jù)。在之后的訓(xùn)練過程當(dāng)中可以重點(diǎn)關(guān)注,提升在這些數(shù)據(jù)上的一些效果。
除此之外,多個(gè)小模型還可以利用比較經(jīng)典的,一個(gè)集成學(xué)習(xí)的不確定性估計(jì)的方法,獲得模型對數(shù)據(jù)的不確定性,從而實(shí)現(xiàn)不確定性挖掘。
所以通過推理引擎,實(shí)際上對所有數(shù)據(jù)的各種屬性進(jìn)行了推理,基于這些數(shù)據(jù)屬性,可以進(jìn)一步地提供復(fù)雜的挖掘規(guī)則,從而實(shí)現(xiàn)更為復(fù)雜和更有針對性的挖掘方式。
另外,從這個(gè)架構(gòu)上不難發(fā)現(xiàn),數(shù)據(jù)提純的效率很大的程度由推理引擎的效率決定。而推理引擎的效率又可以分為數(shù)據(jù)的讀取速度,以及模型的推理和計(jì)算速度。后者其實(shí)可以通過一些分布式的方式來提升,而前者主要可以通過文件系統(tǒng)的一些創(chuàng)新來進(jìn)行優(yōu)化。
這里我們與百度飛槳團(tuán)隊(duì)產(chǎn)生了緊密的合作,將百度自研的PaddleFlow數(shù)據(jù)緩存的基礎(chǔ)架構(gòu),集成進(jìn)入了數(shù)據(jù)閉環(huán)的平臺(tái),實(shí)現(xiàn)了推理引擎數(shù)據(jù)讀取效率的10倍以上的提升。

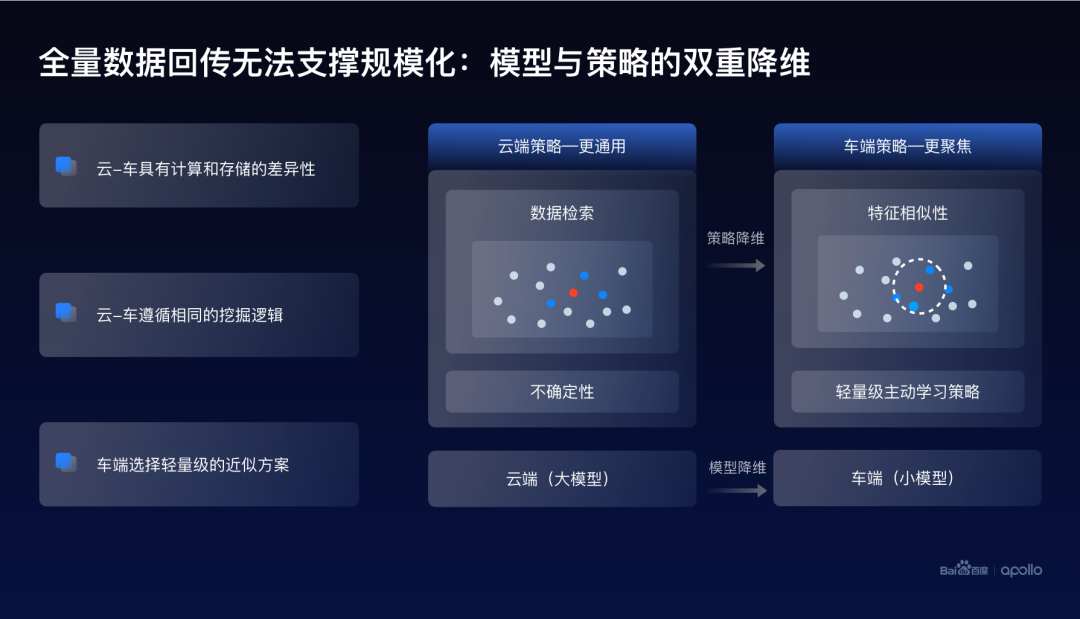
另外一方面,如果只有云端數(shù)據(jù)提純這樣的一個(gè)方式,是沒有辦法滿足大規(guī)模自動(dòng)駕駛的需求的。原因是在于存儲(chǔ)空間的上限其實(shí)是無法支持全量的數(shù)據(jù)回傳。
因而,在車端也需要部署數(shù)據(jù)提純的通路。云端和車端系統(tǒng)的主要區(qū)別在于它的存儲(chǔ)和計(jì)算能力的不同。很多云端可以執(zhí)行的操作,在車端變得難以實(shí)現(xiàn),比如說集成學(xué)習(xí)的一些方式。
因而,我們在設(shè)計(jì)車端挖掘方案的時(shí)候,雖然依舊遵循相同的原則和底層邏輯,但更多是采用一些輕量級的策略。比如云端基于大模型的挖掘方式,在車端是沒有辦法實(shí)現(xiàn)的,所以車端會(huì)改用小模型的特征提取。
最終簡單地總結(jié)一下,數(shù)據(jù)提純的呈現(xiàn)方式,實(shí)際上是云端到車端的一個(gè)模型和策略的雙重降維。
第二部分:在我們獲取了高純度數(shù)據(jù)的同時(shí),另一個(gè)重要的問題,就是如何高效率、高質(zhì)量地消化這些數(shù)據(jù),將數(shù)據(jù)轉(zhuǎn)化為無人車的智能與駕駛能力。

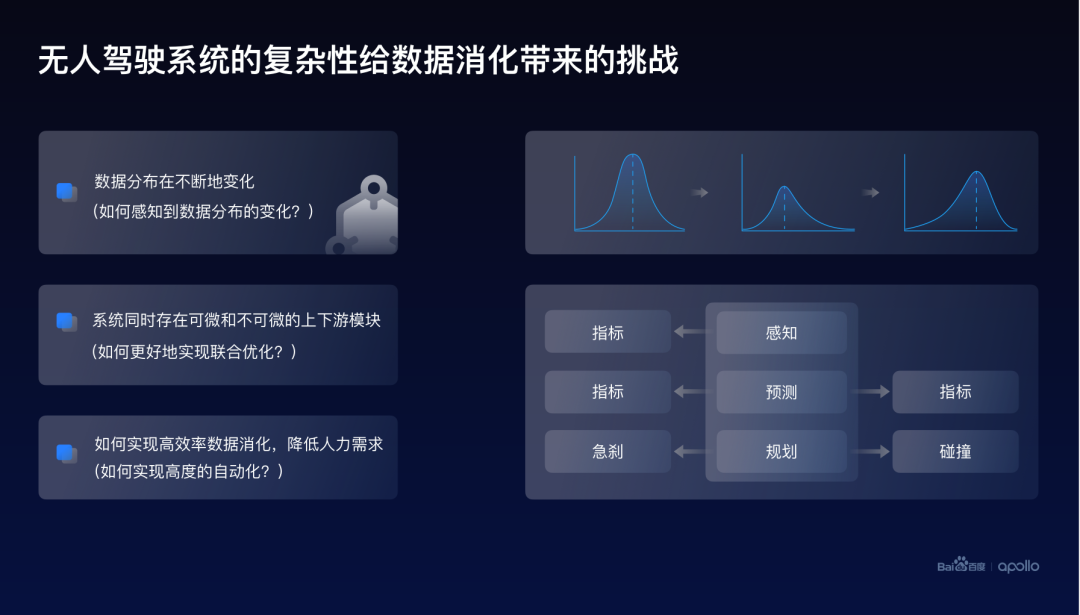
無人駕駛的系統(tǒng)與傳統(tǒng)的機(jī)器學(xué)習(xí)的應(yīng)用其實(shí)是有很大的不同的,這樣的不同,給整體的數(shù)據(jù)消化帶來了很多挑戰(zhàn)。
首先,我們所處的世界其實(shí)是不斷變化的。因而,無人車搜集到數(shù)據(jù)的分布也是在不斷變化的。
所以如何讓無人駕駛這個(gè)系統(tǒng)可以感知到數(shù)據(jù)分布的一個(gè)變化,是需要考慮的一個(gè)重要問題。
其次,無人駕駛的系統(tǒng)并不是單一的模型,是由多個(gè)可微和不可微的模塊共同組成的。并且這些模塊是相互關(guān)聯(lián)、相互影響的。所以需要考慮如何更好地去聯(lián)合優(yōu)化這些模塊。
最后,數(shù)據(jù)消化還存在一個(gè)效率的問題,而高效的系統(tǒng)往往是需要實(shí)現(xiàn)高度的自動(dòng)化,從而降低流程中對于人工的需求,最終達(dá)到降低系統(tǒng)成本的一個(gè)核心目標(biāo)。
接下來,我會(huì)從這三個(gè)角度分別去介紹百度對于數(shù)據(jù)消化的一個(gè)實(shí)踐與思考。它們分別是自動(dòng)化、聯(lián)合優(yōu)化以及數(shù)據(jù)分布。

首先,基于持續(xù)學(xué)習(xí)與AutoML的一些概念,百度在數(shù)據(jù)閉環(huán)里面設(shè)計(jì)了一套自動(dòng)化訓(xùn)練引擎。
數(shù)據(jù)通過數(shù)據(jù)緩存的形式、采樣的方式進(jìn)入到訓(xùn)練引擎,這類似于持續(xù)學(xué)習(xí)里面一些比較經(jīng)典的經(jīng)驗(yàn)回放機(jī)制。
由于自動(dòng)駕駛系統(tǒng)的優(yōu)化是多目標(biāo)的,整個(gè)訓(xùn)練引擎需要持續(xù)的維護(hù)一個(gè)模型集合,不僅僅包含最優(yōu)的模型,還包含在整個(gè)訓(xùn)練過程當(dāng)中產(chǎn)生的中間模型。
我們使用一個(gè)異步的推理引擎對這些模型進(jìn)行評測,因而最終的訓(xùn)練的輸出是一個(gè)候選模型的集合,而不是一個(gè)單一的模型。這個(gè)集合在多目標(biāo)優(yōu)化里面一般叫做Pareto front。
此外,在概念上,百度認(rèn)為一個(gè)模型它是由參數(shù)和超參數(shù)共同定義的,這里的參數(shù)定義了模型的靜態(tài)狀態(tài),而超參數(shù)其實(shí)定義了整個(gè)模型優(yōu)化的軌跡或者叫動(dòng)力學(xué)。這兩種參數(shù)是結(jié)合起來一起進(jìn)行管理的。
通常模型參數(shù)是通過梯度優(yōu)化的方式來優(yōu)化的,而超參數(shù)則需要使用非梯度優(yōu)化。這里借鑒了基于進(jìn)化算法的一個(gè)架構(gòu)思路。
首先從模型集合里采樣模型參數(shù)和超參數(shù)。然后對它們做一些探索。這里有與傳統(tǒng)的超參數(shù)優(yōu)化有所不同的地方,在于不僅僅對超參數(shù)進(jìn)行探索,同時(shí)對整個(gè)模型的參數(shù)也進(jìn)行擾動(dòng)。這也是受到今年Rich sutton等人提出的持續(xù)學(xué)習(xí)的可塑性的影響,以及2019年Jordan ash等人提出的模型熱啟動(dòng)工作的啟發(fā)。百度在實(shí)踐中發(fā)現(xiàn),這種參數(shù)的擾動(dòng)是可以提高在持續(xù)訓(xùn)練的過程當(dāng)中,整個(gè)模型群體的魯棒性和穩(wěn)定性。
探索后的模型參數(shù)可以作為初始化,與超參數(shù)共同傳入Paddlecloud分布式訓(xùn)練,而訓(xùn)練的過程中產(chǎn)生的模型將會(huì)一起傳回整個(gè)模型集合進(jìn)行管理。
需要注意的是,這里的訓(xùn)練步長不一定是要等模型收斂,也可以設(shè)置比較短的一些步長,這樣的話可以直接實(shí)現(xiàn)動(dòng)態(tài)參數(shù)優(yōu)化的一個(gè)能力。
利用這樣的一個(gè)訓(xùn)練引擎,對自動(dòng)駕駛系統(tǒng)里面的數(shù)據(jù)驅(qū)動(dòng)模型實(shí)行了自動(dòng)化托管的能力,也就是說在數(shù)據(jù)確定的情況下,可以實(shí)現(xiàn)全無人的訓(xùn)練模式。

繼續(xù)以剛才的小狗為例,當(dāng)發(fā)現(xiàn)這只小狗出現(xiàn)誤檢之后,可以利用特征檢索的一些方式,挖掘出一批小狗的數(shù)據(jù),然后將新數(shù)據(jù)與舊數(shù)據(jù)同時(shí)傳入到訓(xùn)練引擎進(jìn)行自動(dòng)化訓(xùn)練。這里可以看到每一個(gè)點(diǎn)其實(shí)是一個(gè)模型,可以看到在整個(gè)訓(xùn)練的過程當(dāng)中,模型的效果是不斷提升的,同時(shí)在訓(xùn)練的最終結(jié)果發(fā)現(xiàn),可以實(shí)現(xiàn)小目標(biāo)和總體指標(biāo)的同時(shí)提升。

此外,這個(gè)訓(xùn)練引擎是一個(gè)通用的架構(gòu),因此它不僅僅是可以用在這樣的一個(gè)問題上,其他的各種各樣的一些問題也可以利用這樣的方式提升模型的效果。舉個(gè)例子比如:低矮綠植問題、柵欄問題以及懸浮塑料袋的問題。


點(diǎn)擊查看大圖
不難想象,在持續(xù)優(yōu)化這樣的一個(gè)系統(tǒng)的時(shí)候,所有的這些挖掘的數(shù)據(jù)最終是以一個(gè)個(gè)的數(shù)據(jù)集的形態(tài)傳輸?shù)接?xùn)練引擎當(dāng)中的。
而在迭代的過程當(dāng)中發(fā)現(xiàn),其實(shí)每一次新數(shù)據(jù)進(jìn)來的時(shí)候,整個(gè)模型的效果是呈持續(xù)提升的一個(gè)趨勢。并且尚沒有觀測到數(shù)據(jù)飽和的一個(gè)狀態(tài)。
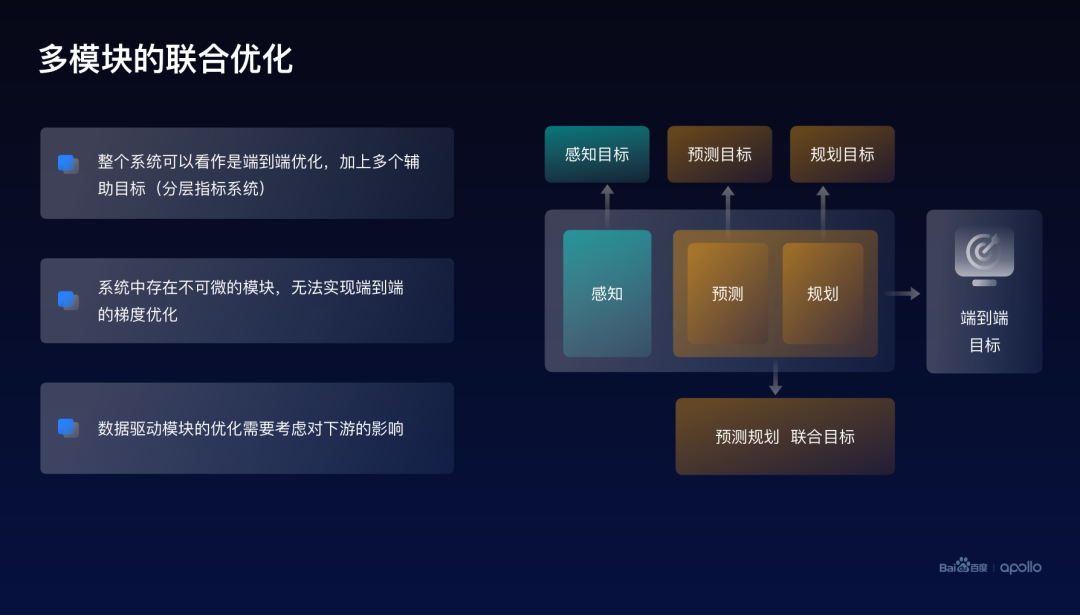
大家可以注意到,其實(shí)剛才提到的例子都是對單一模型的一個(gè)優(yōu)化。而整體自動(dòng)駕駛是一個(gè)多模塊的復(fù)雜系統(tǒng),因而更需要去關(guān)注聯(lián)合優(yōu)化的問題。

本質(zhì)上來看,整個(gè)自動(dòng)駕駛系統(tǒng)可以看作是一個(gè)端到端的優(yōu)化,因?yàn)槲覀冏罱K在乎的,是這個(gè)無人車在車上的一個(gè)效果,而優(yōu)化的方式是通過加上很多模塊級別的輔助目標(biāo)。比如感知會(huì)有自己的目標(biāo),預(yù)測、規(guī)劃都會(huì)有自己獨(dú)立的目標(biāo)。而之所以沒有辦法真正地實(shí)現(xiàn)端到端的優(yōu)化這個(gè)能力,是由于在整個(gè)系統(tǒng)里面存在很多不可微的模塊,因而沒有辦法計(jì)算它們的梯度。
此外,對于系統(tǒng)里面某一些數(shù)據(jù)驅(qū)動(dòng)模塊的優(yōu)化,從端到端的角度,也是需要考慮它對下游的一個(gè)影響,可以認(rèn)為目前整個(gè)的工程架構(gòu)所做的方式,應(yīng)該是類似于系統(tǒng)級的Coordinate descent,又叫做坐標(biāo)下降方法。
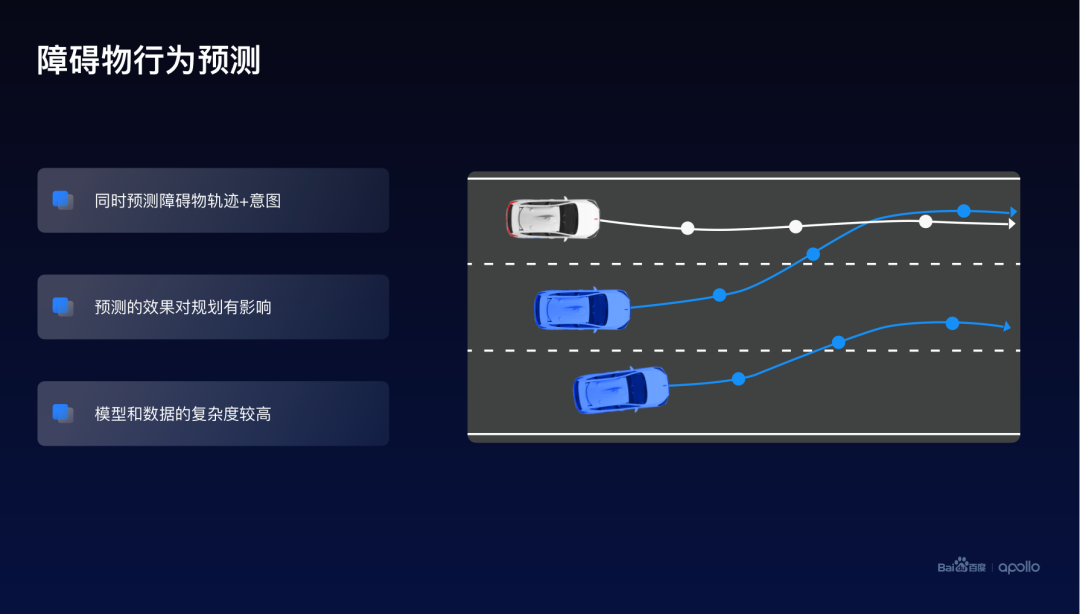
一個(gè)比較經(jīng)典的聯(lián)合優(yōu)化的例子就是行為預(yù)測,在這張圖上可以發(fā)現(xiàn),行為預(yù)測這個(gè)模塊它是處于中間的,它有上游,也有下游。這里的行為預(yù)測模型同時(shí)考慮了障礙物軌跡以及面對障礙物的意圖,它的效果會(huì)直接影響下游的軌跡規(guī)劃這個(gè)模塊。
而預(yù)測的模型,預(yù)測的數(shù)據(jù)以及它的問題的復(fù)雜度都相對比較高。
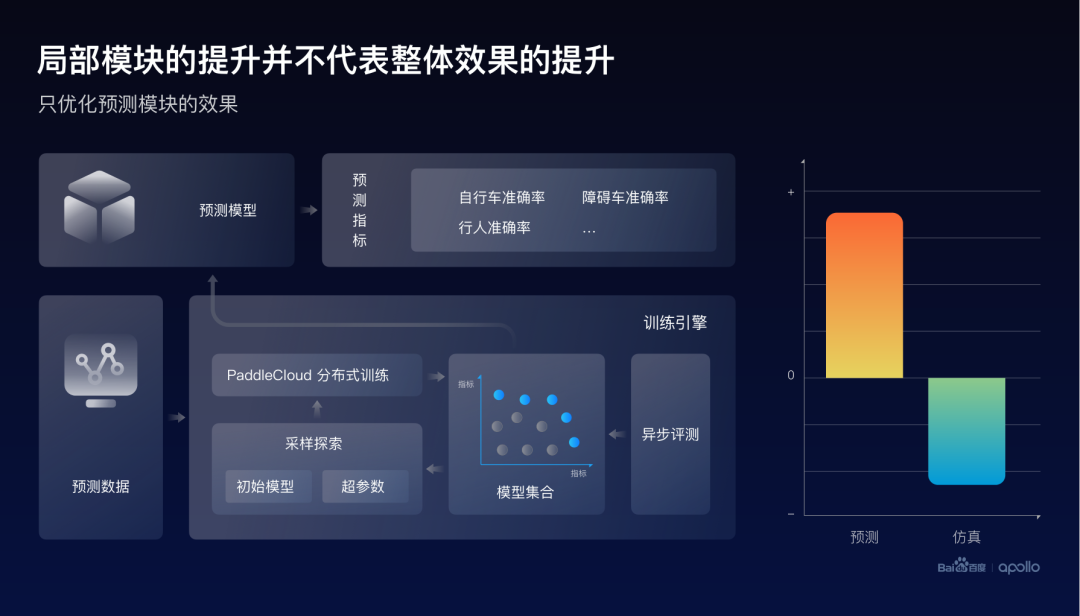
首先我們做了一個(gè)初步的嘗試,嘗試了與之前感知比較類似的一個(gè)方法,搜集一些數(shù)據(jù),利用自動(dòng)化優(yōu)化的引擎來優(yōu)化預(yù)測的評測指標(biāo)。這里的指標(biāo)是由不同的障礙物的類型構(gòu)成,比如自行車、障礙車或者是行人。
從右邊的結(jié)果可以發(fā)現(xiàn),的確發(fā)現(xiàn)了這個(gè)預(yù)測的整體指標(biāo)取得了提升,但是當(dāng)把最好的預(yù)測模型放進(jìn)這個(gè)端到端系統(tǒng)時(shí),發(fā)現(xiàn)仿真的指標(biāo)卻下降了。實(shí)際上,我們認(rèn)為這是由于預(yù)測指標(biāo)與仿真指標(biāo)的目標(biāo)不一致所造成的。
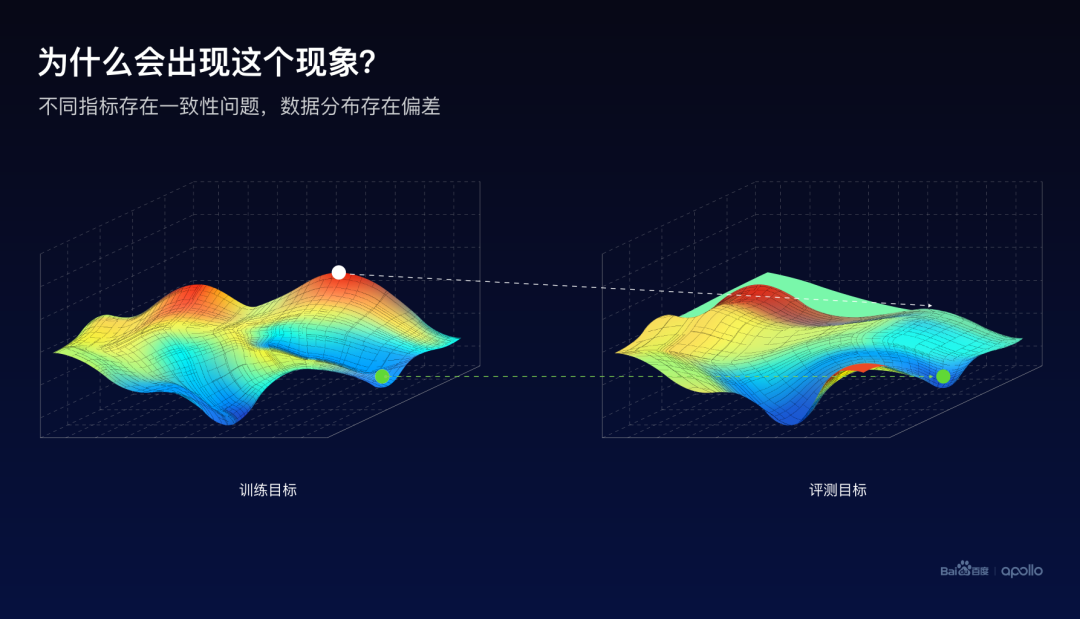
這里使用地形圖來示意訓(xùn)練和評測的優(yōu)化目標(biāo)。假設(shè)越高的點(diǎn)越好,越紅的點(diǎn)越好,指標(biāo)越好。如果只看訓(xùn)練的指標(biāo),使用梯度優(yōu)化的方式,的確是可以找到紅色的比較高的區(qū)域。然后它的對應(yīng)位置的評測目標(biāo),卻并非是處于一個(gè)比較高的狀態(tài)。
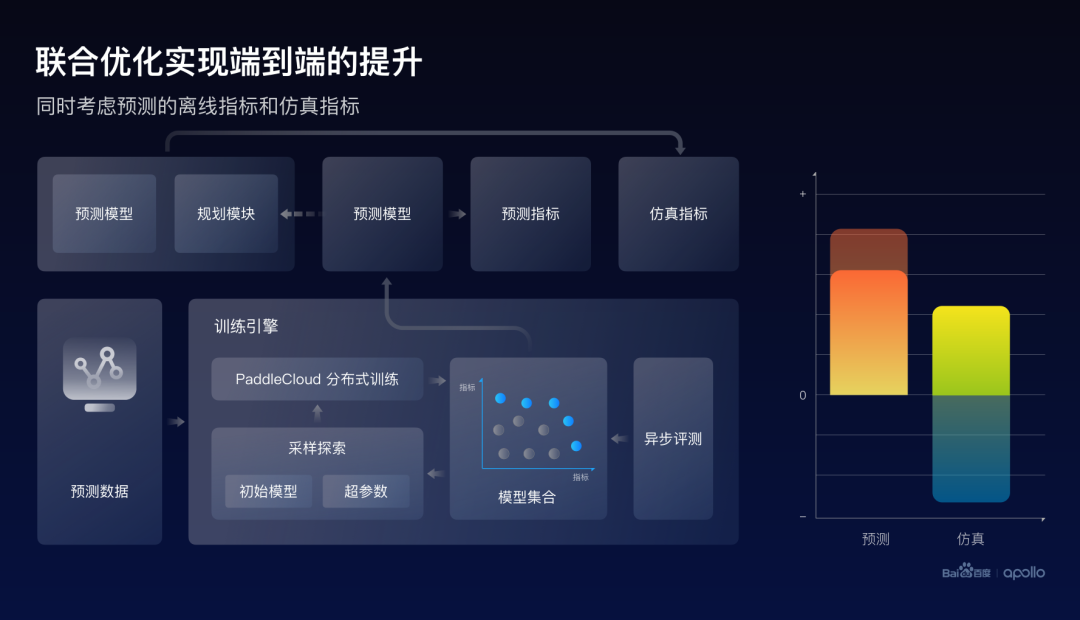
因而一個(gè)比較直觀的想法就是,在優(yōu)化這個(gè)模型的時(shí)候,同時(shí)去看兩個(gè)地形圖的高度,這樣就有更大的概率,去找到兩個(gè)指標(biāo)都好的一個(gè)最終狀態(tài)。
基于這樣的一個(gè)想法,百度實(shí)現(xiàn)了一個(gè)工程架構(gòu)。在訓(xùn)練的同時(shí),將產(chǎn)生的預(yù)測模型實(shí)時(shí)地與下游規(guī)劃模塊進(jìn)行打包,同步地進(jìn)行仿真評測。因而,最終的訓(xùn)練引擎同時(shí)優(yōu)化的是離線的預(yù)測指標(biāo)以及仿真的端到端指標(biāo)。
通過結(jié)果可以發(fā)現(xiàn),雖然預(yù)測的指標(biāo)有小幅度的下降,但是其實(shí)最終這個(gè)仿真的效果是有大幅度提升的。
剛才已經(jīng)提到了一些關(guān)于數(shù)據(jù)分布對于訓(xùn)練的影響的一些問題。可以認(rèn)為整個(gè)數(shù)據(jù)消化的能力是與數(shù)據(jù)分布的理解能力息息相關(guān)的,因而著重也需要去考慮這個(gè)系統(tǒng)如何去理解數(shù)據(jù)分布。
數(shù)據(jù)分布其實(shí)在機(jī)器學(xué)習(xí)里面是一個(gè)非常重要的概念。這個(gè)原因是在于目前比較有效的數(shù)據(jù)驅(qū)動(dòng)的方式主要是基于深度學(xué)習(xí)。而深度學(xué)習(xí)的核心原則是經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化。
這里我列舉出了訓(xùn)練和評測的經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化的公式。而重點(diǎn)關(guān)注的是這個(gè)w和v數(shù)值,它們分別是訓(xùn)練時(shí)的每個(gè)樣本的權(quán)重,或者叫分布或者是密度,和評測時(shí)候的每個(gè)樣本的權(quán)重。
所以從這個(gè)公式可以發(fā)現(xiàn),如果w和v不一樣,那通過這個(gè)訓(xùn)練公式獲得的模型,在評測的時(shí)候大概率也不是最好的。而評測的效果往往是需要真正關(guān)心的。因而,這里一個(gè)核心的問題就是如何找到正確的數(shù)據(jù)分布。
為此,百度在數(shù)據(jù)閉環(huán)里設(shè)計(jì)了一套對于數(shù)據(jù)分布的管理和探索的方案。


點(diǎn)擊查看大圖
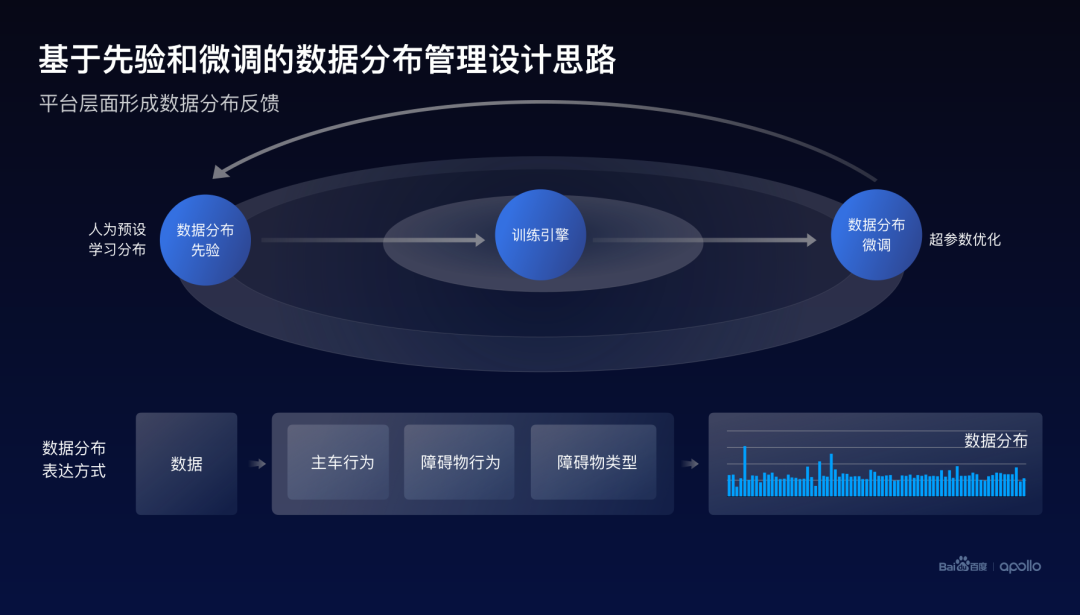
這里主要分為兩個(gè)部分,首先,對數(shù)據(jù)分布的先驗(yàn)進(jìn)行統(tǒng)一的管理,這里的先驗(yàn)可以是人為設(shè)定的,也可以是通過學(xué)習(xí)來獲得。
當(dāng)這個(gè)先驗(yàn)進(jìn)入到訓(xùn)練引擎之后,訓(xùn)練引擎其實(shí)可以把這個(gè)先驗(yàn)或者這個(gè)數(shù)據(jù)分布當(dāng)作超參數(shù),做一定程度的探索或搜索。當(dāng)我們發(fā)現(xiàn)更好的分布之后,可以通過一個(gè)反饋的機(jī)制修正數(shù)據(jù)分布的先驗(yàn)。
而另外一個(gè)問題就是,數(shù)據(jù)分布到底應(yīng)該如何去描述它,百度主要采用標(biāo)簽化或者叫場景化的一個(gè)方式。
以剛才行為預(yù)測為例,其實(shí)可以通過問三個(gè)問題來映射所有的數(shù)據(jù)到不同的場景,而這三個(gè)問題,可以分別是主車的行為、障礙物的行為,以及障礙物的類型。
當(dāng)對每個(gè)場景的數(shù)據(jù)進(jìn)行統(tǒng)計(jì),就可以最終獲得整個(gè)數(shù)據(jù)集所對應(yīng)的數(shù)據(jù)分布的描述。
這里介紹一個(gè)比較有意思的學(xué)習(xí)數(shù)據(jù)分布的一個(gè)嘗試。主要的想法是由于整個(gè)數(shù)據(jù)閉環(huán)的平臺(tái)其實(shí)管理了所有的模型訓(xùn)練,因而在百度平臺(tái)的Log里面存在大量的模型和對應(yīng)的指標(biāo)。
例如在剛才的行為預(yù)測訓(xùn)練里面,我們發(fā)現(xiàn)Log里面其實(shí)有很多模型、預(yù)測指標(biāo)、仿真指標(biāo)的配對數(shù)據(jù)。
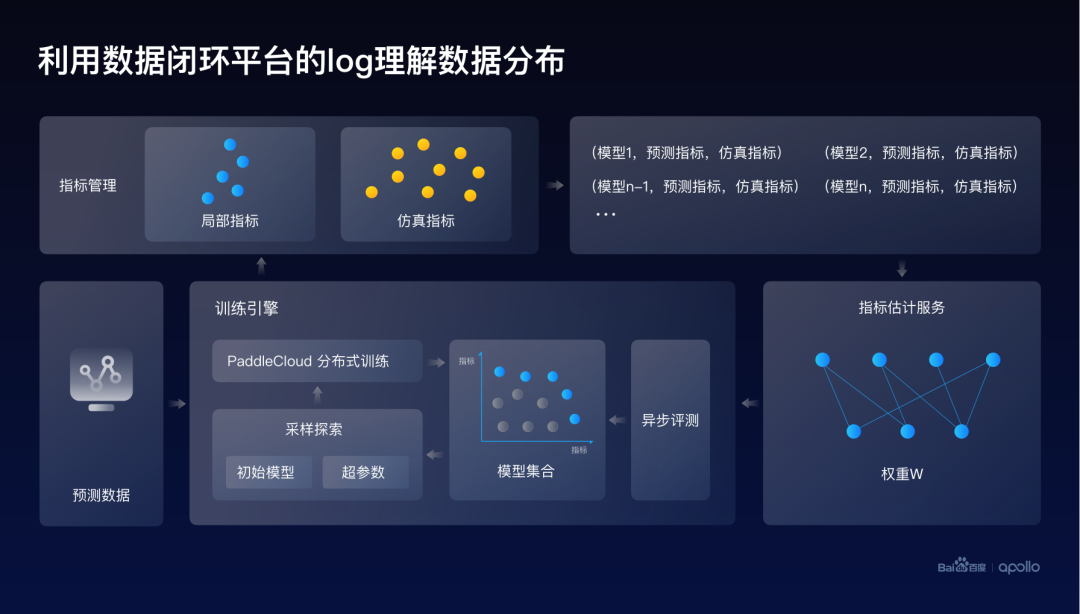
所以一個(gè)自然而然的想法就是,是不是可以訓(xùn)練一個(gè)線性的預(yù)測器,它的輸入是不同場景的預(yù)測指標(biāo),而輸出是仿真的指標(biāo)。這個(gè)線性預(yù)測器的權(quán)重,最終就對應(yīng)了指標(biāo)之間的相關(guān)性,其實(shí)也代表了不同場景下障礙物的預(yù)測能力,對于仿真效果的一個(gè)重要度的體現(xiàn)。
以環(huán)島的數(shù)據(jù)舉例,從這批預(yù)測數(shù)據(jù)中學(xué)習(xí)到了關(guān)于仿真急剎的數(shù)據(jù)分布。這里權(quán)重最高的場景是主車?yán)@行環(huán)島,障礙物進(jìn)入環(huán)島,障礙物為車輛時(shí)的意圖預(yù)測能力。
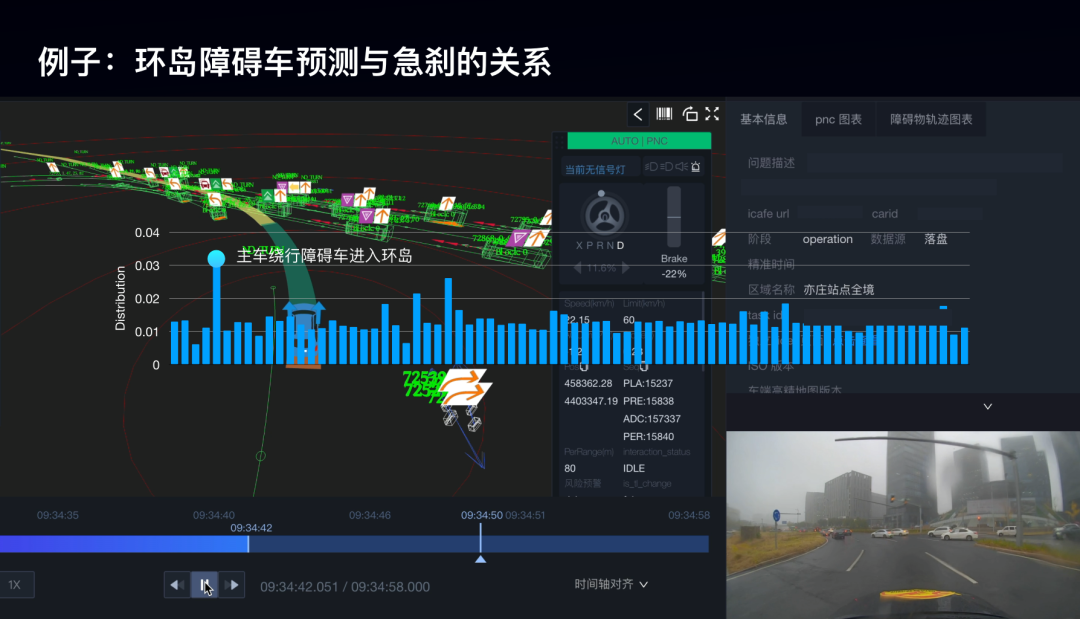
從這個(gè)對應(yīng)場景視頻我們不難看出,當(dāng)在這個(gè)時(shí)候,障礙車預(yù)測不準(zhǔn)確的時(shí)候,主車很有可能出現(xiàn)急剎的情況。
雖然這樣的分布,并非是完全真實(shí)的分布,但平臺(tái)具備這樣貢獻(xiàn)度的估計(jì)能力,其實(shí)可以給研發(fā)帶來一定程度的幫助。
從另外一個(gè)角度,我們可以適度地根據(jù)這樣的一個(gè)數(shù)據(jù)分布,提供一個(gè)指導(dǎo),來調(diào)整數(shù)據(jù)分布的一個(gè)先驗(yàn)或者是指標(biāo)評測時(shí)候的數(shù)據(jù)分布,從而達(dá)到加強(qiáng)訓(xùn)練指標(biāo)和評測指標(biāo)的一致性的方式。
例如在剛才的預(yù)測的例子里,這樣的一個(gè)方式可以大幅度降低在訓(xùn)練流程中對于仿真評測的需求,從而達(dá)到降低成本。
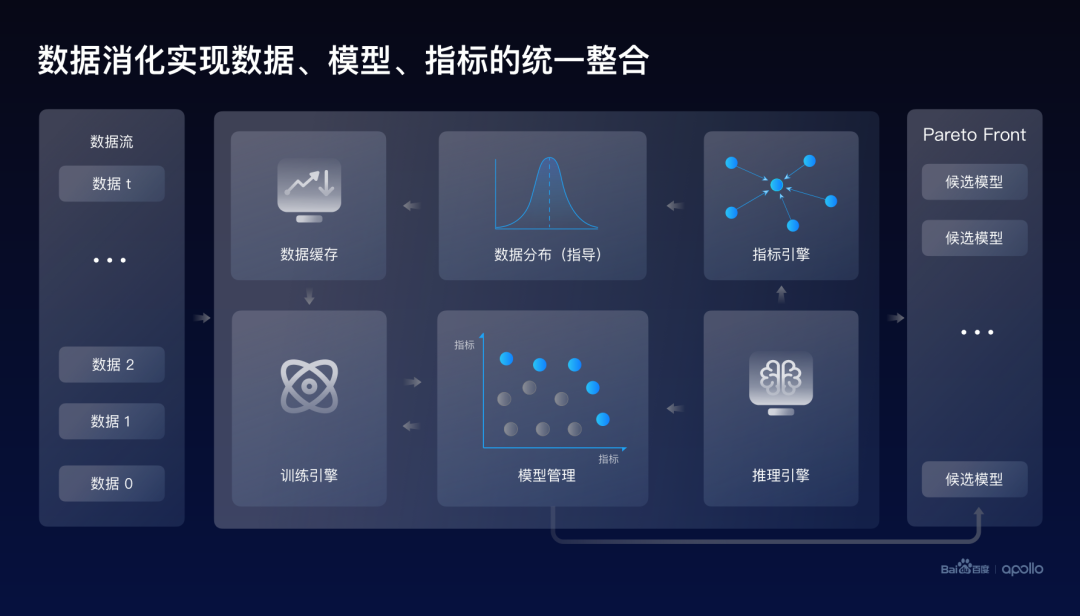
最終總結(jié)一下:百度提出了以高提純、高消化為核心驅(qū)動(dòng)力的數(shù)據(jù)閉環(huán)的設(shè)計(jì)思路。這里的高提純通過小模型和大模型的車云協(xié)同,實(shí)現(xiàn)高效的數(shù)據(jù)挖掘和自動(dòng)化標(biāo)注。
而高消化則通過數(shù)據(jù)、模型、指標(biāo)的集中式、端到端整合來實(shí)現(xiàn)。
除此之外,訓(xùn)練、推理以及數(shù)據(jù)分布是在數(shù)據(jù)消化中可以形成有效的一個(gè)反饋機(jī)制,進(jìn)一步提升數(shù)據(jù)消化的整體效率和效果。
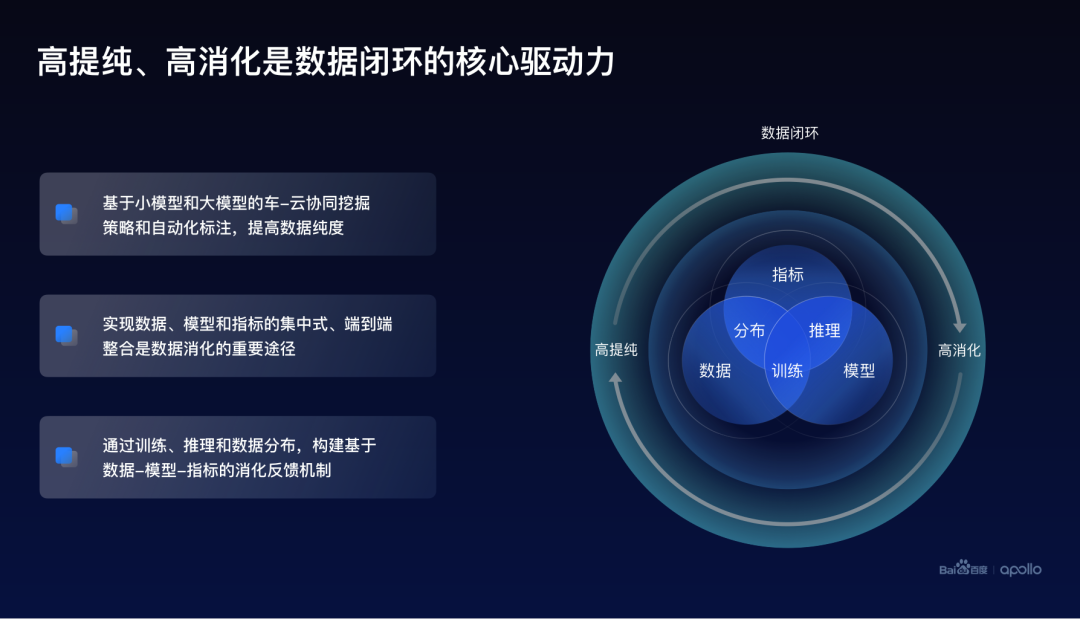
最后,希望百度Apollo的高提純、高消化的數(shù)據(jù)閉環(huán)技術(shù)思想,可以給業(yè)界同行們帶來更多的啟發(fā),共同推動(dòng)和實(shí)現(xiàn)自動(dòng)駕駛大規(guī)模的商業(yè)化落地。
好,謝謝大家!
審核編輯 :李倩
-
自動(dòng)駕駛
+關(guān)注
關(guān)注
784文章
13844瀏覽量
166566 -
無人車
+關(guān)注
關(guān)注
1文章
302瀏覽量
36492 -
Apollo
+關(guān)注
關(guān)注
5文章
342瀏覽量
18472
原文標(biāo)題:百度Apollo Day|李昂:數(shù)據(jù)規(guī)模不是唯一標(biāo)準(zhǔn),數(shù)據(jù)純度更是重要考量
文章出處:【微信號:baiduidg,微信公眾號:Apollo智能駕駛】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
特斯拉在墨西哥新萊昂州大規(guī)模購地
上汽大眾途昂榮獲中汽數(shù)據(jù)“2024年耐腐蝕卓越車型”
ADS9224R使用SPI常規(guī)模式,讀數(shù)據(jù)無返回,請問具體的讀數(shù)據(jù)的時(shí)序應(yīng)該是怎樣的?
上揚(yáng)軟件攜手立昂東芯啟動(dòng)MES解決方案
城市NOA是評價(jià)智駕能力的唯一標(biāo)準(zhǔn)嗎?
數(shù)據(jù)中心布線標(biāo)準(zhǔn)有什么
STM32F0xx_HAL_Driver庫的串口接收數(shù)據(jù)個(gè)數(shù),是不是只能寫成1,一個(gè)一個(gè)數(shù)據(jù)接收?
請問CAN數(shù)據(jù)域的數(shù)據(jù)格式該如何定義?以什么標(biāo)準(zhǔn)定義?
什么數(shù)據(jù)集成(Data Integration):如何將業(yè)務(wù)數(shù)據(jù)集成到云平臺(tái)?
STM32L496 DMA收集到數(shù)據(jù)一半產(chǎn)生中斷,但是仿真時(shí)發(fā)現(xiàn)并不是數(shù)據(jù)的一半,為什么?
探索數(shù)據(jù)中臺(tái)的力量:企業(yè)數(shù)據(jù)資產(chǎn)管理的未來
選擇 KV 數(shù)據(jù)庫最重要的是什么?
西部數(shù)據(jù)交易中心探索創(chuàng)新“一品一碼”服務(wù) 全力打造數(shù)據(jù)權(quán)益保護(hù)“新高地”

數(shù)據(jù)治理為什么要清洗數(shù)據(jù)
機(jī)房精密空調(diào)制冷劑純度低會(huì)導(dǎo)致哪些后果?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論