 對比NEON匯編與NEON Intrinsics編程的優缺點
對比NEON匯編與NEON Intrinsics編程的優缺點
本文選自極術專欄《Infrastructure開源軟件 on Arm》的Arm NEON學習系列。前面我們學習了如何快速上手開始NEON編程以及ArmNEON優化技術,本篇我們將對比NEON匯編與NEON Intrinsics編程的優缺點。
1.簡介
ARMNEON編程主要有兩種最常用的方式手寫匯編和Intrinsics。本文將對比NEON匯編與NEON Intrinsics編程的優缺點。
2.NEON匯編與Intrinsics
NEON匯編與Intrinsics各有優缺點:

NEON匯編與Intrinsics各有優缺點:但實際情況遠遠比這些復雜很多,特別是涉及到ARM v7-A/v8-A跨平臺的時候。下面我們結合實例做一些更深入的分析。
2.1 編程
對于初學者來說,Intrinsics比較易學易用。但是對于有匯編經驗的開發者來說,可能更熟悉NEON匯編編程,切換到Intrinsics反倒需要有個適應過程。下文列出了實際開發中的一些問題。
2.1.1 指令靈活性
從指令使用角度來說,匯編指令比Intrinsics指令更靈活,主要體現在數據加載/存儲上,比如下例:
-
Intrinsics指令
-
加載數據到一個64位寄存器 vld1_s8/u8/s16/u16/s32…etc
-
加載數據到一個128位寄存器vld1q_s8/u8/s16/u16/s32…etc
-
-
ARM v7-A匯編
VLD1 { Dd}, [Rn]
VLD1 { Dd, D(d+1) }, [Rn]
VLD1 { Dd, D(d+1), D(d+2)}, [Rn]
VLD1 { Dd, D(d+1), D(d+2), D(d+3) }, [Rn]
-
ARM v8-A匯編
LD1 { .]
LD1 { ., .}, []
LD1 { ., ., . }, []
LD1 { ., ., ., . }, []
這個問題主要針對現在,相信隨著編譯器的升級這些問題會逐漸解決的。
在一些情況下,有的編譯器已經能把兩條指令解析成一條匯編指令,比如: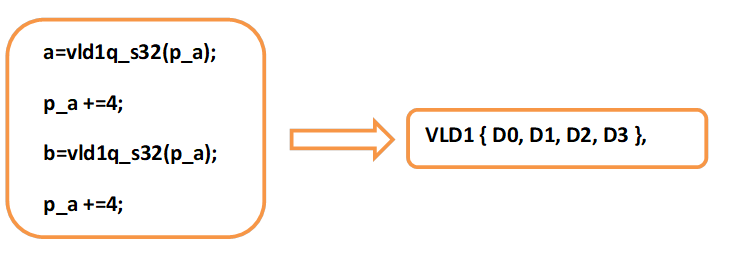
因此,我們有理由由相信,隨著ARM v8-A編譯器的不斷升級,intrinsics指令會完善到跟匯編指令一樣靈活的。
2.1.2 寄存器分配
NEON匯編編程時,需要自己分配寄存器,用戶必須清楚寄存器的使用情況。而Intrinsics編程的一個好處就是,用戶只需要定義變量即可,編譯器會自動分配寄存器。這是優點,但有時也會變成弱點。實踐證明,因為ARMv7-A只有16個128位NEON寄存器,在Intrinsics編程時,如果用戶同時使用過多的NEON寄存器,會導致gcc編譯器的寄存器分配問題。主要表現是編譯器會把很多數據存儲到堆棧中,這樣會極大的影響程序性能。因此用戶在使用Intrinsics編程時要注意這個問題。在性能出現異常時(比如C程序的性能比NEON程序的性能要好),檢查反匯編,看是否有寄存器分配的問題出現。在ARM64中,有32個128位NEON寄存器,這個問題的影響大大減弱。
2.2 性能與編譯器
在同一平臺下,NEON匯編的性能與編譯器無關,只由NEON的實現方式決定。好處是用戶在調整代碼時,用戶可以預測、控制自己程序的性能,但沒有驚喜。
NEON Intrinsics 的性能則極大的依賴于編譯器,不同的編譯器,性能可能有極大的差別。一般來說,越老版本的編譯器,性能越差。如果用戶需要保留對老版本編譯器兼容性時,需要慎重考慮使用Intrinsics。此外,當用戶優化代碼細節的時候,編譯器的介入,使用戶很難預測程序性能的變化,但有時候會有驚喜,有時Intrinsics的性能會比匯編的性能要好。盡管很少見,但確實存在。
編譯器主要對優化NEON程序造成影響。下圖是NEON實現及優化的一般流程:
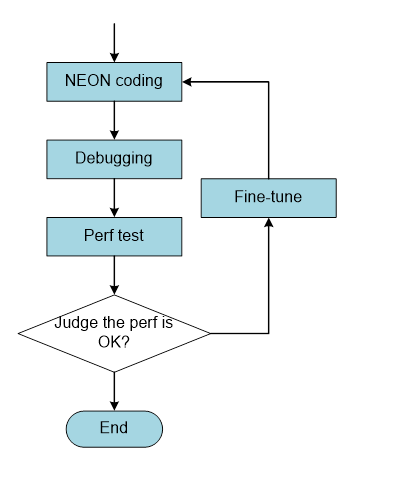
對于NEON匯編或是Intrinsics來講,實現流程是一樣的,編程——調試——測試。但是調優的步驟是不一樣的。
NEON匯編的調優方式主要有:
? 改變實現方式,比如改變所用指令,調整并行方式。
? 調整指令順序,以降低數據依賴性
? 上文第二章所介紹的方式都可以嘗試
在匯編調優時,最精細方式是:
? 確定匯編指令數目和指令的時序
? 使用PMU (Performance Monitoring Unit)測量程序執行的周期數
? 根據使用指令的時序,調整程序,盡量減少指令延時
這種方式的缺點是,針對指定微架構的調整,換到另外的平臺性能不一定會好。經常花費很大的工作量而只能取得很小的性能提升。
NEON intrinsics的調優則比較困難,
? 嘗試NEON匯編所用的調優方式,然后
? 觀察反匯編,看看數據依賴性、寄存器使用等情況
? 判斷優化效果是否達到預期, 如果符合預期則工作結束。此時,需要測試多種編譯器,檢查性能的異同。
在使用intrinsics轉換ARMv7-A的匯編時,優化效果判斷比較簡單,只要Intrinsics性能接近匯編性能即可。但是,在使用Intrinsics優化ARM v8-A的代碼時,我們沒有性能參考的對象,較難判斷代碼是否調整到最優狀態了。可能會有疑問,會不會匯編實現的性能會更好?但隨著整個ARM v8-A環境的成熟,這個問題帶來的影響會越來越小。另外,如果更看重Intrinsics的其它優點,對性能也不是錙銖必較的話,這個問題的影響也不大。
2.3 跨平臺與可移植性
現在,現有的大部分NEON匯編代碼只能運行在ARM v7-A或是ARM v8-A AArch32模式的平臺上。想要運行在ARM v8-A AArch64模式的平臺,我們必須重寫代碼,這帶來了很大的工作量。這時,NEON Intrinsics代碼的好處就體現出來了,在ARM v8-A AArch64模式下,我們可以直接運行這些代碼,減少了重寫代碼的工作量。同時,我們可以只維護一套代碼,這樣也減少了維護的工作量。
然而,由于ARMv7-A/ARMv8-A的硬件資源不同,即使用Intrinsics,有時我們也需要兩套代碼。Ne10中FFT實現就是一個例子:
// radix 4 butterfly with twiddles
scratch[0].r = scratch_in[0].r;
scratch[0].i = scratch_in[0].i;
scratch[1].r = scratch_in[1].r * scratch_tw[0].r - scratch_in[1].i * scratch_tw[0].i;
scratch[1].i = scratch_in[1].i * scratch_tw[0].r + scratch_in[1].r * scratch_tw[0].i;
scratch[2].r = scratch_in[2].r * scratch_tw[1].r - scratch_in[2].i * scratch_tw[1].i;
scratch[2].i = scratch_in[2].i * scratch_tw[1].r + scratch_in[2].r * scratch_tw[1].i;
scratch[3].r = scratch_in[3].r * scratch_tw[2].r - scratch_in[3].i * scratch_tw[2].i;
scratch[3].i = scratch_in[3].i * scratch_tw[2].r + scratch_in[3].r * scratch_tw[2].i;
上述代碼描述了32位浮點復數FFT算法的基本元——基4蝶形運算。從代碼中我們可以看出:
? 如果在一次循環中,兩個基4蝶形運算并行,需要20個 64位寄存器。
? 如果在一次循環中,四個基4蝶形運算并行,需要20個 128位寄存器。
由于ARM v7-A只有16個128位寄存器,因此,該平臺的FFT實現僅能一次循環兩個基4蝶形運算并行。而ARM v8-A有32個128位寄存器,該平臺的FFT實現能一次循環四個基4蝶形運算并行。因此,即使用Intrinsics,我們也需要兩套代碼。
上例可以說明,在實現一套代碼跨ARM v7-A/v8-A平臺時,我們需要注意一些類似的特例。
2.4 將來
上面已經分析了NEON匯編與Intrinsics的很多問題,但是這些問題都是暫時的。長遠來看,使用intrinsics還是更好。Intrinsics能帶來硬件以及編譯器發展的好處。經典算法只要實現一次即可,不用隨著硬件的升級而重新編程,大大減少了工作量。
2.5 總結
結合實例,上文對NEON匯編和Intrinsics做了一些分析。總體來說,使用intrinsics利大于弊。特別是與匯編相比,Intrinsics更容易編程,且能夠更好地兼容ARMv7-A/ARMv8-A。
下面再總結一下NEON Intrinsics使用時的一些注意事項:
? 使用的寄存器數量
? 編譯器選擇
? 查看反匯編
3.總結
本文通過實際程序分析了NEON匯編與Intrinsics的優缺點。希望能對用戶在NEON實際開發中有些借鑒意義。
審核編輯 :李倩
-
寄存器
+關注
關注
31文章
5357瀏覽量
120591 -
編程
+關注
關注
88文章
3623瀏覽量
93798
原文標題:Arm NEON學習(三)NEON 匯編與Intrinsics編程
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論