
 存內計算對“存”的選擇
存內計算對“存”的選擇
電子發燒友網報道(文/周凱揚)無論是前段時間爆火的繪圖模型Stable Diffusion,還是大規模語言模型ChatGPT,AI無疑已經成了新時代的自動化工具,哪怕是在某些與認知相關的任務上,也能通過深度學習實現高于人類的精度。
但正因我們提過多次的算力問題,對于大型AI訓練的計算要求已經在每兩個月翻倍了,別說可持續能源供應了,就連硬件的可持續都有些陷入停滯了。其實以目前各種模型的迭代速度來看,更高的運算效率才是重中之重,畢竟這些模型并不需要每兩個月就推陳出新。
深度學習還有哪些環節可以提升效率
我們先從深度學習運算來看哪些算數運算占比最高,根據IBM給出的統計數據,無論是語音識別的RNN、語言模型DNN和視覺模型CNN,矩陣向量乘法都占據了運算總數的70%到90%,所以打造一個矩陣矢量乘法加速器,是多數AI加速器的思路。
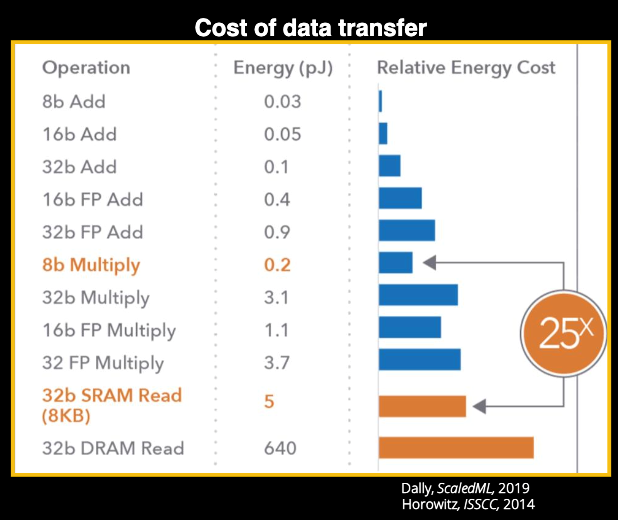
數據傳輸和運算的功耗對比 / ISSCC
要考慮效率,我們就不能不談到功耗的問題,如果只顧算力而不考慮功耗,任由龐大規模的GPU等硬件消耗能量不顧碳排放的話,也不符合全球當下的節能減排趨勢。而在深度學習中,各種精度的加法乘法都會消耗能量,但這些運算消耗的能量與傳統馮諾依曼結構中數據移動消耗的能量相比,就顯得微不足道了,尤其是從DRAM中讀寫高精度數值時,能耗差距甚至可以達到數十倍以上。
這還只是在數據中心場景中,如果我們放到邊緣來看,如今的移動設備需要語音識別、圖像識別之類的各種深度學習應用。所以提升這類設備的效率,才有可能在功耗和內存都有所限制的嵌入式應用中普及深度學習。
存內計算的存儲選擇
為了減少數據移動消耗的能量,提高MVM的計算性能,存內計算成了一個不錯的選擇。存內計算(IMC)是一項創新的計算方式,將特定的計算任務放到存儲設備中,并使用模擬或混合信號的計算技術。相較馮諾依曼結構或近存計算來說,最大程度地減少了數據移動。
而早期利用IMC進行神經網絡推理的測試結果證明,在軟硬件結合的情況下,可以得到優秀的精度結果,而DAC、ADC、功能激活之類的數字操作則是通過片外的軟件或硬件來實現的。自那之后,各種使用SRAM、NOR Flash、RRAM、PCM和MRAM的單核或多核存內計算芯片紛紛面世。
在對于正確存儲類型的選擇上,存內計算必須面臨取舍的問題,比如性能、密度、寫入時間、寫入功耗、穩定性以及制造工藝上。性能自然就是直接影響到我們說的TOPS算力以及效率,目前SRAM優勢較大,密度則決定了裸片大小,同時也影響到了成本。
而在邊緣場景下,環境一致性往往不比數據中心,所以如果不能保證穩定性的話,就會影響到存內計算進行深度學習的精度。最后的制造工藝不僅決定了這類存內計算芯片能否量產,是否存在供應鏈危機或成本問題,也決定了它有沒有繼續推進的空間,比如目前工藝較為先進的主要是PCM和SRAM,最高分別已經到了14nm和12nm。
在2021年的VLSI技術大會上,IBM發表了一篇文章,講述了他們以14nm CMOS工藝打造的一個64核PCM模擬存內計算芯片,HERMES。該芯片采用了后端集成的多層相變化內存,由256個線性化的CCO ADC組成,可以在1GHz的工作頻率之上進行精確的片上矩陣矢量乘法運算。在深度學習的運算測試中,HERMES獲得了10.5 TOPS/W的運算效率以及1.59TOPS/mm2的性能密度。
而荷蘭初創企業Axelera AI則選了數字SRAM這一路線,他們在去年12月成功流片第一代IMC芯片Thetis Core。Thetis Core的面積不到9mm2,卻可以在INT8精度下提供39.3TOPS的算力和14.1 TOPS/W的性能,甚至還可以超頻到48.16TOPS。但不少存內計算芯片提到性能表現時,往往都是指滿載的情況,正因如此,Thetis Core在低利用率下的效率表現才顯得無比亮眼。哪怕從100%利用率降低至25%的,該芯片也能展現13TOPS/W的效率,降幅只有7%左右。
小結
除了“存”以外,存內計算在“算”上的選擇也不盡相同,比如進行模擬或數字MAC運算等等。從斯坦福大學教授Boris Murmann提出的觀點來看,在低精度下模擬運算要比數字運算更高效,但一旦精度拔高,比如8位以后,模擬計算的功耗就會成倍增加了。考慮到落地應用較少,未來的存內計算會更傾向于哪種形式仍有待觀察,但從存儲廠商、存算一體芯片廠商的動向來看,這或許是存儲市場迎來又一輪爆發的絕佳機遇。
但正因我們提過多次的算力問題,對于大型AI訓練的計算要求已經在每兩個月翻倍了,別說可持續能源供應了,就連硬件的可持續都有些陷入停滯了。其實以目前各種模型的迭代速度來看,更高的運算效率才是重中之重,畢竟這些模型并不需要每兩個月就推陳出新。
深度學習還有哪些環節可以提升效率
我們先從深度學習運算來看哪些算數運算占比最高,根據IBM給出的統計數據,無論是語音識別的RNN、語言模型DNN和視覺模型CNN,矩陣向量乘法都占據了運算總數的70%到90%,所以打造一個矩陣矢量乘法加速器,是多數AI加速器的思路。
數據傳輸和運算的功耗對比 / ISSCC
要考慮效率,我們就不能不談到功耗的問題,如果只顧算力而不考慮功耗,任由龐大規模的GPU等硬件消耗能量不顧碳排放的話,也不符合全球當下的節能減排趨勢。而在深度學習中,各種精度的加法乘法都會消耗能量,但這些運算消耗的能量與傳統馮諾依曼結構中數據移動消耗的能量相比,就顯得微不足道了,尤其是從DRAM中讀寫高精度數值時,能耗差距甚至可以達到數十倍以上。
這還只是在數據中心場景中,如果我們放到邊緣來看,如今的移動設備需要語音識別、圖像識別之類的各種深度學習應用。所以提升這類設備的效率,才有可能在功耗和內存都有所限制的嵌入式應用中普及深度學習。
存內計算的存儲選擇
為了減少數據移動消耗的能量,提高MVM的計算性能,存內計算成了一個不錯的選擇。存內計算(IMC)是一項創新的計算方式,將特定的計算任務放到存儲設備中,并使用模擬或混合信號的計算技術。相較馮諾依曼結構或近存計算來說,最大程度地減少了數據移動。
而早期利用IMC進行神經網絡推理的測試結果證明,在軟硬件結合的情況下,可以得到優秀的精度結果,而DAC、ADC、功能激活之類的數字操作則是通過片外的軟件或硬件來實現的。自那之后,各種使用SRAM、NOR Flash、RRAM、PCM和MRAM的單核或多核存內計算芯片紛紛面世。
在對于正確存儲類型的選擇上,存內計算必須面臨取舍的問題,比如性能、密度、寫入時間、寫入功耗、穩定性以及制造工藝上。性能自然就是直接影響到我們說的TOPS算力以及效率,目前SRAM優勢較大,密度則決定了裸片大小,同時也影響到了成本。
而在邊緣場景下,環境一致性往往不比數據中心,所以如果不能保證穩定性的話,就會影響到存內計算進行深度學習的精度。最后的制造工藝不僅決定了這類存內計算芯片能否量產,是否存在供應鏈危機或成本問題,也決定了它有沒有繼續推進的空間,比如目前工藝較為先進的主要是PCM和SRAM,最高分別已經到了14nm和12nm。
在2021年的VLSI技術大會上,IBM發表了一篇文章,講述了他們以14nm CMOS工藝打造的一個64核PCM模擬存內計算芯片,HERMES。該芯片采用了后端集成的多層相變化內存,由256個線性化的CCO ADC組成,可以在1GHz的工作頻率之上進行精確的片上矩陣矢量乘法運算。在深度學習的運算測試中,HERMES獲得了10.5 TOPS/W的運算效率以及1.59TOPS/mm2的性能密度。

而荷蘭初創企業Axelera AI則選了數字SRAM這一路線,他們在去年12月成功流片第一代IMC芯片Thetis Core。Thetis Core的面積不到9mm2,卻可以在INT8精度下提供39.3TOPS的算力和14.1 TOPS/W的性能,甚至還可以超頻到48.16TOPS。但不少存內計算芯片提到性能表現時,往往都是指滿載的情況,正因如此,Thetis Core在低利用率下的效率表現才顯得無比亮眼。哪怕從100%利用率降低至25%的,該芯片也能展現13TOPS/W的效率,降幅只有7%左右。
小結
除了“存”以外,存內計算在“算”上的選擇也不盡相同,比如進行模擬或數字MAC運算等等。從斯坦福大學教授Boris Murmann提出的觀點來看,在低精度下模擬運算要比數字運算更高效,但一旦精度拔高,比如8位以后,模擬計算的功耗就會成倍增加了。考慮到落地應用較少,未來的存內計算會更傾向于哪種形式仍有待觀察,但從存儲廠商、存算一體芯片廠商的動向來看,這或許是存儲市場迎來又一輪爆發的絕佳機遇。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
存內計算
+關注
關注
0文章
32瀏覽量
1486
發布評論請先 登錄
相關推薦
熱點推薦
第二屆知存科技杯華東高校存內計算創新應用大賽正式啟動
在數字化浪潮席卷各行業的當下,數據量呈爆炸式增長,算力需求也水漲船高。存內計算架構作為創新解決方案,備受產學研各界關注。為推動存內
專注存內計算的知存科技榮獲2024全球(中國)半導體市場年度最佳企業獎
在近日舉行的2024-2025全球半導體市場峰會上,知存科技憑借在市場競爭力及未來前景方面的卓越表現,榮獲世界集成電路協會(World Integrated Circuit Association

開源芯片系列講座第24期:基于SRAM存算的高效計算架構
鷺島論壇開源芯片系列講座第24期「基于SRAM存算的高效計算架構」明晚(27日)20:00精彩開播期待與您云相聚,共襄學術盛宴!|直播信息報告題目基于SRAM存算的高效計算架構報告簡介

知存科技啟動首屆存內計算創新大賽
存內計算作為一項打破“內存墻”“功耗墻”的顛覆性技術,消除了存與算的界限,相比CPU或GPU能夠實現更高計算并行度、更大專用算力,達成數量級
存算一體化與邊緣計算:重新定義智能計算的未來
隨著數據量爆炸式增長和智能化應用的普及,計算與存儲的高效整合逐漸成為科技行業關注的重點。數據存儲和處理需求的快速增長推動了對計算架構的重新設計,“存算一體化”技術應運而生。同時,隨著物聯網、5G網絡

晶存科技芯片測試總部基地開業
近日,深圳市晶存科技股份有限公司(簡稱:晶存科技)迎來又一重要里程碑。其全資子公司——中山晶存技術有限公司,作為晶存科技的存儲芯片測試總部基地,在中山市三鄉鎮盛大開業。
D鎖存器的基本實現
在Verilog HDL中實現鎖存器(Latch)通常涉及對硬件描述語言的基本理解,特別是關于信號如何根據控制信號的變化而保持或更新其值。鎖存器與觸發器(Flip-Flop)的主要區別在于,鎖存器
鎖存器的基本輸出時序
在深入探討鎖存器的輸出時序時,我們需要詳細分析鎖存器在不同控制信號下的行為表現,特別是控制信號(如使能信號E)的電平變化如何影響數據輸入(D)到輸出(Q)的傳輸過程。以下是對鎖存器輸出時序的詳細描述,旨在全面覆蓋其工作原理和時序
d鎖存器解決了sr鎖存器的什么問題
D鎖存器(Data Latch)和SR鎖存器(Set-Reset Latch)是數字電路中常見的兩種存儲元件。它們在數字系統中扮演著重要的角色,用于存儲和傳遞信息。然而,這兩種鎖存器在設計和應用上
常用的d鎖存器型號有哪些
D鎖存器是一種常見的數字邏輯電路,用于存儲一個二進制位的狀態。以下是一些常用的D鎖存器型號及其特點: 74LS74:這是一種低功耗的正觸發D鎖存器,具有4個獨立的鎖存器。它具有數據輸入
rs鎖存器和sr鎖存器有什么區別嗎
RS鎖存器和SR鎖存器是數字電路中兩種常見的存儲單元,它們在功能和應用上有一些區別。 RS鎖存器 RS鎖存器,即Reset-Set鎖存器,是
鎖存器電路通過什么觸發的
鎖存器(Latch)是一種在數字電路中廣泛使用的存儲元件,它能夠存儲一位二進制信息。鎖存器電路的觸發方式有很多種,包括同步觸發、邊沿觸發、電平觸發等。 一、鎖存器的基本概念 鎖存器是一
鎖存器電路中的中間是什么元件
鎖存器電路概述 定義與功能 鎖存器(Latch)是數字電路中的一種基本存儲元件,用于存儲一個位(1或0)的狀態。它能夠在特定輸入脈沖電平作用下改變狀態,并保持該狀態直到下一個脈沖電平到來。鎖存器
鎖存器原態和新態的定義
鎖存器(Latch)是一種存儲單元,用于存儲一位二進制信息。在數字電路中,鎖存器是一種基本的存儲元件,廣泛應用于寄存器、計數器、觸發器等電路中。鎖存器的原態和新態是描述鎖存器狀態變化的





 工商網監
工商網監

評論